long __thread counter = 0; long *counterp[NR_THREADS] = { NULL }; long finalcount = 0; DEFINE_SPINLOCK(final_mutex);
voidinc_count(void) { counter++; }
// Add all counter variables from array `counterp` longread_count(void) { int t; long sum; spin_lock(&final_mutex); sum = finalcount; for_each_thread(t) if (counterp[t] != NULL) sum += *counterp[t]; spin_unlock(&final_mutex); return sum; }
// Must be called by each thread before its first use of this counter voidcount_register_thread(void) { int idx = smp_thread_id(); spin_lock(&final_mutex); counterp[idx] = &counter; spin_unlock(&final_mutex); }
// Must be called by each thread before thread exits voidcount_unregister_thread(int nthreadsexpected) { int idx = smp_thread_id(); spin_lock(&final_mutex); finalcount += counter; counterp[idx] = NULL; spin_unlock(&final_mutex); }
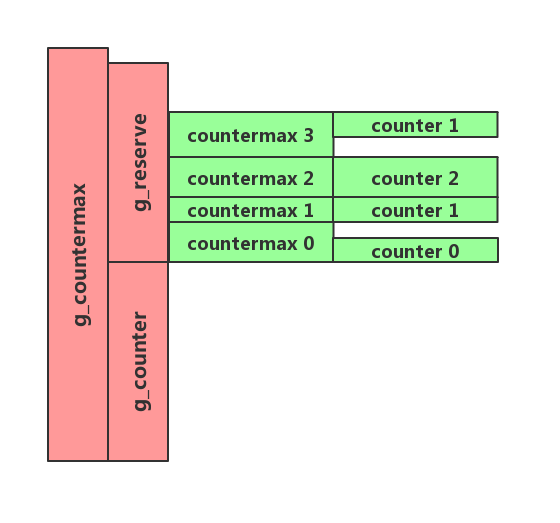
// Global variables // upper bound for number of structures unsignedlong g_countermax = 10000; // The total number of allocated structures unsignedlong g_counter = 0; // Sum of all of the per-thread countermax variables unsignedlong g_reserve = 0; // References the corresponding thread’s counter variable unsignedlong *counterp[NR_THREADS] = { NULL };
// Guards all of the global variables DEFINE_SPINLOCK(gblcnt_mutex);
/** * @brief Adds the specified value `delta` to the counter. * @return If successful, return 1. Otherwise, return 0. */ intadd_count(unsignedlong delta) { // fastpath if (countermax - counter >= delta) { // checks to see if there is room for delta on counter counter += delta; return1; } // slowpath spin_lock(&gblcnt_mutex); // Before access global variables, acquire gblcnt_mutex globalize_count(); if (g_countermax - g_counter - g_reserve < delta) { // no more room for structure spin_unlock(&gblcnt_mutex); return0; } g_counter += delta; balance_count(); spin_unlock(&gblcnt_mutex); return1; }
/** * @brief Subtracts the specified value `delta` from the counter * @return If successful, return 1. Otherwise, return 0. */ intsub_count(unsignedlong delta) { if (counter >= delta) { counter -= delta; return1; } spin_lock(&gblcnt_mutex); globalize_count(); if (g_counter < delta) { spin_unlock(&gblcnt_mutex); return0; } g_counter -= delta; balance_count(); spin_unlock(&gblcnt_mutex); return1; }
unsignedlongread_count(void) { int t; unsignedlong sum; spin_lock(&gblcnt_mutex); sum = g_counter; for_each_thread(t) if (counterp[t] != NULL) sum += *counterp[t]; spin_unlock(&gblcnt_mutex); return sum; }
/** * @brief Clear out this thread’s counter state */ staticvoidglobalize_count() { g_counter += counter; counter = 0; g_reserve -= countermax; countermax = 0; }
/** * @brief Set this thread’s countermax to re-enable the fastpath */ staticvoidbalance_count() { countermax = g_countermax - g_counter - g_reserve; countermax /= num_online_threads(); g_reserve += countermax; counter = countermax / 2; if (counter > g_counter) counter = g_counter; g_counter -= counter; }
/** * @brief Set up state for newly created threads */ voidcount_register_thread() { int idx = smp_thread_id(); spin_lock(&gblcnt_mutex); counterp[idx] = &counter; spin_unlock(&gblcnt_mutex); }
/** * @brief Tear down state for a soon-to-be-exiting thread */ voidcount_unregister_thread(int nthreadsexpected) { int idx = smp_thread_id();
atomic_t __thread ctrandmax = ATOMIC_INIT(0); // counter and countermax unsignedlong g_countermax = 10000; unsignedlong g_counter = 0; unsignedlong g_reserve = 0; atomic_t *counterp[NR_THREADS] = { NULL }; DEFINE_SPINLOCK(gblcnt_mutex); #define CM_BITS (sizeof(atomic_t) * 4) // number of bits used for counter or countermax #define MAX_COUNTERMAX ((1 << CM_BITS) - 1) // bitmask for counter or countermax
staticvoidsplit_ctrandmax_int(int cami, int *c, int *cm) { *c = (cami >> CM_BITS) & MAX_COUNTERMAX; *cm = cami & MAX_COUNTERMAX; }
/** * @brief Extract counter `c` and countermax `cm` from ctrandmax `cam` */ staticvoidsplit_ctrandmax(atomic_t *cam, int *old, int *c, int *cm) { unsignedint cami = atomic_read(cam); *old = cami; split_ctrandmax_int(cami, c, cm); }
/** * @brief Combine counter `c` and countermax `cm` to ctrandmax */ staticintmerge_ctrandmax(int c, int cm) { unsignedint cami; cami = (c << CM_BITS) | cm; return ((int)cami); }
接下来是add_count()和sub_count():
intadd_count(unsignedlong delta) { int c; int cm; int old; int new;
do { split_ctrandmax(&ctrandmax, &old, &c, &cm); if (delta > MAX_COUNTERMAX || c + delta > cm) goto slowpath; new = merge_ctrandmax(c + delta, cm); } while (atomic_cmpxchg(&ctrandmax, old, new) != old); // atomically compares ctrandmax to old, replace ctrandmax with new if success return1;
slowpath: spin_lock(&gblcnt_mutex); globalize_count(); if (g_countermax - g_counter - g_reserve < delta) { // flush all threads’ local state to the global counters flush_local_count(); if (g_countermax - g_counter - g_reserve < delta) { // no space for allocation spin_unlock(&gblcnt_mutex); return0; } } g_counter += delta; balance_count(); spin_unlock(&gblcnt_mutex); return1; }
intsub_count(unsignedlong delta) { int c; int cm; int old; int new;
do { split_ctrandmax(&ctrandmax, &old, &c, &cm); if (delta > c) goto slowpath; new = merge_ctrandmax(c - delta, cm); } while (atomic_cmpxchg(&ctrandmax, old, new) != old); return1;
unsignedlongread_count(void) { int c; int cm; int old; int t; unsignedlong sum; spin_lock(&gblcnt_mutex); sum = g_counter; for_each_thread(t) if (counterp[t] != NULL) { // get counter from ctrandmax split_ctrandmax(counterp[t], &old, &c, &cm); sum += c; } spin_unlock(&gblcnt_mutex); return sum; }
最后是最重要的flush_local_count()和其他函数:
staticvoidglobalize_count(void) { int c; int cm; int old;