Storage and Retrieval
一个数据库在最基本层面要做两件事: 将数据存入数据库, 从数据取得数据. 上一节我们讲了data model和query language, 也就是数据存入数据库的格式, 和取回数据的机制. 本章会从数据库的视角讨论几个问题: 数据库如何存储数据, 如何在用户需要时找到数据. 了解数据库内部的存储与检索机制后, 我们可以更好地选择适合应用的存储引擎.
1. Data Structures That Power Your Database
最简单的数据库可由两个Bash函数实现:
|
这两个函数实现了key-value存储, db_set key value可将key和value存入数据库中, key和value可以是任何类型, 例如: value可以是JSON文档, 调用db_get key返回最新的value, 例如:
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}' $ |
这种数据库存储格式十分简单: 一个文本文件, 每行用comma(逗号)分隔key和value. 每次调用db_set都会向文件末尾追加记录, 所以旧值不会被覆盖, 查找最新值时, 需找到key最后一次出现的位置.
$ db_set 42 '{"name":"San Francisco","attractions":["Exploratorium"]}' |
db_set函数有着很好的性能, 因为文件末尾追加写入非常高效. 许多数据库内部也使用了log(日志), 就是一个append-only(仅追加)的文件. 真正的数据库需要考虑更多问题(如并发控制, 回收磁盘空间以避免日志无限增长, 处理错误与部分写入).
另一方面, 随着数据量不断增加, db_get函数的性能也逐渐降低. 每次查询都需扫描整个数据库文件, 时间复杂度为$O(n)$, 查询时间与记录数量成正比.
为了高效查找数据库中特定key的value, 需引入一个新的数据结构: index(索引). index背后的大致思路是保存一些额外的metadata作为路标, 协助查找数据. index是从主数据衍生的额外结构, 大多数数据库允许添加和删除索引, 不会影响数据的内容, 只影响查询的性能. 维护index也会产生额外开销: 写入时不能简单地追加写入文件, 还需更新index.
这是存储系统中一个重要的权衡: index加快查询速度, 但会拖慢写入速度. 因此, 数据库不会为所有数据添加index, 需要DBA手动选择index.
1.1 Hash Indexes
让我们从key-value Data(键值数据)的index开始, key-value不是index的唯一数据类型, 但十分常见. 该key-value存储与编程语言中的dictionary(字典)相似, 字典用hash map(散列映射)或hash table(散列表)实现.
假设数据存储只是简单地在文件尾部追加写入, 那么最简单的index策略为: 在内存中维护一个的hash map, 每个key映射数据文件中的偏移量. 当写入新的key-value时, 需要更新hash map中该key的偏移量; 查找key时, 使用hash map找到数据文件中的偏移量, 并读取该位置上的值.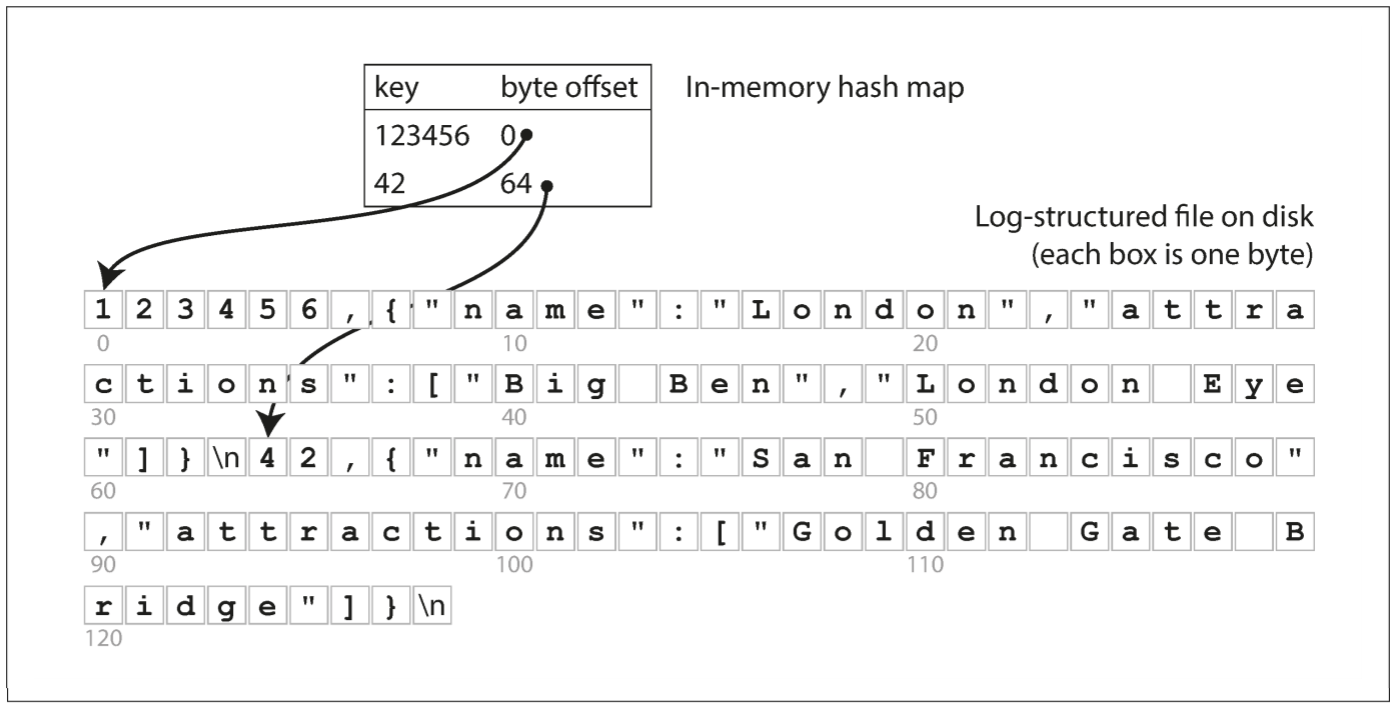
Bitcask就是这样实现的索引(Riak默认的存储引擎). Bitcask提供了高效的读取和写入, 但要求所有key都能放入内存. value可比内存更大, 只存放文件偏移量即可. 如果数据文件已经在文件系统的缓存中, 则无需磁盘I/O操作.
这种存储引擎适合频繁更新value的情况. 例如, key可以是视频的URL, value为播放次数. 这种应用场景中value会被频繁更新, 但要保证key不会太多, 保证能完全放入内存.
直到现在, 我们只追加写入一个文件, 还未讲如何避免耗尽磁盘空间. 一个好的解决方案为: 将log分为特定大小的segment(段), 当log增长到特定大小时关闭当前segment file(段文件), 并开始写入新的segment file. 之后就可对这些segment进行compaction(压缩). 压缩意味着丢弃重复的key, 只保留每个key的最新value.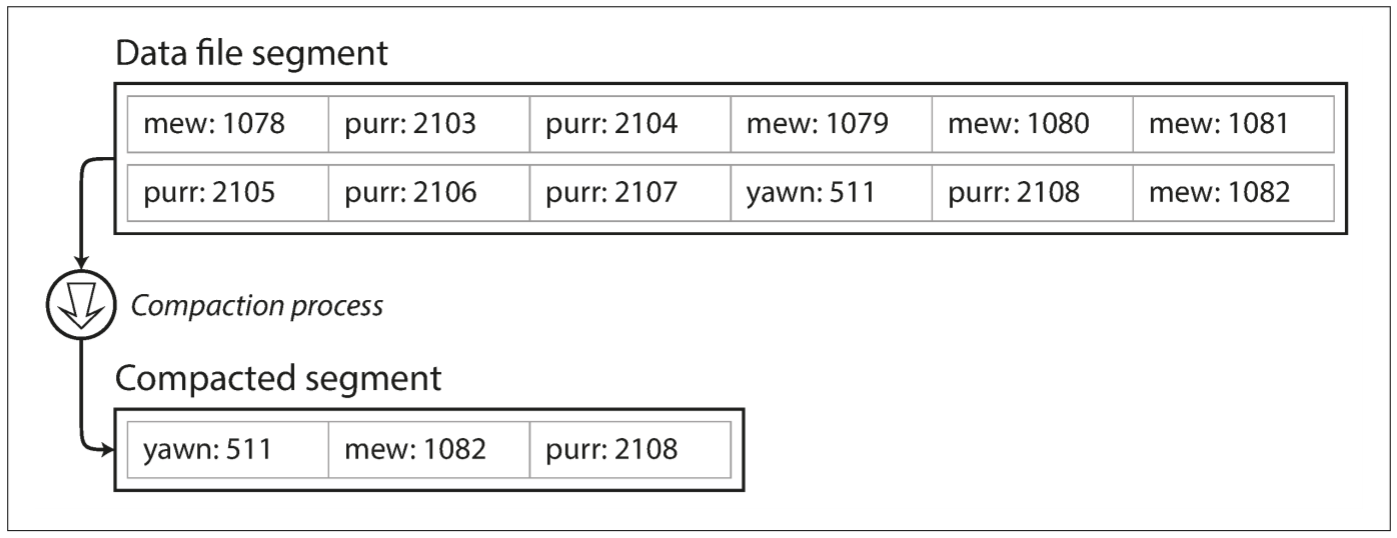
假设一个segment内key被重写多次, 那么压缩会让segment变得很小. 我们也可在压缩时将多个segment合并在一起. segment被写入后永远不会被修改, 所以合并的segment会写入一个新的文件. 压缩可以在后台执行, 用户也可以在压缩时进行读写操作. 合并过程完成后, 用户会使用新的segment, 后台也会删除旧的segment.
每个segment都有自己的hash map, key映射当前文件的偏移量. 为找到某个key的value, 需先检查最新segment的hash map; 若key不存在, 再检查第二新的segment, 以此类推. 实现中会涉及大量细节, 以下是需要考虑的问题:
- 文件格式: 二进制格式更快, 更简单, 以字节为单位对字符串的长度进行编码, 然后是原始字符串(无需转义)
- 删除文件: 若要删除某个key及其value, 可在数据文件中追加一个特殊的删除记录, 压缩时会丢弃该key和所有出现过的值
- 崩溃恢复: 数据库重启时内存中的hash map丢失. 原则上可扫描整个segment, 记录每个key的最新值来恢复hash map; 但如果segment file很大, 可能需要很长时间, 每次服务重启都很痛苦. Bitcask会将每个segment的hash map的快照存储在硬盘上, 这样可更快地加载到内存中
- 部分写入记录: 数据库可能随时崩溃, Bitcask文件包含checksum, 允许检测和忽略log中的损坏部分
- 并发控制: 由于写操作必须以严格的顺序追加到日志中, 因此常见的实现只有一个写入线程. 由于数据文件是仅追加或不可变的, 因此可被多个线程同时读取
那为何我们不覆盖旧值, 而是追加新值? 以下是设计理由:
- 追加和压缩是顺序写入操作, 比随机写入快很多
- 如果segment是不可变的, 并发和崩溃恢复会简单很多, 不必担心更新value时崩溃导致的数据污染
- 合并segment可避免数据文件随着时间推移而碎片化的问题
但hash map index也有其局限性:
- hash map必须能放入内存, 如果将hash map保存在磁盘上, 则需要大量随机访问的I/O, 而且key过多时会出现hash collision(散列冲突)
- 范围查询效率不高, 例如, 无法直接查询00000和99999之间的key, 必须单独查找每个key
1.2 SSTables and LSM-Trees
上述log-structured storage segment(日志结构存储段)都由一系列key-value pair(键值对)组成, 这些pair按写入顺序排列. 现在对segment file的格式做一个简单的修改: pair按key排序. 该格式称为Sorted String Table(排序字符串表), 简称为SSTable. 我们还需保证每个segment file中, 每个key只出现一次. 与hash map相比, SSTable有以下几个优势:
即使segment文件大于内存空间也可以合并: 类似于归并排序, 读取多个segment文件, 查看每个文件的第一个key, 将最小key写入新文件. 如果不同segment中有相同的key, 保留最新segment的value.

为了在文件中找到一个特定的key, 不需要保存内存中所有key的index. 以下图为例, 假设我们正在寻找handiwork, 虽然不知道该key的确切偏移量, 但我们知道handbag和handsome的偏移, 而且由于排序特性, 我们知道handiwork肯定在这两者之间. 可从handbag的位置扫描, 直到找到handiwork. 虽然仍需要一个内存中的index, 但可以是稀疏的: 每几千个字节的数据保留一个key就足够了, 因为几千字节很快就能扫描完.
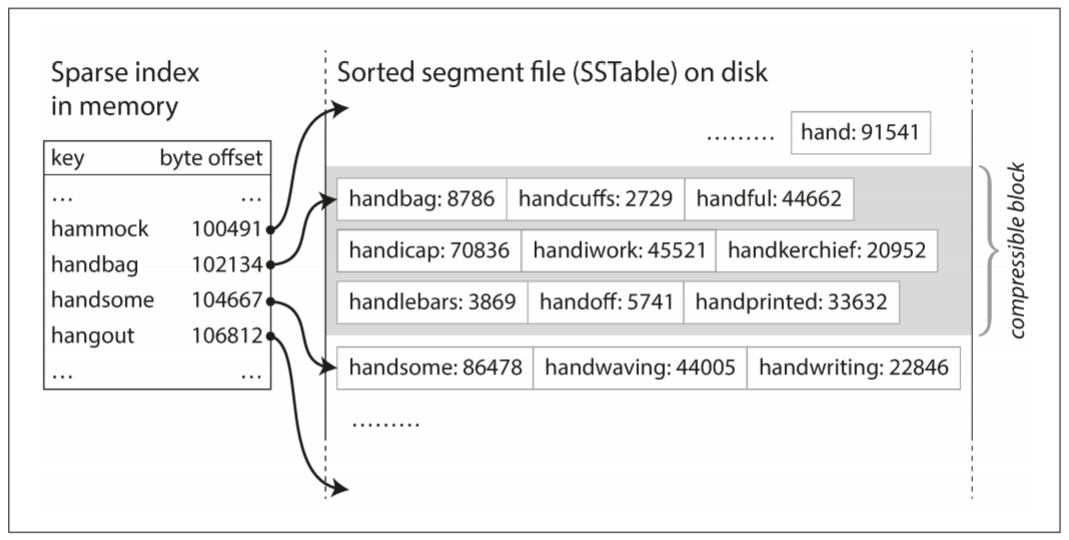
由于读取请求需要扫描一个范围内的key-value pair, 因此可将这些记录分组成block(块), 压缩并写入磁盘. 内存中的稀疏索引的每个entry都指向磁盘中的block. 除了节省磁盘空间, 压缩还可以减少I/O使用
1.2.1 Constructing and maintaining SSTables
由于写入的key-value pair可以是任意顺序, 因此需要用树形数据结构, 如red-black tree(红黑树)或AVL tree. 这样保证插入和读取都按照key排序. 存储引擎的工作步骤如下:
- 写入时, 将pair写入内存中的平衡树, 该树称为memtable(内存表)
- 当memtable大于某个阈值(通常是几兆字节)时, 将其作为SSTable文件写入磁盘. 新的SSTable成为数据库中最新的段, 并使用新的memtable
- 读取时, 首先从memtable查找, 如果没有找到key, 再从最新SSTable中查找, 以此类推
- 后台会进行合并和压缩, 丢弃重复和删除数据
该方法效果很好, 但存在一个问题: 数据库崩溃时, 内存中memtable的数据会丢失, 因此需要单独保留一个log, 写入时立即追加到log上. 该log无需按key排序, 只是为了在崩溃后恢复memtable. 当memtable写入到SSTable时可删除log.
1.2.2 Making an LSM-tree out of SSTables
上述算法被用于LevelDB和RocksDB, 这种key-value stroage engine可嵌入其他应用中. Cassandra和HBase也用到了相同的引擎, 它们都受到了Google的Bigtable论文启发.
一开始Patrick O'Neil描述了这种索引结构, 在Log-Structured Merge-Tree(LSM树)的基础上创建了这种日志结构的文件系统. 基于合并和压缩排序文件的存储引擎称为LSM storage engine.
Lucene是Elasticsearch和Solr使用的full-text search(全文搜索)的索引引擎. full-text search比key-value pair要复杂, 但思路相同的: 当用户查询某个单词时, 找到提及该单词的所有文档(网页, 产品描述等), 仍需要key-value结构实现, key为单词, value为文档的ID列表. 在Lucene中, 词汇和文档的映射保存在类似于SSTable的文件中, 根据需求在后台合并.
1.2.3 Performance optimizations
LSM存储引擎的实现设计大量细节, 例如, 当查找不存在的key时, LSM树算法会变得很慢, 因为需读取磁盘上的每个SSTable并查看, 才能确定该key不存在. 为优化此类访问, 可使用额外的Bloom filter(布隆过滤器, 可告诉引擎该key是否存在, 节省不必要的I/O操作).
SSTable的压缩和合并也有不同的策略, LevelDB和RocksDB选择的是leveled compaction(分层压缩), HBase采用按size-tiered(大小分层). 对于leveled compaction, key范围会被切分到较小的SSTable, 旧数据会被移到到单独的level(层级); 对于size-tiered compaction, 较新和较小的SSTable会被合并到较旧和较大的SSTable中.
虽然实现不同, LSM tree的基本思想相同: 保存一系列在后台合并的SSTable. 由于数据按key排序, 因此范围查找运行效率很高; 由于磁盘顺序写入, 因此支持高写入吞吐量.
1.3 B-Trees
虽然log-structured index逐渐被数据库接收, 但并不是最常见的index. B-Tree于1970年发明, 并在10年后成为主流index数据结构, 几乎所有relational database都使用该结构, 很多nonrelational database也会使用.
B-Tree和SSTable相同, 都保证pair按key排序, 因此支持键值搜索和范围搜索, 但B-Tree有完全不同的设计理念. LSM Tree将数据切分成不同的segment, 通常是几MB; B-Tree将数据分解成固定大小的page, 通常为4KB, 一次只能读取或写入一个page. 这种设计更接近底层硬件, 因为磁盘也按照固定大小的block来组织.
每个page可以用地址或位置来表示, 因此一个page可引用另一个page, 类似于指针, 但存在磁盘而不是内存, 这些引用可构建一个page tree.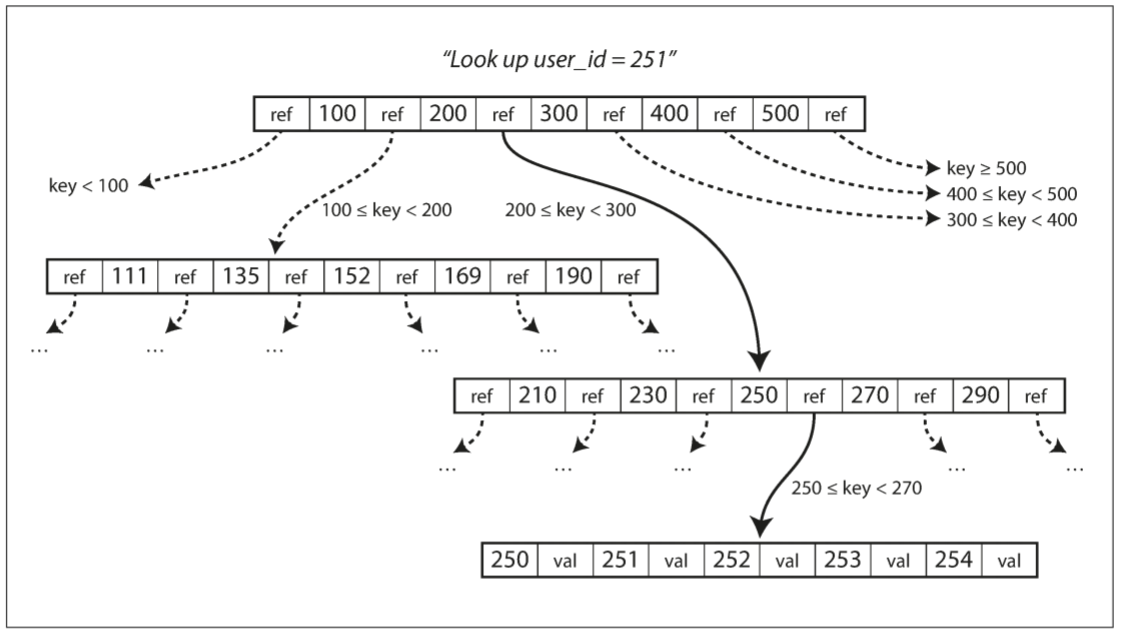
某个page会被指定为B-Tree的root, 搜索某个key时, 会从root开始, root包含几个key和对child page的引用. 每个child page都负责一段连续的key, 引用之间的key表示该引用的child page的key范围. 例如, 搜索$key = 251$, 由于key是排序的, 会选择200到300之间的child page, 以此类推, 最终到达某个包含单个key的page(leaf page, 叶子页面), 该page包含值的页面的引用.
Page对child page的引用数量称为branching factor(分支因子). 上例的分支因子为6, 实践中分支因子取决于存储page引用所需的空间和范围边界所需的空间, 通常为几百个.
如果要更新B-Tree中现有key的值, 需先找到该key的page, 修改page的值, 并写回磁盘. 如果想新添一个key-value pair, 需要先找到key对应的范围, 并添加到该page. 如果page无法容纳新的key, 则将其分为两个半满的page, 并更新父页面的key范围.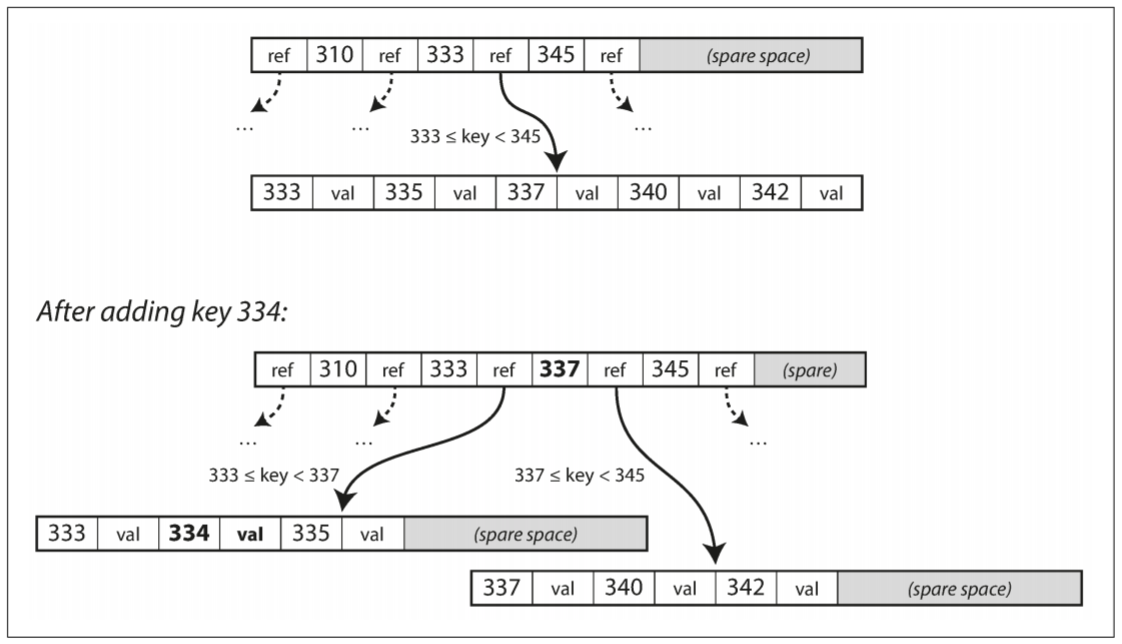
该算法可保证树维持平衡: 具有n个key的B-Tree具有$O(logn)$的深度, 大多数数据库可放入3-4层的B-Tree.(假设分支因子为500, 每个page可引用4KB, 则4级B-Tree可存储256TB的数据)
1.3.1 Making B-Trees reliable
B-Tree的写操作通过将新数据覆盖磁盘上的page, 这与log-structured index不同, 日志结构索引只在尾部附加数据, 不会修改文件. 这意味着, 每次修改都需将磁头移动到正确的位置, 并将新数据覆盖适当的扇区. 而且, 一些操作需要覆盖几个不同的page. 例如, 当插入新数据时, page的引用数量超过分支因子, 这时需要拆分成两个page, 并更新parent page对这两个child page的引用, 如果写入一个page后崩溃, 则会出现一个没有parent page的index.
为了防止崩溃导致的数据损坏, B-Tree通常会带有一个额外的数据结构: write-ahead-log(WAL, 预写式日志), 这是一个仅追加的文件, 每个B-Tree的修改都需要先写入到日志中. 该日志用于数据库崩溃后的恢复.
更新页面的另一个情况是, 若两个线程同时访问B-tree, 则需要并发控制, 每个线程看到的B-Tree可能处于不同状态. 通常使用latches(轻量级锁)保护树的数据结构, log-structured index则没有这样的烦恼, 因为合并在后台进行, 不影响查询操作, 并时不时将旧的segment交换为新的segment.
1.3.2 B-Tree optimizations
B-Tree存在了很久, 期间经历了很多次优化, 以下是几个例子:
- 一些数据库没有使用WAL, 而使用copy-on-write模式作为崩溃后恢复的工具. 修改的页面被写入到不同的位置, 并创建新版本的父页面, 以指向新的位置.
- 通常不存储整个键, 而是缩小其大小来节省page空间, key只需要充当键范围的边界. 页面包含更多的键可让树拥有更大的分支因子, 从而减少层级
- 通常, page可以放在磁盘上的任意位置, 但范围查询需要一个个查找磁盘页面. 因此, 很多B-Tree尝试将树铺平, 使得leaf page按顺序出现在磁盘上. 但随着数据增加, 很难维持该顺序. 相比之下, LSM Tree合并时会重写大部分存储空间, 因此可以尽量保证key顺序排列.
- 树中可存在额外的引用. 例如, leaf page会保留左右两个sibling page的引用.
- B-Tree有很多变种, 例如fractal tree, 借鉴了log-structured思路来减少磁盘寻道次数.
1.4 Comparing B-Trees and LSM-Trees
尽管B-Tree的实现比LSM-tree更成成熟, 但LSM-tree具有特殊的性能特点. 通常LSM-tree的写入更快, 而B-Tree的读取更快. LSM-tree的读取通常比较慢, 因为需要检查不同数据结构和不同压缩层级的SSTables.
1.4.1 Advantage of LSM-trees
B-tree index中的每块数据都至少写入两次: 一次write-ahead log, 一次tree page. 即使只更新page中几个字节, 也需要重写整个page. 有些存储引擎会覆写同一page两次, 以免电源故障导致的page部分更新.
由于需要压缩和合并SSTables, log-structured index也会多次重写数据. 在数据库的生命周期中每次写入数据都需要多次写入磁盘, 被称为write amplication(写放大). 尤为需要注意SSD, 其写入次数有限.
对于写入繁重的应用, 性能瓶颈可能是磁盘写入速度. 此时write amplification会导致直接的性能代价: 存储引擎写入磁盘的次数越多, 有限的磁盘带宽内每秒写入次数越少.
LSM-tree能比B-tree拥有更高的写入吞吐量, 是因为其具有较低的write amplification, 而且其采用顺序写入, 而不是覆盖树的某几个page. 对于磁性硬盘驱动器, 顺序写入比随机写入快得多.
LSM-tree支持更好的压缩数据, 因此产生的文件比B-tree更小. B-tree的存储引擎会由于fragmentation(碎片化)而留下一些未使用的磁盘空间: 当page被拆分或数据过大而不能放入当前page时, page中的某些空间不会被使用. 由于LSM-tree不是面向page的, 并且会定期重写SSTable以消除碎片, 因此其拥有较低的存储开销, 尤其是使用leveled compaction(分级压缩).
很多SSD的固件内部使用log-structured算法, 以将随机写入转换为底层存储芯片上的顺序写入, 因此存储引擎的写入模式对其影响并不大. 但较低的write amplification和更少的碎片化对SSD仍是有利的: 在有限的I/O带宽中, 数据越紧凑, 单位时间内读取和写入数据的次数更多.
1.4.2 Downside of LSM-tree
Log-structured storage的缺点在于: 压缩过程有时会干扰正在进行的读写操作. 尽管很多存储引擎尝试以增量的方式执行压缩, 避免影响并发访问. 但磁盘资源有限, 很容易导致其他请求等待磁盘执行昂贵的压缩操作. 对于吞吐量和平均响应时间的影响很小, 但高percentile(响应时间从低到高, 快于某个百分比的响应时间)有时会很长, B-tree的行为则更具有可预测性.
压缩的另一个问题出现在高写入吞吐量时: 初始写入(记录和刷新memtable到磁盘)和后台运行的压缩线程共享有限的磁盘写入带宽. 空数据库时写入时可使用全部磁盘带宽, 但数据库越大, 压缩线程占用的磁盘带宽越多.
如果写入吞吐量很高, 压缩也没有仔细配置, 压缩可能跟不上写入速率. 此时磁盘未合并的segment数量不断增加, 直到磁盘空间耗尽; 读取速度也会从此变慢, 因为需要查找更多的segment文件.
B-tree还有一个优点: 每个key在index中只出现一次, 而log-structured的存储引擎可能在不同的segment中有相同key的多个副本. 这使得B-tree可以提供强大的事务语义: 在许多关系数据库中, 事务隔离通过在key范围上使用锁来实现, 在B-tree的index中, 这些锁可以直接附加在树上.
B-tree在数据库结构体系中非常根深蒂固, 拥有稳定的性能, 因此不可能很快被替代. 在新的数据存储中, log-structured index变得越来越流行. 现在无法确定哪种类型的存储引擎更好, 需要通过一些测试来验证.
1.5 Other Indexing Structures
目前为止, 我们只讨论了key-value index, 类似于relational model中的primary key(主键)index. 主键可唯一标识table中某一行, 文档数据库中的某个文档, 或图形数据库中的某个顶点. 数据库的其他记录可通过主键引用其他行, index被用于解析这类索引.
Secondary index(次级索引)也很常见. 在关系数据库中, 可使用CREATE INDEX命令在同一个table上创建多个次级索引, 让join操作更快.
次级索引可从key-value index构建. 但区别在于key无需唯一, 即多行(文档, 顶点)可拥有相同的key值. 可通过以下两种方式实现:
- 将行匹配符的列表作为index的value(就像full-text index中的posting list, 文档中的每个单词度对应一个发布列表)
- 向每个key添加行标识符使得key唯一
1.5.1 Storing values within the index
Index中的key是查询要搜索的内容, 其值有两种情况:
- 实际行, 文档, 顶点
- 对其他行的引用
第二种情况中, 行存储的地方称为heap file(堆文件), 行存储没有特定的顺序(数据可以附加在尾部, 也可以放在被删除行的位置). 堆文件很常见, 因为其可以避免多个次级索引有相同的数据副本: 每个索引只引用堆文件中的一个位置, 实际数据保存在一个地方.
在不修改key的情况下更新值时, 堆文件可以非常高效: 只要新值不大于旧值, 就可以覆盖该记录; 如果新值大于旧值, 则情况比较复杂, 因为需要将其移到堆中的其他位置. 此时, 要么所有index都指向记录的新位置, 或在原位置留下一个转发指针.
某些情况下, 从index到堆文件的额外跳跃对读取性能影响很大, 因此需要将行直接放入index里, 被称为clustered index(聚簇索引). 举个例子, MySQL的InnoDB存储引擎会将table的primary key作为聚簇索引, 次级索引则引用primary key(而不是堆文件的位置). SQL Server中可指定table的聚簇索引.
聚簇索引和非聚簇索引之间的折衷被称为index with included columns(包含列的索引), 或称为covering index(覆盖索引), 会将table的一部分column保存在index内. 使得查询只在index内运行(无需额外的跳转).
聚簇索引和覆盖索引提高了读取速度, 但需要额外的存储空间, 且增加写入开销. 数据库还需为实现事务增加开销, 因为重复数据可能导致不一致.
1.5.2 Multi-column indexes
至今为止, index只是将一个key映射到一个value, 如果我们需要同时查询一个table中的多个column(或文档中的多个field), 这显然是不够的.
最常见的multi-column index(多列索引)为concatenated index(连接索引), 其会将一列的值追加到另一列后面, 让多个字段组成一个key(index定义指定了字段的连接顺序). 以电话薄为例, 其提供了一个从姓, 名到电话号码的index. 由于排序, index可用于查找特定姓氏的人, 或所有具有特定姓氏-姓名组合的人. 然而, 如果想找特定名字的人, 则无法使用该index.
Multi-dimensional index(多维索引)是一种查询多个列的普遍方式, 对于地理空间数据更为重要. 例如, 餐厅搜索网站可能有一个数据库, 其中包含每个餐厅的经度和纬度. 当用户在地图上查看餐厅时, 网站需要查询矩阵地图内的所有餐厅, 如下:
SELECT * FROM restaurants WHERE latitude > 51.4946 AND latitude < 51.5079 |
标准B-tree或LSM-tree index不能快速处理这种查询: 他可以返回某个纬度或经度范围内的所有餐厅, 但不能同时满足两个条件.
另一种选择是使用space-filling curve(空间填充曲线)将二维位置转换为单个数字, 然后使用B-tree index. 或使用特殊的spatial index, 如R-tree. 例如, PostGIS使用PostgreSQL的通用Gist工具将地理空间索引实现为R-tree. 多维索引不光用于地理位置, 电商网站可使用多维索引来搜索特定颜色范围内的产品, 也可在天气观察数据库中建立多维索引, 以便查询特定温度和湿度下的所有资料.
1.5.3 Full-text search fuzzy indexes
目前为止, 索引假设用户查询确切的数据, 并允许查询确切的key或具有排列顺序的key范围, 但不允许用户查询类似的key, 如拼写错误的单词. 全文搜索引擎通常允许搜索一个单词, 以及该词的同义词, 忽略该词的语法变种, 并搜索同一文档中相互靠近的词, 并支持其他功能.
Lucene使用一个类似于SSTable的结构作为词典, 该结构要求内存中的索引, 负责告知查询在排序文件中的哪个偏移量查找key. 在LevelDB中, 内存中的index是一些key的散列集合, 但在Lucene中, 内存中的index是key中字符的finite state automation(有限状态自动机), 类似以trie(字典树). 该自动机可转换为Levenshtein automation, 支持一定编辑距离内的单词搜索.
1.5.4 Keeping everything in memory
目前为止, 所讨论的数据结构都为了应对磁盘限制. 与内存相比, 磁盘处理起来更麻烦. 对于磁盘和SSD, 如果想要很好的读取性能, 需要仔细斟酌如何放置数据. 之所以我们忍受这些缺点, 主要因为两点:
- 磁盘拥有持久性, 电源关闭后数据不会丢失
- 磁盘每GB的成本比RAM低
随着RAM越来越便宜, 数据不多的应用可选择将数据全部放在内存中, 并分布在多个机器中, 导致内存数据库的崛起.
内存中的key-value store, 例如Memcached, 仅用于缓存, 需要允许电源故障时丢失数据. 但也有内存数据库具有持久性, 通过特殊硬件实现(电源供电的RAM), 也可以将日志写入磁盘, 定时将快照写入磁盘, 或将内存中的状态复制到其他机器上.
VoltDB, MemSQL和Oracle TimesTen等产品都是具有关系模型的内存数据库, 厂商声称, 由于摆脱了磁盘的开销, 数据库有非常高的性能提升. RAM Cloud是一个具有持久性的, 开源的内存key-value store(使用log-structured方式让数据保存在磁盘中), Redis和CouchBase通过异步写入磁盘提供弱持久性.
与直觉相反, 内存数据库的巨大性能提升并不是因为摒弃了磁盘读取. 即使是基于磁盘的存储引擎, 有足够的内存时也无需从磁盘读取, 因为操作系统会缓存最近读取的数据. 相反, 内存数据库更快的原因在于省去了将内存数据结构编码为硬盘数据结构的过程.
除了性能, 内存数据库的另一个应用领域是提供基于硬盘的index很难实现的数据模型, 例如, Redis会为各种数据结构(如优先队列和集合)提供了类似数据库的接口, 因为其将所有数据保存在内存中, 实现相对简单.
内存数据库可支持比内存还大的数据集, 不必重新采用以磁盘为中心的体系结构. Anti-caching(返缓存)方法在内存不足的情况下, 会将最近最少使用的数据从内存转移到磁盘, 并在将来再次访问时重新加载到内存中. 这与操作系统的虚拟内存和交换文件类似, 但数据库可以比操作系统更有效地管理内存, 因为数据库的粒度为单个记录, 而不是整个内存页面. 尽管如此, 这种方法仍需要内存能放下整个index.
2. Transaction Processing or Analytics
在业务数据处理早期, 数据库的写入与commercial transaction(商业交易)相关: 销售, 向供应商下单, 支付工资等. 随着数据库拓展到不涉及金钱交易的领域, 术语transaction也被保留, 指代一组读写操作构成的逻辑单元.
即使数据库被用于不同类型的数据, 例如博客评论, 游戏动作, 地址簿的联系人, 其基本访问模式与商务交易没太大区别. 应用通常使用index通过某个key查找一小部分record(记录). 用户输入作为reord被插入或更新. 由于应用是interactive(互动的), 其访问模式也称为online transaction processing(OLTP, 在线事务处理).
然而, 数据库也逐渐用于data analytics(数据分析), 其拥有完全不同的访问模式. 通常分析查询需要扫描大量record, 只读取record中的几列, 并计算aggregate statistic(汇总统计, 如count, sum, average), 而不是将原始数据返还给用户. 假设数据为销售交易表, 那么分析查询可能如下:
- 每个店在一月份的总销售额
- 最近的促销中, 香蕉卖了多少
- 哪个品牌的婴儿食品最常和哪个品牌的尿布一起买
这种查询由业务分析师编写, 提供给公司管理层做决策. 这种数据库的事务处理模式称为Online Analytice processing(OLAP, 在线分析处理).
| Property | OLTP | OLAP |
|---|---|---|
| read pattern | 按key查询少量record | 在大量record上聚合 |
| write pattern | 随机访问, 要求低延迟写入 | 批量导入(ETL)或事件流 |
| used by | 终端用户, 通过Web应用 | 内部数据分析师, 用于决策支持 |
| What data represents | 数据的最新状态(当前时间点) | 历史事件 |
| Dataset size | GB - TB | TB - PB |
起初, 事务处理和分析查询使用一样的数据库, SQL也可以灵活地应对两种类型的需求. 然而, 20世纪80年代末和90年代初期, 一些公司开始停用OLAP系统进行数据分析, 而在单独的数据库上运行分析, 这类数据库称为data warehouse.
2.1 Data Warehousing
一个企业可以有几十个不同的交易处理系统: 面向用户的网站, 实体店的收银系统, 库存的跟踪商品, 规划车辆路线, 供应商管理, 员工管理等. 这些系统都非常复杂, 需要专门团队维护.
这些OLTP系统往往对业务运行至关重要, 因而要求高可用性和低延迟, 因此DBA不愿让业务分析人员在OLTP数据库上运行分析查询, 这些查询通常开销很大, 会扫描大量数据, 从而减慢正在运行的事务.
相比之下, 数据仓库是一个独立的数据库, 分析人员可以查询所需数据而不影响OLTP操作. 数据仓库提供OLTP系统中所有的只读数据副本, 从OLTP数据库中提取数据(定期转储或持续更新), 转换为适合分析的模式, 清理并加载到数据仓库中, 上述过程称为Extract-Transform-Load(ETL, 抽取-转换-加载).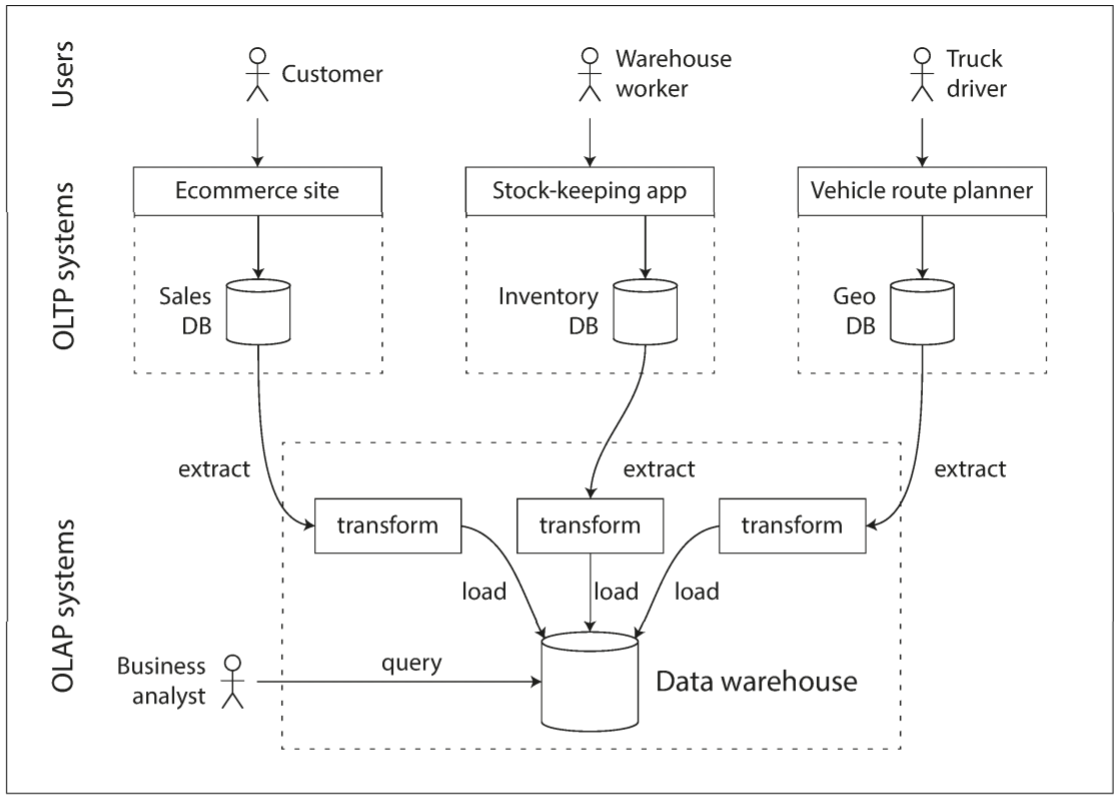
几乎所有大型企业都有数据仓库, 但小型企业则很少使用, 这可能因为大多数小企业没有这么多不同的OLTP系统, 数据也比较少, 因此可以在传统SQL数据库中查询, 甚至在表格中分析. 使用单独的数据仓库, 而不是直接查询OLTP系统进行分析师数据仓库针对分析访问模式的优化.
2.1.1 The Divergence between OLTP dataabses and data warehouses
数据仓库的数据模型通常是关系型, 因为SQL很适合分析查询. 目前有很多图形数据分析工具, 可以生成SQL查询, 可视化结果, 并允许分析人员探索数据(下钻, 切片和切块).
从表面看, 数据仓库和OLTP数据库很类似, 都提供SQL接口. 但它们内部实现可能完全不同, 因为它们针对不同的查询模式进行了不同优化. 大多数数据库供应商只会专注于事务处理或分析工作中的一种.
一些数据库(如Microsoft SQL Server和SAP NAHA)支持在同一产品中进行事务处理和数据仓库, 但其实它们拥有两个独立的存储和查询引擎, 只是共同使用一个通用的SQL接口访问.
Teradata, Vertica, SAP HANA和ParAccel等数据仓库供应商通过销售昂贵的商业许可证让用户使用他们的系统. Amazon RedShift是ParAccel的托管版本. 最近大量开源的SQL-on-Hadoop项目出现, 与商业数据仓库系统竞争, 包括Apache Hive, Spark SQL, Cloudera Impala, Facebook Presto, Apache Tajo和Apache Drill.
2.2 Stars and Snowflakes: Schemas for Analytics
根据应用程序的需求, 事务处理中会使用大量不同的data model(数据模型). 但对于分析业务, 数据模型的种类会少很多. 很多数据仓库会以公式化的方式使用, 称为star schema(星型模式).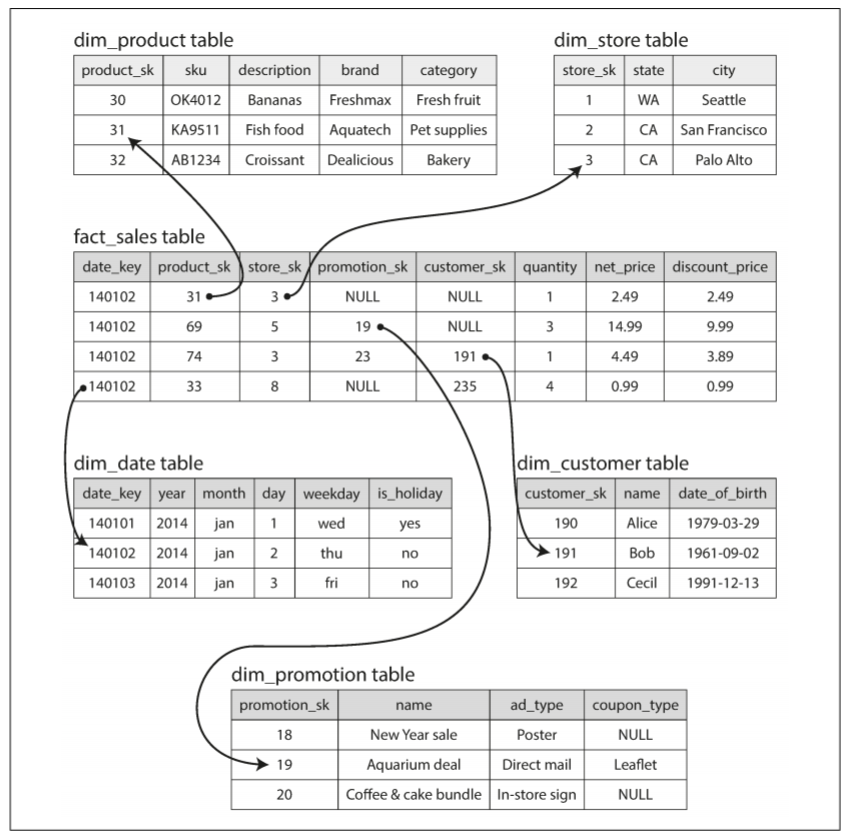
上图为食品零售商的数据仓库. 模型的中央是一个fact table(事实表, 本例中为fact_sales). 事实表的每一行表示发生在某个时间点的事件(本例中, 每一行表示客户购买的一个产品). 如果分析的是网站流量, 那么每一行可表示一个用户的页面浏览或点击.
通常来说, fact被视作一系列单独事件, 因为这样可以在以后的分析中获得最大灵活度. 但这意味着事实表可以非常大. 像是Apple, Walmart, 或eBay会有几十PB的交易记录 其中大部分保存在事实表中.
事实表中的一些列称为attribute, 例如, 产品销售的价格和从供应商购买的成本(可用于计算利润). 事实表中其他列是对其他表的foreign key(外键)引用, 称为dimension table(维度表). 由于事实表中的每一行都表示一个事件, 因此这些维度代表了事件的对象, 内容, 地点, 时间, 方式和原因.
例如, 上图中其中一个维度是已售出的产品, dim_product表中的每一行表示一种代售产品, 包括SKU(库存单元), 产品描述, 品牌名称, 类别, 脂肪含量, 包装尺寸等. fact_sales表中的每一行都使用外键表明在特定交易中的销售了哪些产品(如果客户一次购买多个产品, 事实表将包含多行, 每一行表示一个产品).
日期和时间也可使用维度表表示, 通过对日期的附加信息(例如假期)进行编码, 可区分假期或非假期的销售查询.
Star schema这一名字来源于表关系的可视图: 事实表在中央, 被维度表包围, 表的连接就像星星的光芒.
还有一种该模式的变种称为snowflake schema(雪花模式), dimension被进一步拆分为subdimension(子维度). 例如, brand(品牌)和category(产品种类)可能有单独的表格, dim_product表中的每一行会将brand和category作为外键引用, 而不是将它们作为字符串保存在dim_product表中. 雪花模式比星形模式更规范化, 但一般首选星形模式, 使用更简单.
数据仓库中table通常会非常宽, 事实表通常有100列以上, 甚至几百列. 维度表也可以非常宽, 因为其包含与所有可能与分析相关的元数据. 例如, dim_store表可以包括每个商店提供了哪些服务, 是否具有店内面包房, 店面面积, 商店第一次开张的日期, 最近一次装修时间, 离最近高速公路的距离等.
3. Column-Oriented Storage
如果事实表有万亿行和PB级别的数据, 如何高效存储和查询就成了一个具有挑战性的问题. 维度表通常小很多(几百万行), 因此主要关注事实表的存储.
尽管事实表通常超过一百多列, 但每次查询通常只会访问其中四五个列(SELECT *在分析中很少使用). 下面为查询2013年内人们是否倾向于在一周中的某一天购买水果或糖果:
SELECT |
上述查询只访问了事实表中的三列: date_key, product_sk, quantity, 剩下的列都被忽略.
绝大多数OLTP数据库, 存储都是row-oriented(面向行)放置: 表中每一行相邻存储. 文档数据库也是相似的, 整个文档通常作为一个连续的字节序列.
为了处理上述查询, 可为fact_sales.date_key和fact_sales.product_sk添加index, 告诉存储引擎去哪里查询特定日期或特定产品的销售额. 然而, 面向行的存储引擎仍需从磁盘中加载整个行(每行包含100多个属性), 解析, 并过滤掉不需要的属性. 这需要很长时间.
column-oriented storage(面向列的存储)想法很简单: 不要将一整行数据放在一起, 而是将一列的所有值放在一起. 如果每列存储在单独文件中, 查询只需要读取和解析所需的列, 可节省大量工作, 原理如下图: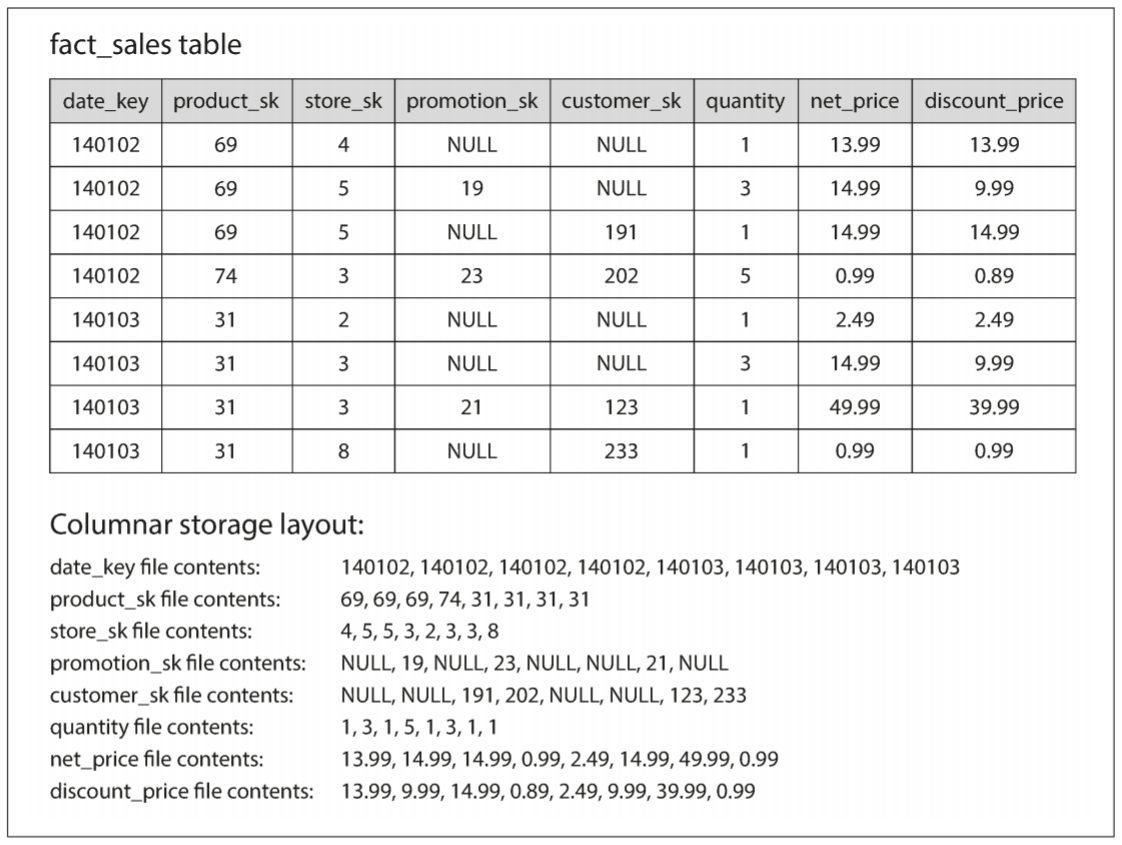
面向列的存储要求每个列文件中的行顺序相同. 因此, 如果需要重组行, 则需要获得每个列文件中的改行属性, 并放在一起形成一个新的行.
3.1 Column Compression
查询除了需要从磁盘中取出列, 还需通过压缩数据来减少对磁盘吞吐量的需求. 幸运的是, 面向列的存储很适合压缩.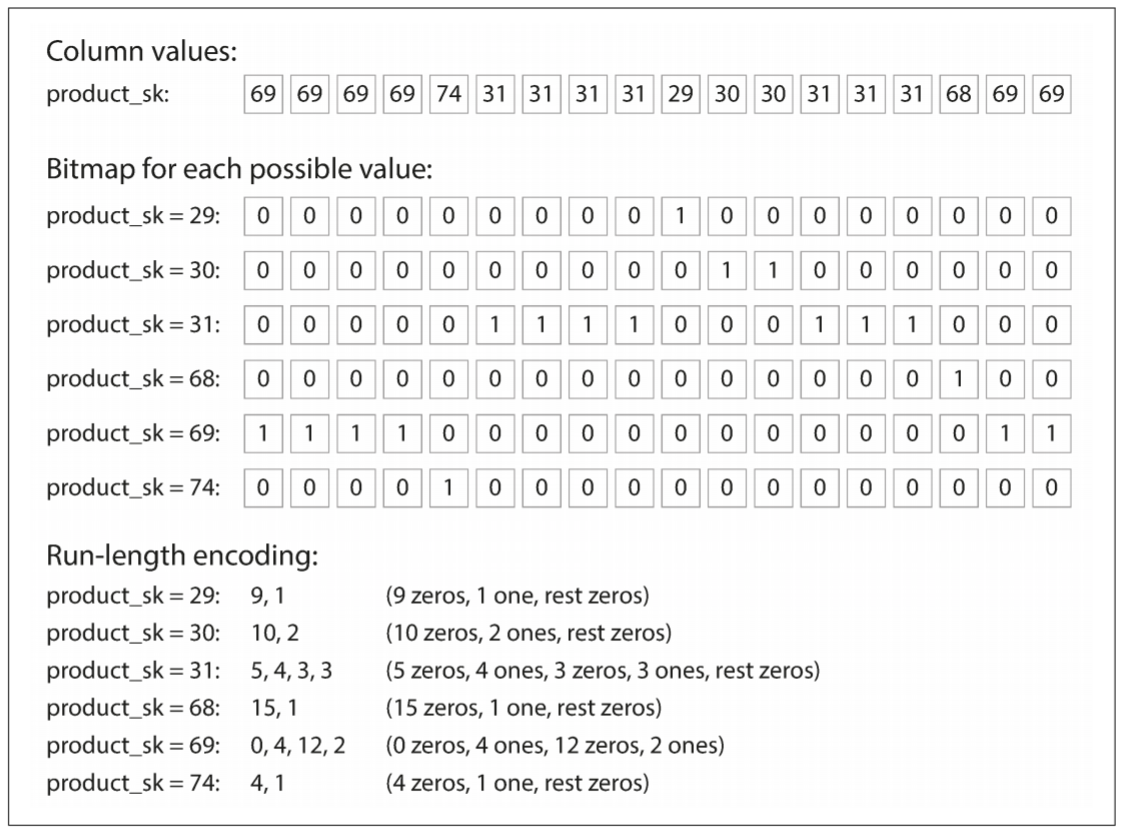
以上图为例, 列值存在大量重复, 很适合压缩. 压缩方式的选择取决列中的数据. 上图的数据很适合bitmap encoding(位图编码). 通常情况下, 值的种类数量比行数少很多(零售商可能有数十亿的销售交易, 但只有100,000个产品). 假设我们有n个不同的值, 可将其转换为n个独立的bitmap(位图): 每个bitmap表示一个值, 每行对应一个bit位. bit为1表示该行具有该值, 0则没有该值.
如果n非常小(例如, 国家/地区的列表只有200多个不同值), 则bitmap可将每行保存为一个bit位. 但如果n更大, bitmap中将会有很多0. 这种情况下, bitmap可以进行run-length encoded(游程编码), 让编码更紧凑.
Bitmap index很适合数据仓库中的各种查询, 例如:
WHERE product_sk IN(30,68,69) |
加载product_sk = 30, product_sk = 68, product_sk = 69这三个bitmap, 并计算三个bitmap的bitwise OR(按位或).
WHERE product_sk = 31 AND store_sk = 3 |
加载product_sk = 31和store_sk = 3的bitmap, 并计算bitwise AND(按位和). 之所以可以这么做, 因为每一列的行顺序是相同的, 因此某一列的bitmap的第k位和另一列的bitmap的第k位对应相同的行.
3.1.1 Memory bandwidth and vectorized processing
对于需要扫描数百万行的数据仓库查询, 将数据从磁盘加载到内存是一个巨大瓶颈. 然而, 这并不是唯一瓶颈. 分析型数据库的开发者还需考虑如何利用从内存到CPU cache的带宽, 如何避免CPU指令处理流水线的分支错误预判, 以及在现代CPU中如何使用single-instruction-multi-data(单指令多数据, SIMD)指令.
除了避免从磁盘加载数据, 面向列的存储布局还可有效利用CPU周期. 例如, 查询引擎可将大量压缩的列数据放入CPU的L1 cache, 并在循环中遍历; 相比每个记录都需要调用大量函数和条件判断代码, CPU执行一个循环更快. 列压缩允许列中更多行加载到L1 cache中. AND和OR运算符也可直接在压缩的列数据块上执行, 这种技术称为vectoized processing(矢量化处理).
3.2 Sort Order in Column Storage
列存储中, 行的存储顺序并不重要. 最简单的方法是按照插入顺序存储, 每次插入只需要将新行追加在列文件尾部. 但我们也可以指定顺序, 就像SSTable. 并将此作为一种索引机制.
每一列单独排序是没有意义的, 因为这样就无法知道不同列的值是否属于同一行. 由于我们需要让某一列的第k个值与另一列的第k值属于同一行, 因此必须以行为单元进行排序.
虽然数据按照列存储, 但仍需按行排序. DBA可根据常用的查询语句来选择被排序的列. 例如, 查询经常搜索一个日期范围, 如上一个月, 可将date_key作为第一个排序键, 查询优化器只需要扫描上个月的行, 比扫描所有行要快很多.
当第一个排序键的值相同时, 第二个排序键可决定排序顺序. 若date_key是第一个排序键, 可将product_sk作为第二个排序键, 这样所有同日同产品的销量存储在一起, 有利于对特定日期范围内按产品对销售进行分组或过滤的查询.
排序的另一个好处是列压缩. 如果排序键存在很多相同值, 那么排序后将拥有很多连续的相同序列. 即使table有数十亿行, 游程编码也可将列压缩到几千字节.
第一个排序键是最容易压缩的. 第二和第三排序键更混乱, 不会有很多重复值. 排序优先级低的列, 更容易以随机顺序出现, 因此不容易压缩; 但对排序优先级高的列进行压缩十分有用.
3.2.1 Several different sort orders
C-Store中引入了对键的排序, 并在商业数据仓库Vertica中被采用. 不同排序有利于不同的查询, 所以为什么不让相同的数据以不同顺序排序呢. 数据可以复制到多个机器上, 因此一个机器的崩溃不会导致数据丢失. 当面对处理查询时, 可从不同排序的数据中选择最合适的版本.
面向列的存储中有多个排序顺序, 类似于面向行的存储中有多个次级索引. 区别在于, 面向行的存储将每一个行保存在一个地方(堆文件或聚簇索引中), 次级索引只包含指向行的指针; 面向列的存储中没有任何指向数据的指针, 只有包含值的列.
3.3 Writing to Column-Oriented Storage
由于分析人员通常只运行只读查询, 因此上述优化是有意义的. 面向列存储, 压缩, 和排序都有利于快速查询. 但缺点在于, 这些优化让写入变得很困难.
B-tree的update-in-place(就地更新)对于压缩的列是不可能的. 在排序表中插入一行就要重写所有列文件. 由于行由列的位置标识, 因此插入行需要对所有列进行一致性更新.
幸运的是, LSM-Tree可以解决这个问题. 所有的写操作先经过内存存储, 其维护一个已排序的结构, 并准备写入磁盘. 内存中的存储是面向行还是面向列并不重要. 当积累了足够的写入数据时, 其会与磁盘上的列文件合并, 并批量写入新文件.
查询操作需要检查两个地方: 磁盘的列文件和最近内存中的写入. 然而查询优化器会向用户隐藏细节. 从分析师的角度, 插入, 更新或删除操作会立刻反映在后续查询中.
3.4 Aggregation: Data Cubes and Materialized Views
并不是每个数据仓库都必须是列存储: 也能使用传统的面向行的数据库和其他架构. 然而, 面向列的存储可显著提高分析分析查询速度, 因此该模式很普遍.
数据仓库的另一个注意点为materialized aggregate(物化汇总). 数据仓库的查询通常会涉及一些聚合函数, 如SQL中的COUNT, SUM, AVG, MIN或MAX. 如果某些聚合被很多查询使用, 可缓存一些频繁使用的COUNT和SUM.
创建缓存的一种方式为materialized view(物化视图). 在关系数据模型中, 其会被定义为一个虚拟视图(一个类似于表的对象, 内容是一些查询的结果). 不同的是, 物化视图是查询结果的实际副本, 会被写入磁盘; 从虚拟视图读取时, SQL引擎会其展开到视图的底层查询中, 并处理展开的查询.
当底层数据发生变化时, 物化视图也需要更新, 因为它是数据的非规范化副本. 数据库会自动执行, 也导致更新的开销更大, 这也是为什么OLTP数据库不怎么使用物化视图. 对于读取繁重的数据仓库, 这种做法更有意义.
物化视图的常见案例为data cube(数据立方体)或OLAP cube(OLAP立方体). 它是按不同维度分组的聚合网格: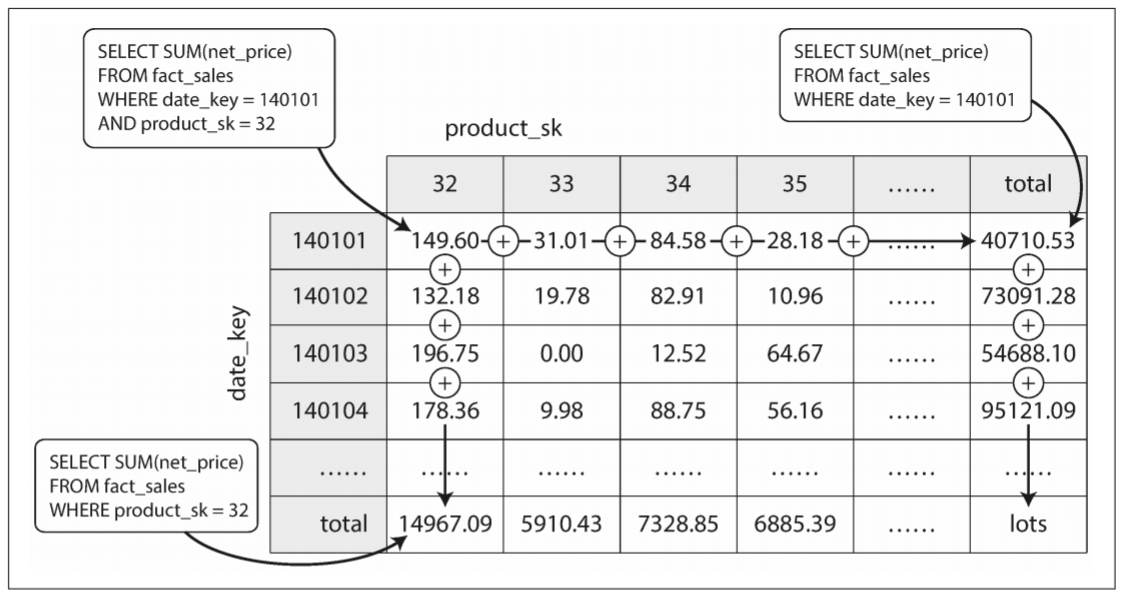
现在每个fact都只有两个二维表的外键, 上图中分别为date和product. 你可以绘制一个二维表, 一条轴上是日期, 另一条轴上是产品. 每个单元格包含具有date-product组合的所有fact属性(例如net_price)的聚合(例如SUM). 然后沿着行或列应用相同的聚合, 从而获得减少一维后的汇总(某个产品所有日期的销售额, 或某个日期所有产品的销售额).
一般来说, fact会有两个以上的维度. 假设存在五个维度: date, product, store, promotion, customer. 很难想象一个五维超立方体是什么样的, 但原理一样: 每个单元格是包含特定date-product-store-promotion-customer组合的销售额. 这些值可在每个维度上重复汇总.
数据立方体的优点在于某些查询非常快, 因为结果已被预先计算好. 例如, 我们想知道每个店的总销量, 则只需查看相对应维度的汇总, 无需扫描数百万行的原始数据; 其缺点则在于查询原始数据不灵活. 例如, 我们无法查询成本高于100美金的商品所占销售比, 因为价格不是其中的一个维度. 因此, 大多数数据仓库会尽量保留原始数据, 并将聚合数据(如数据立方体)作为提升查询性能的手段.