Relational Model Versus Document Mode
Data model(数据模型)或许是构建软件最重要的部分, 因为它们有很深远的影响: 不仅影响软件的编写, 还影响我们思考问题的方式. 绝大多数应用会将数据模型叠加在一起, 对于每一层模型, 问题在于如何用低一层的模型来表示:
- 作为一个应用开发者, 可以观察现实世界(人员, 组织, 货物, 行为, 资金流向, 传感器等), 并使用对象或数据结构, 和操作数据结构的API来建模. 这些结构通常特定于你的应用.
- 当需要存储数据结构时, 可用通用数据模型表示, 例如JSON或XML文档, 关系数据库的table或graph模型.
- 数据库工程师选择如何以字节的方式在内存, 磁盘, 或网络中表示JSON/XML/关系/图数据. 这种表现形式使得数据可以被查询, 搜索, 操纵, 处理.
- 底层上, 硬件工程师需要考虑如何用电流, 光脉冲, 磁场或其他东西来表示字节.
一个复杂的应用程序会有很多中间层, 如基于API的API, 不过基本思想是一样的: 每一层通过提供一个明确的数据模型来隐藏低一层的复杂性. 这种抽象允许不同的人能一起协作, 例如: 数据库厂商的工程师和使用数据库的程序开发人员.
数据模型种类繁多, 每个数据模型都有自己的设计思路. 有些用法很简单, 有些用法则很复杂; 有些操作快, 有些则很慢; 有些数据转换很自然, 有些很复杂. 掌握一个数据模型需花费很多精力, 即使无需考虑数据模型内部的工作机制, 且只使用一个数据模型, 构建软件也非常困难. 然而, 由于数据模式决定了软件的功能(能做什么, 不能做什么), 因此选择一个合适的数据模型十分重要.
1. Relational Model Versus Document Model
最知名的数据结构可能是SQL, 由Edgar Codd在1970年提出: 数据被组织为relation(关系, SQL中称为table), 每个relation由无序的tuple(元组, SQL中称为row)集合组成. Relation model被提出时很多人质疑能否有效地实现该模型. 然而到了20世纪80年代中期, RDBMS(relational database management system)和SQL已经成为绝大多数人存储和查询数据的首选工具. 关系数据库的统治持续了25到30年, 这对于计算机历史来说是一段很漫长的时间.
关系数据库起源于商务数据处理, 20世纪60年代和70年代使用大型计算机运行业务, 有些用例在现在看来稀松平常: transaction processing(银行交易, 航班预定, 仓库存储)和batch processing(用户发票, 工资单, 报表). 当时其他数据库迫使开发者去考虑数据库内部的数据表示形式. 关系数据库则致力于将实现细节隐藏在简洁的接口之后. 多年来出现过很多存储和查询数据的方法: 20世纪70年代和80年代早期, network model(网状模型)和hierrchical model(层次模型)还是主流选择, 但relational model(关系模型)最终占据主导地位. 对象数据库在20世纪80年和90年代卷土重来, XML数据库也在2000年兴起, 但未被大众接受. 每隔一段时间都出现一个关系模型的竞品, 但都没能持续.
随着计算机的性能越来越强, 用途也越来越广. 关系数据库原本只处理业务数据, 现在也被用于其他用例. 现在的网站大多使用关系数据库, 例如: 在线发布, 讨论, 网络社交, 电子贸易, 游戏, 软件服务等应用.
1.1 The Birth of NoSQL
2010年起, NoSQL尝试挑战关系模型. NoSQL这个名字并没有涉及特定技术, 最初只是作为一个醒目的标签. 这个名字在社区和初创公司中传播开来, 很多数据库系统也打上NoSQL标签, 并被重新解释为Not Only SQL(不只是SQL). 以下是使用NoSQL数据库的几个驱动因素:
- 需要比关系数据库更好的拓展性, 包括非常大的数据集或非常高的写入吞吐量
- 相对于商用数据库产品, 更偏向于免费和开源软件
- 需要一些关系数据库不支持的特殊查询操作
- 需要更动态且有表现力的数据模型, 而不只是关系模型
不同应用有不同需求, 其他用例的选择不一定是另一个用例的最佳选择. 因此在不远的将来, 关系数据库可能会和其他非关系数据库一并使用, 称为polyglot persistence(混合持久化).
1.2 The Object-Relational Mismatch
目前绝大多数应用开发都使用object-oriented programming language(面向对象语言), 导致了对SQL数据模型的一些批评: 由于数据保存在relational table(关系表)中, 需要一个笨拙的翻译层负责应用程序代码与数据库模型中table, row和column之间的转换. 这种模型间的不连贯称为impedance mismatch(阻抗不匹配).
ActiveRecord和Hibernated之类的Object-relational mapping(ORM, 对象关系映射)框架可以减少翻译层所需的代码量, 但并不能完全隐藏两个模型间的差异.
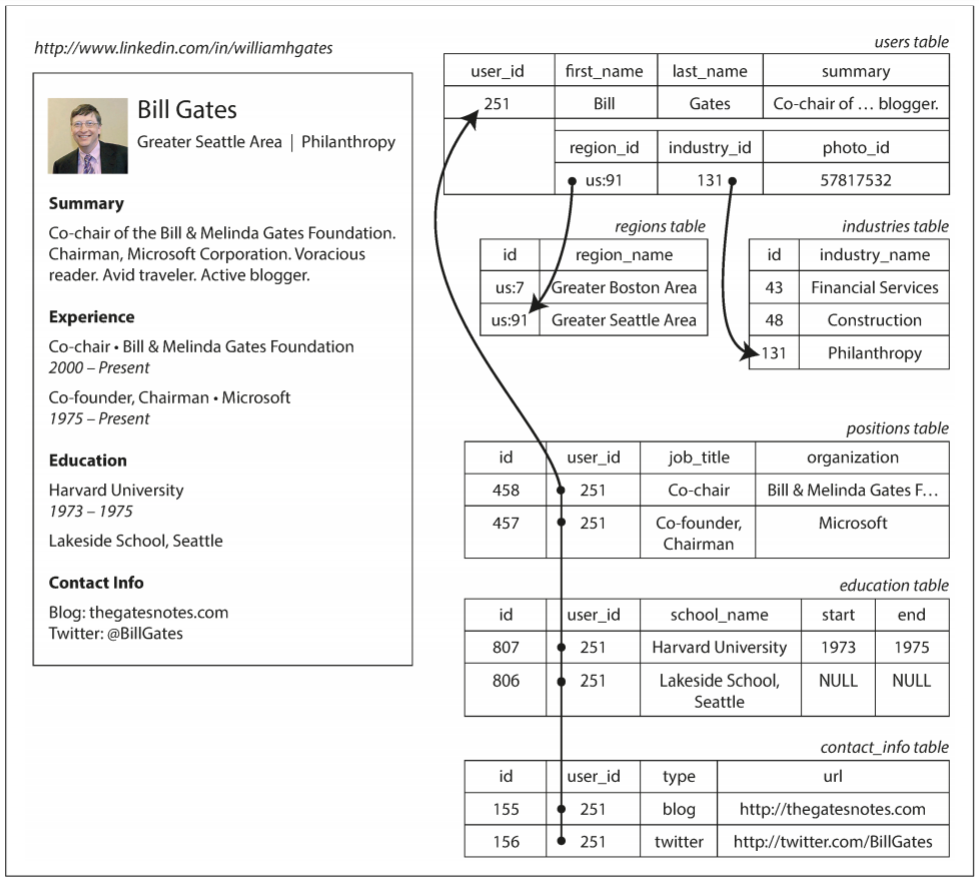
上图展示了如何在关系模型中表示简历. 每个简历有一个唯一标识符(user_id), 每个用户只有一个first_name和last_name字段, 所以可将其作为user table的一个column. 然而, 大多数用户会有多段工作经历, 也会有多段教育经历和多个联系方式, 这种一对多的关系可用以下方式表示:
- 传统SQL模型中, 通常会为position(职业), education(教育), contact information(联系方式)单独建表, 并为user table提供foreign key(外键)引用.
- 后续SQL标准增加了结构化数据类型和XML数据的支持, 允许multi-valued data(多值数据)存储在单行内, 且支持在文档内查询和索引. 该特性已得到Oracle, IBM DB2, MS SQL Server, 和PostgreSQL的支持. IBM DB2, MySQL, 和PostgreSQL也支持JSON数据类型.
- 第三种方式是将职业, 教育和联系方式编码成JSON或XML文档, 并将其保持在text column, 由应用解析其结构和内容. 这种方式无法使用数据库内部方式来查询编码值.
JSON非常适合简历这种self-contained document(自包含文档)的数据结构. JSON比XML更简单, Document-oriented database(面向文档的数据库, 如MongoDB, RethinkDB, CouchDB, Espersso)支持这种数据模型.
{ |
有些开发者认为, JSON模型减少了应用代码和存储层之间的阻抗不匹配. 但JSON作为一种数据编码其实也存在问题. 相比于多表模式, JSON具有更好的locality(局部性). 从关系模型中获得一份完整简历需进行多次查询操作, 或在user表和其子表间执行多路join. 而在JSON表示中, 所有简历信息都放在一个位置, 一次查询即可.
一个简历对应多个职业, 教育经历, 和联系方式, 这种一对多关系可用tree structure(树状结构)表示, 而JSON可让树状结构表示的更清晰: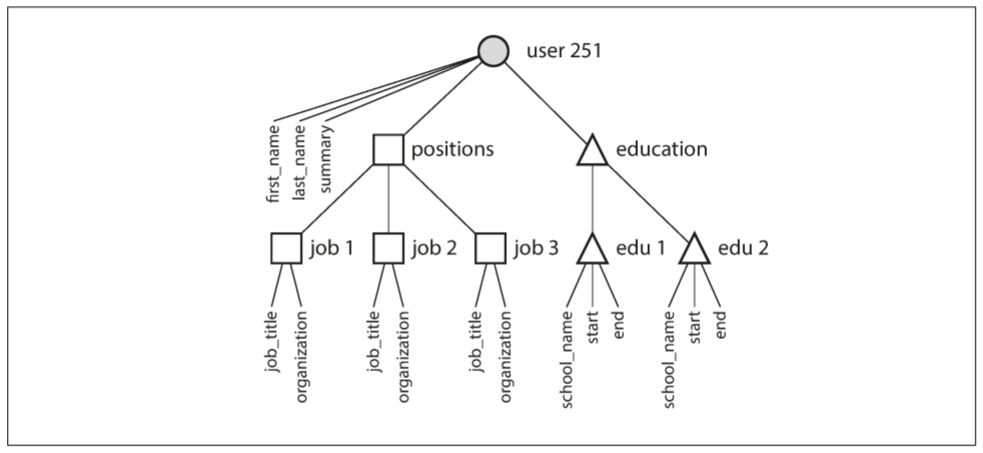
1.3 Many-to-One and Many-to-Many Relationships
上例中region_id和industry_id都使用ID, 而不是纯文本字符串(如Greater Seattle Area或Philanthropy). 如果地区和行业是用户输入的文本, 设置为纯文本字符串是没问题的; 另一种方式则是给出地区和行业的列表, 让用户从下拉菜单或自动填充中选择, 其优势如下:
- 每个简历保持一致的样式和拼写
- 避免歧义(如同名城市)
- 更新容易: 文本保存在一个位置, 如需更新某个城市名, 很容易全面更新
- 支持本地化: 当网站翻译为其他语言, 标准化的列表可被本地化, 地区和行业以用户语言显示
- 更好的搜索: 例如, 搜索华盛顿州的慈善家, 地区列表可反应Seattle处于Washington州这个关系(Greater Seattle Area字符串无法反应该地区所处的州)
存储ID还是文本是一个很复杂的问题. 当使用ID时, 只有ID对应的信息对人是有意义的; 当存储文本时, 每条信息对人都有意义. ID的优点在于与信息本身分离, 由于任何对人有意义的信息都可能被更新, 因此信息修改时ID可保持不变; 若不使用ID且信息被复制, 修改时需更新所有副本, 导致写入开销, 且存在不一致风险(一些副本被更新, 另一些副本未更新). 消除重复则是数据库中normlization(规范化)的核心思想.
然而, 规范化数据需要many-to-one relationship(多对一关系), 这与document model冲突. 关系数据库中, 由于join操作简单, 可用ID引用其他table的row. 但对于文档数据库, 多对一结构没必要用join, 对join的支持也很弱.
如果数据库本身不支持join, 则需在应用程序代码中进行多次查询来模仿join(地区和行业列表可能很小, 可以放入内存, 但join的实现工作从数据库转移到应用程序代码上).
此外, 即使document model满足当前应用的需求, 随着应用程序功能的增加, 数据之间的关系越来越密切. 以下是简历的可能需求:
- 将Organization(组织)和School(学校)作为实体: 之前的版本中, organization和school_name都只是字符串. 若organization和school都有单独的网页, 则需将organization和school作为实体. 每个简历可以链接到相应的organization和school
- Recommendation(推荐): 假设添加一个新功能, 用户可为另一个用户写推荐, 该推荐会显示在被推荐者的简历上, 推荐者的名字和照片也会显示在推荐上. 如果推荐者更新照片, 所有其给出的推荐上的照片也应更新. 因此, 推荐应拥有推荐者简历的引用

下图展示了新功能中的多对多关系. 每个虚线矩形表示一个文档, 对于organization, school和其他user的引用需表示为reference, 且查询时需要join.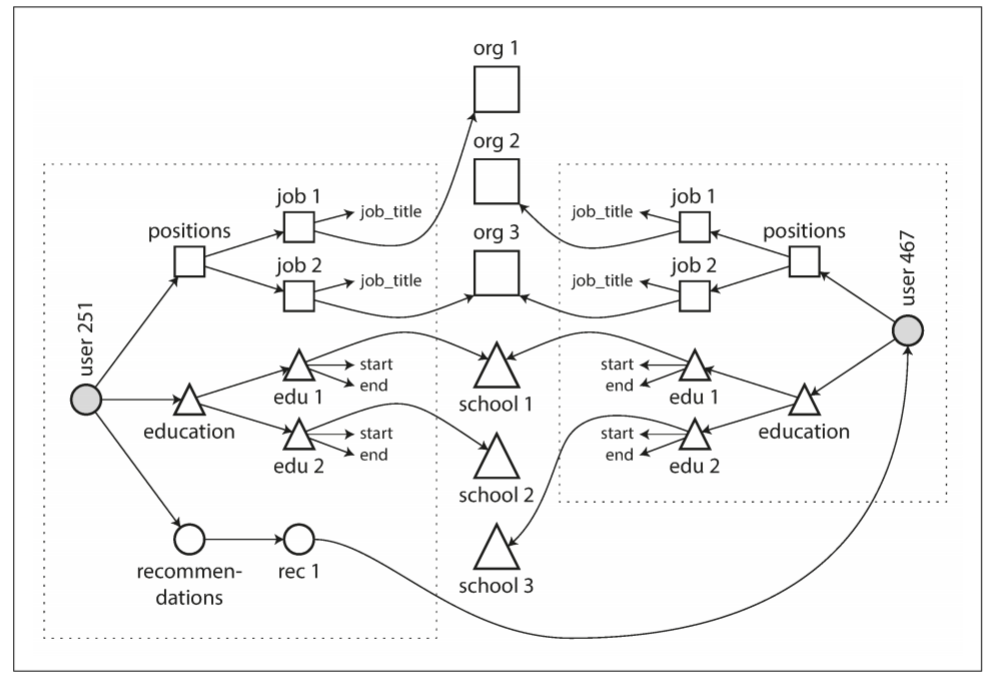
1.4 Are Document Database Repeating History?
关系数据库中使用多对多关系和join已经稀松平常, 但文档数据库和NoSQL则对于如何在数据库中表示关系(relationship)表示质疑. 这类辩论的出现远早于NoSQL, 最早可追溯至computerized database system(计算机化数据库系统).
20世纪70年代最受欢迎的业务数据库为IBM的Information Management System(IMS), 最初用于Apollo(阿波罗)太空计划的仓储管理, 后于1968年商业化, 至今仍被使用, 运行在IBM的OS/390 mainframe上.
IMS使用了一种十分简单的数据模型, 称为hierarchical model(层次模型), 其与文档数据库的JSON模型有很多相似之处. 该模型将数据表示为嵌套在记录中的记录树, 与JSON结构类似.
和文档数据库一样, IMS很好的解决了一对多关系, 但很难应对多对多关系, 且不支持join. 对于开发者, 有两种解决思路:
- denormalize(非规范化, 重复)数据
- 手动解决一个记录到另一个记录的引用
针对hierarchical model局限性的解决方法有很多, 以下是最突出的两种方法:
- relational model(关系模型, 演化为SQL)
- network model(网络模型, 最初受到很多关注, 但最终变得冷门)
1.4.1 Network model
Conference on Data Systems Language(CODASYL)的委员会为Network model(网状模型)进行了标准化, 并由多个数据库厂商实现, 也称为CODASYL model.
CODASYL model是hierarchical model的泛化, 对于树形结构的hierarchical model, 每个记录只有一个父节点; 对于network model, 记录可有多个父节点. 举个例子, "Greater Seattle Area"地区可能是一条记录, 每个居住在该地区的用户都可以与之连接, 因此允许对多对一和多对多关系进行建模.
Network model中记录之间的链接不是foreign key, 而更像是编程语言中的pointer(指针). 访问记录的唯一方法是从根记录出发, 沿着链路形成的路径, 称为access path(访问路径).
最简单的情况下, 访问路径和遍历链表类似: 从链表的头部出发, 不断查看记录, 直到找到所需的记录. 但对于多对多关系, 不同的路径可能导向相同的记录, 开发者需要跟踪自己走过的路径.
CODASYL中的查询通过利用遍历记录和跟踪访问路径来实现数据库中cursor的移动. 如果记录有多个父节点(多个指向该记录的指针), 则程序代码必须跟踪所有关系, 就像在n维数据空间中导航.
即使手动选择访问路径能最有效地利用20世纪70年代的硬件(磁带机, 搜索速度极慢), 但问题在于, 其查询和更新数据库的代码十分复杂不灵活. 无论是hierarchical model还是network model, 如果没有一个达到所需记录的访问路径, 事情将变得更困难. 开发者可以修改访问路径, 但需要重写访问路径的代码, 因此修改应用的数据模型十分困难.
1.4.2 Relation model
相比之下, relational model会将数据放在明面上: 一个关系(table)只是多个tuple(row)的集合. 没有迷宫似的嵌套结构, 没有复杂的访问路径. 你可以读取table中的任意几行, 或指定某些列作为匹配关键字来读取出特定行, 也可向table插入一个新的row, 不用担心与其他table的foreign key关系.
关系数据库中, query optimizer(查询优化器)会自动决定查询执行的顺序, 使用哪个index. 这些选择实际上就是访问路径, 但由查询优化器自动生成, 无需应用开发者的担心.
若你想以不同的方式查询数据, 可声明一个index, 查询时会自动采用最合适的index. 我们不必修改自己的查询语句就可使用新的index. Relational database的query optimizer十分复杂, 其经历了多年的研究和开发精力. relational model的关键在于: 只需创建一次query optimizer, 所有使用数据库的应用都会收益. 为某个query编写访问路径比写一个query optimizer更容易, 但长远而言, 通用解决方案更好.
1.4.3 Comparison to document database
文档数据库在某一方面继承了hierarchical model: 可以在父节点内嵌套多个记录, 而不是将记录放置在一个单独的table中. 然而当描述多对一或多对多关系时, 关系和文档数据库都选择了相同的方案: 相关记录使用一个唯一标识符引用, 该标识符在relational model中称为foreign key, 在document model中称为document reference. 使用join或后续查询中会解析该标识符.
1.5 Relational Versus Document Database Today
当我们对比关系数据库和文档数据库时, 它们之间有很多不同之处: fault-tolerance properties(容错属性), handling of concurrency(并发处理). 本章只专注于数据模型间的不同.
Document data model更偏向于架构灵活度, 因局部性带来的性能提升; 而relational model对join, 多对一, 和多对多关系有更好的支持.
1.5.1 Which data model leads to simpler application code?
如果应用中的数据是类似于文档的结构(例如, 一对多关系树, 通常一次性加载整个树), 那么可使用document model. Relational model会将数据拆分到各个table中, 从而导致繁琐的模式和程序代码.
Document model也有一些局限性: 例如, 你无法直接引用某个文档中的内嵌数据, 只能说"251号用户的第二项数据". 不过只要文档嵌套的不深, 通常不会构成问题.
Document model不支持join操作, 但对于很多应用来说不是一个问题. 例如, 多对多关系对于一个分析型应用来说并不是必须的, 可用文档数据库来记录事件.
然而, 如果应用使用到了多对多关系, document model就没有那么具有吸引力. 虽然可使用denomalize(反规范化)来避免join操作, 但需要更多代码做额外工作以保证数据一致性. Join也可以通过多次数据库请求实现, 但将复杂性转移到应用程序上, 且运行效率更低.
简而言之, 无法一概而论哪个data model更好, 更多取决于数据的关系类型. 对于数据关联度较高的应用, 不推荐document model, relational model更好, graph model最自然.
1.5.2 Schema flexibility in the document model
大部分文档数据库, 还有支持JSON格式的关系数据库都不强制要求schema(模式). 支持XML的关系数据库会提供一个可选的schema验证. 没有schema意味着, 文档中的key和value可以是任何数据; 读取数据时, 客户端无法确定文档中可能包含的字段.
文档数据库也称为schemaless(无模式的), 但这具有误导性, 因为读取数据的代码会假定数据遵守某种模式. 更准确的说法应为schema-on-read(读时模式), 数据结构是不可见的, 只有读取时才被解析; 相对应的是schema-on-write(写时模式), 关系数据库遵守的schema是显式的, 且数据库确保所有写入数据都遵守schema.
读时模式类似于编程语言中的动态类型检查, 而写时模式类似于静态类型检查. 数据库的schema是否强制是一个具有争议的话题, 没有正确答案.
当应用修改数据格式时, 两种schema策略间的区别尤为明显. 例如, 应用将用户的full name(全名)放在一个字段中, 现在将姓氏和名字分别存储两个字段中. 对于文档数据库, 只需要写入含有新字段的文档, 并在应用代码中处理旧数据:
if (user && user.name && !user.first_name) { |
但对于静态类型的数据库schema, 需执行以下迁移操作:
ALTER TABLE users ADD COLUMN first_name text; |
模式变更速度很慢, 且会造成服务不可用. 对于大多数关系数据库系统, 执行ALTER TABLE语句只需要几毫秒. MySQL是一个例外, ALTER TABLE会复制整个table, 如果table规模很大, 会造成几分钟甚至数小时的数据库不可用.
无论哪种类型的数据库, 对大型table进行UPDATE操作都很慢, 因为每条记录都需要重写. 若无法接受, 应用可将first_name的默认值设为NULL, 读取时再填充, 就像使用文档数据库一样.
若集合中的记录并不具有相同结构, 读时模式更具有优势. 例如:
- 对象具有不同的类型, 无法将对象的各个类型放入table中
- 数据结构由外部系统决定, 而我们无法控制其变化
上述情况使得schema的劣势大于优势, schemaless document是一种更自然的数据模型. 但若所有记录遵循同一个结构, schema可以很好地限制文档的结构.
1.5.3 Data locality for queries
文档通常会被保存为一个连续的字符串, 以JSON, XML或二进制变体(例如MongoDB's BSON)编码. 如果应用经常访问某个文档, 则storage locality(存储局部性)会带来性能提升. 如果数据被分割到多个table中, 那么需要多次查询index才能获得全部数据, 导致花费更多时间查找磁盘.
Storage locality仅仅适用于用户需要文档的绝大部分内容. 即使用户只需要一小部分数据, 数据库也会加载整个文档. 更新文档时, 也需重写整个文档. 因此建议保持文档体积尽量较小, 并避免增加文档体积的写入. 这些限制明显减少了文档数据库的应用场景.
值得注意的是, 局部性并不只是文档数据库的特性. 例如, Google的Spanner数据库采用了relational data model, 但允许schema让子表的一行嵌套入父表中, 从而提供存储局部性. Oracle也允许使用multi-table index cluster tables(多表索引集群表). Bigtable data model的column-family(列族)概念也与managing locality(管理局部性)的目的相似.
1.5.4 Convergence of document and relational databases
从2000年中期开始, 绝大多数关系数据库都支持XML格式, 其中包括对XML文档进行本地修改, 在XML文档内部进行索引和查询, 这使得用户可以像文档数据库一样使用数据模型.
PostgreSQL从9.3版本起, MySQL从5.7版本起, IBM DB2从10.5版本起, 开始支持JSON文档. 鉴于Web APIs的JSON流行趋势, 其他关系数据库很可能支持JSON.
对于文档数据库, RethinkDB支持类似关系的join, 一些MongoDB驱动会自动解析数据库引用. 关系数据库和文档数据库似乎变得越来越相似, 这使得两种data model可以互补. 如果一个数据库能处理文档数据, 也可以进行关系查询, 应用就可以结合这些特性, 更好地满足需求.
2. Query Languages for Data
引入relational model时, 随着带来一种新的数据查询方式: SQL是一种declarative(声明式)查询语言, IMS和CODASYL采用imperative(命令式)代码查询数据库. 很多编程语言都是命令式的, 例如, 给定一个动物列表, 查询列表中的鲨鱼:
function getSharks() { |
在关系代数中写作:
$$
sharks = \sigma_{family=Sharks}(animals)
$$
$\sigma$是选择操作符, 返回满足条件(family为Sharks)的动物. 定义SQL时, 其密切遵循关系代数的结构:
SELECT * FROM animals WHERE family = 'Sharks'; |
命令式语言会告诉计算机以什么顺序做什么操作. 计算机会逐行执行, 判断条件, 更新变量, 并决定是否再次循环.
声明式语言(如SQL和关系代数)只需指定所需数据的模式: 数据匹配的条件, 数据转换的格式(sorted, grouped, 和aggregated), 但不会说明如何实现. 具体实现取决于query optimizer决定使用哪个index, 使用哪种join方式, 还有执行顺序.
声明式查询语言很吸引人, 因为十分简洁, 比命令式API更容易使用. 但更重要的是, 它隐藏了数据库引擎的实现细节, 使得数据库系统可以在不修改查询语句的前提下提升性能. 例如, 对于上面的命令式语句, 动物以一定顺序保存. 如果数据库想要在后台回收未使用的磁盘空间, 则需要移动记录, 改变动物的排序. 那么数据库如何在不中断查询的情况下安全地执行呢?
SQL示例不保证特定顺序, 因此也不在意顺序的改变. 但对于命令式代码查询, 很难确定数据是否依赖于排序. SQL虽然缺失了部分功能, 但为自动优化留下空间.
最后, 声明式语言往往更适合并行执行. 目前CPU的增速主要靠增加核心数量, 而不是提高时钟频率. 命令式代码很难在多核或多个机器上并行执行, 因为很多指令必须顺序执行. 声明式语言仅指定结果的模式, 而不指定计算结果的算法, 因此更适合并行执行. 数据库也因此可以自由地实现其查询语言.
2.1 Declarative Queries on the Web
声明式语言的优势不仅仅体现在数据库. 以网页浏览器为例来比较声明式和命令式的不同: 假设网页用于展示海洋中的动物, 某个用户正在网页上查看鲨鱼, 因此导航栏中的Shark应该是被选中的状态:
<ul> |
- 被选中的节点带有CSS类"selected"
<p>Sharks</p>作为当前页面的标题
selected的CSS定义如下:
li.selected > p { |
上述CSS selector声明了我们想要应用蓝色样式的元素的模式: 父元素具有selected的CSS类中的所有<p>元素. <p>Sharks</p>匹配该模式, 但<p>Whales</p>不匹配, 因为父元素<li>缺少class="selected". 如果使用XSL, 代码如下:
<xsl:template match="li[@class='selected']/p"> |
XPath的li[@class='selected']/p等同于CSS selector的li.selected > p. CSS和XSL的共同之处在于, 它们都使用声明式语言. 如果使用命令式方法, 以JavaScript为例, 用户需要使用DOM API, 代码如下:
var liElements = document.getElementsByTagName("li"); |
上述代码会为<p>Sharks</p>设置蓝色背景, 但代码相对于CSS和XSL, 可读性更差且更长, 而且存在其他问题:
- 若selected class被移除, 除非重新运行代码或重新加载页面, 否则不会移除蓝色背景. 对于CSS, 浏览器会自动检测selector是否符合条件.
- 若使用新API, 例如document.getElementsByClassName("selected"), 或document.evaluate(), 虽然可以提高性能, 但需要重写代码. 但对于CSS和XSL, 浏览器开发商可在不破坏兼容性的情况下优化性能.
对于web浏览器, 声明式的CSS样式比JavaScript操作元素更好. 同样的, 对于数据库, 声明式查询语言(例如SQL)比命令式查询API更好.
2.2 MapReduce Querying
MapReduce是由Google推出的编程模型, 用于在多台机器上批量处理大规模数据. 一些NoSQL数据存储支持有限形式的MapReduce, 作为在多个文档中执行只读查询的机制, 包括MongoDB, CouchDB.
MapReduce既不是声明式查询语言, 也不是命令式查询API, 而是介于两者之间: 查询部分由代码片段表示, 这些代码会被处理框架反复调用. 它基于map和reduce两个函数, 这两个函数存在于很多函数式编程语言中. 例如, 数据库记录了不同种类的海洋生物在某一天出现的次数, 我们需要统计每个月鲨鱼出现的次数. 以PostgreSQL为例, 查询语句如下:
SELECT date_trunc('month', observation_timestamp) AS observation_month, |
其中, date_trunc('month', timestamp)函数会将时间戳四舍五入到最近的月份. 上述查询会先筛选出鲨鱼的记录, 然后根据月份进行分组, 最后对出现的次数求和.
若使用MongoDB的MapReduce功能, 代码如下:
db.observations.mapReduce( |
- 声明式地指定一个只包含鲨鱼的过滤器(MongoDB特定的MapReduce拓展): query: { family: "Sharks" }
- 对每个匹配query的文档调用map函数, this表示文档本身
- map函数返回一个key(由year和month组成的字符串, 如"2013-12")和一个value(观察到的动物出现次数)
- key-value pair会根据key分组, 相同key的分组会被reduce函数调用一次
- reduce将同月观察到的所有动物数量相加
- 结果写入monthlySharkReport集合
假设observations集合包含两个文档:
{ |
map函数会对每个文档进行处理, 返回("1995-12", 3)和("1995-12", 4). 之后reduce函数接收到("1995-12", [3, 4]), 返回7.
map和reduce函数都被限制在各自的范围内, 必须是纯函数, 意味着它们只能使用传入的参数作为数据, 不能做额外的数据查询, 且不能有任何副作用. 这种限制可以让数据库以任何顺序, 任何地方运行, 还可以在失败时重新运行. 尽管如此, MapReduce功能还是很强大, 它可以解析字符串, 调用库函数, 进行计算等等.
MapReduce是一个相对底层的编程模型, 用于计算机集群上的分布式执行. SQL作为相对高级的查询语言, 可以用一系列MapReduce操作实现. 但也有SQL可以不借助MapReduce来实现分布式. SQL并没有只限于单个机器上, MapReduce也不是唯一能够分布式查询的.
能够在查询中使用JavaScript代码是高级查询的一个重要特性, 但不限于MapReduce, 一些SQL数据库也进行了JavaScript函数拓展.
MapReduce存在一个可用性问题: 开发者需要写两个密切相关的JavaScript函数, 比其只写一个查询更难. 此外, 声明式查询语言为query optimizer提供了更多机会来提升查询性能. 因此, MongoDB 2.2添加了一种名为aggregation pipeline(聚合管道)声明式查询语言, 查询同月鲨鱼被观察的数量的查询如下:
db.observations.aggregate([ |
Aggregation pipeline与SQL的子集有相同的表现力, 但并没有使用SQL一样的英文句式, 而是用JSON语法.
3. Graph-Like Data Models
多对多关系是区别不同数据模型的重要特征, 如果应用只是用一对多关系(树状结构化数据), 或记录之间没有关联, 那么document model更适合.
如果应用大量使用多对多关系, 则可以考虑relational model. 但若数据之间的关系更加复杂, 可能需要使用graph作为data model. 一个graph由两类对象组成: vertex(顶点, 也称作node或entity)和edge(边, 也称作relationship或arc). Graph model可为以下几种数据建模:
- Social graph: vertex表示用户, edge表示两个人相互认识
- Web graph: vertex表示网页, edge表示指向其他网页的HTML链接
- Road or rail network: vertex表示交叉路口, edge表示它们之间的道路或铁路
图模型有很多算法可以使用: 汽车导航系统在道路图上搜索两点之间的最短路径, PageRank用于确定网页图中网页的流行程度, 从而确定该网页在搜索结果中的排名.
上述例子里, 图中所有vertex表示相同类型的事物(人, 网页或路口), 但图还可以存储不同类型的对象. 例如, Facebook会维护一个图, vertex和edge包括不同的类型: vertex可以是人, 地点, 事件, 签到, 和用户评论; edge表示某人和其他人的关系, 哪个签到发生在哪个位置, 谁评论哪条消息, 谁参与了哪个事件.
下图展示了社交网络中数据模型, 其中包含两个人: 来自Idaho的Lucy, 来自Baeune的Alain, 他们已婚且居住在London.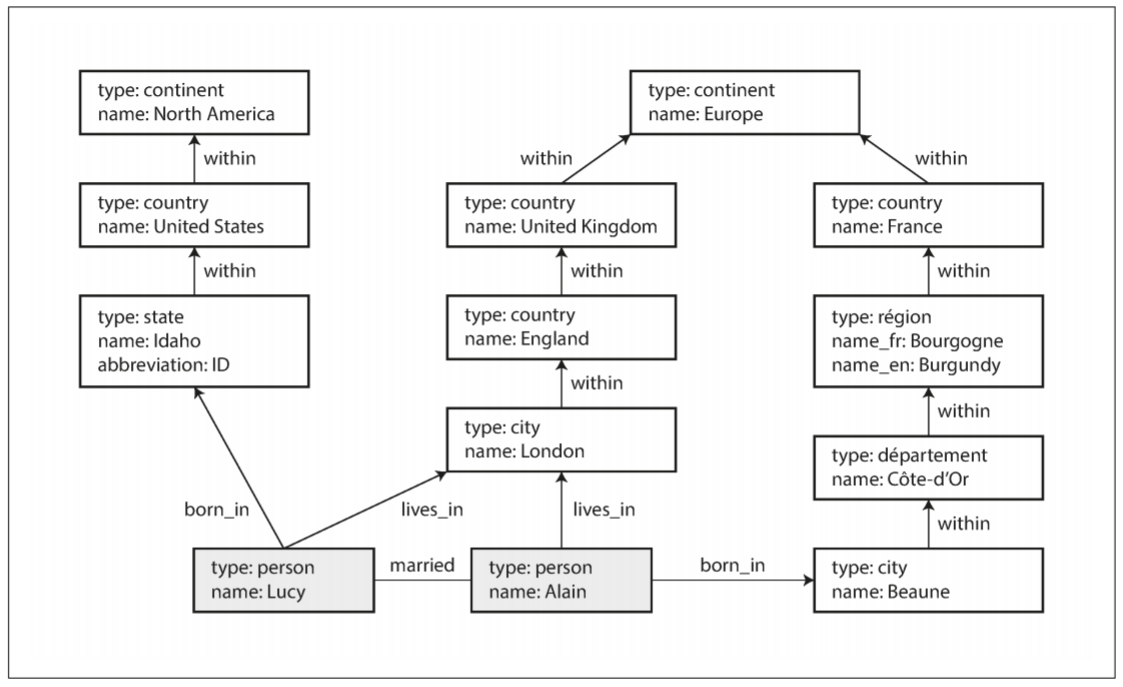
3.1 Property Graphs
对于property graph model, 每个vertex包含以下属性:
- 唯一标识符
- 一组出边(outgoing edge)
- 一组入边(ingoing edge)
- 一组属性(key-value pairs)
每个edge包含以下属性:
- 唯一标识符
- 起点(tail vertex, 箭尾)
- 终点(head vertex, 箭头)
- 描述两个vertex关系的标签
- 一组属性(key-value pairs)
可以将其想象成两个关系table, 一个存储vertex, 一个存储edge. 每个edge有两类vertex: head vertex和tail vertex. 如果想查询某个vertex的入边或出边, 可以在edge table中查询head_vertex或tail_vertex.
CREATE TABLE vertices ( |
该模型有以下特点:
- 任何vertex都可建立与其他vertex的连接(edge)
- 对于任意一个vertex, 可以很快地找到其入边和出边
- 通过不同标签, 可以设置不同类型的关系, 一个图中可包含不同信息
上述特性为图模型提供了很大灵活性和建模能力. 传统关系模式无法表示的关系, 可用图模型清晰表示, 例如不同国家的不同地区结构(中国有省, 美国有州), 不同的数据粒度(Lucy居住地为城市, 但出生地为州). 可以想象, 图模型还可以包含更多关于Lucy和Alain的事实. 例如, 他们会过敏的食物(过敏原为vertex, 人与过敏原之间的edge表示过敏情况), 每个过敏源可拥有一组vertex, 表示哪些食物有哪些过敏源. 我们可轻松地找出哪些食物对哪些人是可食用的.
3.2 The Cypher Query Language
Cypher是property graph的声明式查询语言, 为Neo4j图形数据库发明.
CREATE |
上述Cypher查询插入了多个vertex和edge, 每个vertex都被给予了USA或Idaho之类的符号名称, 用(Idaho) -[:WITHIN]-> (USA)这样的箭头表示edge. Idaho为tail vertex, USA为head vertex. 现在我们想找到所有从美国移民到欧洲的人的名字, 确切地说, 我们要找到所有符合条件的vertex, 并返回这些vertex的name属性: 这些vertex拥有一条连接到USA的edge, 其标签为BORN_IN, 还有一条edge连接Europe, 其标签为LIVES_IN:
MATCH |
查询可理解为同时满足以下两个条件的vertex.
- person顶点有一个标签为BORN_IN的出边. 从该顶点出发, 可经过一系列WHTHIN出边, 最终到达一个类型为Location的顶点, 其name属性为USA
- person顶点有一个标签为LIVES_IN出边, 从该顶点出发, 可经过一系列WITHIN出边, 最终到达一个类型为Location的顶点, 其name属性为Europe
存在有几种可能的查询路径, 例如, 先扫描数据库中的所有人, 检查每个人的出生地和居住地, 然后返回符合条件的人. 相反的, 可从两个Location顶点反向查找, 假设name属性上有索引, 则可以迅速找到name为USA和Europe的两个顶点, 然后沿着所有WITHIN入边, 找到USA和Europe的所有位置(州, 城市, 地区). 最后找出BORN_IN或LIVES_IN入边的人.
对于声明式查询语言来说, 编写查询语句时无需关心执行细节: query optimizer会自动选择最高效的访问路径.
3.3 Graph Queries in SQL
在关系数据库中存储图数据有些困难, 我们在做query时必须知道哪些数据需要join. 图查询中, 在找到vertex之前必须遍历多个edge, join的次数是不固定的. 以上一节Cypher查询中的() -[:WITHIN*0..]-> ()为例, person对象的LIVES_IN edge可能指向任何地址: 一条街, 一个城市, 一片区域, 一个州等. 一个城市可能包含在一片区域中, 一个州可能包含在一个国家里. LIVES_IN edge可能指向所需的location vertex, 也可能隔着好几层Location vertex.
Cypher中, :WITHIN*0..表示WITHIN edge重复零次或多次, 相当于正则中的*操作符. 从SQL 1999起, 查询中可使用recursive common table expression(WITH RECURSIVE语法)实现可变长度遍历路径, 以下SQL使用递归实现了相同功能:
WITH RECURSIVE |
执行步骤如下:
- 首先, 查找name属性为United States的顶点, 将其作为in_use集合的第一个元素
- 从in_usa顶点集合出发, 遍历每个标签为with_in的入边, 将其起点加入到该集合并不断递归, 直到访问完所有with_in入边
- 同上, 从name属性为Europe的顶点出发, 递归并建立in_europe集合
- 对于in_usa集合中的每个顶点, 根据born_in入边来找到所有出生在美国的人
- 对于in_europe集合的每个顶点, 根据lives_in入边来找到所有居住在欧洲的人
- 最后, 求in_usa和in_europe的交集
查询功能相同, Cypher需要4行, 而SQL需要29行, 说明不同数据模型适用于不同应用场景, 选择应用程序的数据模型十分重要.
3.4 Triple-Stores and SPARQL
Triple-stores model(三元组存储模式)和property gragh model大体相同, 用不同的词描述相同的目的. 三元组存储中所有信息由三个部分组成: subject(主语), predicate(谓词), object(宾语). 例如, 对于三元组(Jim, likes, bananas), Jim是主语, likes是谓语, bananas是宾语. 三元组的主语相当于图模型的vertex, 而宾语表示两种事物:
- 原始数据类型: 如字符串或数字. 谓词和宾语等同于图模型中vertex的key-value属性. 例如, (lucy, age, 33)等同于lucy顶点的属性: {age: 33}.
- 图中的另一个vertex: 谓词表示图的edge, 主语表示起点, 宾语是终点. 例如, (lucy, marriedTo, alain), lucy和alain都是顶点, 谓词marriedTo是edge的标签.
下列是Turtle表示的数据子集:
@prefix : <urn:example:>. |
图的顶点写作_:someName, 这个格式并不表示任何东西, 只是让我们更明确哪些三元组指向同一顶点. 当谓语表示edge时, 宾语为顶点, 如_:idaho :within _:usa. 当谓语是一个属性时, 宾语是一个字符串, 如_:usa :name "United States". 也可用分号来说明同一主语的多个事件:
@prefix : <urn:example:>. |
3.4.1 The semantic web
如果阅读更多关于triple-stores的文章, 可能陷入关于语义网络的漩涡中. 三元组存储模型独立于语义网络, 这里需要说明一下. 语义网是一个很简单的想法: 网站将信息发布为文字和图片供人类阅读, 为什么不将信息作为机器可读的数据也发布给机器呢? Resource Description Framework(RDF, 资源描述框架)作为不同网站以统一的格式发布数据的一种机制, 允许来自不同网站的数据合并成一个数据网络. 然而语义网在21世纪初被滥用, 到目前为止也没有很好的实践.
3.4.2 The RDF data model
上一节使用的Turtle语言可以提供一种易于理解的RDF数据格式, RDF也可用XML格式描述. 如下:
<rdf:RDF xmlns="urn:example:" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> |
由于RDF为在互联网上交流数据而设计, 因此主语, 谓语, 宾语都是URI. 例如, 谓语可能是一个URI, 如http://my-company.com/namespace#within, 而不仅仅是WITHIN. 这样的设计可避免你的数据和其他人的数据产生冲突; 如果其他人也需要用到within或lives_in, 他们可以使用不同的namespace, 如http://other.org/foo#within.
3.4.3 The SPARQL query language
SPARQL采用RDF数据模型, 作为为triple-stores设计的查询语言, 其早于Cypher. 由于Cypher借鉴了SPARQL, 因此两者看起来有很多相似之处.
以下语句用于找到出生在美国且在欧洲生活的人:
PREFIX : <urn:example:> |
以下两个表达式是等价的:
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher |
由于RDF不区分属性和边, 只是将它们作为谓语, 因此可以用相同的语法匹配属性, 下面的表达式中, 变量usa被绑定到具有"United States"字符串的name属性的顶点上:
(usa {name:'United States'}) # Cypher |
3.5. The Foundation: Datalog
Datalog是比SPARQL和Cypher更古老的语言, 虽然不知名, 但为以后的查询语言提供了基础. 实践中, Datalog只出现在少数数据系统中, 例如, Datomic使用Datalog作为查询语言, Casacalog作为Hadoop大数据集用于查询的语言, 也实现了Datalog数据模型.
Datalog的数据模型类似于三元组, 但写作predicate(subject, object). 以下是Datalog的写入语句:
name(namerica, 'North America'). |
以下是Datalog的查询语句:
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */ |