Encoding and Evolution
应用程序不可避免地随时间而变化. 新产品的推出, 对需求的深入理解, 商业环境的改变, 都伴随着feature(功能)的增删. 绝大多数情况下, 修改应用程序的功能意味着修改存储的数据: 可能使用新的字段或记录类型, 或以新的方式展示现有数据.
不同的数据模型有不同方法来应对变化. 关系数据库假定所有数据都遵循一个schema(模式): 虽然schema可被改变, 但任何时间点只有一个有效的schema. 相比之下, schema-on-read database(读时模式数据库, 也称为schemaless database)不会强制一个schema, 因此数据库可在任意时间写入新旧格式数据.
当数据的format(数据格式)或schema发生变化时, 对应的应用代码也往往需要修改(例如, 记录添加新的字段后, 应用也需要读取或写入该字段). 然而, 大型应用的代码修改无法立刻完成:
- 对于server-side(服务端)应用程序, 可能需要执行rolling upgrade(滚动升级, 也称为staged rollout). 为检查新代码是否运行正常, 会先部署到少数几个节点, 并逐步部署到所有节点. 这样无需中断服务就可以部署新版本, 为更频繁的发布和更好的演化性提供了可行性.
- 对于client-side(客户端), 是否升级取决于用户意愿, 用户可能很长一段时间都不升级.
这意味着, 新旧代码, 以及新旧的数据格式会同时出现在系统中. 为了让系统顺利运行, 需要保持双向兼容性:
- Backward compatibility(向后兼容): 新代码可读取旧数据
- Forward compatibility(向前兼容): 旧代码可读取新数据
向后兼容不难实现: 新代码的开发者清楚地知道旧数据的格式, 因此处理起来很轻松; 向前兼容比较困难, 因为旧代码需要忽略新数据格式的新增部分. 本章将介绍几种编码数据的格式, 包括JSON, XML, Protocol Buffers, Thrift, 和Avro. 我们将关注这些格式如何应对模式变更, 以及如何支持新旧代码共存问题. 然后将讨论如何使用这些格式进行数据存储和通讯: 在web服务中, Representational State Transfer(REST)和remote procedure calls(RPC), 以及message-passing system(消息传递系统).
1. Formats for Encoding Data
程序通常使用两个形式的数据:
- 在内存中, 数据以object, struct, list, array, hash table, tree和其他形式存在. 这些数据结构针对CPU的高效访问和操作进行了优化(通常使用指针).
- 当需要将数据写入文件或通过网络传输时, 则需编码为某种自包含的字节序列(如JSON文档). 由于每个进程都有自己独立的地址空间, 因此指针对于其他进程没有意义, 所以编码后的字节序列和内存中的数据结构完全不同.
因此, 我们需要一种转换机制, 从内存中的呈现形式转换为字节序列的过程称为encoding(编码, 也称serialization或marshalling), 反之称为decoding(解码, 也称为parsing, deserialization, unmarshalling).
1.1 Language-Specific Formats
很多编程语言都自带编码方式, 可将内存对象编码为字节序列. 例如, Java的java.io.Serializable, Ruby的Marshal, Python的pickle. 还有很多第三方库, 例如Java的Kryo.
这些编码库非常方便, 可用很少的额外代码实现内存对象的保存与恢复. 然而, 它们也存在一些深层问题:
- 这些编码方式与特定编程语言挂钩, 很难以其他语言读取编码后的数据. 如果以这类编码方式存储或传递数据, 则与该编程语言绑定, 很难与其他系统集成(其他组织可能使用其他语言)
- 为恢复相同对象类型的数据, 解码需要有实例化任意类的能力, 从而造成安全隐患: 如果攻击者可让你的应用解码任意字节序列, 就可以实例化任意class, 并借此攻击系统, 如远程执行任意代码
- 这些库通常不会考虑版本控制, 因为它们的设计目的是为了便捷地编码数据, 往往忽略了向前和向后兼容性
- 很多库的编码效率较低, 如Java的内置序列化
1.2 JSON, XML, and Binary Variants
当谈及可以被多种编程语言读写的编码方式时, 很容易想到JSON和XML. 它们广为人知且广受支持, 但也深受差评. XML因冗长和复杂性而备受批评. JSON的流行主要源于Web浏览器的内置支持, 且比XML简单. CSV也是一个独立于任何语言的格式, 但功能性较弱.
JSON, XML, CSV都是文本格式, 且具有可读性. 除了语法问题外, 它们还存在一些问题:
- number(数值)编码存在歧义: XML和CSV中无法区分数值和字符串; JSON虽然能区分字符串和数值, 但不区分整数和浮点数, 而且不能指定精度
- 处理大数值时存在问题: 例如, 大于$2^{53}$的整数不能以IEEE 754双精度浮点数表示, 因此使用浮点数时数字会变得不准确. Twitter中有使用到超过$2^{53}$的数值, 用于标识每条tweet. Twitter的API返回一个JSON, 包含两个tweet ID, 一个是JSON number, 一种是十进制字符串, 以免JavaScript无法正确解析数字
- JSON和XML对Unicode字符串有很好的支持, 但并不支持二进制字符串. 二进制串是很有用的功能. 虽然可以使用Base64将二进制数据编码为文本, 但会让数据体积增加三分之一
- XML和JSON都有可选的模式支持. 这些模式语言很强大, 但学习和实现都很复杂. XML模式的使用很普遍, 但基于JSON的工具并不会使用模式. 由于数据的解析依赖于模式的信息, 不适用XML/JSON模式的应用需对相应的编码/解码逻辑进行硬编码.
- CSV没有任何模式, 因此行列的定义完全取决于应用程序. 如果一个应用添加了新的行或列, 那么必须手动处理. CSV也是一个相当模糊的格式, 尽管转义规则被正式规定, 但并不是所有解析器都正确实现了标准
尽管存在很多缺陷, JSON, XML和CSV还是可以满足很多需求. 不出意外的话, 它们很可能继续流行下去, 尤其是作为数据交换格式(例如, 将数据从一个组织发送给另一个组织). 这种情况下, 只要人们认同这种编码, 效率和美观就不算太大问题. 让不同组织达成一致比很多问题还重要.
1.2.1 Binary encoding
对于仅在组织内部使用的数据, 可使用最小公约数式的编码格式. 例如, 我们可选择压缩更紧凑或更快的解析格式. 若数据集较小, 收益可忽略不计; 但如果数据集达到TB级别, 数据格式的选择会产生巨大影响.
JSON比XML简洁, 但相对于二进制格式, 这两者还是太占空间, 因此诞生了很多二进制编码的JSON(如MessagePack, BSON, BJSON, UBJSON, BISON, Smile)和XML(WBXML, Fast Infoset). 这些格式已经在很多领域中使用, 但没有一个像文本版JSON和XML那样广泛使用.
其中某些格式拓展了一些数据类型(例如, 区分整数和浮点数, 增加对二进制字符串的支持), 但并没有改变JSON/XML的数据模型. 由于没有schema, 所以必须在编码数据中包含所有的对象字段名称:
{ |
上图为JSON文档的二进制编码, 需包含字符串userName, favoriteNumber和interests. 以MessagePack为例, 以下是JSON文档的二进制编码字节序列: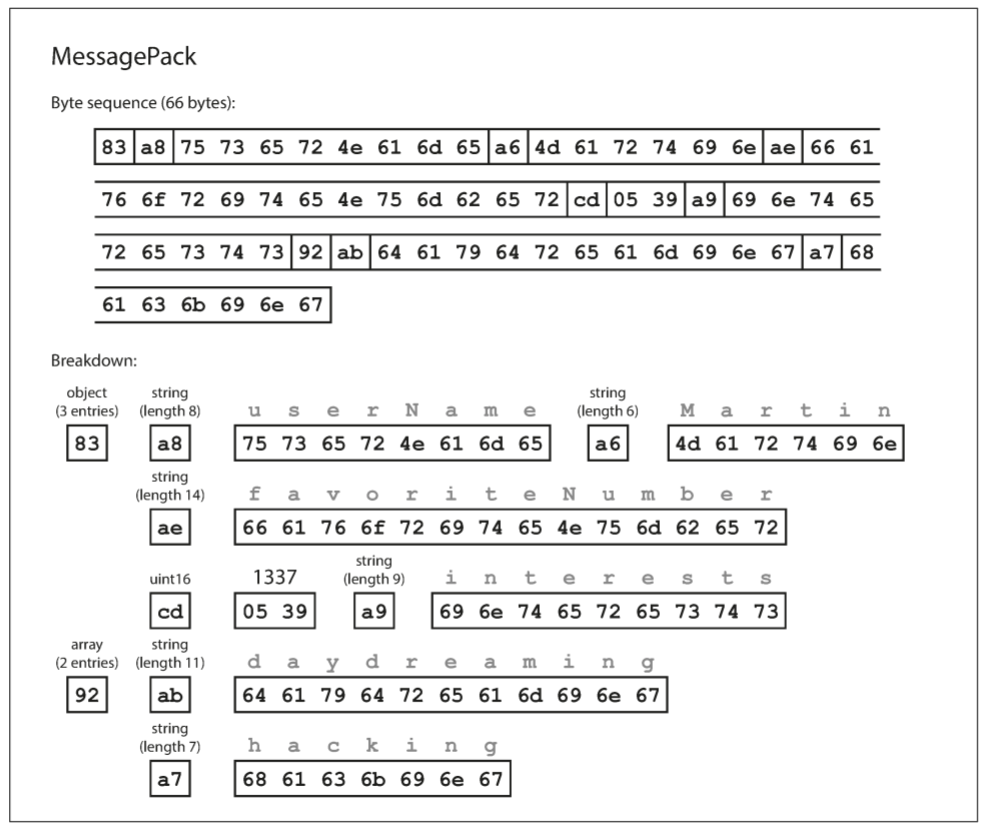
前几个字节如下:
- 第1个字节0x83表示接下来是3个字段(低四位0x03)的object(高四位0x80). 如果对象有15个以上的字段, 由于4bit不够表示字段数量, 因此会使用其他类型的标识符, 字段数量可编码为2个或4个字节.
- 0xa8表示接下来是8个字节长(低四位0x08)的字符串(高四位0xa0)
- 接下来8个字节是ASCII字符串userName, 之前已经指明长度, 因此无需终止符
- 0x06表示接下来的6个字节是ASCII字符串Martin
二进制编码长度为66字节, 略小于81字节的文本JSON编码. 所有二进制编码的JSON在这一方面是相似的, 空间虽然节省了一点, 但牺牲了可读性.
1.3 Thrift and Protocol Buffers
Apache Thrift和Protocol Buffers都是二进制编码库. Protocol Buffers由Google创建, 而Thrift由Facebook创建, 两者都在2007-2008年间开源.
Thrift和Protocol Buffer都要求编码数据有一个schema. 在Thrift中对数据进行编码, 需要使用Thrift interface definition language(Thrift接口定义语言, IDL)定义一个schema:
struct Person { |
Protocol Buffer的等效schema如下:
message Person { |
Thrift和Protocol Buffer都自带一个代码生成工具, 其会接收schema定义, 并以当前编程语言生成实现schema的class. 应用代码会调用生成的代码对记录进行编码和解码.
编码后的数据是什么样子? Thrift有两种二进制编码格式, 分别为BinaryProtocol和CompactProtocol. 以下是BinaryProtocol编码后的二进制数据, 共59字节: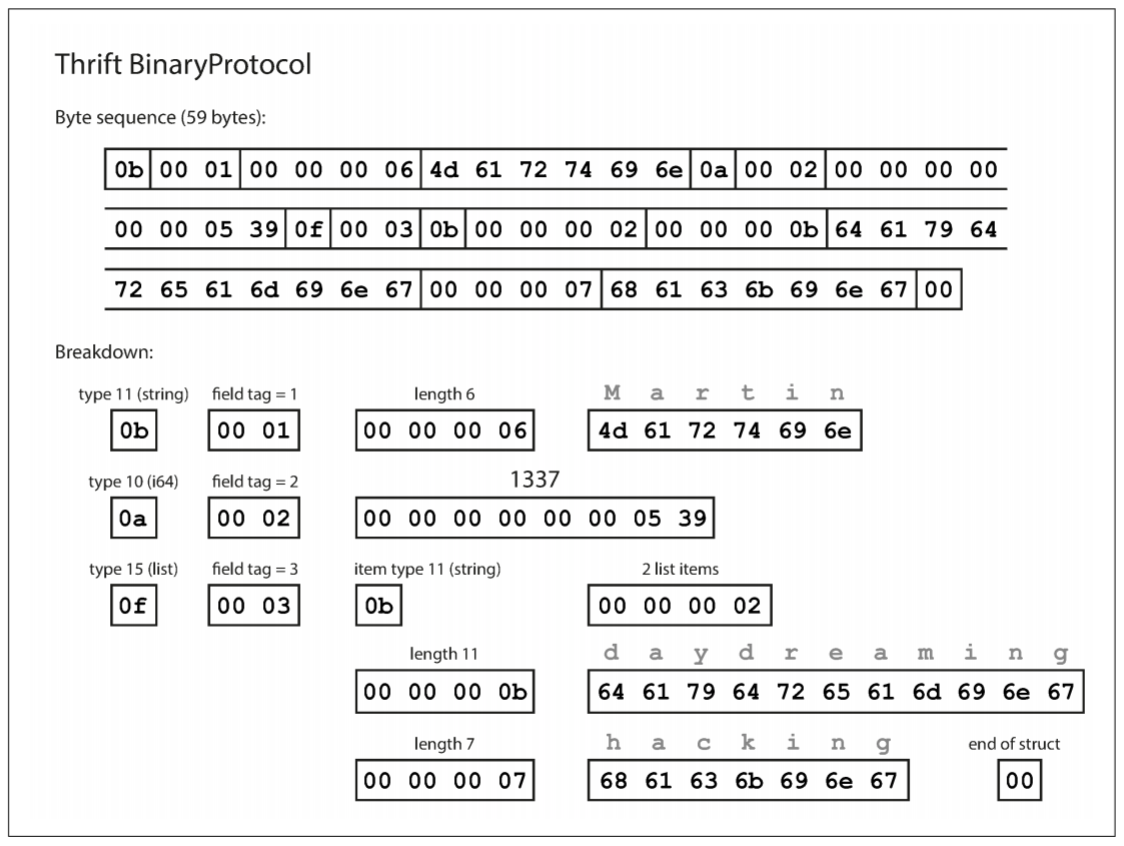
每个字段都有一个类型注释(用于指示该字段是字符串, 整数, 列表等), 还会指定长度(字符串的长度, 数组中的项目数). 字符串("Matin", "daydreaming", "hacking")以ASCII编码, 与JSON/XML相同.
与JSON/XML最大的不同在于, 二进制数据中不包含任何字段名(userName, favoriteNumber, interests). 相反, 编码数据包含field tag(字段标签), 通常是数字(1, 2, 3). 这些数字也出现在schema定义中. Field tag相当于字段的一种更紧凑的方式, 而不必拼出字段全称.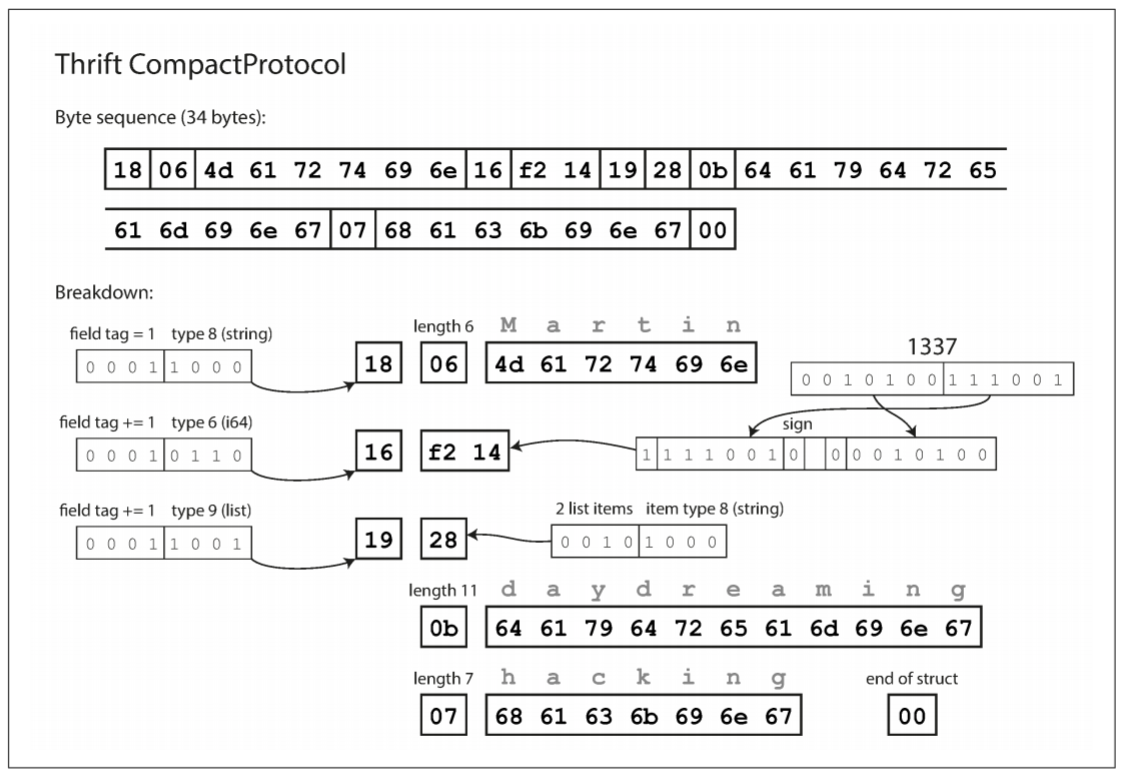
CompactProtocol编码在语义上与BinaryProtocol相同, 但只使用了34个字节. 其将字段类型和标签号打包到单个字节, 并使用可变长度整数来实现. 数字1337并没有使用8个字节, 而是2个字节编码, 每个字节的最高位用来指示是否还有更多字节. 因此, -64到63的数字占一个字节, -8192到8191的数字占两个字节.
最后是Protocol Buffer的编码, 与CompactProtocol十分相似, 使用了33个字节. 需要注意一个细节: 上述模式中, 每个字段被标记为required(必需)或optional(可选), 但并不影响编码方式. 如果字段标记为required且没有设置该字段, 则运行时检查将失败, 对捕获错误非常有用.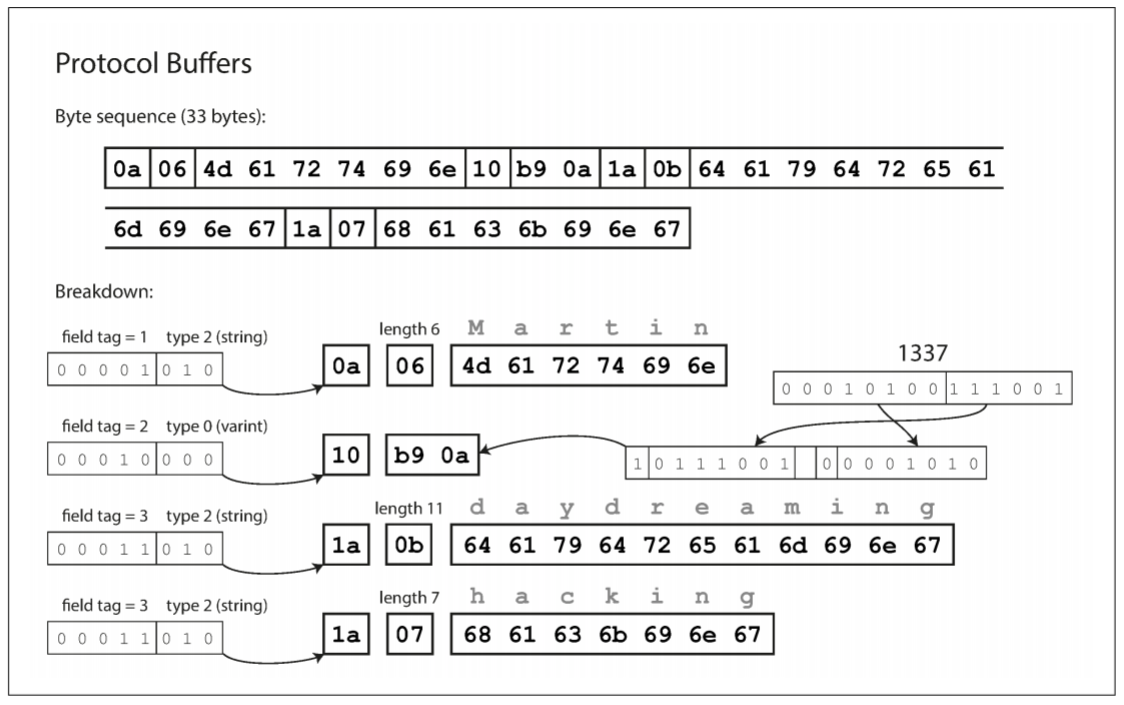
1.3.1 Field tags and schema evolution
Schema不可避免地随着时间而改变, 称为schema evolution(模式演变). Thrift和Protocol Buffer如何在模式更改时保持向前和前后兼容性?
从上一节可以看到, 编码数据就是字段的拼接. 每个字段由tag number(1, 2, 3)标识, 并用数据类型(字符串或整数)注释. 如果没有设置字段值, 则忽略该字段. 因此field tag对编码数据的含义至关重要. 无论怎么修改字段名称, 编码的数据都不会写入该字段名称. 但不能修改字段的标记, 这会导致现有编码数据无效.
我们可以添加新的字段到schema, 只要给每个字段一个新的tag number, 当旧代码读取新数据时, 由于无法识别tag number, 会直接忽略该字段. 这样保证了向前兼容性: 旧代码可读取新代码编写的记录.
只要每个字段都有唯一的tag number, 新代码总能读取旧的数据, 因为tag number仍具有相同的含义. 唯一需要注意的是, 如果添加一个新的字段, 不能将其设为required, 否则新代码读取旧数据时会失败. 因此, 为了保持向后兼容性, 初次部署schema时, 新增字段必须为optional或具有默认值.
删除字段就像新增字段, 为了向前兼容性, 只能删除optional的字段, 且不能使用被删除的tag number(旧代码可能将新字段当做被删除的字段).
1.3.2 Datatype and schema evolution
如何改变字段的数据类型? 这有可能会丢失精度. 例如, 假设要将一个32位的整数变成一个64位的整数, 新代码可读取旧数据, 但旧代码读取新数据时会用32位变量保存该值.
Protobuf有一个奇怪的细节, 其不提供list或array的数据类型, 而是用repeated标识符. 标记为repeated的字段表示同一字段会重复出现在记录中, 因此可将optional字段改为repeated字段: 新代码读取旧数据时会看到一个包含0个或1个元素的列表; 旧代码读取新数据时只能看到列表的最后一个元素.
Thrift有一个专用的列表数据类型, 可使用列表元素的数据类型进行参数化. 虽然不能像Protocol Buffer一样支持从单值到多值的更改, 但支持嵌套列表.
1.4 Avro
Apache Avro是一种和Protocol Buffer, Thrift不同的二进制编码格式. 由于Thrift不适合Hadoop的用例, 其作为Hadoop的子项目于2009年推出.
Avro也使用schema指定编码的数据结构. 其有两种模式语言: Avro IDL用于人工编辑; JSON用于机器读取. 以下是Avro IDL编写的schema:
record Person { |
等价的JSON:
{ |
首先, 该schema中没有tag number. 如果使用该schema编码上一节的案例, Avro只需32个字节, 是目前最紧凑的编码. 编码字节序列如下: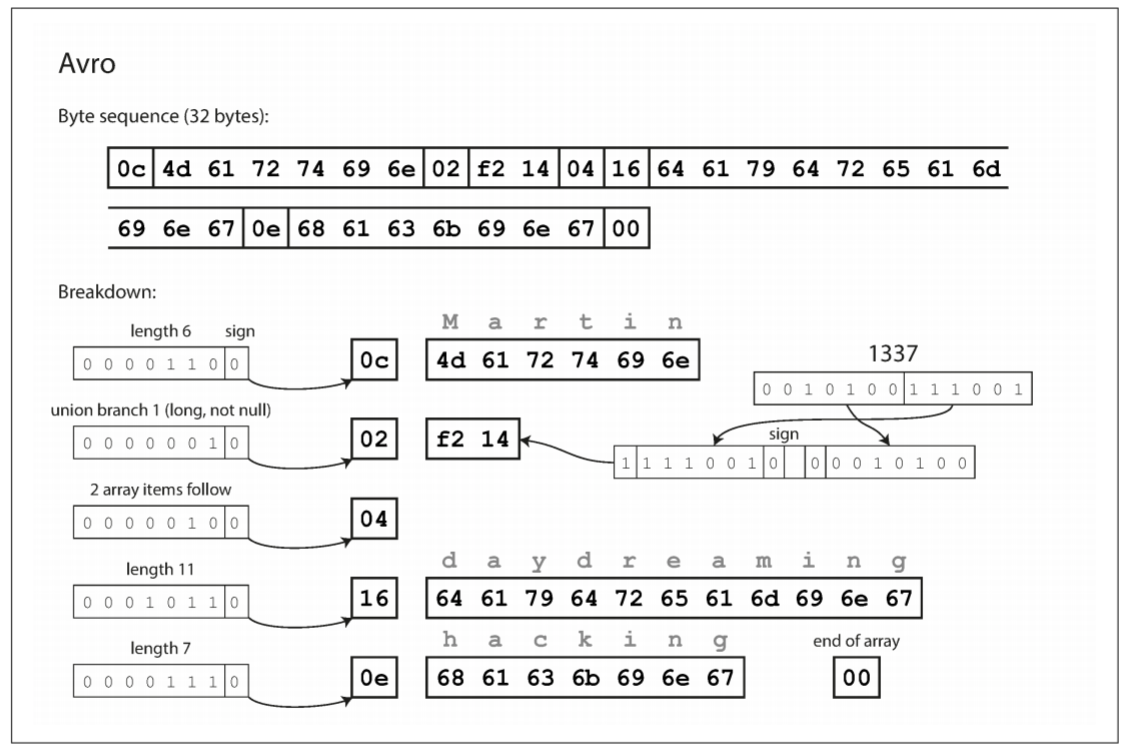
查看字节序列可以发现, 编码中没有识别字段或数据类型的标识符, 编码只是将值连接在一起. 一个字符串只有一个长度前缀和UTF-8字节, 但没有任何字节告诉我们其为字符串, 其也可以是整数, 整数使用可变长度编码.
为了解析二进制数据, 可按照它们在schema中出现的顺序遍历字段, 并使用schema来推断出字段的数据类型. 这意味着, 只有编码端和解码端使用相同schema才能正确使用. Reader和Writer之间的模式不匹配意味着错误解码数据.
1.4.1 The writer's schema and the reader's schema
当应用程序编码数据时(将其写入文件或数据库, 通过网络发送等), 可使用任何版本的schema. 例如, schema可能被编译到应用中, 称为Writer模式; 当应用解码数据时(从文件或数据库中读取数据, 从网络接收数据等), 其希望数据在某个schema中, 称为Reader模式.
Avro的关键思想在于, Writer模式和Reader模式不必相同, 只需彼此兼容. 当解码数据时, Avro库会对比writer模式和reader模式, 将数据从writer模式翻译成reader模式来解决差异. Avro规范定义了这种解析的工作原理, 如下图: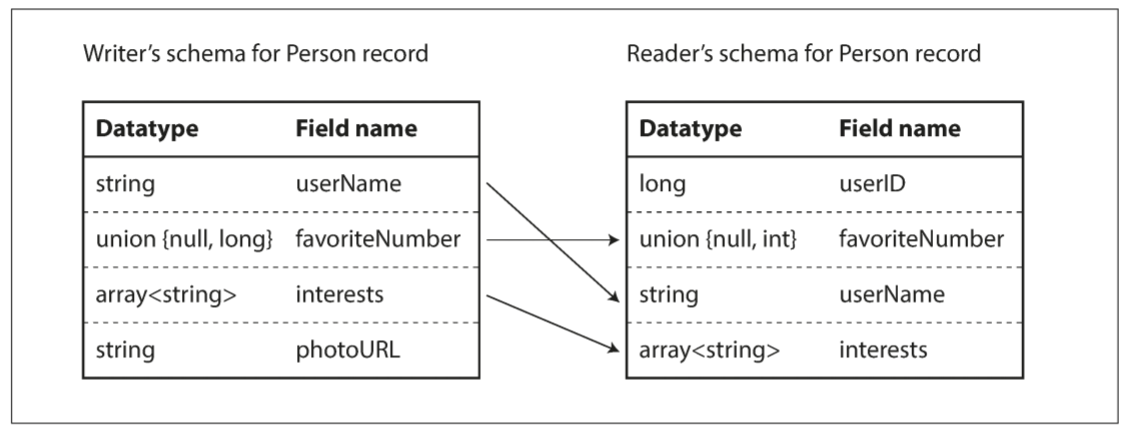
Writer模式和reader模式的字段乱序并不影响, 因为Avro通过字段名匹配. 如果扫描时发现某个字段出现在writer模式中, 但没出现在reader模式, 则忽略该字段; 若reader模式中有某个字段, 但writer模式中没有, 则使用reader模式中的默认值.
1.4.2 Schema evolution rules
Avro中, 向前兼容性意味着, writer模式是新版的, reader模式是旧版的; 向后兼容性意味着, reader模式是新版的, writer模式是旧版的.
为了保持兼容性, 只能添加或删除具有默认值的字段(字段favoriteNumber的默认值为null). 例如, 当新增一个具有默认值的字段时, 新的schema具有该字段, 旧版则没有. 若reader使用新schema, 但数据用旧schema编码, 会用默认值填充新字段.
若新增字段没有默认值, 新reader将无法读取旧writer写入的数据, 从而破坏向后兼容性; 如果删除的字段没有默认值, 旧reader将无法读取新writer写入的数据, 破坏向前兼容性. 一些编程语言中, null是任意变量都可以接收的默认值, 但Avro并不一样: 如果允许一个字段为null, 则必须使用union类型. 例如, union { null, long, string }字段, 表示该字段可以是数字, 字符串, 或null. 这要求我们必须明确规定字段是否为null, 虽然比起允许默认值为null更冗长, 但可以防止出错. 因此, Avro没有Protocol Buffer和Thrift的optional和required标记.
只要Avro可以转换相应的类型, 就可以改变字段的数据类型. 也可以更改字段名称: Reader模式可包含字段名的alias(别名), 可通过别名匹配旧Writer模式的字段名. 这意味着更改字段名称可保证向后兼容, 但不保证向前兼容. 同样, 向union中添加新的类型也是向后兼容, 而不向前兼容.
1.4.3 But what is the writer's schema?
到目前为止, 还存在一个问题: Reader如何知道一段编码数据的writer模式? 我们不能将整个schema放入每个记录, 因为schema可能比编码数据还要大, 浪费编码节省的空间. 答案取决于Avro使用的上下文, 如下:
- 有很多记录的大文件: Avro的一个常见用途, 用于存储包含数百万条记录的大文件, 所有编码都是用相同的schema, 尤其在Hadoop中. 这种情况下, writer会将schema放在文件头部. Avro制定了一个文件格式来做到这一点.
- 支持独立写入记录的数据库: 在数据库中, 不同的记录在不同时间可能使用不同的Writer模式, 因此不能假设所有记录都使用相同的schema. 最简单的解决方法是在每个编码记录的开头包含一个版本号, 并在数据库中保留每个版本的schema. Reader可接收记录, 提取版本号, 并从数据库中获取该版本号的Writer模式, 使用该模式解析记录的其他部分.
- 通过网络连接发送记录: 当两个进程通过网络进行通信时, 他们可以在创建连接时协商schema版本, 之后传输的记录都用该schema解析. Avro RPC协议就是这样工作的.
存有schema各个版本的数据库可以作为文档, 让我们检查schema兼容性. 对于版本号, 可使用递增的整数, 也可使用schema的哈希值.
1.4.4 Dynamically generated schemas
相对于Protocol Buffer和Thrift, Avro的一大优势是schema不需要包含任何tag number. 这使得Avro对动态生成的schema更友好. 例如, 假设想把一个关系数据库中内容转储到一个文件中, 并且想使用二进制格式来避免其他文本格式(JSON, CSV, SQL)的问题. 如果使用Avro, 可以很容易地从关系模式中生成一个Avro schema, 并对数据库内容编码, 放入一个Avro object container file(Avro对象容器文件)中. 可为每个表生成一个schema, 每一列都是记录的一个字段, 表的列名映射到Avro的字段名称.
如果数据库的schema发生变化(例如, 新增或删除一列), 可根据数据库的schema生成新的Avro schema, 并通过新schema编码数据. 数据导出过程无需关注schema模式的更改, 任何读取新数据文件的人都能看到记录的字段已被更改, 但由于字段通过名称标识, 因此新的Writer模式仍可与旧Reader模式匹配.
相比之下, 如果使用Thrift或Protocol Buffer, 字段的tag number可能需要手动配置: 每次数据库schema更改时, 需手动更新表列名和字段tag number的映射关系(虽然可以自动配置, 但要避免之前的tag number被重用). 自动生成schema并不是Thrift和Protocol Buffer的设计初衷.
1.4.5 Code generation and dynamically typed languages
Thrift和Protocol Buffer依赖于代码生成: 当schema被定义后, 可选择一个编程语言来生成实现该schema的代码. 这在Java, C++和C#等静态类型语言中很有用, 因为它们可将高效的内存中结构用于解码的数据, 且在IDE中编写程序时提供类型检查和自动补全.
在动态类型编程语言(如JavaScript, Ruby或Python)中, 由于没有compile-time type checker(编译时类型检查器), 生成代码没有太多意义. 由于这些语言避免了显式编译, 因此代码生成不受待见. 而且对于动态生成的schema(如从数据库表生成的Avro schema), 代码生成对获取数据是个没必要的障碍.
Avro为静态类型编程语言提供了可选的代码生成功能, 但也可以不生成代码. 如果你有一个对象容器文件, 可用Avro库打开并查看数据, 就像JSON文件一样. 这类文件是self-describing(自描述)的, 因为其包含所有必要的元数据.
该属性很适合动态类型的数据处理语言, 如Apache Pig. 在Pig中, 你可以打开一些Avro文件, 分析数据, 并将派生数据以Avro格式写入输出文件中, 无需考虑schema.
1.5 The Merits of Schemas
Protocol Buffer, Thrift和Avro都是用schema描述二进制编码格式. Schema语言比XML或JSON更简单, 但支持更丰富的验证规则(例如, 字符串值必须遵循某个正则匹配, 整数值必须介于某个数值区间). 由于Protocol Buffer, Thrift和Avro实现简单, 易用性高, 已经支持很多编程语言.
这些编码的思路并不新奇. 例如, 现代编码方式和ASN.1有很多相似之处, 而它是1984年首次被标准化的模式定义语言. ASN.1被用于网络协议, 其现在仍用编码SSL整数(X.509). ASN.1使用tag number实现schema演进, 类似于Protocol Buffer和Thrift, 但由于非常复杂度且没有配套文档, 因此不适合新兴应用程序.
很多数据系统会实现专有的二进制编码. 例如, 大多数关系数据库都有一个网络协议, 通过该协议可向数据库发送查询并获取响应. 这些协议通常特定于单个数据库, 数据库供应商提供解码的驱动程序(如ODBC或JDBC API).
尽管JSON, XML和CSV等文本数据很普遍, 但二进制编码也是一个可行方案, 其优势如下:
- 比binary JSON等变种更紧凑, 因为其省略了数据中的字段名
- Schema可作为一种有价值的文档, 因为schema是解码所必需的
- 维护一个schema的数据库可让我们检查向前和向后兼容性
- 对于静态类型编程语言的用户来说, 代码生成可在编译时进行类型检查
总而言之, schema演化和JSON数据库的schemaless/schema-on-read具有一样的灵活性.
2. Modes of Dataflow
上一节提到, 无论何时想将数据从一个进程发送到另一个非共享内存的进程, 都需要将数据编码为一个字节序列. 例如, 通过网络传输数据, 或将其写入文件; 向前和向后的兼容性对于evolvability(可演化性)十分重要, 这意味着允许独立升级系统中的不同部分, 而不必一次修改所有内容. 兼容性是编码进程和解码进程的一种关系.
数据从一个进程流向另一个进程有很多种方法, 本节将讨论进程间数据流向的常见方式:
- 通过数据库
- 通过服务调用
- 通过异步消息传递
2.1 Dataflow Through Databases
数据库中, 写入数据的进程负责编码, 读取数据的进程负责解码. 如果只有一个进程访问数据库, 那么reader只是该进程的后续版本; 换句话说, 将数据写入数据库, 可等同于向未来的自己发送数据. 因此, 向后兼容性很有必要, 否则未来的自己无法解码当前存入的数据.
一般来说, 数据库中会有多个进程同时访问. 这些进程可能是不同应用程序或服务, 或者是某个服务的不同实例(为了可伸缩性或容错性). 无论何种方式, 在应用程序不断变化的环境下, 某些访问数据库的进程可能运行新代码, 有些进程可能运行旧代码. 例如, 使用rolling upgrade(滚动升级)部署新版本代码时, 有些实例已经更新, 而其他实例还未更新.
这意味着, 数据库中的某个值可能被新版本的代码写入, 然后被旧版本的代码读取. 因此, 数据库也需要向前兼容.
除此之外还有一个问题, 当schema添加一个字段时, 新版本代码会向数据库的新字段写入数据, 随后旧版本代码读取记录, 更新并写入. 这种情况下, 即使旧代码无法解析新字段, 也要保持新字段不变.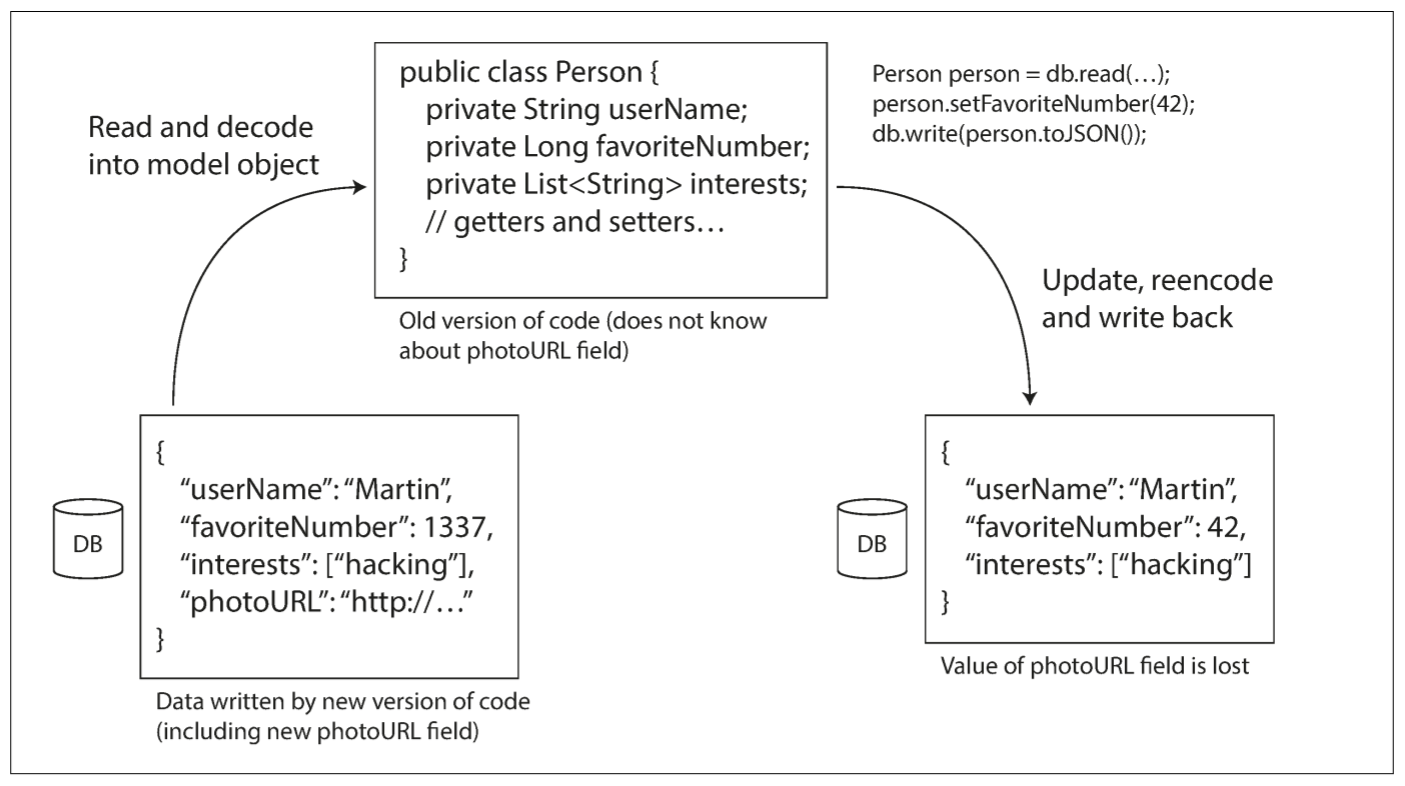
前面讨论的编码格式支持未知字段的预留, 但应用程序层面需要留意. 例如, 上图将数据库中的数据解码为应用程序的模型对象, 之后重新编码这些模型对象, 未知字段可能在翻译时丢失. 解决该问题并不困难, 但需要随时留意.
2.1.1 Different values written at different times
数据库允许在任何时间更新任何数据. 这意味着, 在一个数据库中, 有些值是5毫秒前写入, 有些值是5年前写入的. 部署新版本的应用程序时, 不到几分钟就可以将所有旧版本替换为新版本(至少server端是这样). 但数据库并非如此: 对于五年前的数据, 除非全部重写, 否则会一直保持原先的编码. 这种现象称为: data outlives code(数据的生命周期超过代码的生命周期).
可以将所有数据以新模式重写, 但如果数据集十分大, 完全重写会是一个昂贵的事情, 大多数数据库都会避免此行为. 大多数关系数据库允许在不修改数据的前提下做一些简单的schema更新, 例如, 添加一个默认值为null的新列. 当读取某一行时, 数据库会为编码数据中缺失的新列填充null. Linkedin的数据库Espresso使用Avro存储, 允许其使用Avro的模式演变规则.
因此, 模式演变让整个数据库看起来像是单一模式编码, 即使底层存储可能包含不同历史版本的模式编码记录.
2.1.2 Archival storage
我们有时会为数据库创建snapshot(快照), 例如备份或加载到数据仓库. 此时, 即使源数据库中的编码包含不同时期的schema版本, data dump(数据转储)仍可使用最新的schema进行编码. 由于复制数据在所难免, 因此最好对数据进行统一编码.
由于数据转储是一次性的, 以后也不会变, 因此Avro对象容器文件之类的格式非常适合. 也可以用Parquet进行编码, 这是一种对分析友好的面向列格式.
2.2 Dataflow Through Services: REST and RPC
当进程进行网络通信时, 有几种不同的通信方法. 最常见布局有两种角色: client和server. Server在网络上公开API, client可连接到该server并向API发送请求. Server公开的API称为service(服务).
Web以这样的流程运行: client(web browser)向web server发送请求, 通过GET请求下载HTML, CSS, JavaScript, 图像等, 并通过POST请求向server提交数据. API包含一组标准的协议和数据格式(HTTP, URLs, SSL/TLS, HTML等). 由于浏览器, server和网站开发者都认同这些标准, 因此web浏览器可访问任何网站.
Web浏览器不是唯一的client类型. 例如, 运行在移动设备和电脑的原生应用也可以向server发送请求, 一个JavaScript应用可使用XMLHttpRequest成为一个HTTP client(该技术称为Ajax). 这种情况下, server的响应通常不使用易于阅读的HTML, 而是使用client端便于处理的编码数据(如JSON). 虽然HTTP被用作传输协议, 但顶层实现的API特定于应用程序, client和server需对API的细节达成统一.
此外, server也可以作为另一个服务的client(例如, web application server可作为数据库的client), 通常用于将大型应用程序按照功能拆分为多个较小的服务, 当一个服务需要另一个服务的某些功能或数据时, 会向另一个服务发送请求. 这种构建的方式称为service-oriented architecture(SAO, 面向服务的体系结构), 也称为microservices(微服务).
在某些方面, 服务类似于数据库: 它们允许client提交和查询数据. 但数据库允许client使用query language(查询语言)查询; 而服务公开的API只允许业务逻辑规定的输入和输出. 这种限制提供了一定程度的封装: 服务对客户可以做什么和不可以做什么作出细粒度的限制.
面向服务/微服务架构的一个关键设计目标: 服务的独立部署和演化, 让应用程序易于更改和维护. 例如, 每个服务都由一个团队拥有, 该团队能频繁发布新版本的服务, 不必与其他团队协调. 换句话说, 我们应让server和client的新旧版本共存, server和client使用的数据编码应在不同版本的API之间兼容.
2.2.1 Web services
当服务使用HTTP作为底层通信协议时, 可称为Web服务. Web服务不止用于web, 也可用于其他环境, 例如:
- 运行在用户设备上的client应用程序通过HTTP向服务发送请求(例如, 移动端的本地应用程序, 或使用Ajax的JavaScript web应用程序). 这些请求通常通过公共网络进行
- 一个服务向处于同一组织的另一个服务发送请求, 这些服务通常位于同一数据中心, 作为面向服务/微服务架构的一部分(支持这种用例的软件称为middleware, 中间件)
- 一个服务通过互联网向其他组织所拥有的服务发送请求, 通常用于不同组织的数据交换. 包含在线服务(如信用卡处理系统)提供的公共API, 或用于共享访问用户数据的OAuth
Web服务有两种主流实现方法: REST和SOAP. 它们在设计哲学上针锋相对, 并在两边的支持者间引起很多争论.
REST不是一个协议, 而是一种基于HTTP的设计哲学. 其强调简单的数据格式, 使用URL来标识资源, 并使用HTTP的特性进行缓存控制, 身份验证, 和内容类型协商. 在跨组织服务集成的背景下, REST比SOAP更受欢迎, 也经常与微服务相关. 根据REST设计的API称为RESTful.
相比之下, SOAP是一种基于XML的协议, 用于制作网络API请求. 虽然HTTP中使用更广泛, 但其设计目的并不只有HTTP, 且没有使用很多HTTP功能. 反之, 它拥有庞大且复杂的标准.
SOAP Web服务的API被描述成一种基于XML的语言, 称为Web Service Description Language(WSDL, Web服务描述语言). WSDL支持代码生成, client可使用local class(本地类)和method call(方法调用)来访问远程服务. 在静态编程语言中非常有用, 但在动态编程语言中很少.
由于WSDL的设计不是为了给人类阅读, 且SOAP消息因为过于复杂而无法手动搭建, 因此SOAP的开发者很大程度上依赖于工具支持, 代码生成和IDE. 如果SOAP供应商没有支持开发者所用的编程语言, 则很难集成SOAP服务.
尽管SOAP及其各种拓展看起来很标准, 但不同厂商的实现存在互通问题. 基于以上原因, 尽管SOAP仍被大型企业使用, 但没有受到小企业的青睐.
RESTful API则更简单, 通常涉及较少的代码生成和自动化工具. definition format(定义格式, 如OpenAPI, 也称为Swagger)可用于描述RESTful API并生成文档.
2.2.2 The problems with remote procedure calls(RPCs)
Web服务仅仅是通过网络发送API请求的一系列技术的最新实现, 其中很多技术收到热捧, 但也存在严重问题. Enterprise JavaBeans(EJB)和Remote Method Invocation(RMI)受限于Java. Distributed Component Object Model(DCOM)受限于Microsoft平台. Common Object Request Broker Architecture(CORBA)过于复杂, 不具备向前或向后兼容性.
上述所有都基于remote procedure call(RPC), RPC模型会尝试向远程网络服务发出请求, 看起来与本地调用函数无异(这种抽象称为loction transparency, 位置透明). 尽管看起来很方便, 但存在一些缺陷, 以下是网络请求和本地函数调用的区别:
- 本地函数调用是可预测的, 成功与否仅取决于参数; 网络请求则不可预测: 请求或响应可能因网络问题丢失, 远程机器可能很慢或不可用, 这些问题都不可控. 网络问题很常见, 因此必须做好准备, 例如重试失败的请求.
- 本地函数调用要么返回结果, 要么抛出异常, 或永远不返回(陷入无限循环或进程崩溃). 网络请求有另一种可能性: 因网络超时而不返回结果. 这时, 我们不知道发生了什么: 如果没收到远端服务的响应, 就无法知道请求是否通过
- 如果请求被远端服务处理, 但响应在网络中丢失, 这时重传请求会导致操作被执行多次, 除非在协议中引入deduplication(去重机制, 即idempotence). 本地函数调用则没有这类问题.
- 调用本地函数时, 每次需要的时间大致相同. 网络请求比函数调用要慢的多, 且延迟也是可变的: 网络状况好的情况下, 可能一毫秒内完成; 但当网络拥塞或远程服务超载时, 可能需要几秒才能完成.
- 调用本地函数时, 可将引用(指针)指向本地内存中的对象. 当发送一个网络请求时, 所有参数都需要被编码为一个字节序列, 并通过网络传输. 如果参数是像primitive(原语, 如数字, 字符串)则没问题, 但很难处理较大的对象.
- client和service可能用不同的编程语言实现, 所以RPC框架必须将数据类型从一个语言转换为另一个语言. 由于并不是所有语言都有相同的类型(如JavaScript的整数无法超过$2^{53}$), 因此可能出现问题.
上述所有因素意味着, 让远程服务看起来像是本地函数调用毫无意义, 因为这是两个不同的事情. REST的其中一个优点在于, 并不试图掩饰自己是一个网络协议.
2.2.3 Current directions for RPC
尽管RPC有很多问题, 但并没有因此消失. 很多RPC框架使用上一节提到的编码方式: 例如, Thrift和Avro带有RPC支持, gRPC是基于Protocol Buffer的RPC实现, Finagle使用Thrift, Rest.li使用JSON over HTTP.
新一代RPC框架更加明确一个事实: 远程请求不同于本地函数调用. 例如, Finagle和Rest.li使用future(promises)来封装可能失败的异步操作. 对于需要并发发出多个请求并将其结果合并, Future可简化这种情况. gRPC支持streams, 一次调用不止含有一个请求和响应, 而是随时间的一系列请求和响应.
有些RPC框架还提供service discovery(服务发现), 即允许client找到哪个IP地址和port number对应哪个服务.
相比于JSON over REST, 二进制编码格式的自定义RPC协议拥有更好的性能. 但是, RESTful API还具有一些特有的优点: 方便实验和调试(可通过web浏览器或命令行工具curl, 无需任何代码生成或软件安装即可发送请求), 被所有主流编程语言和平台支持, 还有大量可用的工具(server, cache, load balancer, proxy, fireball, monitoring, debugging tool, testing tool等).
种种原因导致REST成为公共API的主要风格. RPC框架的重点在于同一组织内服务间的请求, 通常在同一数据中心内.
2.2.4 Data encoding and evolution for RPC
对于可演化性, RPC client和server都可以单独更改和部署. 相对于通过数据库流动的数据, 通过服务流动的数据存在一个假设: server先更新, client后更新. 因此, 只需满足请求的向后兼容性, 响应的向前兼容性.
RPC scheme的向前和向后兼容性源自其使用的编码方式:
- Thrift, gRPC(Protobuf), Avro RPC可根据相应编码格式的兼容性规则进行演变
- SOAP中, 请求和响应由XML scheme指定. 可演变, 但存在一些缺陷.
- RESTful API通常使用JSON作为响应, 已经用于请求的JSON或URI-encoded(URI编码)/form-encoded(表格编码)的请求参数. 为保持兼容性, 可在请求中添加可选请求参数, 或在响应对象中添加新字段.
由于RPC通常被用于跨组织的通信, 服务的兼容性很难实现, 服务提供商常常无法控制cient, 也无法强制client升级. 因此, 兼容性需要维持很久, 可能是无限期的. 如果对兼容性进行修改, 则服务提供商需同时维护多个版本的服务API.
API的版本化没有一个确切答案(例如, client如何声明其使用的API版本). 对于RESTful API, 通常方法是在URL或HTTP Accept header中使用一个版本号. 如果服务使用API密钥来标识特定client, 可将client请求的版本号保存在server中, 并通过单独的管理界面更新版本选项.
2.3 Message-Passing Dataflow
到目前为止, 我们讨论了从一个进程到另一个进程的不同编码数据的方式, 如REST和RPC(一个进程通过网络向另一个进程发送请求, 并期望尽快获得响应), 以及数据库(一个进程写入编码数据, 另一个进程稍后读取数据). 最后我们将介绍asynchronous message-passing system(异步信息传递系统), 其介于RPC和数据库之间. 它与RPC类似: client的请求(通常称为message, 消息)以低延迟传送到另一个进程; 它也与数据库相似: 消息并不通过网络传输, 而通过message broker(消息代理, 也称为message queue或message-oriented middleware)作为中介, 用于临时保存消息.
与RPC相比, 消息代理有以下几点好处:
- 如果接收端不可用或超载, 可作为缓冲区, 提高系统可靠性
- 自动将消息重新发送到已崩溃的进程, 防止消息丢失
- 避免发送端需要知道接收端的IP地址和端口号(在虚拟机经常出入的云部署中十分有用)
- 允许一条消息发送给多个接收端
- 将发送端和接收端解耦(发送端只需要发布消息, 不需要在意谁接收)
然而, 与RPC相比, 这种消息传递是单向的: 对于发出的消息, 发送端无需接收任何响应. 进程发送一个响应也是可能的, 但通常需要另一个单独的channel(通道). 这种通信方式是asynchronous(异步的): 发送端无需等待响应, 发送后就可以做其他事情.
2.3.1 Message brokers
在过去, 消息代理被TIBCO, IBM WebSphere和webMethods等商业软件统治. 最近像RabbitMQ, ActiveMQ, HornetQ, NATS, Apache Kafka这样开源实现已经流行起来.
具体delivery semantic(交付语义)因实现而异, 但通常来说, 消息代理的使用方式为: 一个进程向queue(队列)或topic(主题)发送信息, broker保证消息传递给一个或多个consumer(消费者)或subscriber(订阅者). 同一个主题下可有多个producer和多个consumer.
一个topic仅提供一个单向数据流. 然而, 一个consumer本身可能是另一个topic的producer, 或将消息发送给原本的发送者.
消息代理中的消息只是包含元数据的字节序列, 可使用任何编码格式. 如果编码具有向前和向后兼容性, 我们可以对publisher和consumer的编码进行独立的修改, 并以任意顺序进行部署.
如果consumer重新发布信息到另一个topic, 需要保留未知字段, 防止数据丢失.
2.3.2 Distributed actor frameworks
Actor model是单进程内的并发编程模型. 与其直接操作线程, 不如将逻辑封装在actor中. 每个actor代表一个client或entity, 其包含一些本地状态(不与其他任何角色共享), 通过发送和接收异步消息与其他actor通信. 消息传送不受保证: 在特定错误场景中, 消息可能丢失. 由于actor同一时间只能处理一个消息, 因此无需担心产生竞争, 且每个actor都可由框架独立调度.
在distributed actor framework(分布式Actor框架)中, 此编程模型用于跨多个节点伸缩的应用程序. 无论sender和recipient是否处于同一节点, 都可使用相同的消息传递机制. 如果他们在不同节点, 则该消息被编码为字节序列, 通过网络发送, 并在另一侧解码.
Actor model的位置透明比RPC效果更好, 因为actor model已经假定消息可能丢失, 即使在单个进程中也是如此. 尽管网络延迟比进程延迟更高, 但使用actor model时, 本地和远程通信之间的不匹配较少.
分布式actor框架将消息代理和actor编程模式集成到一个框架中. 但是, 如果基于actor的应用程序执行滚动升级, 仍需注意向前和向后兼容性问题, 新版本节点的消息可能发送给旧版本节点, 反之亦然.
三种分布式actor框架处理消息编码的方式如下:
- Akka默认使用Java内置的序列化, 不提供向前或向后兼容性. 但是, 你可以使用Protocol Buffer代替, 从而实现滚动升级.
- Orleans默认使用自定义的数据编码格式, 不支持滚动升级部署. 为了部署新版本, 可以设置一个新集群, 将流量从旧集群迁移到新集群, 然后关闭旧集群.
- 在Erlang OTP中, 无法修改record schema(尽管系统具有为高可用性设计的功能). 是可能滚动升级, 但需要仔细计划. 一个新的实验性的maps数据类型可能使得这个数据类型在未来更容易.