Reliable, Scalable, and Maintainable Applications
现代应用更多的是data-intensive(数据密集型), 而不是compute-intensive(计算密集型). CPU算力已不是性能瓶颈, 更多的问题出现在数据的规模, 数据的复杂度, 和数据更改的速度.
Data-intensive应用通常由多个standard building block(标准组件)组成, 这些组件提供了所需的功能. 举个例子, 很多应用都会用到如下组件:
- database: 存储数据, 以便自己或其他应用之后访问该数据
- cache: 记录一个开销昂贵的操作的结果, 以加快读取速度
- search index: 允许用户通过keyword搜索数据, 或通过filter过滤数据
- stream processing: 向其他应用发送消息, 让数据实现异步处理
- batch processing: 定期处理大量积累的数据
如果上述听起来太显而易见, 正说明data system(数据系统)是一种很成功的抽象. 虽然一直在使用它, 但从未思考太多. 当创建一个应用时, 绝大多数工程师不会从头写一个新的数据存储引擎, 因为现有的数据系统已可完美地完成任务.
但现实总是复杂的. 由于不同应用有不同要求, 因此各种数据系统具有不同的特性. 实现cache的方式有很多, 实现search index的方式也有很多. 当创建应用时, 需要明白哪个工具最匹配应用需求. 且当单个工具无法满足需求时, 需将多个工具组合在一起.
我们将探究数据系统的原理和实践, 以及如何使用这些工具来创建数据密集型应用. 我们还将区分各个工具的异同, 以及他们如何实现各自的特性. 本章将讨论每个数据系统的基本目标: reliable(可靠性), scalable(可拓展性), maintainable(可维护性).
1. Thinking About Data Systems
我们通常认为database, queue, cache等, 是不同类型的工具. 虽然database和message queue表面上存在共通之处: 都用于存储数据. 但其实它们有不同的数据访问方式, 从而决定了不同的性能, 因此也有不同的实现.
所以我们为何将这些工具统一称为data system? 最近几年出现了很多新的数据存储和处理工具. 它们都针对不同的使用场景做出优化, 也不能再被归为传统类型. 例如, database可作为message queue(Redis), message queue也可拥有类似数据库的持久性保证(Apache Kafka). 不同类别的边界变得越加模糊.
其次, 越来越多的应用都不满足于单个工具实现数据处理和存储. 相反, 任务会被拆分为多个小任务, 这些小任务由各自工具完成, 并经由应用代码缝合. 例如, 如果将cache layer(缓存层, 使用Memcached或其他工具), 或full-text search server(全文搜索服务器, 如Elasticsearch或Solr)从主数据中分离, 那么应用代码就需负责同步主数据库和cache/index中的数据. 下图为一种可能的架构, 其数据系统包含多个组件: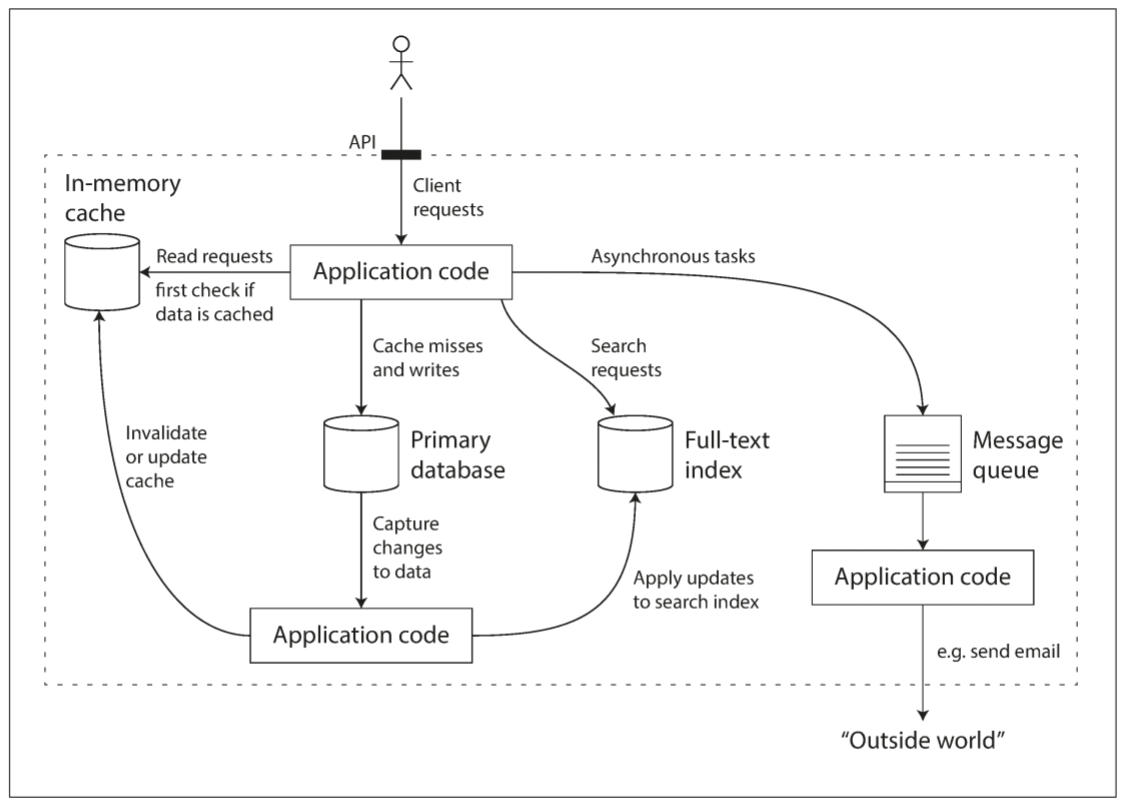
将多个工具结合在一起并提供服务时, 服务的接口或API通常会隐藏技术细节. 当使用多个较小的通用组件来创建一个全新的数据系统时, 该复合数据系统应提供一些保证, 例如: cache应被正确地修改和无效化, 保证外部client看到相同结果. 我们不仅是应用开发者, 也是一个数据系统设计者.
设计数据系统或服务时, 难免出现很多问题. 当系统内部出现错误时, 如何确保数据的正确性和完整性? 当部分系统被降级时, 如果确保性能不滑坡? 如何处理增长的负载? 一个好的API是什么样子?
设计一个数据系统有很多影响因素, 包括开发人员的技术, 工作经历, 对legacy system(遗留系统)的依赖, 交付时间, 上级对不同类型风险的容忍度, 监管限制等. 上述因素会因不同情况而变得大不相同, 这里我们只关注三个方面:
- Reliability(可靠性): 即使遇到一些困境(硬件或软件故障, 或人为失误), 系统仍能正确运行(以所需的性能水平执行正确的功能)
- Scalability(可拓展性): 随着系统规模的增长(数据量, 流量, 复杂度), 系统有方法处理这种增长
- Maintainability(可维护性): 随时间推移, 新老员工都能高效地为系统工作(既要维持当前的功能, 也要为系统添加新功能)
2. Reliability
每个人对Reliability都有不同的理解. 对于软件开发, Reliability应满足以下期望:
- 满足用户需求的功能
- 容忍用户犯错或以非常规方式使用
- 在预期的负荷和数据量下, 满足性能需求
- 防止未经授权的访问和滥用
若上述都能得到满足, 则系统具有reliability. 粗略地说, 能在犯错时依然正确运行, 即称为reliability.
出错的部分称为fault(故障); 若系统能预料并应对fault, 则称为fault-tolerant(容错)或resilient(弹性的), 前者有一定的误导性, 会让人觉得系必须能承受所有故障, 实际上并不现实, 地球被黑洞吸入也会导致服务器故障, 而我们讲的只包含特定类型的故障.
注意, fault并不等同于failure(崩溃). fault通常定义为系统的某一组件偏离其标准; failure是系统作为一个整体停止向用户提供服务. 我们永远无法将fault的发生概率降到0, 只需要设计容错机制来防止fault造成failure.
可通过人为地触发fault来增加fault发生的概率, 比如随机kill某个进程. 之所以系统中存在许多bug, 就是因为没有很好的错误处理. 通过人为制造fault, 可以测试并确保容错机制正确工作. Netflix的Chaos Monkey就是其中一种制造fault的方式.
虽然我们倾向于容错而不是防止出错, 但预防总比治疗好. 安全问题就属于这类问题, 当攻击者控制系统并获取敏感数据时, 事情会变得无法挽回.
2.1 Hardware Faults
硬件故障往往是最容易想到的问题. 硬盘崩溃, RAM报错, 电网停电, 意外拔掉网线. 数据中心的工作人员几乎每天都能遇到上述情况.
硬盘的平均MTTF(失效时间)为10到50年. 假设一个存储集群有10000个磁盘, 平均每天就有一个磁盘失效. 为降低系统崩溃的概率, 第一反应是为单个硬件增加冗余度. 例如: 磁盘可以组成RAID, 服务器可拥有双电源和热插拔CPU, 数据中心可有自己的电池和柴油发电机. 当某个组件崩溃时, 可用其他部件替代, 并替换损坏的部件. 这种方法不能完全杜绝硬件故障引起的failure, 但易于理解, 且能保证单个机器多年不间断运行.
直到最近, 由于单个机器故障的概率十分罕见, 硬件冗余已可满足大多数应用. 只要能将备份快速转移到新的机器, 对于大多数应用来说故障时间都不是很严重, 只有少数高可用性要求的应用才需要多套硬件冗余.
然而, 随着数据量和计算量要求的不断增加, 越来越多的应用开始使用大规模机器, 导致硬件故障率变增加. 此外, 在一些云平台上, 例如Amazon Web Services(AWS), 虚拟机实例会在毫无预警的情况下变得不可用, 因为云平台优先考虑的是flexibility(灵活度)和elasticity(弹性), 而不是单机可靠性.
因此, 如果在硬件冗余的基础上使用软件容错技术, 系统就可容忍整机丢失的情况. 这种系统还具有操作优势: 如果想重启机器, 单服务器系统需要一个预定的停机时间(例如安装系统安全补丁), 而容许整机故障的系统不需要停机时间也能修复节点.
2.2 Software Errors
硬件故障通常被认作是独立且随机的: 单个机器上的磁盘损坏并不会导致其他机器的磁盘受影响. 硬件间可能存在弱相关性(由于某些原因导致机房的温度上升), 但几乎不可能出现大面积硬件故障.
另一类故障为systematic error(系统性错误). 这类故障更难以预测, 因为它们是跨节点的, 比起硬件故障, 这类故障更有可能导致system failure(系统崩溃), 例如:
- 特定错误输入导致的软件bug, 从而引发应用服务器中的所有实例崩溃. 例如, 2012年6月30日的闰秒会触发Linux Kernel中的一个bug, 从而导致应用崩溃
- 失控进程耗尽共享资源, 包括CPU时间, 内存, 磁盘空间, 或网络带宽
- 系统所依赖的服务变慢, 无响应, 或返回错误响应
- 级联故障, 组件中的小故障触发另一个组件中的故障, 最终导致越来越多的故障
导致软件崩溃的bug通常会潜伏很久, 直到某个特殊情况下被触发. 这意味着软件对其环境做出了某种假设: 这种假设一般情况下是正确的, 但在特殊情况下不成立.
对于软件中的系统故障, 没有一个快速解决的方案, 但有很多小方法: 仔细考虑系统中的假设和交互; 彻底的测试; 进程隔离; 允许进程崩溃和重启; 测量, 监控并分析生产环境中的系统行为. 如果系统能提供一些保证(例如, 在一个消息队列中, 传入的消息数等同于传出的消息数), 就能在运行时不断检查自身, 并在发现discrepancy(差异)时预警.
2.3 Human Errors
软件系统由人类设计并构建, 人类也负责系统的维护, 但人是不靠谱的. 举个例子, 一项针对大型互联网服务的研究表明, 配置错误是导致崩溃的主要原因, 硬件故障只占到10%到25%. 那么如何让系统更加可靠? 以下是几种可组合使用的方法:
- 以最小化犯错的方式设计系统. 精心设计的抽象, API, 和管理界面都可让操作人员更轻松地做出正确操作, 并减少错误操作的出现概率. 但若接口限制过多, 人们会忽视其好处并选择绕过, 因此需要找到一个平衡点
- 将人们经常犯错的地方和经常导致崩溃的地方分离. 提供一个功能齐全的non-production沙盒, 人们可使用真实数据安全地探索和测试, 而不会影响到真实用户.
- 对各个级别进行彻底测试, 从单元测试, 到系统集成测试, 再到手动测试. 自动化测试被广泛应用, 易于理解, 且能覆盖corner case(边缘情况).
- 允许从人为错误中快速恢复, 以减小崩溃带来的影响. 举个例子, 快速回滚配置更改, 回滚新代码, 并提供工具来重新计算数据
- 设置详细且清晰的监控, 如性能指标和错误率. 其他工程学科中称为telemetry(遥测, 一旦火箭离开地面, 遥测负责跟踪发生的一切, 以帮助理解失败原因). 监控会向我们展示一些预警信号, 并检查系统是否违反某些假设或限制. 当错误发生时, 指标数据对于诊断问题十分宝贵.
- 良好的管理和充分的培训
2.4 How Important Is Reliability?
Reliability(可靠性)不光适用于核电站和空中交通管理软件, 其他应用也需要可靠地运行. 商业应用中的bug会导致生产力的损失(还会伴随着法律风险), 电子商务网站的崩溃带来收入损失和名誉受损. 即使在一些"非关键"的应用上, 我们也应对用户负责. 若一个父母将所有他们和孩子的照片全部存在你的相片应用中. 数据损坏时他们会是怎样的心情? 他们又如何从备份中恢复? 在某些情况下, 我们可能会选择牺牲可靠性来降低开发成本(为未经证实的市场开发产品原型)或运维成本(利益率极低的服务), 但需保持警惕.
3. Scalability
即使一个系统今天能稳定工作, 也代表未来能稳定工作. degradation(降级)的其中一个原因为负载增加: 系统的同时在线人数负载从10,000增加到100,000, 或从百万增加到千万, 现在处理的数据量级可能比过去大很多.
Scalability(可拓展性)是一种系统应对负载增加的能力. 注意, scalability并不是一个一维标签: "X具有可拓展性", "Y没有可拓展性", 这类陈述没有意义. Scalability需考虑以下问题:
- 若系统以特定方式增长, 如何应对这种增长
- 如何为额外负载增加计算资源
3.1 Describing Load
首先我们要描述系统的当前负载, 然后讨论负载增加问题(负载翻倍会发生什么). 用于描述负载的数值称为load parameter(负载参数). 参数的选择取决于系统的架构: 可能是web服务器的每秒请求数, 数据库的读写比, 聊天室内同时活跃的用户数, 缓存的命中率, 或其他东西. 或许平均情况对你很重要, 或许系统瓶颈取决于少数极端情况.
为了使该概念更清晰, 我们以Twitter于2012年11月发布的数据为例. 以下是Twitter的两个主要业务:
- Post tweet: 用户向其follower发送信息(平均4.6k请求/秒, 峰值为12k请求/秒)
- Home timeline: 用户浏览其follow的人所发的tweet(300k请求/秒)
每秒12,000次的写入处理起来比较简单. 然而, Twitter的挑战不是tweet量, 而是fan-out(扇出): 每个用户都关注了很多人, 也被很多人关注. 大体上有两种实现方式:
- 发送tweet只需将tweet存入tweet集合中. 当用户请求主页的timeline时, 查找他们关注的所有人, 找到他们的所有tweet, 并按时间顺序合并. 关系型数据库中查询如下:
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user
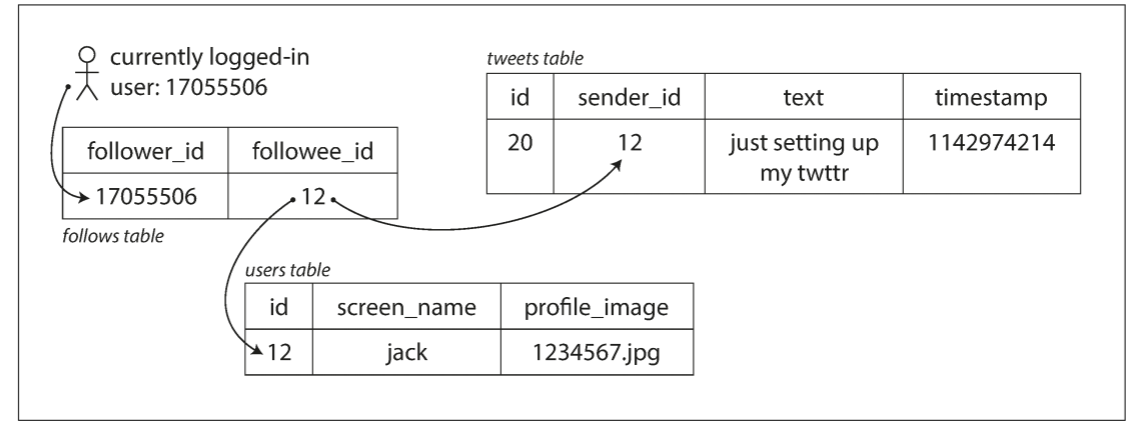
- 为每个用户维护各自的主页timeline, 类似于为每个收件人准备一个tweet邮箱. 当某个用户发布tweet时, 查询其所有follower, 并将该tweet加入到他们timeline cache中. 这时, 读取主页timeline的请求开销很小, 因为结果已被提前计算好.
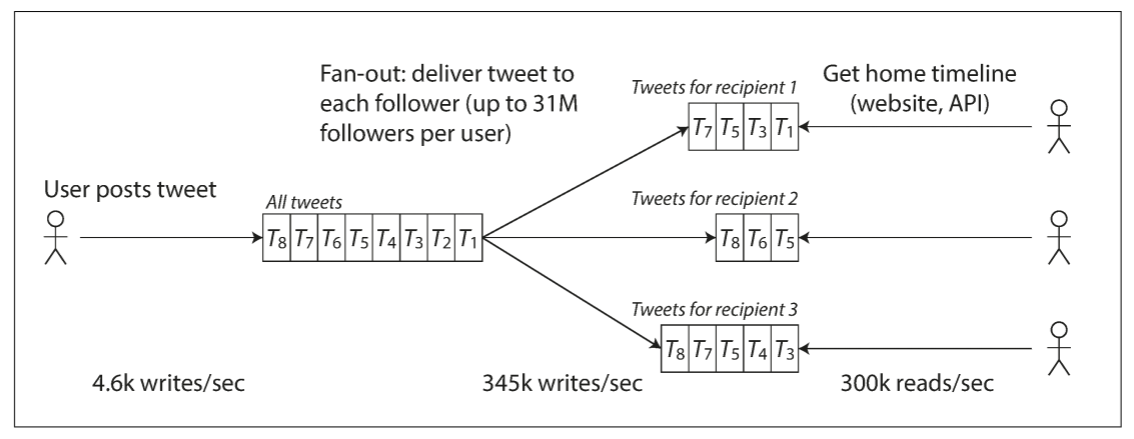
Twitter的第一个版本使用第一种方法, 但系统难以承受timeline查询的负载增加, 因此公司转而使用第二个方法. 该方法效果更好, 因为tweet发布速率远低于timeline读取速率. 因此写入时多做一些操作, 读取时能少做一些操作.
然而方法二的缺点在于, 发布一个tweet需做大量额外工作. 平均而言, 一条tweet需要推送给75个follower, 4.6k/sec的tweet发布则需要timeline cache中每秒345k的写入. 但平均值掩盖了一个事实: 用户间的follower数量差异巨大, 有些用户的follower数超过三千万, 这些用户每次发布tweet都需要进行三千万次写入. 由于twitter需在5秒内向所有follower推送, 这种操作成为一个巨大挑战.
上述例子中, 用户的follower分布决定了fan-out负载, 该变量是讨论scalability的关键负载参数. 不同应用有不同特性, 可用相似的原则来考虑负载.
Twitter现在已开始实现第二种方法, 并逐步转向两种方法的混合使用. 大多数用户的tweet会写入到timeline cache, 一小部分拥有大量粉丝的用户发tweet时不会写入cache. 当用户读取timeline时会分别获取已关注的名人的tweet, 再与timeline cache合并.
3.2 Describing Performance
一旦能够描述系统负载, 就可以研究负载增加时会发生什么. 以下是两种角度:
- 当负载参数增加, 且系统资源(CPU, 内存, 网络带宽等)保持不变, 系统性能会受到什么影响
- 当负载参数增加, 需增加多少资源来保持性能不变
上述两个问题都需要性能数据, 因此需先描述一下什么是系统性能. 在批处理系统(如Hadoop)中, 通常关心的是throughput(吞吐量), 也就是每秒处理的记录数, 或特定规模的数据集中运行一项工作的总时长. 对于在线系统, 服务的response time(响应时间)更重要, 也就是client发送请求与接收回复之间的时间间隔.
即使发送相同的请求, 每个请求的响应时间也会略微不同. 实际中, 系统会处各式各样的请求, 响应时间也会天差地别. 因此我们不能将响应时间看作单个数值, 而是一个数值分布.
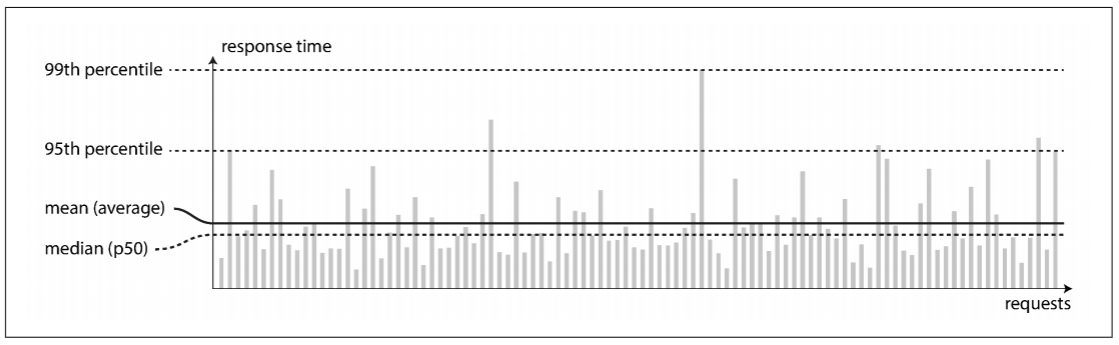
上图中每个灰色柱表示一次请求, 其高度表示请求处理的时间. 大多数请求都非常快, 但偶尔会出现更长时间的异常值. 也许因为该请求的操作昂贵, 例如, 需要处理更多数据. 但有些情况下, 即使我们认为所有请求都使用相同时间, 实际上依然存在波动, 例如: 上下文切换到后台进程, 网络丢包与TCP重传, 垃圾回收导致的时停, 读取时遭遇磁盘的page fault, 服务器机架的振动等.
通常报表都会展示服务的平均响应时间(严格来说, "平均"并不指代任何公式, 但实际上可理解为算数平均值: 给定n个值, 相加之和除以n). 但均值并不是一个很好的指标, 因为我们无法获知有多少用户经历过该延迟.
Percentiles(百分位)更适合描述响应时间. 如果将所有响应时间从低到高依次排序, 其median(中位数)就是中间的数值: 例如, 若中位数为200ms, 意味着一半的响应时间小于200ms, 还有一半高于200ms.
如果想知道真实场景中用户的等待时间, 中位数是一个很好的标准: 一半用户的响应时间小于中位数, 另一半的用户的响应时间大于中位数. 中位数也称为50th percentile(第五十个百分位), 缩写为p50. 注意, 中位数只关乎单个请求, 如果用户发出多个请求, 则至少有50%的概率其中一个请求比中位数慢.
为了弄清楚异常值有多糟糕, 可观察更高百分位, 如95th, 99th, 99.9th percentile(缩写为p95, p99, p999). 这些百分位表示快于95%, 99%, 或99%的响应时间的阈值. 举个例子, 假设95th percentile的响应时间为1.5秒, 意味着95%的响应时间小于1.5秒, 100个请求里有5个响应时间超过1.5秒.
响应时间的高百分位(也称为tail latency, 尾部延迟)非常重要, 因为该值直接影响用户的服务体验. 举个例子, Amazon以p999作为响应时间为准, 因为响应最慢的客户往往是数据最多的客户, 也就是最有价值的客户. 保证网站快速响应对用户满意度十分重要: Amazon发现, 每增加100ms响应时间, 销量就会减少1%; 也有一些报告说, 每慢1秒, 用户满意度减少16%.
另一方面, 优化p9999成本过高, 并且无法产生足够的效益. 因为随机事件的影响, 减少p9999的响应时间十分困难, 收益也会减少.
Percentile经常用于SLO(service level objectives, 服务级别标准)和SLA(service level agreement, 服务界别协议), 这两者定义了服务预期性能和可用性. SLA可能会声明: 若响应时间的中位数小于200ms, 且p99小于1s, 则说明服务可用. 这些指数为client设置了期望值, 允许用户在SLA未达标时申请退款.
Queue delay(排队延迟)通常占据高百分位响应时间的很大一部分. 由于服务器只能并行处理少量事务(例如, 限于CPU核数), 因此少量缓慢的请求就能阻塞后面的请求, 也称为head-of-line blocking(头部阻塞). 即使后续请求能被快速处理, 由于需等待先前请求完成, 对于client来说响应还是很缓慢. 因此从client端测量响应时间非常重要.
为测试系统的可拓展性而人为产生负载时, 产生负载的client要独立于响应时间不断发送请求. 如果client在发送下一个请求时需要等待上一个请求完成, 则会产生人为排队的效果, 测试产生的队列比真实情况更短.
3.3 Approaches for Coping with Load
我们已经讨论过用于描述负载的参数, 和用于衡量性能的指标. 现在开始讨论可拓展性: 当负载参数增加时, 如何保持高性能.
适用某一负载级别的架构不大可能应付10倍于此的负载. 如果正处于快速扩张的业务中, 每当系统负载上升一个数量级, 都需考虑重新设计架构, 甚至更频繁. 人们经常将拓展二分为scaling up(纵向拓展, veritical scaling, 也称为垂直拓展, 转移到性能更强的机器)和scaling out(横向拓展, horizontal scaling, 也称为水平拓展, 将负载分摊到多个小机器上). 跨多个机器的负载分配也称为shared-nothing(无共享)架构. 将系统放在单个机器上会更加简单, 但高端机器更贵, 因此水平拓展在所难免. 事实上, 好的架构通常会结合这两种方法, 使用几个性能强劲的机器可能会比多个虚拟机更简单, 更便宜.
有些系统是elastic(弹性的), 意味着负载增加时, 会自动增加计算资源, 其他系统则需要手动拓展(人工计算容量并决定是否向系统添加机器). 若负载难以预测, 则弹性系统十分有用, 但手动拓展系统往往更加简单, 且意外操作更少.
将stateless service(无状态服务)部署在多台机器上比较简单, 将有状态的数据系统从单个节点变为分布式配置则可能引入额外复杂度. 因此, 通常将数据库放在单个节点上(纵向拓展), 直到拓展成本或者可用性需求迫使系统转向分布式. 由于分布式系统的工具和抽象越来越好, 对于某些应用, 上述方法可能会改变. 未来即使应用无需处理大量的数据或流量, 也可能默认使用分布式数据系统.
大规模运行的系统往往有专属架构, 不存在一种通用的, 一刀切的可拓展架构. 系统的瓶颈可能是数据的读取, 写入, 存储, 数据的复杂度, 响应时间的要求, 访问模式, 或上述多个因素. 例如, 一个系统每秒处理100,000个请求, 每个请求2kB大小; 一个系统每分钟处理3个请求, 每个请求2GB大小. 两个系统虽然吞吐量相同, 但设计上完全不同.
一个适用特定应用的系统架构往往围绕某些假设构建: 哪些操作常见, 哪些操作罕见. 如果假设错误, 则拓展无效, 甚至导致系统效率下降. 在初创公司或未经验证的产品中, 快速添加产品功能通常比拓展负载重要.
虽然架构为每个应用定制, 但架构也是由很多通用的组件构建而成, 并由常见的模式排列.
4. Maintainability
众所周知, 软件的大多数开销不是初始开发, 而是后续维护, 包括修复bug, 维护系统运行, 调查故障, 适配新平台, 针对新用例进行修改, 偿还技术债, 添加新功能等.
然而, 很多软件开发人员不喜欢维护"lagecy system"(遗留系统), 这涉及修复他人的错误, 使用过时的平台, 被迫做一些非系统设计目的的功能. 每个遗留系统都有各自的不愉快之处, 因此很难给出通用意见.
因此在设计软件时, 应该尽量减少维修的痛苦, 避免软件变成遗留系统. 为此我们需关注软件系统中的三个设计原则:
- Operability(可操作性): 运维团队能够轻松地保持系统运行
- Simplicity(简单性): 尽量减少系统复杂度, 让新入职的工程师能轻松地理解系统
- Evolvability(可进化性): 使工程师能够轻松地对系统进行修改, 当需求更改时为新场景做适配, 也称为extensibility(可拓展性), modifiablity(可修改性), 或plasticity(可塑性)
与reliability和scalability不同, 上述目标没有一个通用解决方案. 不过我们可以想象具有operability, simplicity和evolvability的系统是什么样的.
4.1 Operability: Making Lift Easy for Operations
有人认为: 好的运维能绕开垃圾软件的局限性, 但好的软件不能在垃圾运维下可靠运行. 虽然操作可以自动化, 但其正常运行仍取决于人. 运维团队对于软件系统是够能平稳运行至关重要, 一个好的运维团队的主要职责如下:
- 监控系统的运行状况, 并在服务状态不佳时快速恢复服务
- 追踪问题原因, 如系统故障或性能下降
- 及时更新软件和平台, 如安全补丁
- 密切关注不同系统的相互影响, 以免造成损失
- 预测未来可能发生的问题, 并在其发生前解决
- 为部署, 配置管理等建立良好规范和工具
- 执行复杂的维护任务, 如将一个应用从一个平台迁移到另一个平台
- 配置改动时, 保持系统的安全性
- 制定工作流程, 让操作可预测, 并保持生产环境的稳定
- 即使新人到来, 或老员工离职, 也能保持组织对系统的了解
良好的可操作性会让日常任务变得简单, 让运维团队把精力放在更有价值的事情上. 数据系统可以让日常任务变得简单:
- 通过良好的监控, 可提供对运行时行为和系统内部状态的visibility(可见性)
- 将系统与标准化工具集成, 为自动化提供支持
- 避免依赖单个机器(允许系统正常运行下停机维护)
- 提供良好的文档和易于理解的操作模式
- 提供良好的默认行为, 但也允许管理员覆盖默认值
- 在适当情况下自我修复, 但也允许管理员手动控制系统状态
- 行为可预测, 最大限度减少意外
4.2 Simplicity: Managing Complexity
小型软件有着简单且表现力强的代码, 但随着项目越来越大, 代码会变得非常复杂且难以理解. 这种复杂度拖慢了所有人的工作效率, 进一步增加了维护成本. 一个陷入复杂泥潭的项目称为a big ball of mud(大泥球). 复杂度有很多可能的症状: 状态空间的激增, 模块间的紧密耦合, 错综复杂的依赖关系, 不一致的命名和名词, 解决性能问题的奇淫巧技, 需要绕开的特例等.
由于复杂度导致维护困难, 预算和预计时间通常会超支. 复杂的系统中的修改往往会带来bug: 当开发者难以理解系统时, 隐藏的假设, 无意的后果, 和意外的交互都容易被忽略. 相反, 降低复杂度能极大地提高软件的可维护性, 因此Simplicity应作为构建系统的一个关键目标.
让系统变得更简单不意味着减少功能, 而是消除额外的复杂性. Moseley和Marks把额外复杂度定义为: 具体实现所引起的复杂度, 而不是问题本身带有的复杂度.
消除额外复杂度最好的工具之一为abstraction(抽象). 一个好的抽象可将大量实现细节隐藏在一个清晰且易于理解的外表下. 一个好的抽象也可用于不同应用. 比起反复实现类似的功能, 这种重用效率更高, 也有助于软件的质量. 例如, 高级编程语言就是一种抽象, 其隐藏了机器码, CPU寄存器, 系统调用. SQL也是一种抽象, 其隐藏了复杂的磁盘和内存数据结构, 多个client的并行请求, 崩溃后的不一致性. 当然, 使用高级编程语言时其实仍在使用机器码; 只不过没有直接使用.
4.3 Evolvability: Making Change Easy
系统要求不可能一成不变, 系统需求也永远在改变, 例如: 了解到新的事实, 出现未预料的场景, 业务优先级的更改, 用户要求新功能, 平台的变更, 法律和监管的变更, 系统增长迫使架构更改等.
在组织流程方面, 敏捷工作模式提供了一种适应变化的框架. 敏捷社区也开发了一些有利于软件快速迭代的工具和模式, 例如TDD(test-driven development, 测试驱动开发).
绝大多数针对敏捷技术的讨论局限于小型的, 本地的规模. 我们将从更大的数据系统层面提高敏捷性, 系统中可能包含多个应用和服务.
轻松地修改数据系统, 并改变需求, 这些都与简单性和抽象性密切相关: 简单易懂的系统往往更容易修改, 这是一个很重要的概念, 我们用evlovability(可进化性)来表示系统的敏捷性.