Replication
Replication意味着通过网络连接的多台机器上保留相同数据副本. 以下是保留多个数据副本的原因:
- 让数据与用户在地理上接近(减少延迟)
- 即使系统的一部分出现故障, 系统仍能正常工作(提高可用性)
- 横向拓展可以处理读取请求的机器数量(提高读取吞吐量)
本节假设数据集非常小, 每台机器都能保存整个数据副本. 下一章再讨论数据集的partitioning(分割).
如果数据不会随时间而改变, 那么复制很简单: 将数据复制到每个节点一次即可. 困难之处在于如何应对数据的变化. 本节将介绍三种主流的复制变更算法: single-leader, multi-leader, leaderless. 几乎所有分布式数据库都使用其中一种算法.
复制时需进行很多权衡: 例如, 使用同步复制还是异步复制, 如何处理失败的副本, 这些通常是数据库中的配置选项, 细节上因数据库而差异.
数据库的复制是一个老生常谈的题目. 从70年代到现在, 基本原理上没有什么太大变化, 因为网络的基本约束没有改变. 然而, 许多开发人员仍假设一个数据库只有一个节点. 分布式数据库变成主流是最近才发生的事情, 很多刚刚接触该领域的程序员可能会对eventual consistency(最终一致性)等问题存在误解.
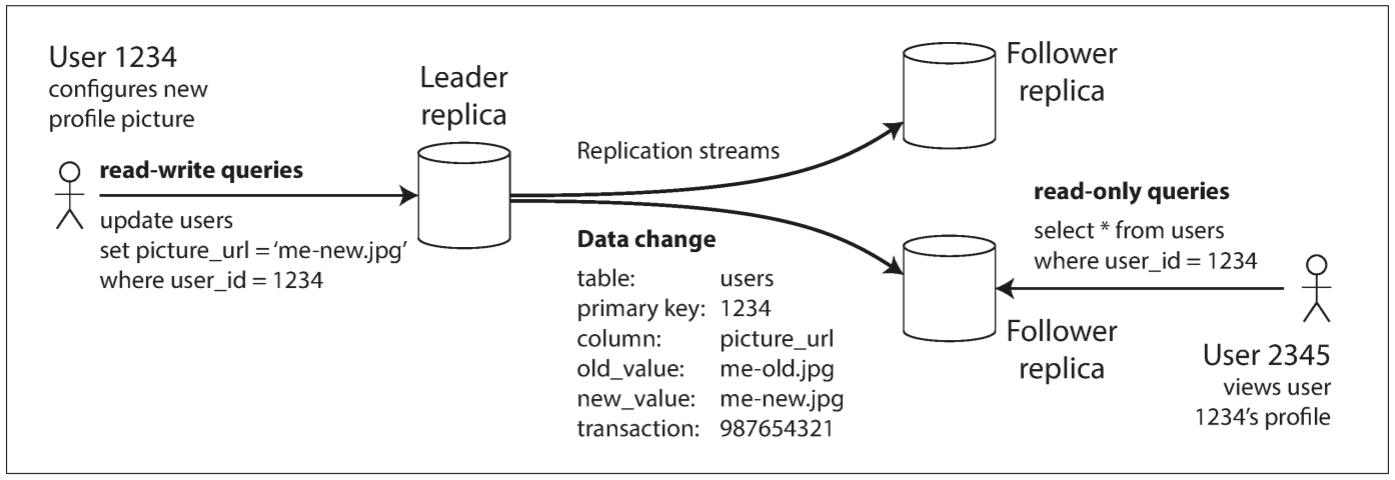
1. Leaders and Followers
存储数据副本的节点称为replica(副本). 当存在多个replica时就不可避免地引起一个问题: 如何确保数据复制到所有replica中?
数据库的所有写入都必须被所有replica处理, 否则replica会包含不同的数据. 最常见的解决方案被称为leader-based replication(基于领导者的复制, 也称为active/passive, 或master-slave replication). 操作流程如下:
- 指定其中一个replica为leader(领导者, 也称为master或primary). 当client想要写入数据库时, 必须向leader发送请求, leader会先将数据写入其本地存储
- 其他replica被称为follower(跟随者, 也称为read replica, slave, secondaries, hot-standby). 当leader将新数据写入本地存储后, 会将数据变更发送给所有的follower, 称为replication log(复制日志)或change stream(变更流). 每个follower从leader获取日志, 并以leader相同的写入顺序更新本地数据副本
- 当用户想要读取数据时, 可向leader或follower查询, 但只有leader能接收写操作.
很多关系数据库都自带该复制模式, 如PostgreSQL, MySQL, Oracle Data Guard, 和SQL Server的AlwaysOn Availability Groups. 其也被用于一些非关系数据库, 如MongoDB, RethinkDB, 和Espresso. 最后, 基于leader的复制并不仅限于数据库: Kafka和RabbitMQ这类高可用队列也使用该复制模式. 一些网络文件系统和块复制设备也类似, 如DRBD.
1.1 Synchronous Versus Asynchronous Replication
复制系统的一个重要细节为: 复制是同步的还是异步的(在关系数据库中, 这是一个可配置项; 其他系统通常硬编码为其中一种).
假设网站允许用户更新自己的头像. 某个时间点, 用户向leader发送更新请求; 不久后leader收到请求, 并转发给follower. 最后leader通知用户更新成功. 下图显示了各个组件间的通信: 用户端, leader, 和两个follower. 时间从左向右, 请求和响应用箭头表示: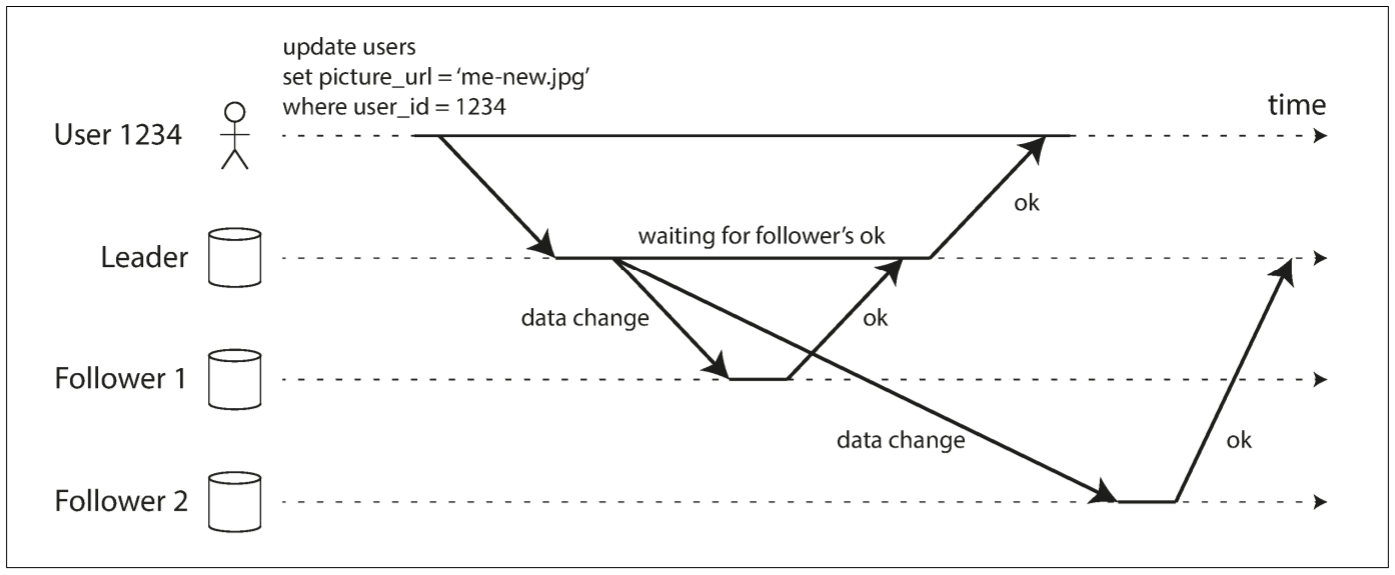
对于follower 1, 复制是同步的; leader等到follower 1的回复后才响应用户. 对于follower 2, 复制是异步的: leader向其发送更新, 但没有等待follower的响应.
图中follower 2处理前有一个非常明显的延迟. 通常情况下, 复制的速度很快: 绝大多数数据库系统会让follower在一秒内完成更新. 然而, 其并不能提供复制用时的保证. 有些情况下, follower会落后leader几分钟或更久, 如follower从故障中恢复, 系统以最大负荷运行, 或节点间出现网络问题.
同步复制的优点在于, follower与leader的数据一致. 若leader出现故障, 可从follower找到最新的数据副本. 缺点在于, 若同步follower不回复, 则leader无法处理写入请求, 所有写入操作都会被阻塞.
因此, 不应将所有follower都设置为同步的: 任何一个节点故障都会导致整个系统停滞. 实际上, 如果在数据库上使用同步复制, 只会有一个follower被设置为同步, 其他follower都是异步. 如果同步follower不可用或超时, 则会将另一个异步follower变为同步. 这样保证至少两个节点拥有最新的数据副本: leader和同步follower. 这种配置称为semi-synchronous(半同步).
有时也会配置为完全异步. 如果leader故障且不可恢复, 未写入follower的数据将丢失. 这意味着, 即使client收到server的写入确认, 也不能保证该写入是durable(持久). 完全异步的优点在于: 即使所有follower都落后了, leader也能处理写入请求.
弱化的持久性听起来像是一个糟糕的权衡, 但其却被广泛使用, 尤其是folower数量较多的情况, 或是follower的地理位置较为分散的情况.
1.2 Setting Up New Followers
有时我们需要启动新的follower: 可能是增加replica数量, 或替代故障节点. 那么如何保证新的follower拥有leader的全部数据副本?
将一个节点的数据复制到另一个节点是不够的: 用户会不断地提交写入请求, 数据在不断变化, 数据副本在不同时间点总是不一样的, 复制当前数据副本没有意义.
通过锁定数据库可让磁盘上的文件保持一直, 但这违背了high availability(高可用性). 实际上, 添加新的follower可不必停机, 过程如下:
- 在某个时刻获得leader的consistent snapshot(一致性快照), 尽量不锁住整个数据库. 由于大多数数据库都需要备份, 所以都能生成快照. 也可以用第三方工具实现, 如MySQL的innobackupex.
- 将快照复制到新的follower节点
- Follower与leader建立连接, 并请求快照之后的所有数据变更. 这要求快照与leader的复制日志中的位置精确关联. 该位置有不同名称: PostgreSQL中称为log sequence number(LSN, 日志序列号), MySQL中称为binlog coordinates(二进制日志坐标)
- 当follower处理完快照之后的数据变更后, 我们可以说该followercaught up(赶上)leader. 现在该follower可以继续处理来自leader的数据更新
每个数据库的执行步骤并不相同. 有些系统中, 整个过程是全自动的; 但其他系统中, 整个过程分为多个步骤, 且需要管理员手动执行.
1.3 Handling Node Outrages
系统中的任何节点都可能宕机, 或因意外的故障, 或因计划内的维修(例如, 安装内核安全补丁时必须重启机器). 对于运维团队, 如果能在不中断服务的情况下重启单个节点能带来很多好处. 因此, 我们的目标是: 即使单个节点宕机, 整个系统也能继续工作, 且尽可能控制节点宕机带来的影响. 那么如何在基于leader的复制中提供高可用性?
1.3.1 Follower failure: Catch-up recovery
每个follower在磁盘中都有一个日志, 其存放来自leader的数据变更. 当某个follower崩溃并重启, 或因网络故障导致网络临时中断, follower可快速恢复: follower可从日志中得知故障发生前的最后一个事务. 因此, follower可连接leader, 请求故障期间的所有数据更新. 完成所有更新后, follower也就赶上leader, 并可继续接收数据更新流.
1.3.2 Leader failure: Failover
Leader宕机比较难处理: 其中一个follower会被指定为leader, 需重新配置客户端, 让用户的写入请求分配给新的leader, 其他follower需从新的leader获取数据更新. 整个过程称为failover(故障切换).
Failover可手动执行(管理员发现leader宕机, 采用必要步骤来创建新的leader), 或自动执行. 自动执行failover的步骤如下:
- 确认leader失效: 实际中会发生很多情况, 崩溃, 停电, 网络问题等都会导致出错. 没有一个方法能确定到底出现了什么问题, 大多数系统会使用Timeout(超时)来判断: 节点互相频繁传递消息, 若某个节点一段时间没有响应(例如30秒), 则认为该节点挂掉(计划内的维护不算节点失效)
- 选择新的leader: 可通过选举完成(replica多数选举产生leader), 或由预先选定的controller node(控制器节点)指定新的leader. leader的最佳人选通常是具有最新的数据副本.
- 重新配置系统以启用新的leader: 用户需将写入请求发送给新的leader. 如果旧leader恢复, 其可能认为自己仍是leader. 系统需要确保旧leader成为一个follower, 并跟随新的leader.
以下是failover可能出现的问题:
- 如果使用异步复制, 新leader可能没有收到旧leader宕机前最后的写入. 新leader上台后, 当旧leader在重新加入集群, 如何处理这些未复制的写入? 最常见的解决方法是丢弃这些写入, 但这会违背持久性.
- 如果其他外部存储需与数据库同步, 则丢弃写入是非常危险的操作. 例如, 在GitHub的一次事故里, 一个过时的follower被晋升为leader. 数据库使用一个递增的计数器作为primary key(主键), 但由于新leader的计数器落后于旧leader, 因此新leader重新使用已被分配的主键, 主键重用让MySQL和Redis中产生数据不一致, 导致一些数据分配给了错误用户.
- 某些故障可能导致同时出现两个leader, 称为split brain(脑裂). 该情况非常危险, 如果两个leader都接收写入请求, 且没有冲突解决机制, 则数据很可能丢失或损坏. 安全起见, 一些系统一旦检测到存在两个leader会关闭其中一个节点. 但如果没有设计妥当, 可能导致两个leader都被关闭.
- leader超时多久才应被判定为失效? 超时设置的越长, leader宕机后需要的恢复时间越长; 超时设置的太短, 会导致不必要的failover. 例如, 一次负载峰值或数据包延迟就会导致超时. 如果系统已处于高负载或被网络问题困扰, 不必要的failover只会让情况更糟.
上述问题没有统一的解决方案. 因此, 有些团队选择手动处理failover, 有些则选择自动failover. 无论是节点宕机, 不稳定的网络, 还是副本的一致性, 持久性, 可用性与延迟的权衡, 这些都是分布式系统的基本问题.
1.4 Implementation of Replication Logs
基于leader的复制的实现方式有很多, 接下来我们一个个研究.
1.4.1 Statement-based replication
最简单的方法: leader把每个处理过的写入请求写入日志, 并发送给follower. 对于关系数据库, INSERT, UPDATE, DELETE语句都会转发给follower, follower会执行该SQL语句, 就像是客户端发来的写入请求. 但该方法也存在一些问题:
- 对于nondeterministic function(非确定性函数)的语句, 可能会在每个replica上产生不同的值. 如, 使用NOW()获取当前日期和时间, 使用RAND()获取一个随机数
- 如果语句中使用了autoincrementing column(自增列), 或依赖数据库中的现有数据(如,
UPDATE ... WHERE <some condition>), 则要求每个replica以相同顺序执行语句, 否则会产生不同的结果. 当有多个并发执行的事务时, 这可能成为一个限制 - 带有副作用的语句(例如, trigger, stored procedure, user-defined function)可能导致不同的replica产生不同的结果
的确有办法绕开上述问题. 例如, leader可将不确定性函数替换为固定返回值, 让follower使用相同的值. 然而由于边缘情况太多, 通常会选择其他复制方式.
MySQL 5.1之前还使用基于语句的复制. 由于其相当紧凑, 现在有时还在使用. 但默认情况下, 如果语句存在任何不确定性, MySQL会切换到row-based replication(基于行的复制). VoltDB使用基于语句的复制, 但要求事务必须是确定性的.
1.4.2 Write-ahead log(WAL) shipping
对于数据库, 写操作通常会被追加到日志中:
- 对于log-structured storage engine, 日志就是主要的存储位置. 后台会对log segment进行压缩和垃圾回收
- 对于B-tree, 其会覆写单个磁盘块, 每次修改都先写入write-ahead log(WAL, 预写式日志), 以便崩溃后index恢复到一致的状态
以上两种情况中, 日志都是一串仅追加(append-only)的字节序列, 其中包含所有写入. 我们可使用相同的日志在另一个节点建立副本: leader不仅将日志写入磁盘, 还将其传输给follower.
当follower使用日志时, 会建立一个和leader完全相同的数据副本. PostgreSQL和Oracle都使用这种复制方法. 该方法的缺点在于, 日志记录的数据非常低层: WAL包含哪些磁盘块中的哪些字节发生了更改. 这使得复制与存储引擎紧密耦合. 如果数据库因版本不同而更改存储格式, 不同版本的leader和follower无法兼容.
看似很微小的实现细节, 可能对运维有巨大影响: 如果复制协议允许follower的版本比leader高(向前兼容), 则可以先升级follower, 然后failover, 让升级后的节点称为新leader, 从而执行不停机升级; 若复制协议不允许存在版本差异, 则需要停机升级.
1.4.3 Logical(row-based) log replication
复制和存储引擎可使用不同的日志格式, 让复制日志从存储引擎中分离出来. 这种复制日志称为logical log(逻辑日志), 用于和存储引擎使用的日志区分.
对于关系数据库, logical log是一串对表的写入的记录序列, 以行为粒度:
- 对于被插入的行, 日志会包含所有列的新值
- 对于被删除的行, 日志会包含足够的信息来唯一标识该行. 通常为主键, 但如果table没有主键, 则需要记录每一列的值
- 对于一个被更新的行, 日志会包含足够的信息来唯一标识该行, 以及所有列的新值(至少所有被修改的列的新值)
需要修改多行的transaction(事务)会包含多个日志记录, 最后一条记录表明该事务可以提交. MySQL的binlog(当配置为row-based replication时)就是用这种方式.
由于logical log与存储引擎解耦, 因此很容易实现向后兼容, leader和follower可使用不同版本的数据库, 甚至是不同的存储引擎.
Logical log也更容易被外部应用解析. 可把数据库的内容发送给一个外部系统, 例如: 复制到数据仓库中进行离线分析, 或建立自定义index和cache. 这种技术也称为change data capture(数据变更捕获)
1.4.4 Trigger-based replication
上述所有方法都由数据库系统实现, 不涉及任何应用程序代码, 但某些情况下缺乏灵活性. 例如, 当我们只想复制一部分数据, 或需要从一种数据库复制到另一种数据库, 或需要conflict resolution logic(冲突解决逻辑), 则需将复制转移到到应用程序层.
有些工具可以让应用程序读取数据库日志, 从而让其使用数据, 如Oracle GoldenGate. 还可使用关系数据库自带的功能: trigger(触发器)和stored procedure(存储过程).
Trigger允许我们注册一个自定义的应用程序代码, 当数据库中发生数据更改(写入事务)时自动执行. Trigger可将修改记录到一个单独的表; 外部程序可读取该表, 并加上任何业务逻辑处理, 将数据修改再复制到另一个系统中. Oracle的Databus和PostgresSQL的Bucardo都是这么做的.
基于trigger的复制通常具有更高的开销, 比起数据库的内部复制, 更容易出错, 也有更多限制. 然而其灵活性仍十分有用.
2. Problems with Replication Lag
容忍节点故障只是复制数据的其中一个原因; 另一个原因是scalability(可伸缩性, 处理单个机器无法承受的大量请求), 以及latency(延迟, 让数据在地理位置上靠近用户).
基于leader的复制要求所有写入操作由单个节点处理, 但只读查询可由任意replica处理. 对于读多写少的场景, 这种方式非常适合: 创建大量follower, 将查询请求分配给所有follower. 这样能减少leader的负载, 且允许向距离最近的replica发送读请求.
在read-scaling(读伸缩)架构中, 只需要添加follower就可以增加读取能力. 然而这种方式只适用于异步复制, 如果使用同步复制, 单个节点的宕机或网络故障就让整个系统无法写入. 随着follower的数量越来越多, 宕机的概率也会不断增加, 因此完全同步是不现实的.
当用户从异步follower读取数据时, 如果follower落后于leader, 则可能看到outdated(过时的)信息, 从而导致数据库中出现不一致: 如果同时对leader和follower执行相同查询, 由于follower存在写入延迟, 两者返回的数据可能不一致. 但如果停止写入一段时间, 这种不一致就会消失, 因为follower最终会catchup(赶上), 并与leader保持一致. 这种效应称为eventual consistency(最终一致性).
eventually(最终)一词故意表示出模糊性: replica落后多少并没有一个明确定义. 通常来说, replication lag(复制延迟), 也就是写入leader到写入follower之间的延迟, 可能仅仅只有几分之一秒, 实践中并不会察觉到. 但如果系统负载过高, 或出现网络故障, 复制延迟可能增加到数秒, 甚至几分钟.
复制延迟过高导致的不一致是数据系统设计中的重要问题. 本节将介绍几种延迟导致的问题, 以及一些解决方案.
2.1 Reading Your Own Writes
很多应用允许用户提交数据, 并查看已提交的内容. 对于频繁读取但偶尔写入的场景, 可在提交数据时发送给leader, 读取数据时由follower处理.
但异步复制存在一个问题: 如果用户在写入后立刻读取数据, 但新数据还未被复制到follower, 用户会看不到已提交的数据, 可能认为数据丢失.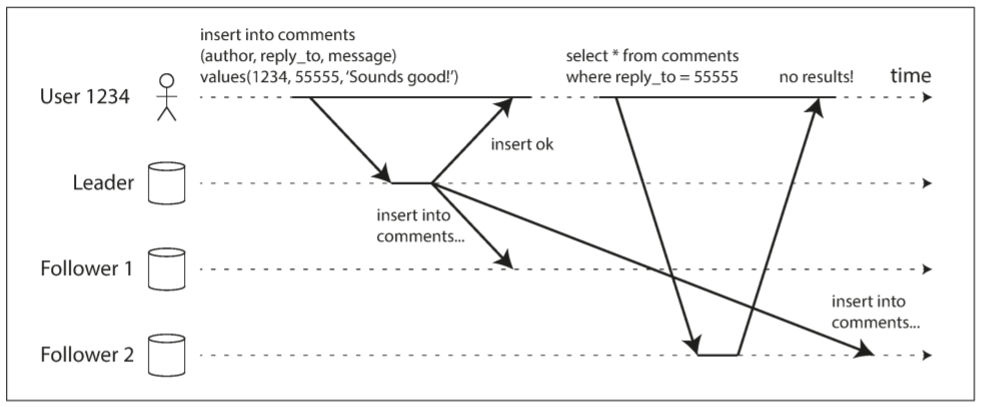
此时我们需要read-after-write consistency(读写一致性), 也称为read-your-writes consistency(读己写一致性): 如果用户重新加载页面, 用户总能看到已提交的数据. 但该一致性不保证其他用户看到新数据: 其保证该用户的输入已被正确保存, 但其他用户的更新可能过段时间才能看到.
以下是在基于leader的复制系统中, 实现读写一致性的技术:
- 对于用户可能修改的数据, 从leader读取; 否则从follower读取. 这种需要我们在不查询的情况下知道数据是否可能被修改. 例如, 社交网站上的用户个人资料只能由本人编辑, 因此需要从leader读取, 其他用户的个人资料可从follower读取
- 如果大多数信息都可能被用户编辑, 则上一种方式不适用(增加follower无法增加伸缩性). 此时, 需要一些其他方式判断是否从leader读取. 例如, 跟踪上次更新的时间, 如果更新不超过一分钟, 则从leader读取. 也可以监控follower的复制延迟, 防止从复制延迟超过一分钟的follower读取.
- 客户端记录最近写入的时间戳, 系统负责确保follower是否拥有该时间戳前的所有数据修改. 如果follower不够新, 可从其他follower读取, 或等待follower赶上来. 时间戳可以是逻辑时间戳, 如果使用系统时钟, 则需要确保时钟同步
- 若replica分布在不同的数据中心(与用户在地理位置上尽量靠近), 则会增加复杂度. 任何需要leader处理的请求, 都需要路由到leader所在的数据中心.
还有一种复杂情况: 如果同一个用户从多个设备请求服务, 例如桌面浏览器和手机App. 这时, 需要corss-device read-after-write consistency(跨设备的读后一致性): 用户在一个设备上输入数据, 然后在另一个设备上读取到新数据. 需要考虑以下几种问题:
- 记录用户上次更新的时间戳变得更加困难, 因为一台设备上的程序不知道另一台设备发生了什么, 元数据需要一个中心存储
- 如果replica分布在不同的数据中心, 很难保证不同设备连接到同一个数据中心. 例如, 台式机使用宽带网络, 移动设备使用蜂窝数据网络, 则网络路线可能不同. 若需要从leader读取, 则用户所有设备的请求都要转发给同一个数据中心.
2.2 Monotonic Reads
从异步follower读取数据时, 用户可能遇到时光倒流.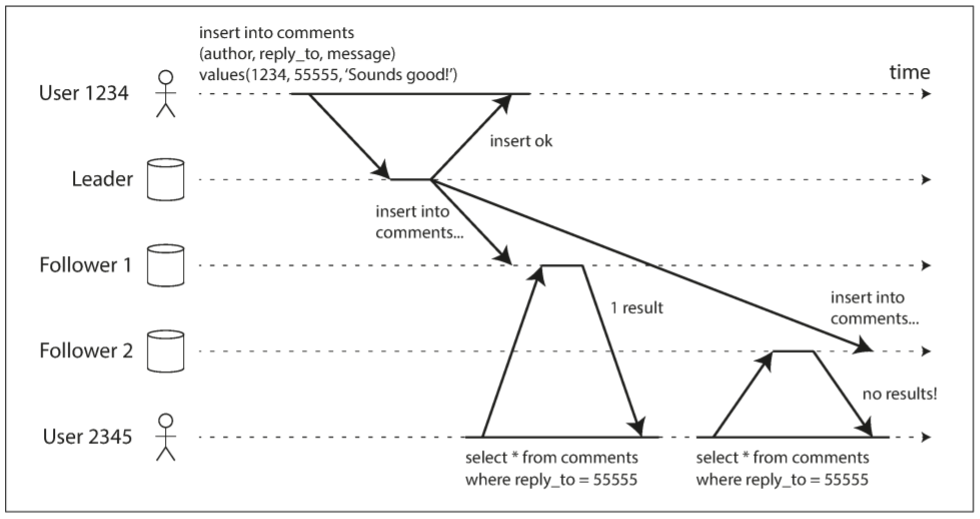
当用户从多个replica读取时. 例如, user2345执行了两次相同的查询, 第一个follower延迟低, 第二个follower延迟高. 第一个查询返回了user1234刚添加的评论, 但第二个查询并未返回该评论, 因为滞后的follower还未获得数据更改. 相比于第一个查询, 第二个查询像是更早的查询. 如果第一个查询没有返回任何内容, 那么问题不大, 因为user2345不知道添加了新评论; 但如果user2345看到了评论, 之后评论又消失, 则会让人很困惑.
Monotonic reads可防止上述异常. 这是一种比strong consistency(强一致性)弱, 但比eventual consistency(最终一致性)强的保证. 单调读意味着: 如果一个用户顺序进行多次读取, 不会出现时光倒流. 即如果先读到新数据, 之后不会得到旧数据.
实现单调读的一种方法为: 确保单个用户总是从同一个replica读取(不同的用户可从不同的replica读取). 例如, 基于用户ID的hash值分配replica, 而不是随机选择replica. 但如果该replica宕机, 用户的查询会被分配到新的replica.
2.3 Consistent Prefix Reads
假设存在以下对话:
- Mr. Poons: 你能看到多远的未来
- Mrs. Cake: 大约十秒
这两句话存在因果关系: Cake听到Poons的问题后作出回答. 假设第三个人通过follower听到这段对话. Cake说的话延迟低, 而Poons说的话延迟高, 于是第三方听到的对话如下:
- Mrs. Cake: 大约十秒
- Poons: 你能看到多远的未来
对于第三者来说, Cake看上去真的能预知未来, 这种违背因果的情况会让人困惑.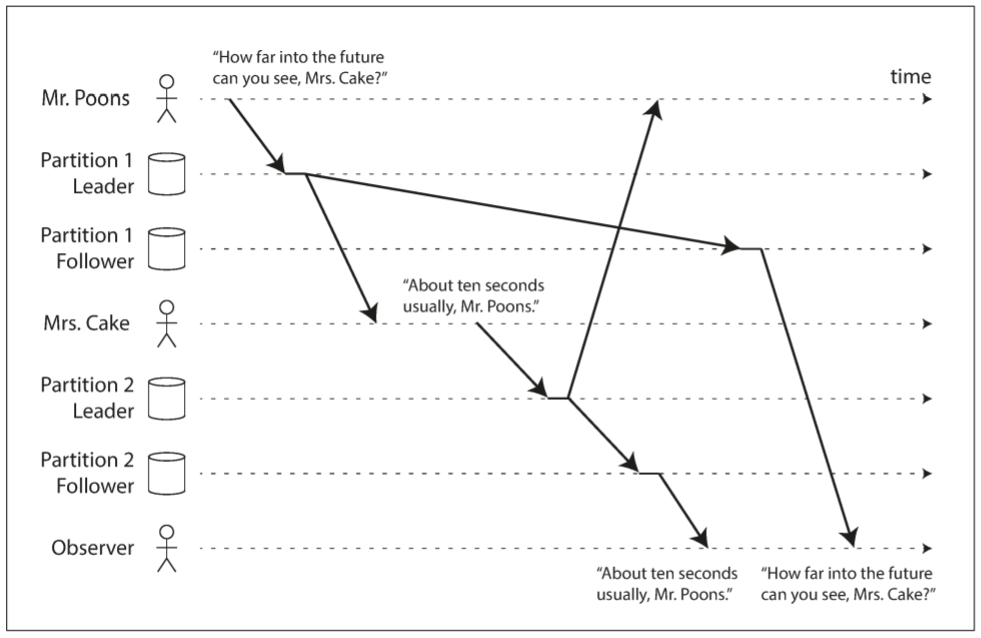
为防止这种异常, 需要另一种类型的保证: consistent prefix reads(一致前缀读). 如果一串写入按照某个顺序执行, 那么读取时也会以相同顺序出现.
这是partitioned/sharded datbase(分区/分片数据库)中的一个特殊问题. 如果数据库能保证写入顺序一致, 那么读取也必然一致, 异常也不会发生; 但对于分布式数据库, 不同分区独立运行, 因此不存在一个全局写入顺序: 当用户读取数据时, 数据库的某些部分处于旧状态, 某些处于新状态.
一种解决方法是, 确保任何因果相关的写入操作都经由一个分区执行. 对于无法高效完成此类操作的应用, 可以使用一些跟踪因果关系的算法.
2.4 Solutions for Replication Lag
使用最终一致性的系统时, 如果复制延迟扩大到几分钟甚至几小时, 应考虑应用程序的行为. 如果用户体验不好, 则需为系统提供一个更强的保证, 例如read-after-write(写后读). 明明是异步复制, 且当作是同步复制, 这是很多问题的根源.
应用程序可提供比底层数据库更强有力的保证, 例如, 通过leader进行某种读取. 但应用代码中处理的问题很复杂, 容易出错. 于是有了transaction的存在, 它使得应用程序开发人员不必担心复制问题, 这也是事务存在的原因: 通过事务提供强大的保证, 应用程序也变得更加简单.
单节点的事务已经存在了很久. 然而迈向分布式后, 很多数据库放弃了事务, 并声称事务在性能和可用性上代价太高, 认为最终一致性是不可避免的. 这些陈述有一些道理, 但太多简单.
3. Multi-Leader Replication
基于leader的复制有一个明显缺陷: 由于只有一个leader, 所有写入都必须经它处理. 如果由于各种原因而无法连接到leader, 如网络中断, 就无法写入数据库.
该模型有一个衍生品; 允许多个节点接收写入. 复制仍遵循相同逻辑: 处理写入的节点必须将数据发送给其他节点. 我们将其称为multi-leader configuration(多leader配置), 每个leader同时作为其他leader的follower.
3.1 Use Cases for Multi-Leader Replication
在单个数据中心中使用多个leader不是很必要, 因为这种配置的复杂度超过其带来的好处. 但在某些场景中, 可以使用多leader配置.
3.1.1 Multi-datacenter operation
假设我们有一个数据库, replica分布在不同的数据中心(为了防止单个数据中心宕机, 或为了地理位置上更接近用户). 如果采用传统的基于leader复制, 则leader只能存在于某个数据中心, 所有写入都须经过该数据中心.
多leader配置则可以让每个数据中心都拥有一个leader. 以下图为例, 单个数据中心采用传统的leader-follower复制模式; 在数据中心之间, 每个数据中心的leader会将更新发送给其他leader.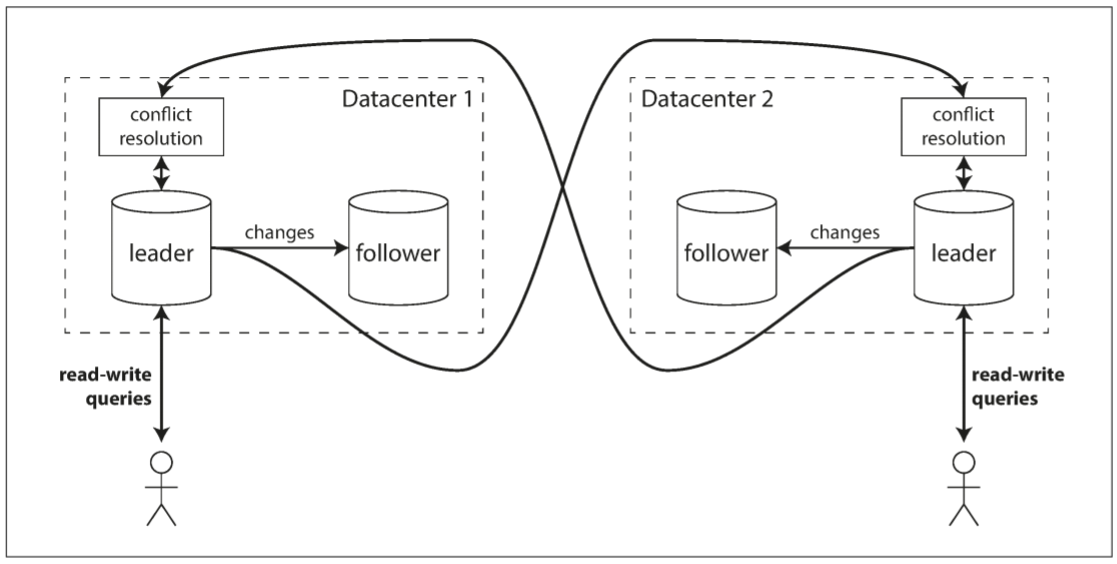
以下是单leader和多leader在多数据中心部署中的区别:
- Performance(性能): 单leader配置中, 每个写入请求都需传递给leader所在的数据中心. 这会增加写入时间, 并违背了多数据中心的初衷; 多leader配置中, 每个写入请求可由最近的数据中心处理, 并异步复制给其他数据中心. 因此, 用户感受不到数据中心间的网络延迟, 体验更好.
- Tolerance of datacenter outages(容忍数据中心宕机): 在单leader配置中, 如果数据中心的leader宕机, 故障切换必须让另一个数据中心的follower称为leader. 在多leader配置中, 每个数据中心可独立于其他数据中心继续运行, 当发生故障的数据中心恢复后可以很快赶上.
- Tolerance of network problems(容忍网络问题): 数据中心之间通讯通常需要经过公共网络, 其可靠性不如内部网络. 由于单leader配置中写入是同步操作, 其对于数据中心之间的连接问题更敏感; 多leader配置的异步复制功能可以更好地承受网络问题: 一次临时网络中断不会阻塞正在处理的写入.
一些数据库默认支持多leader配置, 但也可以使用外部工具, 例如MySQL的Tungsten Replicator, PostgreSQL的BDR, Oracle的GoldenGate.
虽然多leader配置有很多优点, 但存在一个致命缺点: 一份数据可能被两个数据中心同时修改, 必须解决写冲突.
由于数据库中的多leader配置属于改装功能, 通常存在一些配置陷阱, 且会与其他数据库功能产生冲突, 例如自增主键, triggers, 完整性约束等. 因此, 多leader复制通常需要被避免.
3.1.2 Clients with offline operation
若应用程序需在断网后继续工作, 则可使用多leader复制. 例如, 手机, 笔记本, 和其他设备上的日历应用. 无论是否连接网络, 用户都需随时查看会议信息(读请求), 发布新的会议(写请求). 任何离线状态下的修改会在下次上线时同步到服务器.
此时, 每个设备都有一个本地数据库作为leader(接收写请求), 不同设备上的replica会进行异步的多leader复制. 复制延迟可能是几小时, 甚至几天, 取决于设备何时联网.
从架构角度来说, 这与多leader配置的多个数据中心无异: 每个设备都是一个"数据中心", 且网络连接极其不稳定. 从各种日历应用糟糕的同步可以看出, 多leader复制是一个相当难实现的事情.
有些工具可让多leader配置更简单, 例如, CouchDB就是为了这种模式而设计.
3.1.3 Collaborative editing
Real-time collaborative editing(实时协作编辑)应用程序允许多个用户同时编辑文档. 如Etherpad和Google Docs. 虽然协作式编辑不等同于数据库复制问题, 但却与离线编辑有一些相似之处. 当用户编辑文档时, 更新将立刻应用到本地副本中(Web浏览器或客户端中的文档状态).
为保证不发生编辑冲突, 应用程序必须先取得文档的lock. 若其他用户想要编辑该文档, 必须等待上一个用户提交修改并释放lock. 这种协作模式相当于在单leader复制中, 在leader上执行事务操作.
然而, 为了加快协作, 需将修改的单元设置的非常小(例如, 一个按键), 并避免锁定. 这样可允许多人同时编辑同个文档, 但同时也带来了多leader复制的所有挑战, 包括冲突解决.
3.2 Handling Write Conflicts
多leader复制的最大问题是写入冲突. 例如, 两个用户同时编辑某个wiki页面, 如下图. 用户1将标题从A改为B, 用户2同时将标题从A改成C. 每个用户的更改都成功应用于本地leader. 但当异步复制时会发生冲突. 单leader数据库就不会出现这种问题.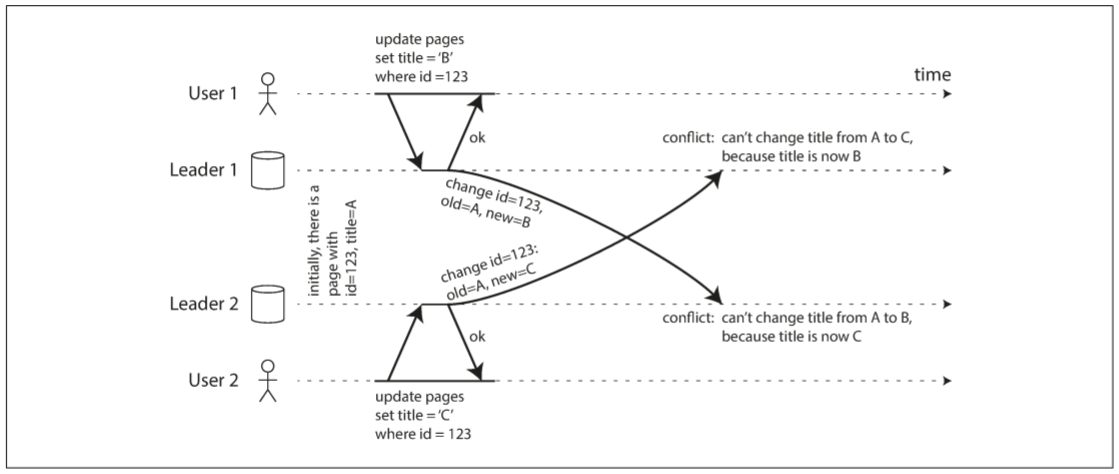
3.2.1 Synchronous versus asynchronous conflict detection
在单leader数据库中, 第二个写入会被阻塞并等待第一个写入完成, 或终止第二个写入事务, 强制用户重试. 多leader配置中, 两次写入都执行成功, 并在稍后异步地检测到冲突. 到那时要求用户解决冲突为时已晚.
原则上可以同步检测冲突. 例如, 先等待更新被复制到所有replica, 再通知用户写入成功. 然而, 这样做会失去多leader复制的优势: 允许每个replica独立接收写请求. 如果使用同步检测冲突, 可使用单leader复制.
3.2.2 Conflict avoidance
最简单方式是避免冲突: 如果应用程序能保证特定记录只经由某个leader写入, 则不会发生冲突. 由于多leader复制的很多实现并不能很好地解决冲突, 往往推荐避免冲突.
例如, 对于用户可编辑自己数据的应用程序, 单个用户的请求始终路由到同一数据中心, 并使用该数据中心的leader进行读写. 不同的用户可能选择不同的数据中心(可能根据用户的地理位置选择), 从单个用户的角度来说, 配置为单leader.
然而, 有时需要更换某个记录的leader(可能因为数据中心出现故障, 需将流量路由到其他数据中心; 或因用户移动到其他位置, 需要更靠近的数据中心). 这时, 冲突避免会中断, 可能出现不同leader的同时写入.
3.2.3 Converging toward a consistent state
单leader数据库按顺序进行写操作: 若某个字段进行了多次更新, 最后一次更新将决定该字段的最终值.
在多leader配置中, 没有明确的写入顺序, 所以最终值不确定. 主库1中标题先被改为B, 后被改为C; 主库2中, 标题先被改为C, 后被改为B. 没法说哪个顺序是正确的.
如果每个replica按照自己接收的写入顺序执行, 那么数据库最终将处于不一致状态: 主库1的C和主库2的B. 然而, 无论什么复制方案, 都必须保证所有replica中的数据最终是一致的. 因此数据库必须以一种convergent(收敛的)方式解决冲突, 换句话说, 当所有更改都完成复制时, 所有replica的数据都必须收敛到相同值. 以下是解决冲突的几种方法:
- 为每个写入分配一个ID(例如, 一个时间戳, 一个随机数, 一个UUID, 或hash值), ID越大优先级越高, 并丢弃优先级低的写入. 如果使用时间戳, 该技术称为last write wins(最后写入胜利, LWW). 虽然这种方法很流行, 但会造成数据丢失.
- 为每个replica分配一个ID, ID编号越高, 写入的优先级越高. 这种方法也会造成数据丢失.
- 以某种方式将值合并在一起. 例如, 按字母排序, 然后连接起来(以修改wiki标题为例, 合并后的标题可能为B/C).
- 用一种显式数据结构来记录冲突的所有信息, 并编写应用代码来解决冲突
3.2.4 Custom conflict resolution logic
解决冲突最合适的方式取决于应用程序, 绝大多数多leader复制工具都需要开发者编写冲突解决逻辑. 代码会在写入或读取时执行:
- On write: 只要数据库系统检测到复制更改日志中存在冲突, 就会调用冲突处理程序. 例如, Bucardo允许用户编写一段Perl代码. 由于程序在后台运行, 且需快速执行, 因此无法通知用户.
- On read: 当检测到冲突时, 所有冲突写入都会被保存. 下次读取数据时, 所有版本的数据都会返回给应用程序, 并让用户手动解决, 或自动处理冲突, 最后将结果写回数据库. CouchDB以这种方式工作.
冲突解决适用于单行或单个文档, 而不是整个事务. 因此, 如果一个事务中包含多次写入, 需单独考虑每个写入.
3.2.5 What is a conflict?
有些冲突十分明显: 当两个写操作同时修改同一记录中的同一字段, 并将其设置为两个不同的值, 毫无以为这是一个冲突.
其他类型的冲突可能很难察觉. 例如, 对于会议室预订系统: 该系统负责追踪哪些房间在哪些时间段被哪些人预定. 该应用需要确保单个房间在同一个时间只被一组人预定(即单一个房间不能重叠预定). 若某个房间同时被两组人预定, 则会发生冲突. 即使应用在处理预定之前检查房间的可用性, 仍可能因为不同的预定发生在不同的leader而导致冲突.
3.3 Multi-Leader Replication Topologies
replication topology(复制拓扑)描述了写入从一个节点传播到另一个节点的通信路径. 如果只有两个leader, 则只有一种拓扑: leader1把其所有写入发送给leader2, 反之亦然. 但若leader数量多于两个, 会出现多种拓扑. 以下图为例: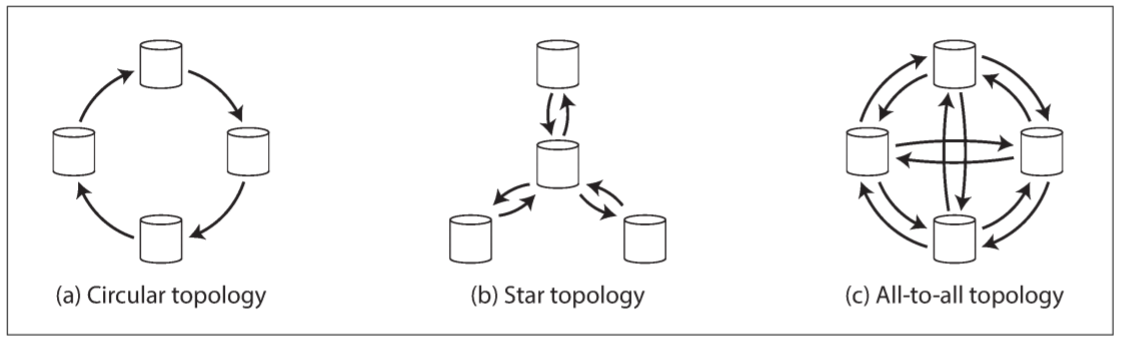
最常见的拓扑是all-to-all: 每个leader把其写入传给其他leader. 但也会使用一些更受限的拓扑: 例如, MySQL支持circular topology(环形拓扑): 每个节点接收上一个节点的写入, 并将其转发给下一个节点. 另一种流行的拓扑结构为star(星形): 根节点将写入转发给其他所有节点, 也可拓展为tree(树型).
对于环形和星形拓扑, 在更新传递到所有replica之前, 写入需经过多个节点. 因此, 需要节点作为中介进行转发, 为了防止无限复制循环, 每个节点都有一个唯一标识符. 复制日志中, 写入会记录所经过节点的标识符. 当一个节点检测到自己的标识符, 会忽略该写入.
环形和星形拓扑存在一个问题: 如果某个节点发生故障, 节点之间的复制消息流会被中断. 重新配置拓扑结构可绕过故障节点, 但大多数部署中, 这种重新配置需手动操作. 因此, 越密集连接的拓扑结构, 容错率越好(如all-to-all), 因为消息可沿着不同的路径传播, 不受单点故障影响.
另一方面, all-to-all拓扑也存在问题. 特别是部分网络链接快于其他网络连接时, 某些复制消息可能"超过"其他复制消息.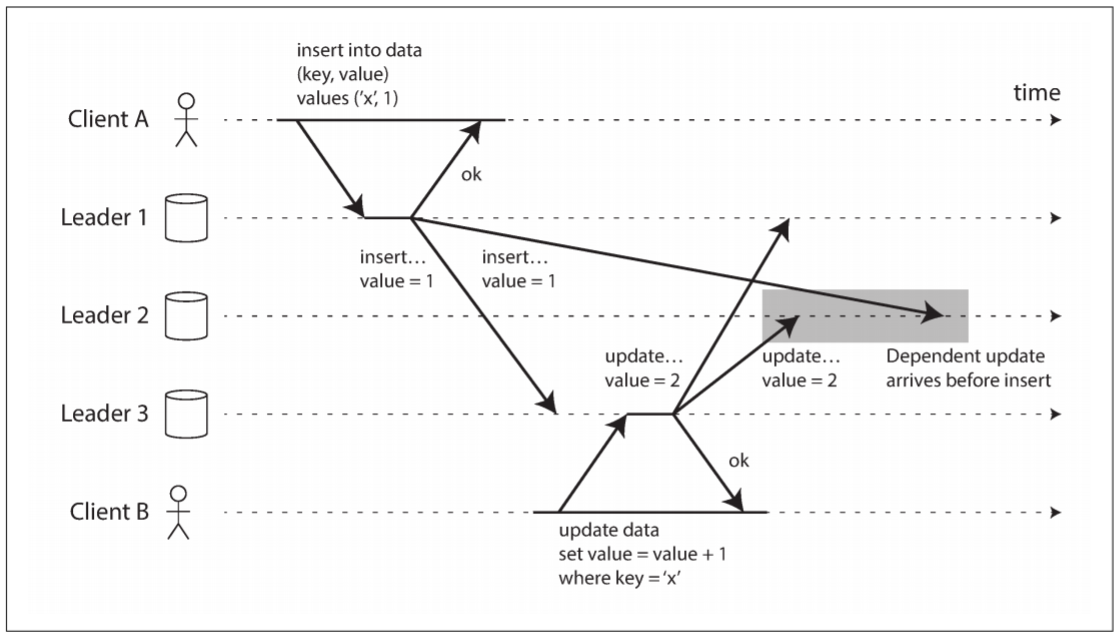
上图中用户A向主库1的表中插入一行, 用户B在主库3中更新该行. 然而, 主库2可能以不同顺序接收写入: 先收到更新(更新不存在的行), 再收到插入(本应在更新之前).
这是一个因果关系问题: 更新取决于之前的插入, 所以要确保所有节点先处理插入, 再处理更新. 仅仅在每次写入时添加一个时间戳是不够的, 因为时钟无法完全同步.
为正确排序这些事件, 可使用version vectors(版本矩阵). 然而很难在多leader复制中实现. 例如, PostgreSQL BDR不提供写入的因果排序, MySQL的Tungsten Replicator甚至不检测冲突.
如果选择使用具有多leader复制功能的系统, 则应该知道其存在的问题, 仔细阅读文档, 并充分测试数据库, 这样才能确保其提供了你想要的保证.
4. Leaderless Replication
之前已经讨论了两种复制模式: 单leader复制和多leader复制, 这两种模式基于同一理念: 用户向leader发送写请求, 数据系统负责将写入复制到其他replica. Leader决定了写入顺序, follower按相同写入顺序执行.
一些数据存储系统采用不同的方法, 摒弃了leader的概念, 并允许任何replica都能接受用户的写请求. 最早的复制数据系统是leaderless(无领导的), 但随着关系数据库的崛起, 这种想法逐渐被抛弃. Amazon将其使用到Dynamo系统后, 这类数据库再次流行起来. Riak, Cassandra, 和Voldemort都是基于leaderless复制模型的开源数据存储, 这类数据库也称为Dynamo-style(Dynamo风格).
在某些leaderless实现中, 用户直接向多个replica发送写请求; 而另外一些数据库会让coordinator(协调者)代表用户进行写入. 但与leader不同, coordinator不按照特定顺序执行写请求. 这种设计上的差异会让数据库的使用方法大不相同.
4.1 Writing to the Database When a Node Is Down
假设数据库中有三个replica, 其中一个replica不可用(可能正在重启以安装系统更新). 在基于leader的配置中, 如果想继续执行写操作, 可能需要执行故障切换.
leaderless配置中不存在故障切换. 以下图为例: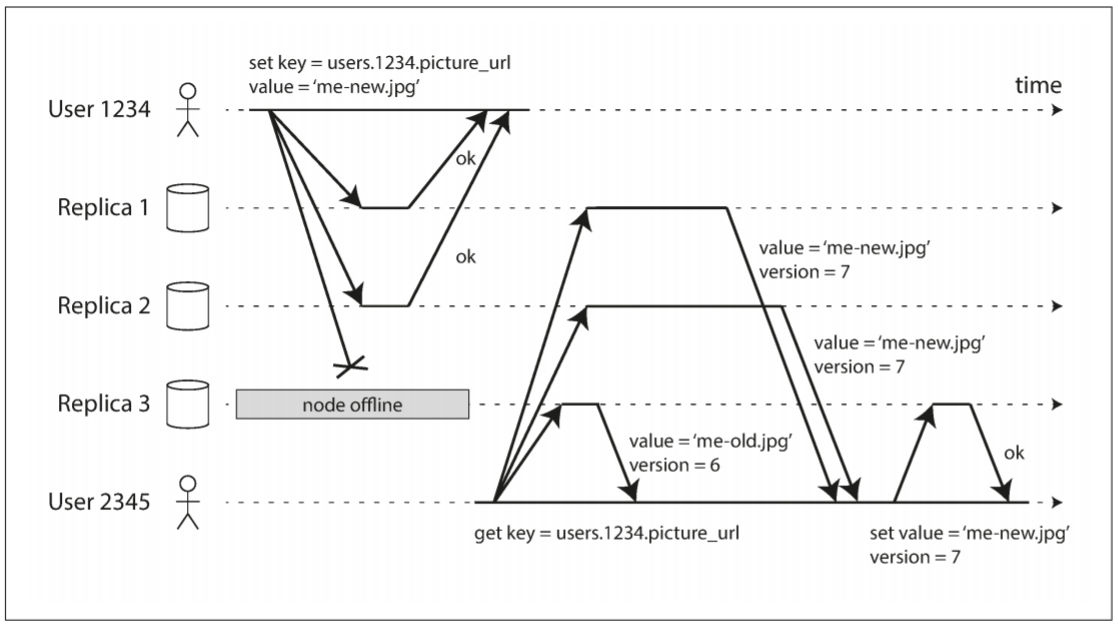
客户端1234将写请求并行发送给三个replica, 其中两个replica接受了写入, 剩下一个replica不可用. 假设三个replica中, 两个replica写入就已足够: 客户端1234收到两个响应后可认为写请求成功, 并会忽略一个replica没有写入的事实.
现在假设replica 3重新上线, 客户端开始读取数据. 该节点宕机时的写入已丢失, 因此从该节点读取的数据是旧值.
为了解决该问题, 当客户端读取数据时, 不能只向一个replica发送读请求: 读请求也需发送给多个replica, 客户端可能收到不同响应. 例如, 一个节点返回最新值, 另一个节点返回旧值. 这时可用版本号来决定哪个值更新.
4.1.1 Read repair and anti-entropy
复制模式必须保证所有replica上的数据最终保持一致. 当一个不可用的节点重新上线后, 如何赶上进度?
Dynamo风格的数据存储有两种机制:
- Read repair(读修复): 当客户端从多个节点读取数据时, 会检测到旧响应. 如, 客户端2345收到来自replica 3的响应, 其版本号为6; 还收到replica 1和2的响应, 版本号为7. 客户端会认为replica 3含有旧值, 并将新值写回该replica. 这种方法适用于频繁读取的场景.
- Anti-entropy process(反熵过程): 有些数据存储拥有一个后台进程, 该进程不断检查replica间的差异, 并将丢失的数据从一个replica复制到另一个replica. 与基于leader配置的复制日志不同, 反熵过程不会以特定顺序写入, 复制数据之前也存在明显的延迟.
并非所有系统都实现了上述两个机制. 例如, Voldemort没有反熵过程. 如果没有反熵过程, 某些replica中很少读取的值会丢失, 从而降低了持久性.
4.1.2 Quorums for reading and writing
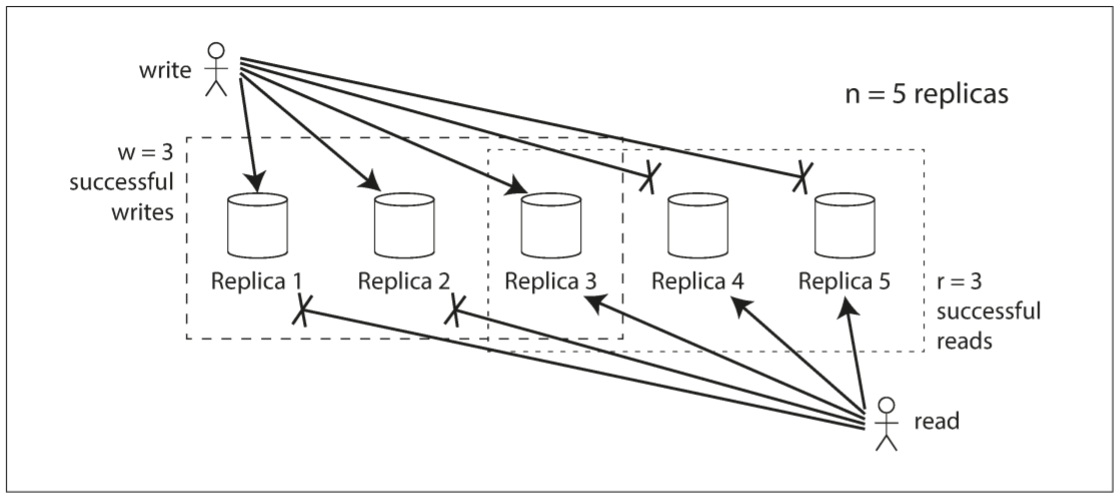
上例中, 三个replica中只要二个replica写入就算成功. 随着replica数量的增加, 多少replica完成写入才可认为写入成功?
三个replica中至少有两个replica写入数据, 意味着最多只有一个replica是陈旧的. 因此当客户端从两个或两个以上的replica读取时, 至少有一个响应是最新的. 即便第三个副本宕机或响应缓慢, 读取仍可以获得最新值.
若存在$n$个replica, $w$个节点写入就算成功, 读取会向$r$个节点发送请求. 只要满足$w + r > n$, 就可保证每次读取时至少有一个最新值. 遵循$r$值和$w$值的读写称为quorum(法定人数)的读和写. 换句话说, $r$和$w$是读写所需的最低票数.
在Dynamo风格的数据库中, 参数$n$, $w$, 和$r$都是可配置的. 通常会将n设为奇数(通常为3或5), 并设置$w = r = (n + 1) / 2$(向上取整). 例如, $w=n$和$r=1$的系统适用于写入很少且读取频繁的场景. 虽然读取更快, 但单个节点的宕机就会导致整个数据库不可用.
法定人数条件$w + r > n$允许系统容忍不可用的节点, 如下:
- $w < n$: 若节点不可用, 仍可处理写入
- $r < n$: 若节点不可用, 仍可处理读取
- $n = 3, w = 2, r = 2$: 可容忍一个节点不可用
- $n = 5, w = 3, r = 3$: 可容忍两个节点不可用
- 读写请求会并发发送到所有replica, $w$和$r$决定了客户端需要等待多少个响应, 即客户端认为写入和读取成功前, 需等待多少个replica回复.
如果少于$w$或$r$个节点, 写入和读取将返回错误. 节点不可用的因素很多: 节点宕机(崩溃或电源故障), 执行错误(因磁盘已满而无法写入), 与客户端或其他节点的网络中断等. 我们只需关心节点是否返回响应, 不需要在乎节点为何不可用.
4.2 Limitations of Quorum Consistency
假设现在有n个replica, w和r遵循$w + r > n$, 可保证每次读取都能获得最新值, 因为写入的节点集合和读取的节点集合存在交集, 读取的节点中至少有一个拥有最新数据.
通常, r和w都会设置为多数节点(超过$n/2$个节点), 即使$n/2$个节点不可用, 也可保证$w + r > n$. 但法定人数不一定是多数节点, 写入和读取只重叠一个节点即可. 法定人数的配置让分布式算法的设计具有一定的灵活性.
也可将w和r设置为较小的数值, 以使$w + r <= n$(即不满足法定人数). 读取和写入仍发送给所有replica, 但只需等待少量响应.
较小的w和r会让读取无法包含具有最新值的节点, 因此客户端可能读取到旧值; 但这种配置也使得延迟变低, 可用性更高: 若出现网络中断, 或多个replica不可用, 客户端仍可继续读取和写入. 只有可用replica数量少于w或r时, 数据库才无法写入或读取.
然而, 即使满足$w + r > n$, 也存在返回旧值的可能. 可能出现的情况如下:
- 若采用宽松的法定人数, w个写入和r个读取可能落在不同的节点, 这时读取和写入不存在重叠
- 若同时发生两个写入, 很难分清哪个写入先发生. 这时, 唯一安全的解决方法是合并并发写入. 根据时间戳选择一个胜利者, 但由于时钟偏差, 写入可能会丢失.
- 若同时发生读写, 写入只保存在部分replica. 这时读取无法保证能否读取到最新值.
- 若写入数据在某些replica上成功, 而在其他节点上失败(例如, 因磁盘已满而失败), 最终没有满足w个replica成功写入, 可认为写入失败, 但已写入的数据没有被回滚. 这意味着, 若某次写入失败, 后续读取可能获得失败写入的数据.
- 若具有新值的节点宕机, 并在之后恢复时从具有旧值的节点中恢复数据, 则具有新值的replica数量可能小于w, 从而打破法定人数条件.
- 即使一切工作正常, 也可能出现时序的边缘情况
因此, 尽管理论上法定人数可保证读取时返回最新的写入值, 但实践中没有那么简单. Dynamo风格的数据库会针对可以容忍最终一致性的用例进行一系列优化. 通过$w$和$r$参数, 可调整客户端读取到旧值的概率, 但不能将法定人数当成一个绝对的保证.
4.2.1 Monitoring staleness
从运维的角度来说, 很有必要监控数据库是否返回最新值. 即便应用能够容忍旧值, 也需要了解复制的状况. 若复制落后太多, 需及时调查原因(例如, 网络问题或节点负载过大).
对于基于leader的复制, 由于leader和follower遵循同一顺序写入, 且每个节点在复制日志中占据一个位置(当前节点的写入数量), 因此, 数据库可公开复制滞后的状况, 并交由监控系统. Leader的写入次数减去follower的写入次数, 就是复制的滞后量.
然而, 对于leaderless复制的系统, 由于没有固定的写入顺序, 导致监控很难实现. 若数据库只使用read repair(没有anti-entropy), 则数据的老化程度没有任何保证.
Leaderless复制数据库中, 虽然存在一些衡量replica老化程度的方法, 例如通过$n$, $w$, $r$参数来推断读取到旧值的比例, 但都不是常见做法. 将老化测量纳入到数据库的度量标准中是一件好事. 虽然最终一致性刻意是一种模糊保证, 但也需要某种量化.
4.3 Sloppy Quorums and Hinted Handoff
合理配置的法定人数使得数据库无需故障切换就能容忍个别节点故障, 也可容忍个别节点响应变慢, 因为请求无需等待所有响应. 对于要求高可用性, 低延迟, 且容忍读取时偶尔返回旧值的应用, leaderless复制更具有吸引力.
然而, 法定人数的容错具有一定局限性. 网络中断可能会让客户端与大多数节点断开. 虽然节点依旧提供服务, 但对于该客户端来说, 节点并不可用. 这时, 客户端收到的写入或读取响应数量小于$w$和$r$, 无法满足法定人数.
在一个大型集群中, 网络中断期间客户端仍能连接到个别节点, 但又不满足法定人数. 此时数据库设计人员需权衡以下两个问题:
- 对于不满足法定人数的请求, 是否返回错误
- 是否应该接收写入, 并写入一些可到达的节点, 但不在这些值通常所存在的n个节点上
后者称为sloppy quorum(宽松的法定人数): 读和写仍需r和w个响应, 但这些响应可能不来自指定的n个节点. 类似于你被门反锁, 可能会去邻居家暂留一段时间.
一旦网络中断恢复, 临时接收数据的节点会将写入发送给原本的节点, 称为hinted handoff(提示移交, 一旦找到房屋钥匙, 需从邻居家离开).
宽松法定人数可提高写入可用性: 只要有任意w个节点可用, 数据库就能接收写入. 然而, 即使满足$w + r > n$, 也不能保证读取到最新值, 因为最新值可能写入了当前节点集群外的其他节点.
因此, 宽松法定人数实际上不是一个法定人数, 只是一种持久性保证, 即数据存储在w个节点的某个地方. 在hinted handoffer完成前, 无法保证读取的r个节点中包含最新值.
所有主流的Dynamo实现中, 宽松法定人数是optional(可选的). Riak默认开启, 而Cassandra和Voldemort默认禁用.
4.3.1 Multi-datacenter operation
之前讨论了基于leader复制的跨数据中心复制. Leaderless复制可容忍冲突的并发写入, 网络中断, 和延迟尖峰, 因此也可适用于跨数据中心操作.
Cassandra和Voldemort使用leaderless模型来实现多数据中心的支持: replica的数量$n$表示所有数据中心的节点, 也可配置每个数据中心的replica数量. 每次写入都发送给所有replica, 但只会等待本地数据中心内的法定节点的确认, 不会受到跨数据中心链路延迟和中断的影响. 数据中心之间的高延迟写入通常配置为异步.
Riak会将客户端只与一个本地数据中心保持连接, 因此n表示单个数据中心内的replica数量. 数据库集群之间的跨数据中心复制在后台异步执行, 类似于多leader复制.
4.4 Detecting Concurrent Writes
Dynamo风格的数据库允许多个客户端同时写入相同key, 即使使用严格的法定人数也会发生冲突. 这种情况与多leader复制相似. 但在Dynamo风格的数据库中, 在read repair或hinted handoff期间也可能发生冲突.
由于网络延迟和局部故障, 事件可能在不同节点以不同顺序到达. 以下图为例, A和B同时向三个数据存储节点写入键X.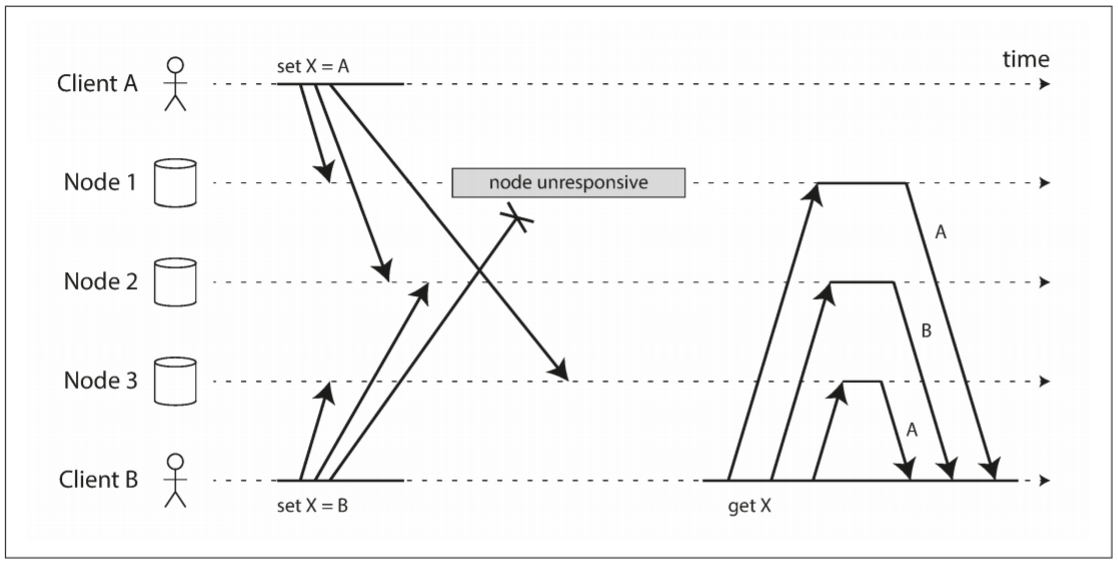
- 节点1接收到A的写入, 但未收到B的写入
- 节点2先收到A的写入, 之后收到B的写入
- 节点3先收到B的写入, 之后收到A的写入
若节点只要接收到客户端写入就覆盖键值, 则节点将永久不一致. 以上图为例: 节点2的最终值为B, 其他节点的最终值为A.
为了实现最终一致性, replica应趋于相同的值. 有些开发者希望数据库能自动处理, 但不幸的是, 大多数实现都很糟糕: 若想避免丢失数据, 开发者需要了解数据库冲突处理的相关知识.
4.4.1 Last write wins(discarding concurrent writes)
一种实现最终收敛的方法: 每个副本只需保存"最近"的值, 并允许旧值被覆盖和丢弃. 但我们需要找到一种方法来确定不同写入的新旧关系, 并将写入复制到每个replica, 最终实现收敛.
然而"最新"具有误导性. 当客户端向数据库节点发送写请求时, 并不知道其他客户端的行为, 因此无法确定谁先发送. 实际上, 很难说清先后关系, 只能说写入是并发的, 所以它们的顺序是不确定的.
尽管写入没有一个自然顺序, 但可以赋予一个顺序. 例如, 为每个写入附加一个时间戳, 最大时间戳表示该写入为最新值, 并丢弃时间戳较小的写入. 这种冲突解决算法称为last write wins(最后写入胜利, LWW), 是Cassandra唯一支持的冲突解决方法, 也是Riak的可选特征.
LWW实现了最终收敛, 但代价是持久性: 若同一键有多个并发写入, 即使客户端都收到写入成功的响应, 也只能保留一个写入, 其他写入将被默默丢弃. 此外, 非并发的写入也可能被丢弃.
有些情况可以接受写入丢失, 如caching, 但如果无法接收写入丢失, 则不推荐使用LWW. 与LWW一起使用数据库的唯一安全方法是确保一个键只写入一次, 且该值不可更改, 从而避免对同一键的并发更新. 例如, Cassandra推荐使用UUID作为键, 为每个写操作提供一个唯一键.
4.4.2 The "happens-before" relationship and concurrency
如何判断两个操作是否并发? 以下是一些例子:
- 对于图, 两次写入不是并发的: 由于B递增的值是A插入的值, 因此A发生在B之前. 换句话说, B的操作基于A的操作, 因此B的操作更靠后. 因此B是causallu dependent(因果依赖)于A.
- 对于图, 两次写入是并发的: 当客户端开始操作时, 并不知道其他客户端正在对同一键进行操作. 因此, 两个操作之间没有因果关系.
若B知道A的存在, 或依赖于A, 或基于A的操作, 则可以说A发生在B之前. 一个操作是否发生在另一个操作之前, 这是定义并发的关键. 若两个操作没有前后关系, 则两个操作是并发的.
因此, 两个操作(A和B)存在三种可能性: A发生在B之前, B发生在A之前, A和B并发. 现在只需一个算法来判断两个操作是否并发. 若一个操作发生在另一个操作之前, 则后者覆盖前者; 若两者并发, 则需要解决冲突.
4.4.3 Capturing the happens-before relationship
以一个判断操作先后的算法为例. 假设数据库只有一个replica. 若单个replica能实现, 则可将其推广到多replica的leaderless数据库.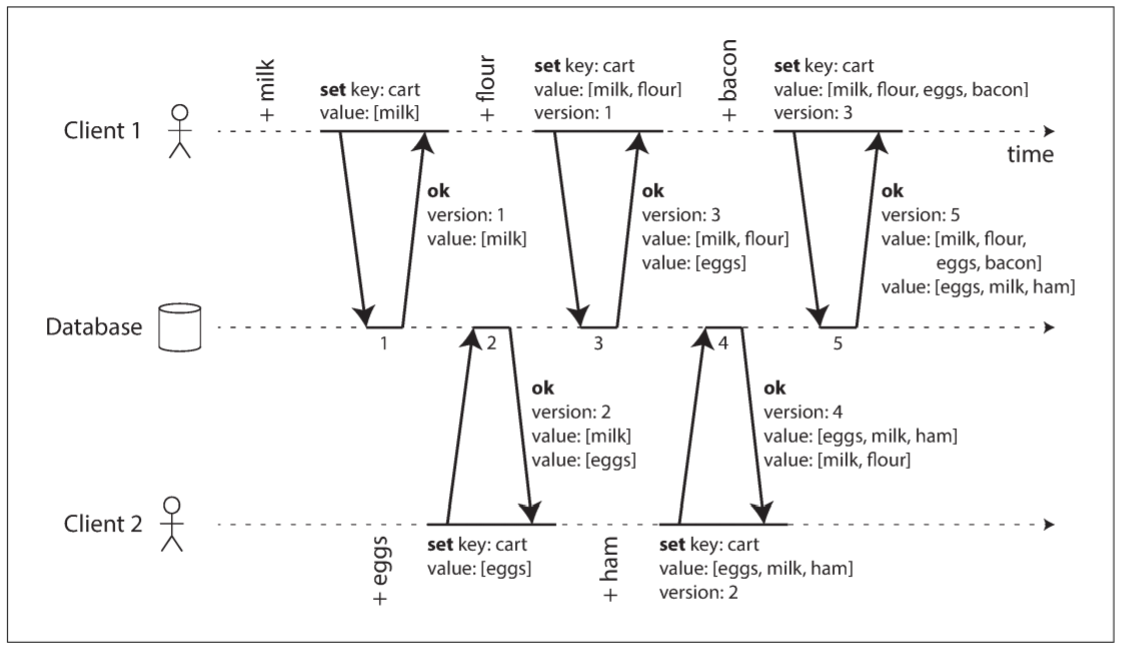
上图展示了两个用户向同一个购物车添加商品. 购物车一开始是空的, 一共进行了五次写入:
- 用户1将牛奶加入购物车. 由于是第一次写入, 数据库保存并为该写入分配版本号1, 最后将值和版本号1返回给用户
- 用户2将鸡蛋加入购物车, 其并不知道用户1同时添加了牛奶(用户2认为购物车里只有鸡蛋). 数据库为该写入分配版本号2, 将鸡蛋和牛奶作为两个独立的值, 然后返回版本号2和两个商品
- 用户1不知道用户2的写入, 想将面粉加入购物车, 并认为购物车只有
[牛奶, 面粉]. 其将两件商品和版本号1一起发送. 数据库从版本号可知[牛奶, 面粉]的写入取代了先前的[牛奶], 但与[鸡蛋]并发. 因此, 数据库为[牛奶, 面粉]分配版本号3, 覆盖版本号1的[牛奶], 但保留版本号2的[鸡蛋], 并返回所有商品和版本号 - 与此同时, 用户2将火腿加入购物车, 其不知道用户1添加了面粉. 之前数据库已将牛奶和鸡蛋发送给用户2, 因此用户2会将版本号2和
[鸡蛋, 牛奶, 火腿]一起发送. 数据库检测到版本号2被覆盖, 但与版本号3的[牛奶, 面粉]并发, 所以剩下两个版本: 版本号3的[牛奶, 面粉], 版本号4的[鸡蛋, 牛奶, 火腿] - 最后, 用户1将培根加入购物车. 之前从数据库获得了两组数据:
[牛奶, 面粉]和[鸡蛋], 合并后将[牛奶, 面粉, 鸡蛋, 培根]和版本号3一起发送. 数据库更新版本号3的[牛奶, 面粉], 该版本与版本号4并发, 所以保留这两个版本.
上述操作流程可用下图表示: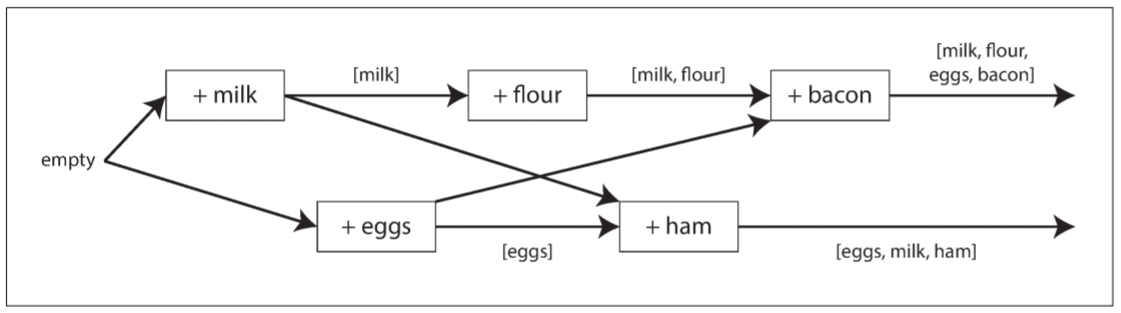
图中箭头表示哪个操作发生在其他操作之前, 意味着箭头操作依赖于箭尾操作. 该例中, 用户永远无法获得数据库的所有数据, 因为总有另一个操作同时进行. 但旧版本的值最终会被覆盖, 且不会丢失任何写入.
通过版本号来判断两个操作是否并发, 而无需查看操作内的数据. 该算法的工作原理如下:
- 数据库为每个键保留一个版本号, 每次写入键时会自增版本号, 并将新版本号和新值一起存储
- 当用户读取键时, 数据库将返回所有未覆盖的值以及最新的版本号. 用户在写入前必须读取
- 当用户写入键时, 必须包含之前读取的版本号, 也必须将新值和上一次读取获得的值合并在一起. 写请求的回应与读取相同, 回应中包含当前所有值, 这样就能将多个写入串联起来
- 当数据库接收到特定版本号的写入时, 其可以覆盖该版本号的所有值(因为数据库知道旧值已经被合并到新值中), 但数据库必须用更高的版本号来保存所有值(因为这些值与随后的写入是并发的)
当一个写入包含上一次读取的版本号时, 说明本次写入基于上次的读取. 若写入不携带任何版本号, 则该写入与其他写入是并发的, 也不会覆盖任何值, 只会在随后的读取中作为一个值返回.
4.4.4 Merging concurrently written values
这种算法可确保数据不会被默默丢弃, 但需要客户端做一些额外工作: 若存在多个并发操作, 客户端必须合并并发写入的值. Riak将这些并发值称为siblings(兄弟).
合并并发值本质上与多leader复制中的冲突解决相同. 根据版本号或时间戳挑选其中一个值, 也意味着丢弃数据, 所以应用代码需灵活地处理数据.
以购物车为例, 一个合理的合并值的方法是求并集. 最后剩下的两个并发值: [牛奶, 面粉, 鸡蛋, 培根]和[鸡蛋, 牛奶, 火腿]. 其中, 牛奶和鸡蛋出现在两个并发值中, 合并后可得: [牛奶, 面粉, 鸡蛋, 培根, 火腿].
然而, 如果应用允许客户端从购物车中移除商品, 则求并集会产生错误结果: 将牛奶从其中一个并发值中移除, 并集中仍会出现牛奶. 为防止出现这种情况, 不能简单地将商品从数据库中删除; 相反, 系统必须保留一个具有合适版本号的标记, 用于提醒客户端在合并时将该商品移除. 这种删除标记称为tombstone(墓碑).
由于应用代码中的合并并发值十分复杂且易出错, 一些数据结构应运而生, 用于自动执行合并. 例如, Riak支持一种称为CRDTs的数据结构家族, 其会以合理的方式自动合并并发值, 包括保留删除.
4.4.5 Version vectors
购物车例子只涉及一个replica, 无leader且存在多个replica时该怎么使用该算法呢?
对于单个replica, 使用单个版本号可捕获多个操作之间的依赖关系; 但当多个replica并发接收写入时, 这还不够. 相反, 除了对每个key使用版本号外, 还需为每个replica使用版本号. Replica在处理写请求时自增自己的版本号, 并跟踪其他replica看到的版本号. 这一信息能指出哪些值被覆盖, 以及保留哪些并发值.
所有replica的版本号集合称为version vector(版本向量). 该思路有很多变种, 其中最有趣的一种是Riak 2.0中的dotted version vector(点线版本向量). 当读取数据时, replica会将版本向量发送给客户端; 写入时, 需将其发送回数据库(Riak将版本向量编码为一个字符串, 称为causal context, 因果上下文). 版本向量允许数据库区分覆盖写入和并发写入.
另外, 就像单个replica一样, 应用代码需要合并并发值. 版本向量结构可确保从replica读取和向replica写入是安全的. 这样做虽然会在其他replica上创建数据, 但只要正确合并就不会丢失数据.