Replication Controllers
1. Introduction
当k8s API server接收到pod请求时, k8s会将pod分配到一个worker node并开始运行. 虽然kubelet可通过各种probe(liveness probe, readiness probe, startup probe)检测pod中container的状态, 但pod只会被部署一次, 因此一旦pod所在的node不可用, 则kubelet和pod都不可用, k8s也不会重新部署该pod. 在解决node不可用之前, 我们需先了解kubelet如何处理pod中container的不可用情况:
- 若container只有一个进程, 当该进程停止运行时, kubelet会自动重启container
- 若container存在多个进程, 当主进程(dockerfile中
ENTRYPOINT或CMD启动的进程)停止运行时, kebelet会自动重启container
但很多情况下, container中的进程处于不可用但未停止运行的状态, 例如: 当Java程序内存不足时会抛出OutOfMemoryErrors, 但JVM进程依然运行, 导致kubelet不会重启container. 因此需要一种机制来告诉kubelet何时重启container.
1.1 Probes for container
K8s提供了三种probe(探针)来检测container状态:
- Liveness probe: 决定是否重启container. 大部分情况下会将liveness probe设置为一个HTTP endpoint, 当container中进程陷入死锁时, k8s在尝试访问多次(failureThreshold)endpoint后会判定container不可用, 并重启container.
- Readiness probe: 决定container是否接受流量, 通常用于等待一些耗时的初始化任务, 例如: 建立网络连接, 加载文件, 初始化缓存.
- Startup probe: 决定container是否启动. 通常和liveness probe一起使用, 避免container被提前重启.
2. Liveness probes
K8s可通过liveness probe检测container是否可用. Liveness probe有三种探测方式:
- HTTP GET probe向container的IP address发送GET请求. 若probe收到的response code为2xx或3xx, 则认为container可用; 否则重启container.
- TCP Socket probe会与container的指定port发起TCP连接. 若成功创建连接, 则container可用; 否则重启container.
- Exec probe在container中执行指定命令, 并检查exit status code. 若为0, 则container可用; 否则重启container.
2.1 Create an HTTP-based liveness probe
创建pod时, 可为每个container指定一个liveness probe. 下例中, probe每隔一段时间(默认10秒)会对名为kubia-liveness的pod所在的IP address下的/路径和8080端口进行HTTP访问.
apiVersion: v1 |
假设container返回500, k8s会自动重启该container. 执行kubectl get pods时, RESTARTS一列会显示该pod中的container重启了多少次:
$ kubectl get po kubia-liveness |
执行kubectl describe pod可获得probe更详细的信息:
$ kubectl describe po kubia-liveness |
上述表示当前运行的container之前被重启过, exit code为137. 退出码为128+x, x表示发送给进程的信号, 也即是SIGKILL.
2.2 Configure additional properties of the liveness probe
Liveness probe还可以配置其他属性:
- initialDelaySeconds: container启动后多久开始probe, 默认为0
- timeoutSeconds: probe发出请求后可等待多久回复, 默认为1
- periodSeconds: probe的请求间隔, 默认为10
- failureThreshold: probe探测到container失败后, 重启container的最大次数, 默认为3, 最小为1.
HTTP GET probe提供了以下属性:
- host: Hostname, 默认为pod的IP address
- scheme: 连接container的方式, HTTP或HTTPS, 默认为HTTP
- path: HTTP资源路径
- httpHeaders: HTTP Header
- port: HTTP port, 范围为[1, 65535]
2.3 Create effective liveness probes
生产环境中, pod中的每个container都应有一个liveness probe. 但需要注意以下几点:
- 上述liveness probe例子对于很多项目来说过于简单, 无法覆盖所有应用面对的问题, 通常会创建一个单独应用用于检测进程是否正常运行, probe只需访问一个专属URL地址(如
/health). - Liveness probe只应检测container内部产生的异常, 而不是外部因素导致的异常, 例如: 当使用liveness probe检测web server运行状况时, 若因数据库问题或其他外部依赖而停止运行, 则不应该让server不断重启.
- Liveness probe的设计必须轻量级, 不应占据太多计算资源, 因为每个container都有资源上限, 且liveness probe与container共享计算资源.
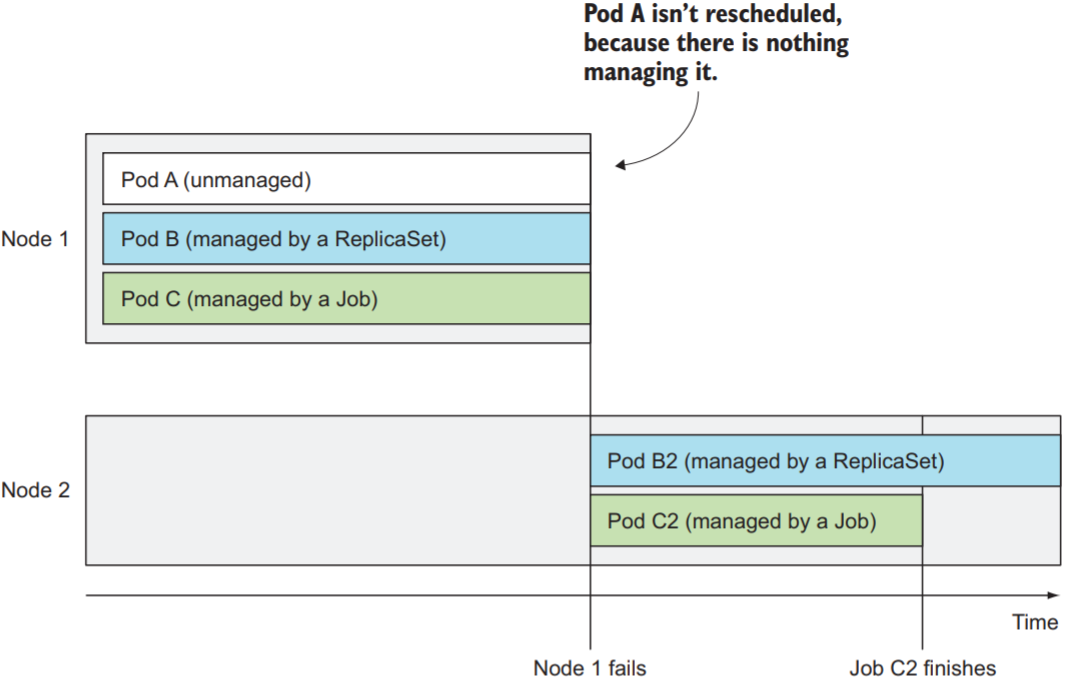
Probe由worker node上的kubelet管理, k8s control plane并不参与, 因此当worker node不可用时, probe也不再可用. 为保证node不可用时, k8s会将该node上所有pod转移到其他worker node上, 需使用ReplicationController或其他机制.
3. ReplicationControllers
ReplicationController作为k8s其中一种资源, 用于确保pods一直保持运行. 当pod消失时(pod被删除或pod所在的node不可用), ReplicationController都会创造新的pod. 下图中, Pod B由ReplicationController管理, 而Pod A被直接创建. 当Node 1不可用时, ReplicationController会在Node 2创建一个新的Pod B来替代失踪的Pod B. 以下ReplicationController简称为RC.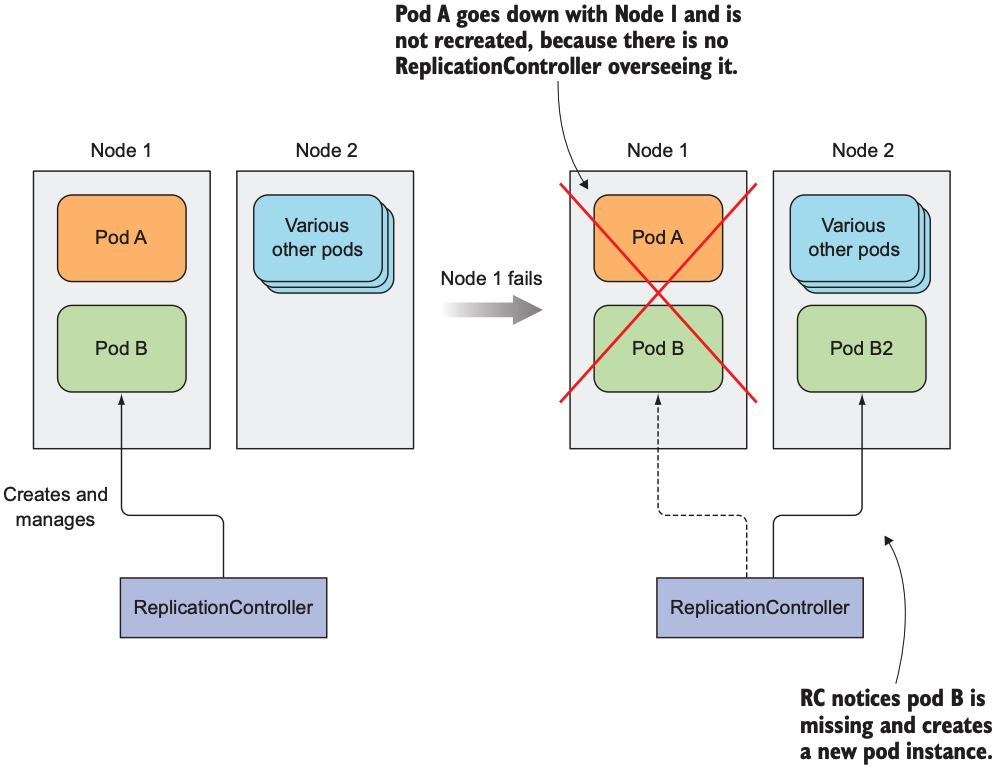
3.1 The Operation of a ReplicationController
RC会持续监控pod集合并确保该类型的pod维持在一定数量:
- 若运行中的pod数量小于目标数量, 则创建新的pod
- 若运行中的pod数量大于目标数量, 则移除多余pod
RC的运行过程如下: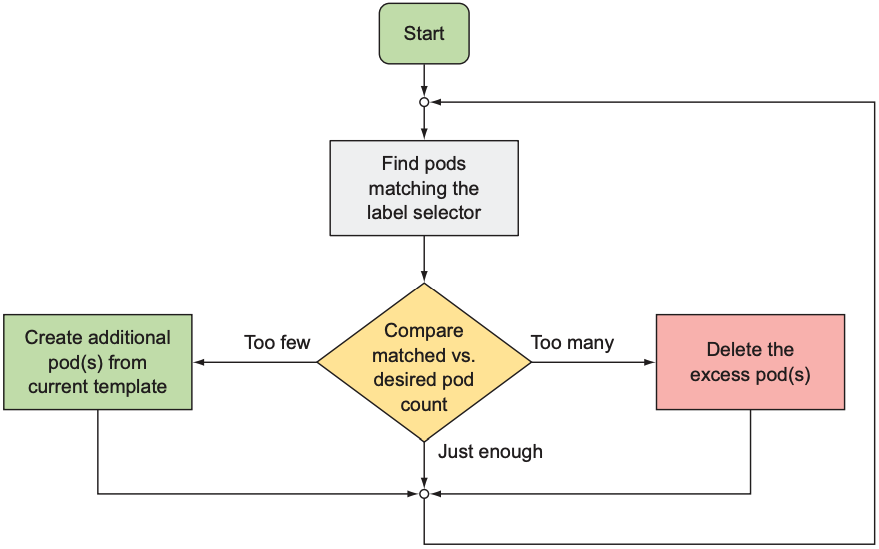
可以看出, RC最重要的目的是保持运行中的pod数量始终与目标数量一致, 比较数量的方法就是label selector: RC创建的pod一定与其label selector匹配, 因此可称为同类型pod. 以下操作会导致运行中的pod数量大于目标数量:
- 创建一个同类型的pod
- 其他pod被修改为同类型
- RC的pod目标数量被下调
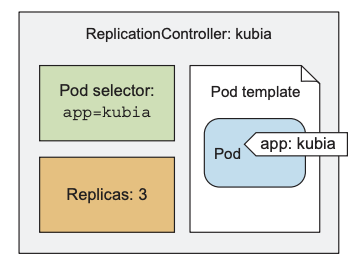
RC由以下三个部分组成:
- label selector: RC管理的pod范围
- replica count: 所需的运行中pod运行数量
- pod template: 创建新pod所需的模板
相比于pod, RC拥有以下优点:
- Pod消失时, 确保新的Pod会被创建并持续运行
- Node不可用时, 会在其他可用node中创建pod
- 提供了一种水平拓展pod的方式
3.2 Create a ReplicationController
RC也通过JSON或YAML文件创建:
apiVersion: v1 |
将YAML文件上传到k8s API server后, k8s会创建名为kubia的RC, 并创建三个label为app=kubia的pod, RC会保证随时都有3个该类型的pod在运行. API server会检查spec.selector与spec.template.metadata.labels是否一致, 为避免label不一致, 可不设置spec.selector, k8s会自动将label selector设置为spec.template.metadata.labels.
K8s允许用户修改label selector, replica count和pod template:
- 修改label selector后, RC会创建新的pod, 之前创建的pod将会被忽略. 需要注意的是, 修改时必须保证
spec.selector与spec.template.metadata.labels一致 - 修改pod template后, 运行中的pod不会有任何改变, 只有RC需要创建新的pod时才会使用新的pod template
- 修改replica count后, RC会立即比较运行中的pod数量是否符合要求, 若小于目标数量, 则创建新pod; 若大于目标数量, 则删除已有pod
3.3 ReplicationController in action
执行kubectl create创建RC:
$ kubectl create -f kubia-rc.yaml |
当pod数量小于目标pod数量时, RC会自动创建新的pod:
$ kubectl delete pod kubia-53thy |
查询所有的rc:
$ kubectl get rc |
以下是node不可用时的情况(本例中共有3个worker nodes, 3个pods):
----- Disconnect one of worker nodes from the network ----- |
当worker node重新连接后, pod的status变为Ready, 最终由于pod数量超过目标值, 因此会被删除.
3.4 Move pods in and out of the scope of a ReplicationController
- Add Labels to Pods Managed by a ReplicationController
RC并不会在意pod上的其他label:$ kubectl label pod kubia-dmdck type=special
pod "kubia-dmdck" labeled
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kubia-oini2 1/1 Running 0 11m app=kubia
kubia-k0xz6 1/1 Running 0 11m app=kubia
kubia-dmdck 1/1 Running 0 1m app=kubia,type=special - Change the Labels of a Managed Pod
修改pod的label可能导致pod脱离RC的管理范围, 从而导致RC创建一个新的pod:$ kubectl label pod kubia-dmdck app=foo --overwrite
pod "kubia-dmdck" labeled
$ kubectl get pods -L app
NAME READY STATUS RESTARTS AGE APP
kubia-2qneh 0/1 ContainerCreating 0 2s kubia
kubia-oini2 1/1 Running 0 20m kubia
kubia-k0xz6 1/1 Running 0 20m kubia
kubia-dmdck 1/1 Running 0 10m foo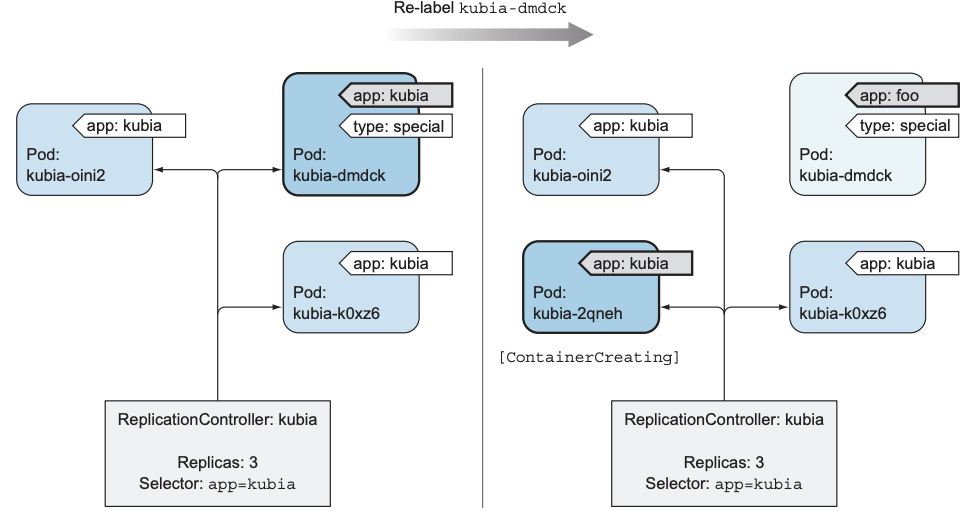
- Remove Pods from RC in Practice
当pod运行错误时, 可删除该pod, RC会自动创建一个新的pod - Change the ReplicationController's label selector
修改RC的label selector后, 之前运行的Pod会脱离管理并继续运行, RC会创建新的pod来保持replica count, 但绝大多数情况下都不需要修改label selector
3.5 Change the pod template
修改RC的pod template不会影响已经运行的Pod, 若想让所有运行的pod遵循新的pod template, 需要手动删除所有pods.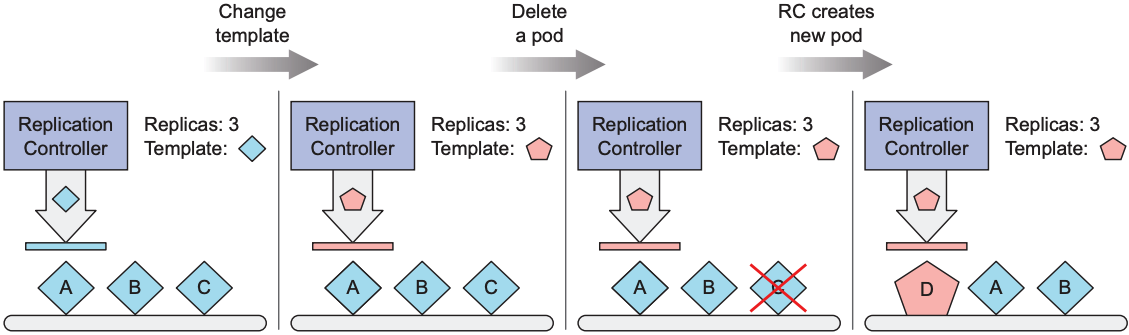
执行kubectl edit rc <rc-name>会打开RC的YAML文件, 修改后保存即可. 若需修改editor, 可修改环境变量KUBE_EDUTOR为目标editor路径.
3.6 Horizontally scaling pods
有两种方法改变replica count:
- 执行
kubectl scale修改replica count:$ kubectl scale rc kubia --replicas=<num-of-desired-replicas>
- 执行
kubectl edit修改RC的YAML文件:kubectl edit rc kubia
3.7 Delete a ReplicationController
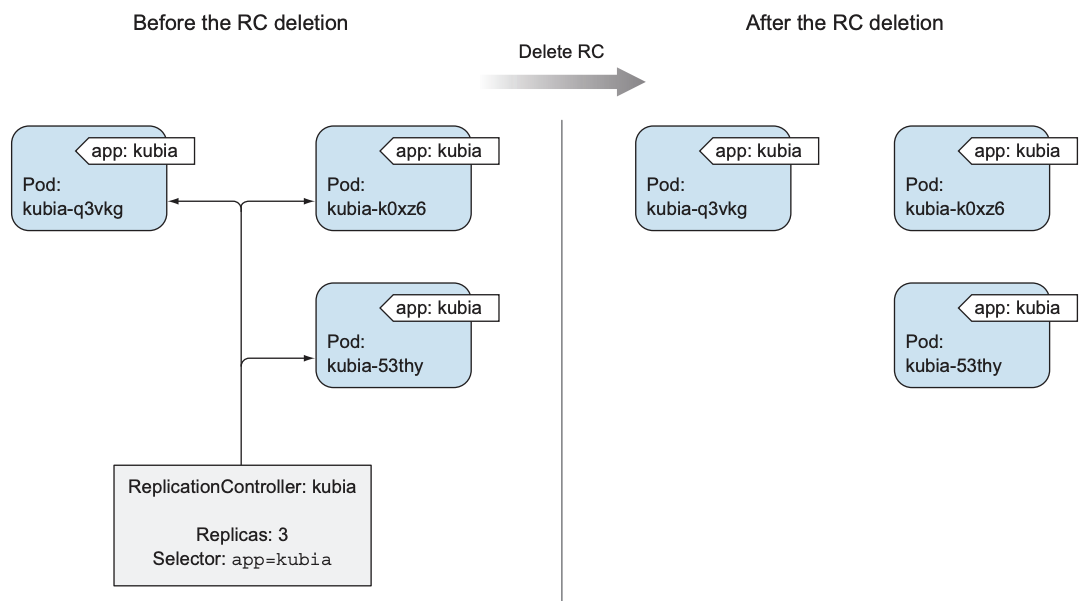
执行kubectl delete不仅会删除RC, 还会删除其管理的所有pods. 若想在删除RC的前提下保留其pods, 可加上--cascade=false:
$ kubectl delete rc kubia --cascade=false |
4. ReplicaSet
最一开始, RC是k8s中唯一可以水平拓展pod的工具, 但之后引入了ReplicaSet, 其可以完全替代RC. ReplicaSet相比于RC的最大区别在于selector. 例如: RC不支持selector中同一key拥有多个value值(例如: env=devel, env=production), 也不支持selector只包含key, 不包含value.
apiVersion: apps/v1beta2 |
ReplicaSet与RC的区别如下:
- ReplicaSet不属于v1, 而是v1beta2
- ReplicaSet的selector为
selector.matchLabels
ReplicaSet支持更复杂的label selector, matchLabels与RC的selector并无区别, matchExpressions则支持更复杂的label匹配:
selector: |
matchExpressions必须包含key和operator, value是可选项. 以下是operator的所有选项:
- In: pod的value需匹配selector的其中一个value
- NotIn: pod的value需与selector中的所有value不同
- Exists: pod需拥有selector的key, 不可设置value
- DoesNotExist: pod不能拥有selector的key, 不可设置value
若同时使用了matchLabels和matchExpressions, 只有全部符合条件的pod才会被ReplicaSet管理.
5. DaemonSet
RC和ReplicaSet都可让k8s cluster中运行特定数量的pod, 但无法保证哪个pod被分配到了哪个worker node, 有时我们需要每个worker node都运行一个pod, 例如用于收集node信息的log collector或kube-proxy.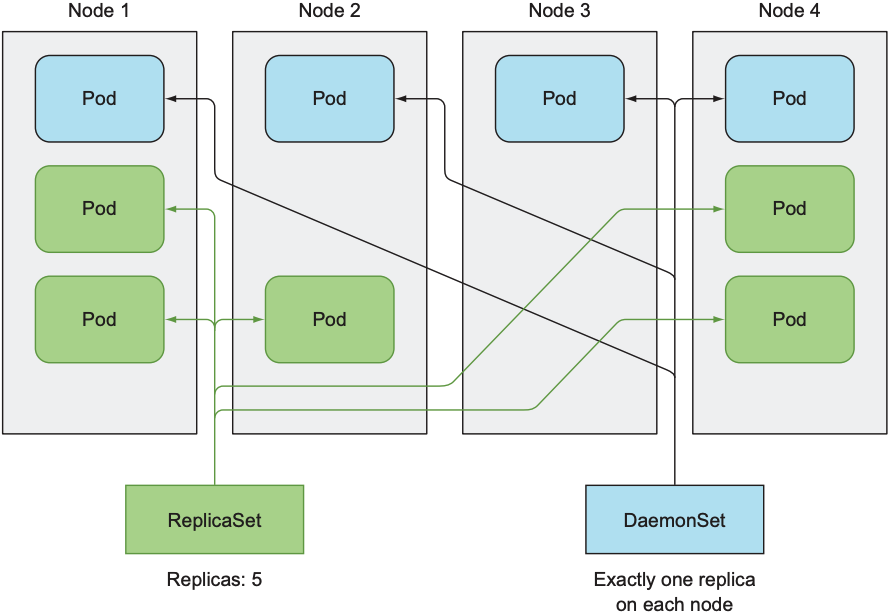
DaemonSet不需要replica count, 因为pod数量只与worker node的数量相关:
- 当某个node不可用时, DaemonSet不会创建新的pod
- 当添加一个新的node时, DaemonSet会立即创建新的pod
若只想在某些node上分别运行一个pod, 可使用node selector来告诉DaemonSet需要管理哪些node.
apiVersion: apps/v1beta2 |
执行kubectl create创建DaemonSet:
$ kubectl create -f ssd-monitor-daemonset.yaml |
以下是DaemonSet的运行结果: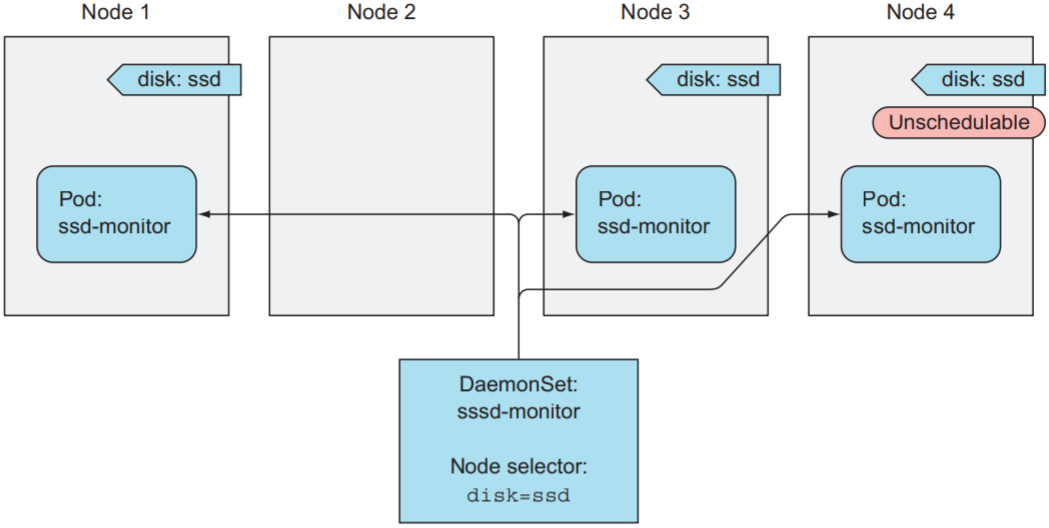
当node移除或修改app: ssd label时, DaemonSet会删除该node上的Pod:
$ kubectl label node minikube disk=hdd --overwrite |
6. Job
RC, ReplicaSet和DaemonSet都有一个共同点: 它们会保证管理的pod一直保持运行状态, 当pod中的进程退出时, 它们会自动重启container. 但有时我们只想完成一些一次性工作, 并不需要pod一直运行. Job作为k8s的一种资源, 会在Pod成功运行后自行结束, 以下是pod无法正常执行完毕时的处理:
- Pod所在的node不可用: job会将该pod分配给其他node
- Pod运行失败: job可选择是否重启该pod
6.1 Define a Job resource
apiVersion: batch/v1 |
配置job时需注意以下几点:
- Job的
restartPolicy不可为Always, 因为job需要在pod执行完成后停止 - Job中的pod的
restartPolicy必须设置为OnFailure或Never, 保证kubelet不会重启已经完成的container
6.2 Seeing a Job run a Pod
$ kubectl get jobs |
需要注意的是, 已经完成的pod默认不会显示在kubectl get pods输出中, 必须加上--show-all或-a才能显示已完成的Pod.
6.3 Run multiple pod instance in a Job
Job还包含两个重要属性:
- completions: 总共需要多少个pod完成执行
- parallelism: 可同时运行多少个pod
通过设置这两个属性, 可实现串行或并行运行pod:
- Run Job Pods Sequentially
未设置parallelism时, Job会一个个创建pod并等待其运行完毕apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5
template:
... - Run Job Pods in Parallel
设置parallelism时, Job会同时运行多个PodapiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5
parallelism: 2
template:
...
Job运行时仍可通过kubectl scale修改Job的parallelism. 若pod运行时过长, 可在pod中设置activeDeadlineSeconds, 若pod运行时间超过该值, k8s会判断job失败并终止当前pod.
7. CronJob
Job会在其创建时立即运行pod, 无法在某个特定时刻运行pod. CronJob作为k8s的一种资源, 具有定时执行功能, 精确到秒. 假设我们需要每隔15分钟执行一次任务:
apiVersion: batch/v1beta1 |
CronJob的schedule属性分为以下5个值:
- Minute
- Hour
- Day of month
- Month
- Day of week
若需每个月第一天每隔30分钟执行一次, 可设置为0, 30 * 1 * *; 若需每个周日的3AM执行, 可设置为0 3 * * 0. 一般来说, pod的创建时间会比指定时间晚一点, 若对pod的执行时刻有严格限制, 可在YAML文件中设置startingDeadlineSeconds. 例如:
apiVersion: batch/v1beta1 |
上述例子中, 若pod未能在10:30:15之前执行, 则不会运行pod, 并将其标记为Failed.