Services
1. Introduction
当我们使用pod时, 有些pod只需单独运行, 但有些pod需要响应外部请求. 在microservices中, pod之间通过HTTP请求相互通信. 在k8s之前, 应用在服务器上运行, 服务器之间的通信需要系统管理员手动配置每个服务器的IP地址或hostname, 但在k8s中不能为pod手动配置, 原因如下:
- Pod生存周期短暂: pod会由于各种原因而随时消失或创建, 例如, 调整ReplicaSet的replica count
- K8s会在分配pod到某个node和启动pod之间为pod分配IP地址, 因此client无法提前获知其IP地址
- 水平拓展导致多个pod具有相同功能: client不应关心有多少个pod提供了对应服务, 同功能的pod应共享一个IP地址
为解决这些问题, k8s提供了名为Service的资源, 其可为cluster内的一组pod提供单一且不变的入口: service的IP地址和端口号不会改变. client向service发送请求时, 请求会被转发给其中一个pod, 因此client不必在意pod处于哪个node中, 或一共有几个pod.
假设现在有一个网站项目: 多个pod运行frontend, 单个pod运行backend. 该项目存在两个问题:
- client向frontend的某个pod发送请求
- frontend接收到client请求后需要连接backend, 我们并不想在backend pod移动到其他node时重新配置frontend pod
解决方案: 为frontend创建一个service, 并为backend创建一个service. 当pod的IP地址改变时, service的IP地址也不会改变, cluster中的任何资源都可通过service的IP地址或service的名字访问.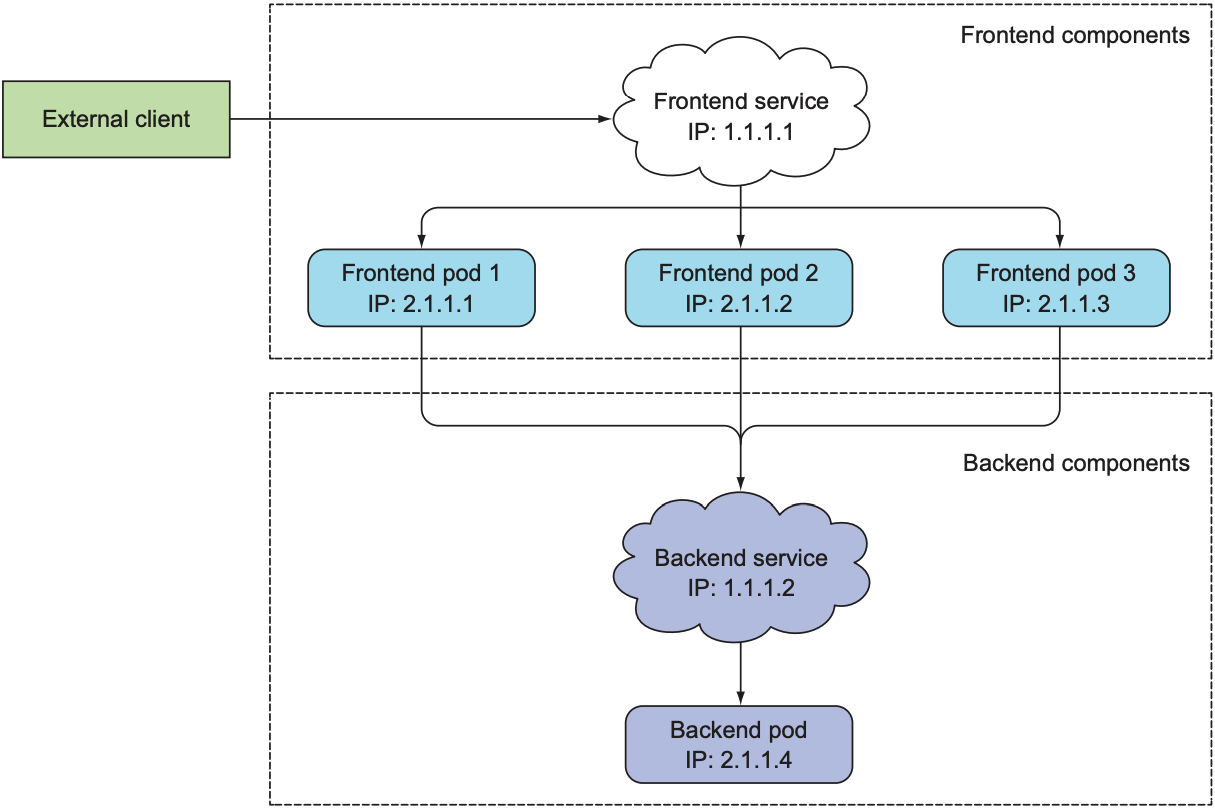
1.1 Create Services
我们现在有一个ReplicationController, 其中包含三个pod, service负责为所有pod提供一个统一入口.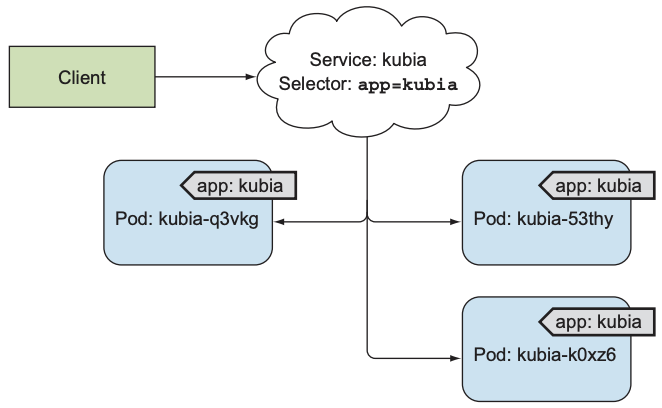
Service使用label selector选择pod. 以下是两种创建service的方式:
- 执行
kubectl expose - 创建YAML文件并执行
kubectl create,port为service的端口号,targetPort为pod的端口号.
apiVersion: v1 |
执行kubectl get svc可查看当前cluster上的所有service:
$ kubectl get svc |
需要注意的是, service的cluster IP只是cluster内部IP地址, cluster外无法访问该IP地址. 以下是在cluster内测试test的几种方式:
- 创建一个pod并向cluster IP发送请求, 查看pod日志来查看是否回复
- 通过ssh进入node, 执行curl向service发送请求
- 执行
kubectl exec进入运行中的pod, 执行curl向service发送请求
1.1.1 Remotely Execute Commands in Running Containers
kubectl exec可实现在pod内的任意一个container中执行命令. 以下例子从名为kubia-7nog1的pod中执行curl, 10.111.249.153为service的IP地址:
$ kubectl exec kubia-7nog1 -- curl -s http://10.111.249.153 |
Double dash(--)是kubectl的option, 可防止kubectl读取命令时将--后的命令当做kubectl的参数. 若不使用--, 则-s会被当作kubectl的参数. 以下是kubectl exec的执行流程: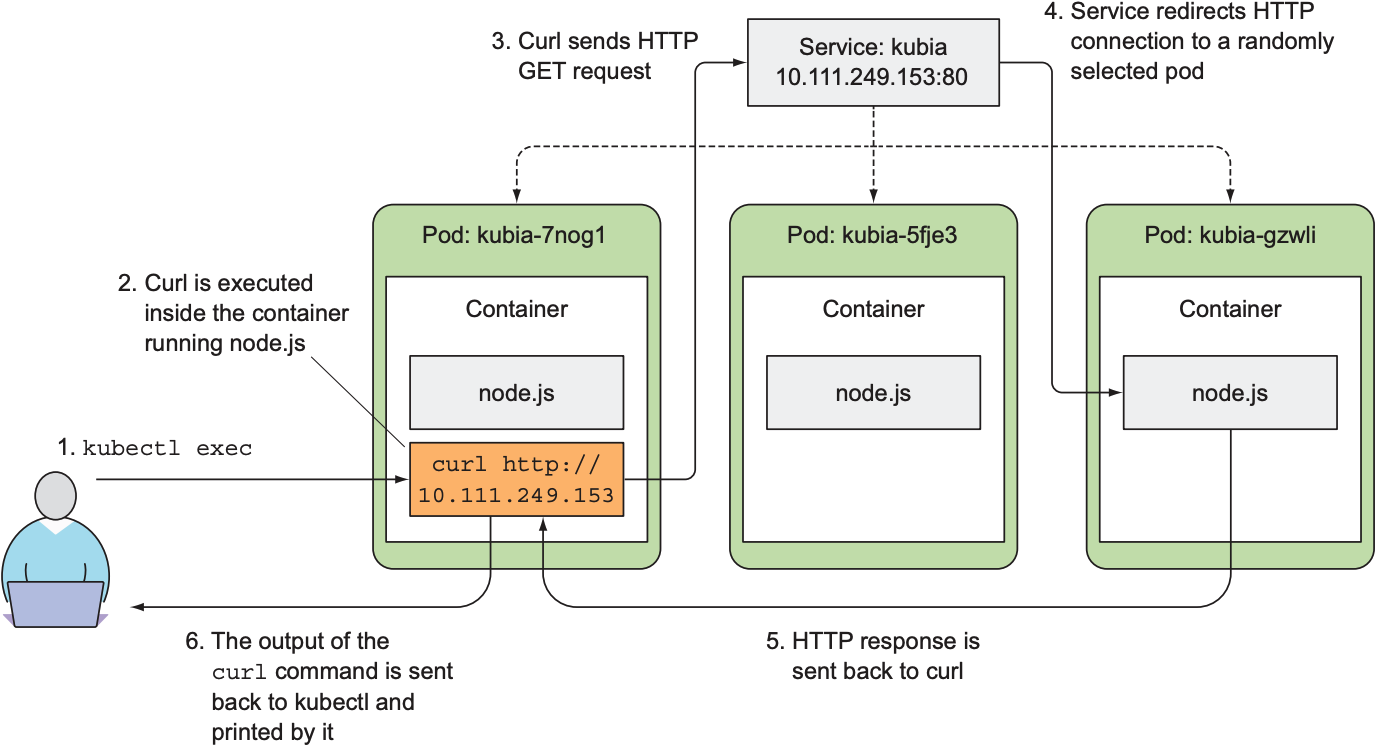
1.1.2 Configure Session Affinity on the Service
由于service转发请求时会随机挑选一个pod, 因此client每次请求时可能遇到不同pod. 若需要client的所有请求都发送给同一pod, 则需设置sessionAffinity属性:
apiVersion: v1 |
sessionAffinity只支持ClientIP和None(默认为None). 由于service不解析应用层, 因此无法支持基于cookie的session affinity, 只能通过IP地址进行load balance. 设置为ClientIP后, 即使同一个IP address下有多个client连接, 也只会连接到同一Pod.
1.1.3 Expose Multiple Ports in the Same Service
Service支持多个端口号. 当pod监听多个端口号时, service可设置对应端口号, 但需要注意的是, 每个端口号都需要指定名字:
apiVersion: v1 |
1.1.4 Use Named Ports
上述例子需在Service的YAML文件中明确标注pod的端口号, 但如果我们在pod的YAML文件中为端口号命名, 则service的YAML文件中可直接使用端口号名.
kind: Pod |
即便pod修改其端口号, Service也不需要做任何修改:
apiVersion: v1 |
1.2 Discover Services
虽然service提供了一个稳定的IP地址和端口号, 但client如何获知Service的IP地址和端口号? 如果需要知道service的IP地址才能访问, 那么service必须在client前创建. K8s提供多种方式让client检测service的IP地址和端口号.
1.2.1 Discover Services through Environment Variables
当k8s启动pod时, 会在pod的environment variable(环境变量)中初始化所有service信息. 若client在service之后创建, 则client pod可通过环境变量访问service的IP地址和端口号.
$ kubectl exec kubia-3inly -- env |
使用环境变量获取service的IP地址和端口号需注意以下几点:
- 若pod的创建时间早于service, 则pod的环境变量中不包含该service
- 若pod的创建时间晚于service, 但pod创建后执行
kubectl edit修改service, 则pod的环境变量不会包含修改后的service - 关于service的环境变量命名规则如下:
- Service的环境变量全部为大写字符
- Service的IP地址为
<SVC_NAME>_SERVICE_HOST - 若service的YAML文件中未标注
ports.name, 则service的端口号为<SVC_NAME>_SERVICE_PORT - 若service的YAML文件中标注
ports.name, 则service的端口号为<SVC_NAME>_SERVICE_PORT_<PORT_NAME>
1.2.2 Discover Services through DNS
名为kube-system的namespace中有一个pod名为kube-dns, 其作为一个DNS server负责将FQDN转换为IP地址. Cluster中其他pod都可通过该pod查询任何资源的IP地址(每个container的/etc/resolv.conf中包含kube-dns的地址), pod可通过设置dnsPolicy选择是否使用内部DNS解析. Service作为一种资源, 也会在kube-dns中保留一个DNS entry, client只需通过kube-dns查询service的FQDN即可获取其IP地址. 以backend database service为例, 其FQDN为:
backend-database.default.svc.cluster.locals |
backend-database为service的名字, default表示service所在的namespace, svc表示资源类型为service, cluster.local为所有cluster domain的后缀, 因此可以不写该后缀. 若frontend pod与backend pod处于同一namespace, 也可省略default, FQDN直接写backend-database即可. 同理, 每个pod也拥有各自的FQDN, 例如: 192-168-0-6.default.pod.cluster.local, 192-168-0-6表示pod的IP地址, default表示pod所在namespace, pod表示资源类型为pod, cluster.local则为默认后缀. 但由于client需要知道pod的IP地址才能访问域名, 与域名解析的初衷相悖, 因此通常会在pod的spec.hostname和spec.subdomain设置自定义域名.
通过内部DNS域名解析获取service的IP地址的优缺点如下:
- 创建service时会自动在DNS server中注册DNS entry, 因此client不必在service之后创建
- 域名解析只能返回service的IP地址, 端口号仍需手动配置, 或从环境变量获取
1.2.3 Run a Shell in a Pod's Container
直接进入pod后查看/etc/resolv.conf也可以看到FQDN
$ kubectl exec -it kubia-3inly bash |
需要注意的是, 我们无法ping该service的IP地址, 因为service的IP地址是一个虚拟地址, 只有同时使用service的IP地址和端口号时才会使用到service.
2. Connect to services living outside the cluster
上一节只提到了通过service与cluster内pod的通信, 但client也可以通过service与cluster外的服务通信.
2.1 Endpoints
K8s中, service并不会直接与pod相连, 而是让endpoint作为中介. 若service包含label selector, k8s创建service时会自动创建对应的endpoints. Endpoint是k8s的一种资源, 其包含一个或多个IP地址和端口号, 负责将pod和service连接起来. 执行kubectl describe svc时会看到该service的endpoints:
$ kubectl describe svc kubia |
也可执行kubectl get endpoints直接读取service的endpoints:
$ kubectl get endpoints kubia |
虽然service有label selector, 但并不会在转发请求时使用. 相反, selector由endpoint拥有. Service接收到了请求后, 会从endpoint中挑选一个IP地址和端口号, 并将请求转发给该地址.
2.2 Manually Configure Service Endpoints
K8s之所以这样设计, 是为了将service与IP地址/端口号分离, 允许用户手动配置地址. 因此为了手动配置endpoint, 可以创建一个没有label selector的service:
apiVersion: v1 |
Endpoint也可通过YAML文件创建. Endpoint的metadata.name必须与service同名, 并在subsets中指定IP地址和端口号.
apiVersion: v1 |
Service和endpoints创建完毕后, 之后创建的pod的环境变量中都包含service的IP地址和端口号.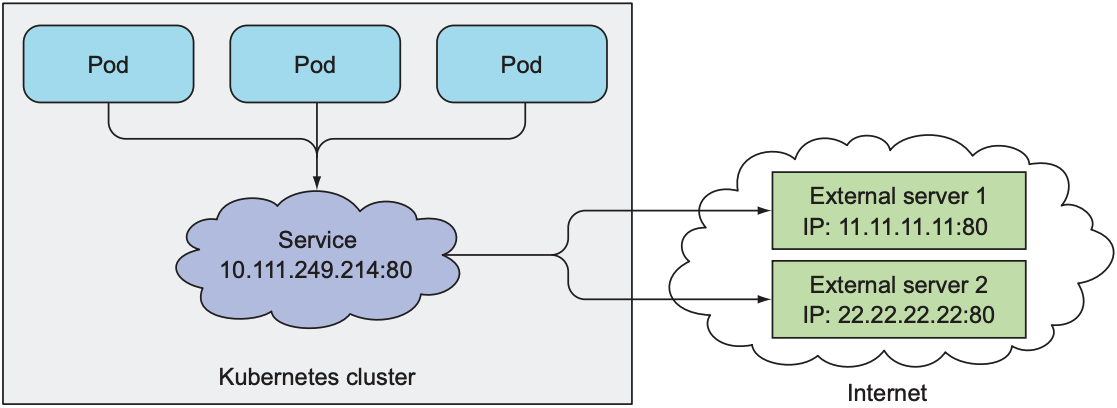
若外部服务并入cluster中, 可给service添加label selector, k8s会自动更新service对应的endpoints; 若service已有label selector, 将selector移除后, k8s不会再更新endpoint, 这意味着service拥有的IP地址永远不会改变.
2.3 Create an Alias for an External Service
手动配置endpoint让service将请求转发到外部服务虽然可行, 但若外部服务频繁变换地址, 每次变更都需手动更新; K8s提供了更简单的方法: service的spec.type默认为ClusterIP, 表示service只能从一组IP地址中选择一个转发请求; 若将service的spec.type设置为ExternalName, service会将请求转发给spec.externalName, 从而实现访问cluster外部服务.
apiVersion: v1 |
K8s会为ExternalName类型的service创建一个CNAME DNS record. 当pod访问external-service.default.svc.cluster.local时, 请求会被转发给someapi.somecompany.com, 因此service也不需要cluster IP.
3. Expose Services to External Clients
前两节只讲到pod通过service向cluster内/外的服务发送请求. 本节则着重于cluster外部服务通过service向pod发送请求. 例如: 为frontend webserver创建service, 从而让cluster外的client顺利访问frontend webserver.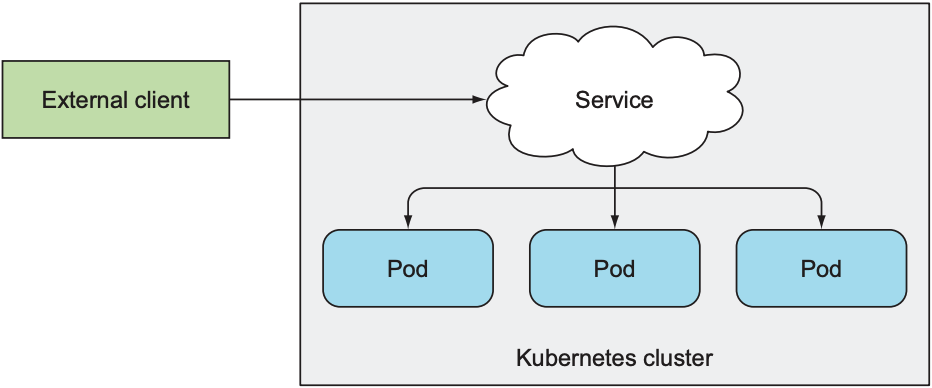
3.1 NodePort
当使用NodePort类型的service时, k8s会在每个node上保留一个端口号用于该service使用:
apiVersion: v1 |
该类型的service支持pod访问service的cluster IP, 也支持外部服务访问node的IP地址, 但两者访问的端口号不同:
- cluster IP对应
spec.ports.port - Node IP对应
spec.ports.nodePort
当cluster外的client访问cluster中任意node的nodePort时, 都会被service转发到对应的pod, 从而实现cluster外client访问pod. 假设cluster中存在两个node, service如下:
$ kubectl get svc kubia-nodeport |
以下三种方式都可以访问该service:
- 10.11.254.223:80
- <1st node's IP>:30123
- <2nd node's IP>:30123
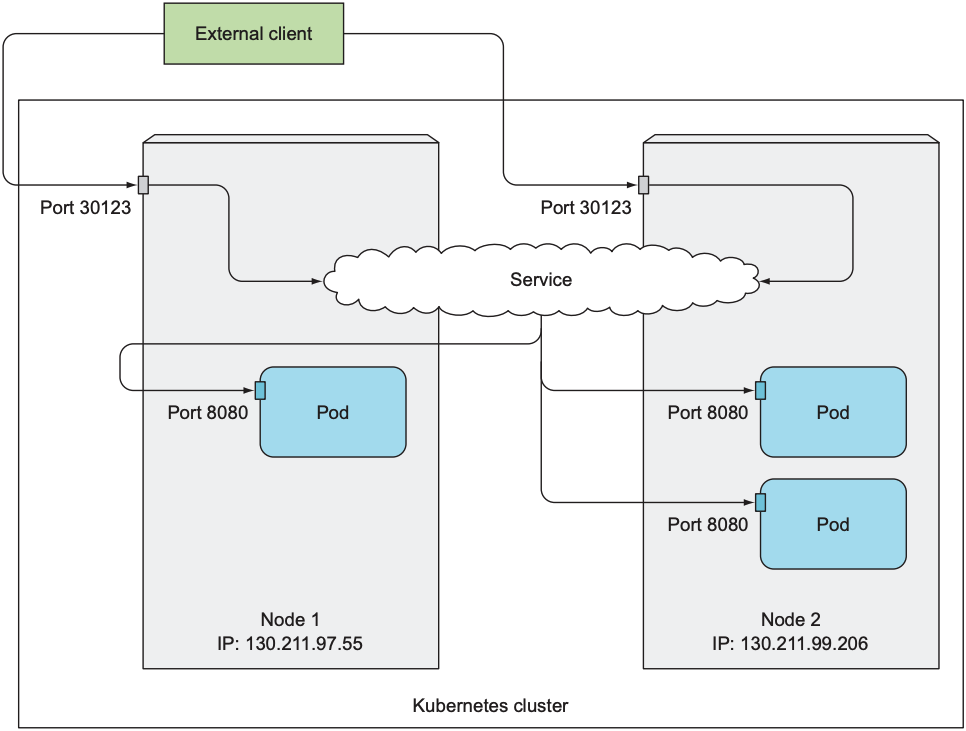
无论cluster外的client向哪个node发送请求, 只要访问端口号为30123, 都会被service转发给对应pod. 虽然client可以向任意node发送请求, 但需要注意的是, 若client发送请求的node不可用, 则请求不会被service处理, 因此通常会在node前使用load balancer, 以便所有请求都会发送给可用的node.
3.2 LoadBalancer
K8s cluster通常运行在云服务提供商的云基础设施上, 绝大多数云服务提供商都提供load balancer. 将service的类型设置为LoadBalancer时, 云服务提供商会自动添加一个load balancer, 其拥有一个公有IP地址, 会将所有请求都转发给service. 因此client无需知道node的地址, 直接访问load balancer的IP地址即可与pod通信:
apiVersion: v1 |
执行kubectl create后, 云服务提供商会创建一个load balancer, 并将其IP地址写入service的status.loadBalancer.
$ kubectl get svc kubia-loadbalancer |
上例中, 130.211.53.173即为load balancer的公有IP地址.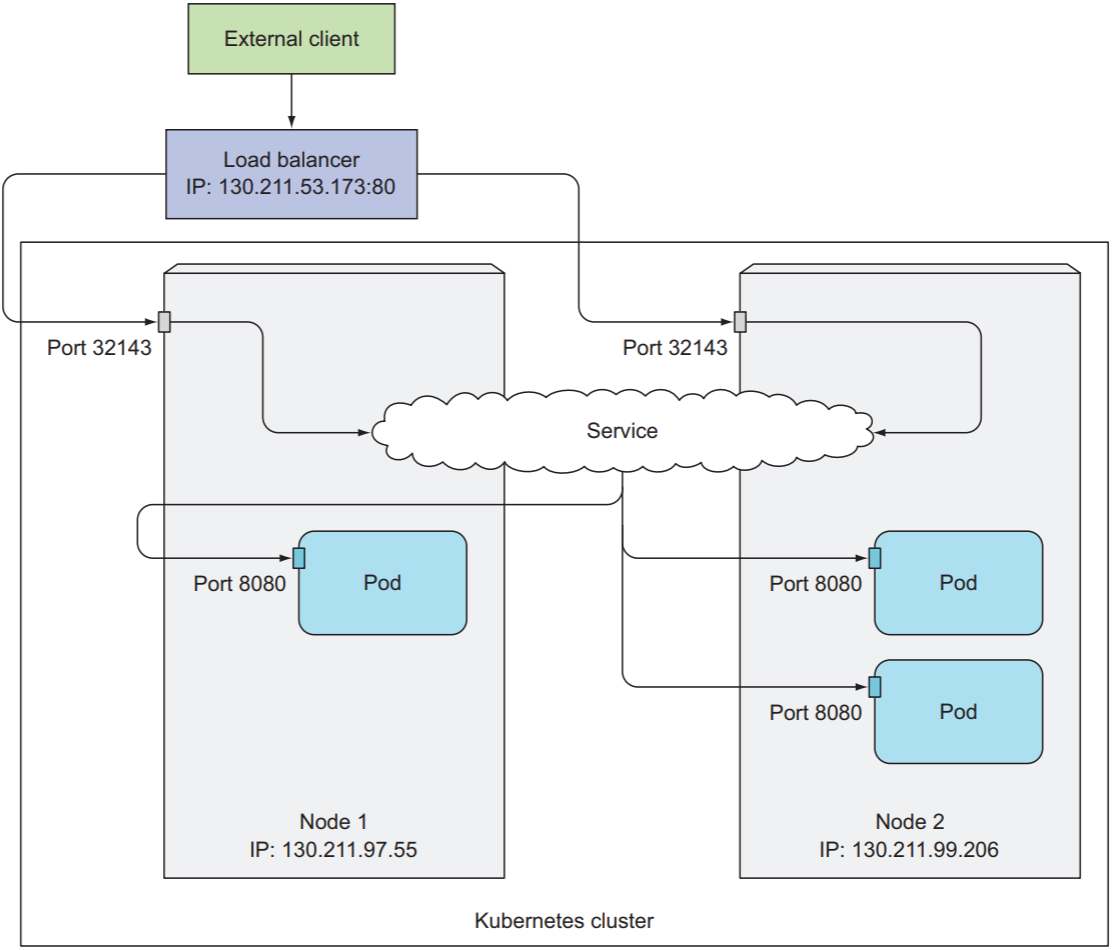
需要注意的是, LoadBalancer类型的service不再负责挑选pod, client会直接向load balancer发送请求, 并由load balancer选择pod. 由于浏览器会使用keep-alive connection, 而云服务提供商的load balancer通常支持基于cookie的负载均衡, 即便service的sessionAffinity为None, 一个连接内的请求也只会发送给同一个pod.
LoadBalancer类型的service也会在每个node上保留一个端口号, LoadBalancer可以说是NodePort的超集, 只是多提供了一个load balancer.
3.3 Summary of Service
K8s中的每个node都会运行一个kube-proxy, 其与API server保持连接, 确保service和endpoint始终处于最新状态, 并符合配置和管理node上的路由规则. Kube-proxy支持四种模式:
- iptables (default)
- ipvs
- userspace
- kernelspace
以下只讨论iptables模式下的k8s网络配置. 由于数据包的路由规则最终由node上的iptables决定, 因此三种不同类型的service的实现方式如下:
- ClusterIP:
- Pod中container产生的数据通过veth pair从container network namespace的网络接口流向node network namespace的docker0接口
- 在node network namespace中, 数据会在iptables的
nattable中的PREROUTINGchain中经过一系列跳转 - k8s依赖iptables内核随机模块来实现负载均衡
- 使用DNAT将cluster ip转化为pod的ip address
- Node Port:
- 数据包直接发送到k8s clsuter中的某个node, 在node network namespace的
PREROUTINGchain中匹配KUBE-SERVICES - 在
KUBE_SERVICES中匹配KUBE-NODEPORTS - 在
KUBE-NODEPORTS中根据端口号匹配KUBE-SVC-XXX - 后续与cluster ip类型相同
- 数据包直接发送到k8s clsuter中的某个node, 在node network namespace的
- Load Balancer:
- 外部client向load balancer发送数据
- load balancer接收到数据后通过某种复杂均衡算法将数据发送给k8s cluster中的某个node
- 后续与node port类型相同
3.3 The Peculiarities of External Connections
Service提供了两种外部client访问集群pod的方式:
- NodePort: client向node发送请求
- LoadBalancer: client向load balancer发送请求, load balancer将请求转发给一个可用的node
假设client发送的请求直接或被load balancer转发给node1, 而node1中并不存在对应的pod, 则node1会将请求的source IP address替换为自己的IP address, 并将destination IP address替换为pod的IP address, 并转发给对应的node(假设其名为node2). 此时会引发两个问题:
- node1每次收到请求时, 都需将请求转发给node2, 构成网络延迟
- node2收到请求时, 请求的source IP address并不是client的IP address, 而是node1的IP address
为解决上述问题, 可在service中配置:
spec: |
若client访问的node中没有对应pod, 则连接会被挂起, 而不是转发给其他node. 使用externalTrafficPolicy前需注意两点:
- 由于node不会转发请求, 因此需保证client或load balancer将请求发送给拥有pod的node
- 由于node会自动平衡负载, 因此将
externalTrafficPolicy设置为Local可能造成负载失衡, 如下图: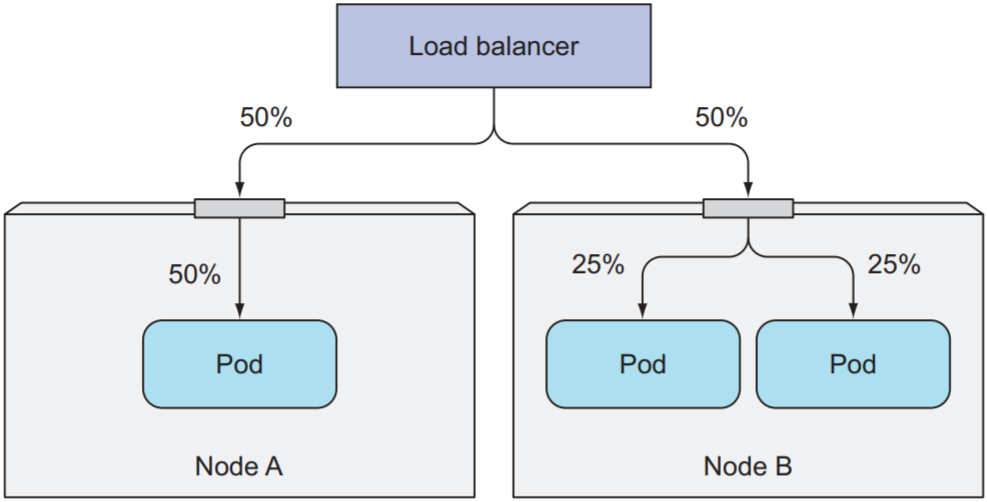
若只是为了保留client的source IP address, 也可使用以下方案:
- 对于HTTP应用, 可使用HTTP header中的
Forwarded或X-FORWARDED-FOR - 使用proxy协议
4. Expose Services Externally through an Ingress Resource
LoadBalancer虽然解决了外部client如何访问pod的问题, 但由于load balancer需要一个公有IP地址, cluster中的service越多, 就需要越多的公有IP地址. K8s为此提供Ingress, Ingress只需一个公有IP地址, 由于Ingress在HTTP应用层操作, 可根据HTTP请求的host和path将请求转发给不同的service: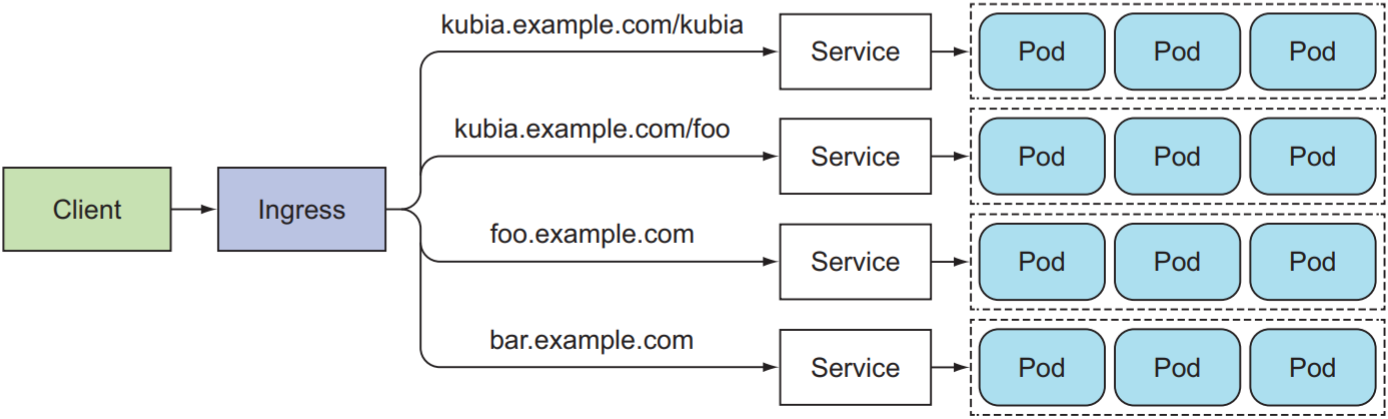
以下是创建Ingress的YAML示例, 其中包含一条rule: 发送向kubia.example.com的请求会被转发给名为kubia-nodeport的service上的80端口
apiVersion: extensions/v1beta1 |
4.1 Access the Service through the Ingress
访问service前需得知Ingress的IP地址:
$ kubectl get ingresses |
得知Ingress的IP地址后, 可让DNS server将该域名解析为Ingress的IP地址, 或在本地的/etc/hosts配置192.168.99.100 kubia.example.com. 向kubia.example.com发送请求时, 请求首先会被解析为Ingress的IP地址, Ingress根据域名选择对应的service, 并通过service对应的endpoint得知对应pod的IP地址, 并将请求转发给该pod的IP地址: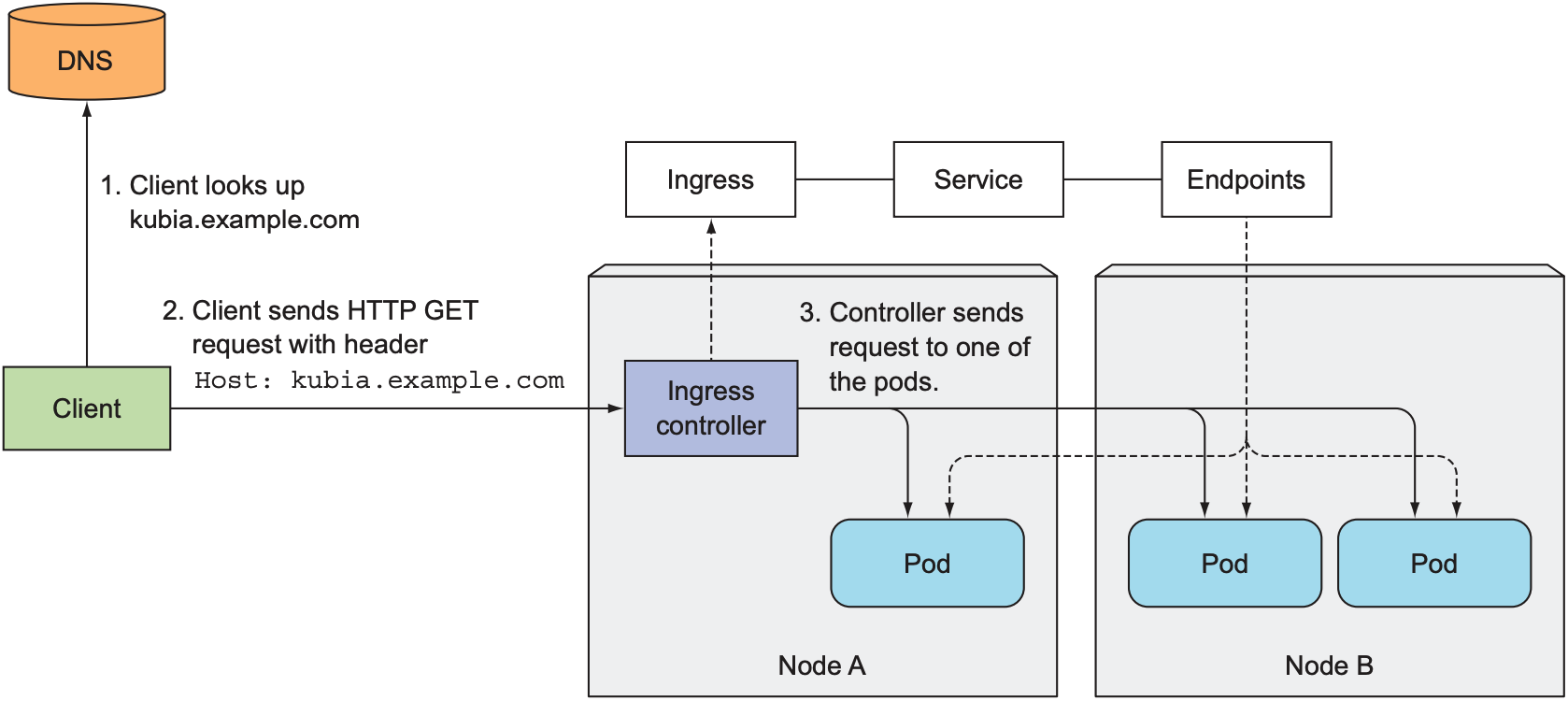
4.2 Expose Multiple Services through the Same Ingress
Ingress的rules和paths为数组, 因此可将多个host, path和service组合成不同情况:
- 同一host下的多个path指定不同service:
...
- host: kubia.example.com
http:
paths:
- path: /kubia
backend:
serviceName: kubia
servicePort: 80
- path: /foo
backend:
serviceName: bar
servicePort: 80 - 不同host下的同一path指向不同service:
...
spec:
rules:
- host: foo.example.com
http:
paths:
- path: /
backend:
serviceName: foo
servicePort: 80
- host: bar.example.com
http:
paths:
- path: /
backend:
serviceName: bar
servicePort: 80
4.2 Configure Ingress to handle TLS Traffic
为支持client与Ingress的加密通信, 需让Ingress支持TLS:
- 创建private key和certificate:
$ openssl genrsa -out tls.key 2048
$ openssl req -new -x509 -key tls.key -out tls.cert -days 360 -subj /CN=kubia.example.com - 创建secret
$ kubectl create secret tls tls-secret --cert=tls.cert --key=tls.key
secret "tls-secret" created - 在Ingress中配置tls和secret
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
tls:
- hosts:
- kubia.example.com
secretName: tls-secret
rules:
- host: kubia.example.com
http:
paths:
- path: /
backend:
serviceName: kubia-nodeport
servicePort: 80
5. Signal when a Pod is Ready to Accept Connections
当pod被创建时, 若其带有service对用的label, 则会被纳入对用service的管理. 若pod需要一定时间初始化, 而service将client请求转发给该client, 则会发生异常情况, 因此K8s提出readiness probe来帮助service判断pod是否可以处理请求, readiness probe会定期检查pod, 但并不负责终止或重启pod. 与liveness probe相同, readiness probe也有三种类型:
- Exec probe: 在container中执行command, 检查exit status code
- HTTP GET probe: 向container发送HTTP GET请求, 检查HTTP status code
- TCP Socket probe: 向container的某一端口创建TCP连接, 检查是否成功创建连接
假设一个service拥有3个pod, 其中一个pod的readiness probe探测失败, 则会将该pod从service中移除, 从而避免将外部请求转发给该pod.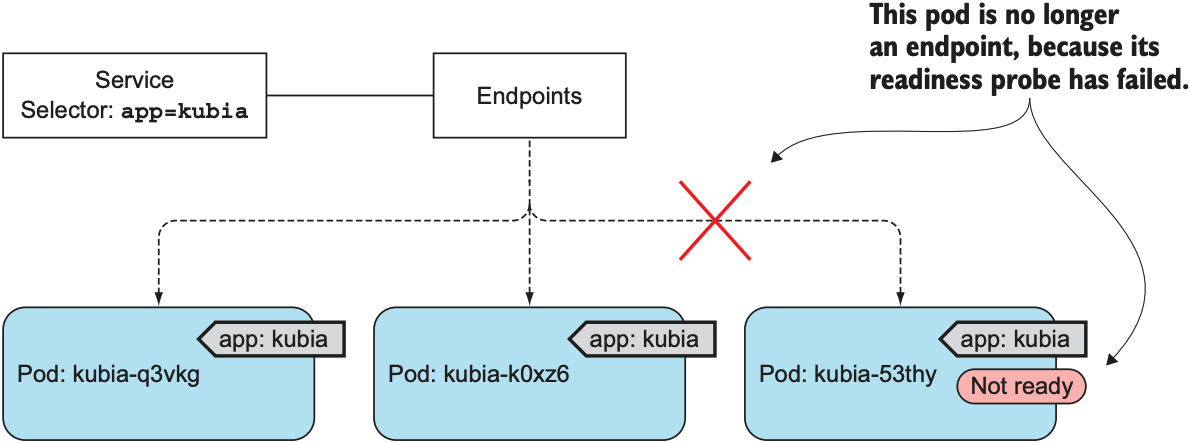
5.1 Add a Readiness Probe to a Pod
apiVersion: v1 |
上述YAML文件中为每个pod中的container指定一个readiness probe. 该readiness probe会在pod创建后周期性执行ls /var/ready. 若/var/ready不存在, ls返回非零; 反之返回零.
$ kubectl get pods |
除此之外, readiness probe和liveness probe类似, 也拥有以下属性值:
- initialDelaySeconds
- timeoutSeconds
- periodSeconds
5.2 What Readiness Probe Should Do
- 为保证client的请求总会成功, 一定要在container中添加readiness probe来判断container是否能够或想要接受请求
- 若从service中移除某个pod, 可删除pod或修改pod的label
- Readiness probe无需包含任何关于pod关闭的逻辑: 当pod被删除, service就立即将该pod移除.
6. Headless Service
Service解决了client与pod的通信问题, 但service只会随机选取一个pod与client通信, client无法连接service管理的所有pod. 为此k8s提供了headless service, 其不拥有任何IP地址, 因此查询service名时, DNS server会返回所有pod的IP地址, 而不是service的IP地址.
6.1 Create a Headless Service
创建一个clusterIP为None的Service:
apiVersion: v1 |
6.2 Discover Pods through DNS
现在可执行DNS lookup来验证service是否返回pod IP地址, 但由于service中的kubia container不提供nslookup, 因此需要创建一个额外的pod:
$ kubectl run dnsutils --image=tutum/dnsutils --generator=run-pod/v1 --command -- sleep infinity |
接下来可使用该pod验证service是否返回pod的IP地址
$ kubectl exec dnsutils nslookup kubia-headless |
上述例子中, headless service的FQDN为kubia-headless.default.svc.cluster.local, 并返回该service的两个pod的IP地址.
6.3 Discover all pods that aren't ready
若想让service展示所有管辖内的pod, 包括尚未准备就绪的pod, 可在创建service时使用alpha feature或publishNotReadyAddresses:
kind: Service |