StatefulSet
Introduction
无论是ReplicaSet或Deployment, 其只能创建和管理stateless pod, 以下是stateless pod和stateful pod的区别:
| Feature | Stateless Pod | Stateful Pod |
|---|---|---|
| State Management | 不创建或依赖任何persistent state | 每个pod都有自己的persistent state |
| Interchangeability | pod间可互相替换 | pod无法互相替换 |
| Deployment Controller | Deployment或ReplicaSet | StatefulSet |
| Storage | 所有pod共享同一PV | 每个pod拥有自己的PV |
| Scalability | 可任意水平拓展 | 无法随意水平拓展 |
| Fault Tolerance | 损失一个pod不会影响其他pod | 随时任意pod都会影响数据完整性 |
对于计算密集型事务, 由于单个node/pod无法处理所有请求, 可借助stateless pod的水平拓展能力解决计算瓶颈; 但对于数据密集型事务, 由于数据量巨大而无法将所有数据放入一个pod/node中, 需将全部数据分散到多个node/pod中, 例如:
- Database: MySQL, Oracle, PostgreSQL, Cassandra, Elasticsearch等
- Distributed File System: GlusterFS, Ceph等
- Message Broker: Kafka, RabbitMQ
- Session data store: 很多应用依赖session追踪用户
- IoT system: 负责存储手机IoT设备获取的数据
1. Replicating Stateful Pods
ReplicaSet会从一个pod template创建多个pod, 若pod template中包含一个PVC, 则所有pod都共享该PVC对应的PV: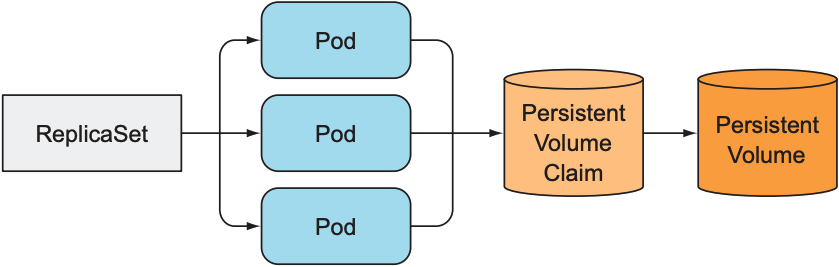
1.1 Run Multiple Replicas with Separate Storage
如果想让每个pod使用各自volume, 可采取以下方式:
- 手动创建pod: 手动创建多个pod, 并让每个pod使用不同的PVC. 由于未使用ReplicaSet, 需要手动管理pod: pod不可用时需手动删除并重新创建pod.
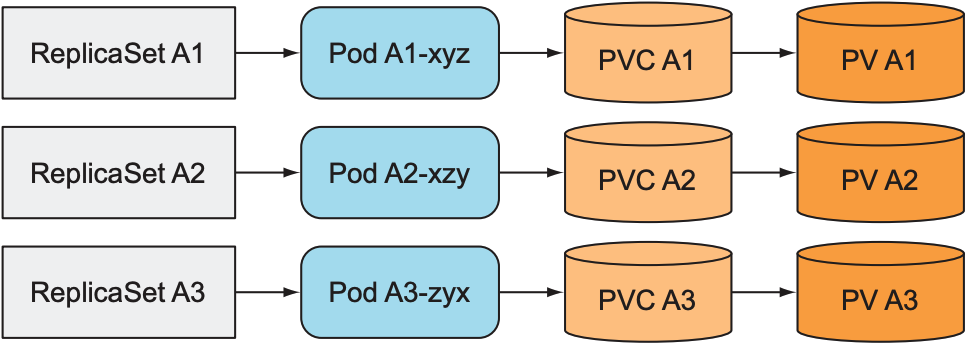
- 一个pod对应一个ReplicaSet: 创造多个ReplicaSet, 每个ReplicaSet只管理一个pod, 并使用不同PVC. 虽然ReplicaSet会自动管理pod, 但需要额外创建多个ReplicaSet; 且无法随意修改pod数量: 增加或减少pod数量时, 需手动创建或删除ReplicaSet.
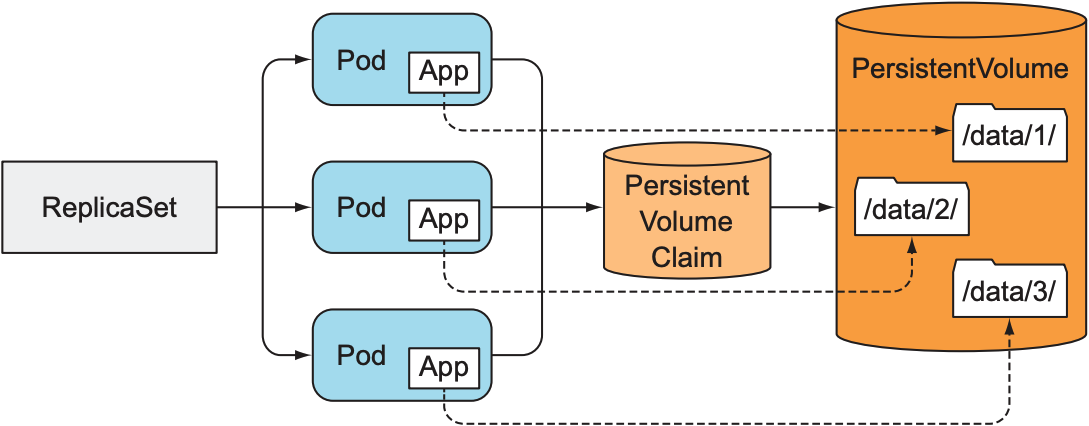
- 在同一volume中使用不同文件路径: 一个ReplicaSet管理多个pod, 但每个pod访问不同文件目录, 从而实现数据分布式. 但由于无法给每个pod指定不同的文件目录, 需要pod自己检查文件目录是否被其他pod使用, 因此需要某种pod间的合作机制:
1.2 Provide a Stable Identity for Each Pod
当pod不可用时, ReplicaSet会替换新的pod, 这就导致一个问题: 由于每个pod拥有各自数据, 其他pod无法提供不可用pod的数据, 当新的pod替换不可用pod时, 我们无法获知新pod的地址, 因此需要让每个pod都有一个稳定的网络身份(固定IP地址或域名). 这与ReplicaSet为新创建pod随机分配一个hostname或IP地址相冲突, 最容易想到的解决方案: 为每个pod创建对应的service.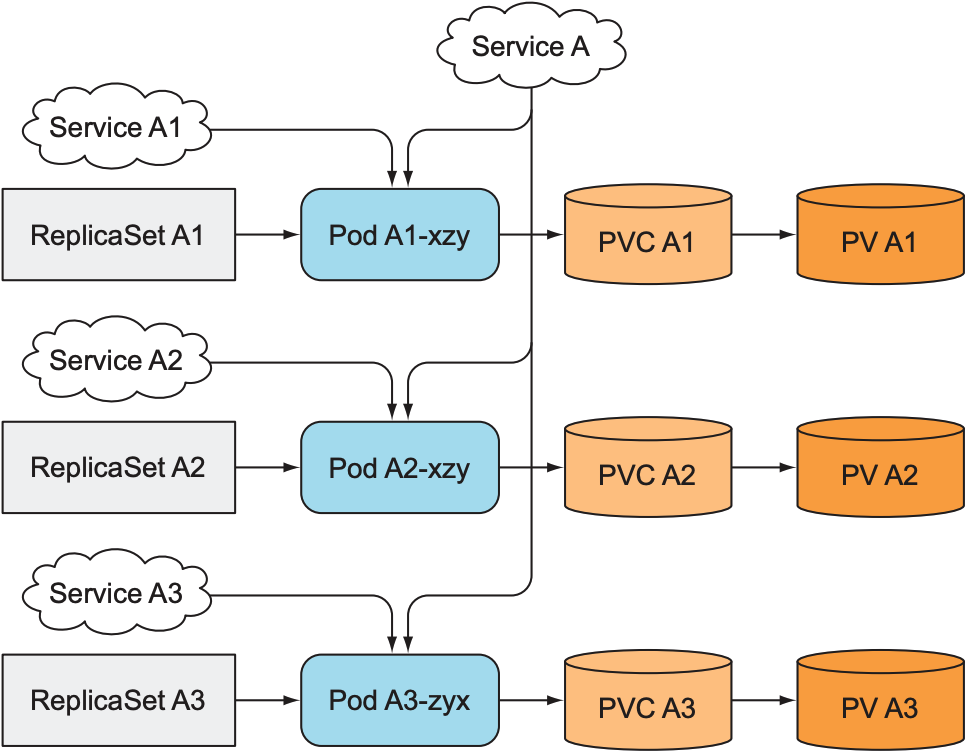
2. StatefulSet
StatefulSet作为k8s的一种资源, 提供了一种管理stateful pod的解决方案. 以下是StatefulSet和ReplicaSet/Deployment的区别:
- Goals: ReplicaSet负责管理non-stateful application; StatefulSet负责管理stateful application
- Identity: ReplicaSet为pod随机分配名字和hostname; StatefulSet按顺序为pod分配名字和hostname
- Volume: ReplicaSet中的所有pod绑定PVC对应的PV; StatefulSet中的pod拥有各自PV
2.1 Provide a Stable Network Identity
StatefulSet中所有pod名字都会以递增整数作为结尾(以0为起点), 因此pod的域名可预测; ReplicaSet则会为pod添加随机后缀: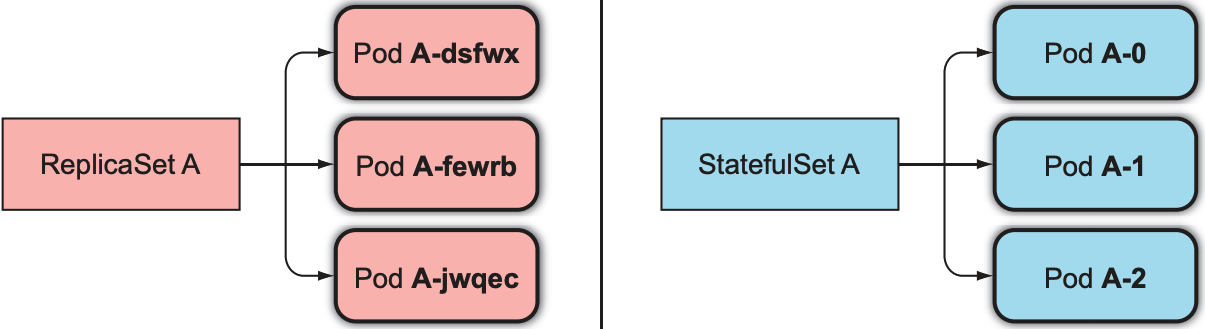
StatefulSet需要headless service, 从而让每个pod都有自己的DNS记录, 其他服务可通过DNS记录访问对应pod. 假设default namespace中的service名为foo, 第一个pod的名字为A-0, 则该pod的域名为a-0.foo.default.svc.cluster.local; 除此之外, 还可通过SRV记录访问所有pod, 其域名为foo.default.svc.cluster.local.
当pod所在的node不可用时, StatefulSet会在其他node上创建该pod, 且保证新创建的pod的名字和hostname与之前pod相同; ReplicaSet则会重新分配pod的名字和hostname: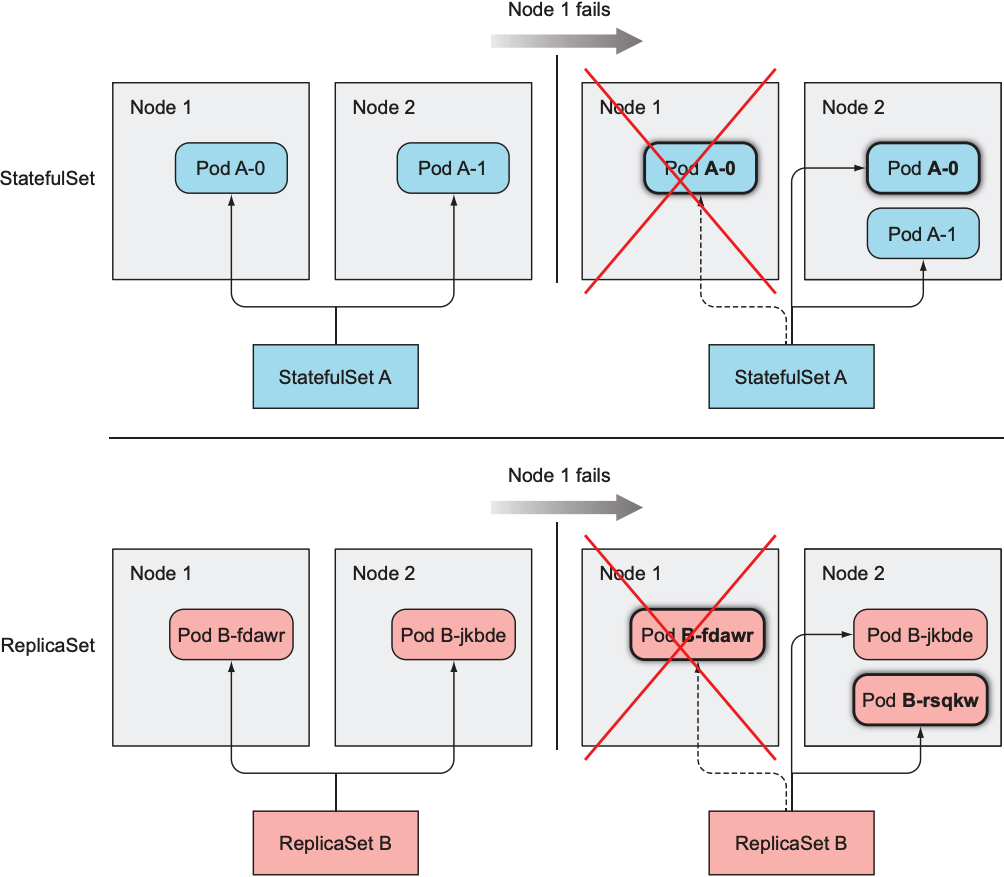
增加StatefulSet的replica count时, StatefulSet会创建一个新的pod, 其名字为下一个未使用的索引; 减小StatefulSet的replica count时, 会按照索引大小倒序移除pod, 且一次只移除一个pod: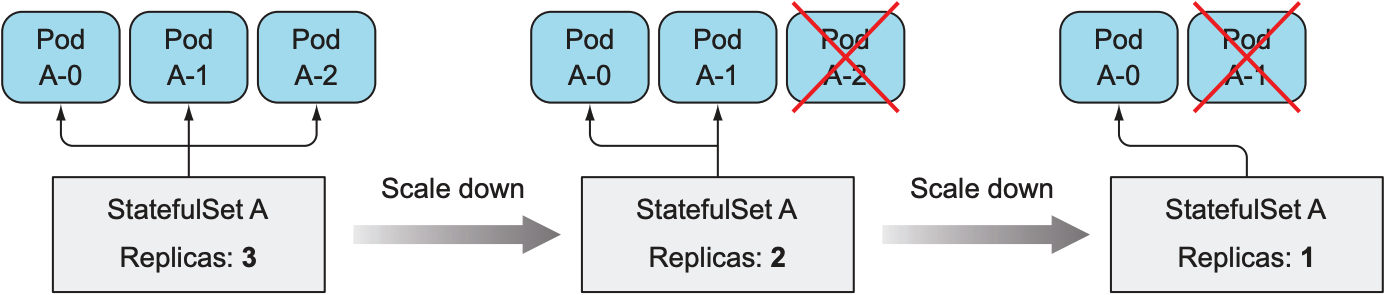
2.2 Provide Stable Dedicated Storage
当一个pod因不可用而创建新的pod时, StatefulSet需保证新创建的pod依然绑定之前pod对应的volume, 由于PVC与PV一一对应, 因此StatefulSet只需保证pod与PVC一一对应即可, PVC负责管理对应的PV: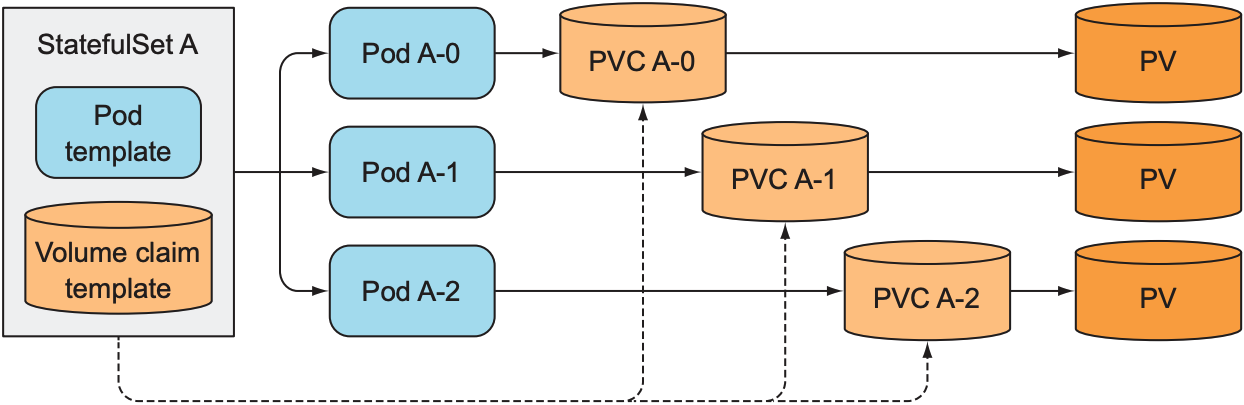
因此, 增加replica count时, StatefulSet会创建两个API对象: pod与对应的PVC; 减小replica count时, StatefulSet只会移除pod, 不会删除对应的PVC, 因为一旦删除PVC, 其对应的PV也会被回收, 为了防止数据丢失需保留PVC; 也可手动删除PVC来回收PV; 当replica count恢复到之前数量时, 新创建的pod会绑定原有PVC: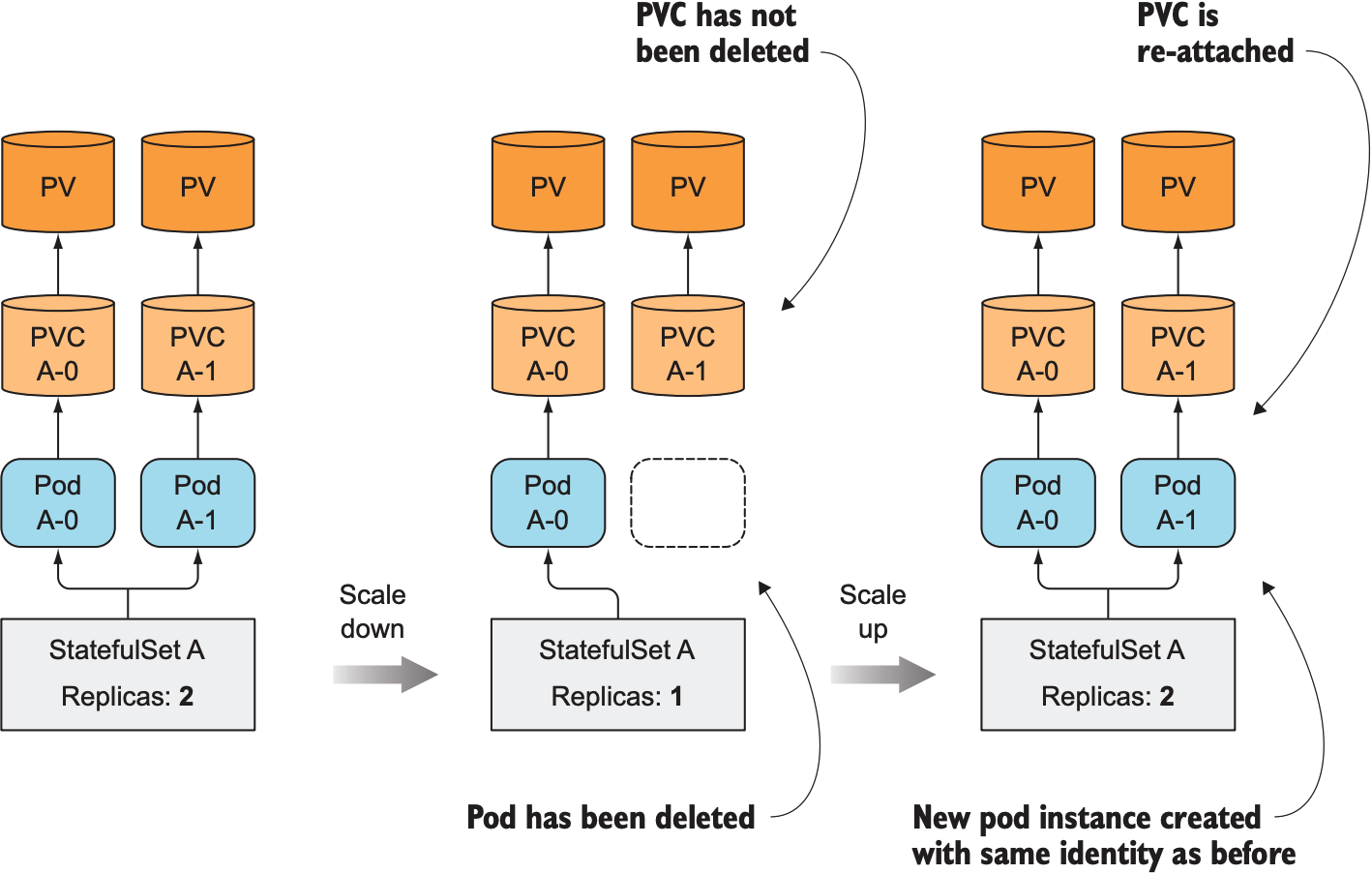
2.3 StatefulSet's At-Most-One Semantics
由于StatefulSet支持新建pod复用不可用pod的identity(pod名字, hostname和PVC), 需保证只有pod不可用时才创建新的pod, 为此StatefulSet使用at-most-one语义来确保同一时间最多只有一个pod使用使用该身份, StatefulSet会尽最大努力确认pod是否不可用.
3. Use a StatefulSet
3.1 Create the App and Container image
为了更好地展示StatefulSet, 需创建一个应用, 其可写入和读取volume中的数据, 并可以与其他服务通信:
... |
上述Node.js程序监听8080端口: 收到POST请求时将请求数据写入/var/data/kubia.txt; 收到GET请求时从该文件中读取数据并回复.
3.2 Deploy the App through a StatefulSet
部署应用时需创建三种资源:
- PV: 负责存储数据(k8s cluster不支持动态创建PV时需手动创建PV)
- Service: 负责网路通信
- StatefulSet
StatefulSet会自动创建PersistentVolumeClaim, 所以并不需手动创建PVC.
3.2.1 Create the Persistent Volume
使用Google Kunernetets Engine时, 需先创建三个GCE Persistent Disk:
$ gcloud compute disks create --size=1GiB --zone=us-east1-b pv-a |
以下是使用GCE persistent disk的PV, 一共有三个PV(pv-a, pv-b和pv-c), 每个PV有1Mb空间.
kind: List |
3.2.2 Creating the Governing Service
clusterIP: None表示这是一个headless service, 负责为stateful的每个pod提供网络身份.
apiVersion: v1 |
3.2.3 Creating the StatefulSet Manifest
volumeClaimTemplates指定StatefulSet创建何种规格的PVC.
apiVersion: apps/v1beta1 |
可以发现, 除了volumeClaimTemplates外, StatefulSet的配置与ReplicaSet基本相同. 上述StatefulSet包含2个pod, 每个pod包含app: kubia的label, pod会将/var/data路径挂载到名为data的volume上. volumeClaimTemplates则定义了一个PVC的模板, 会为每个pod生成对应的PVC.
3.2.4 Create the StatefulSet
$ kubectl create -f kubia-statefulset.yaml |
创建StatefulSet立刻查看pod:
$ kubectl get po |
不同于ReplicaSet, StatefulSet不会立即创建所有pod, 而是先创建第一个pod, 直到该pod处于运行状态时才创建下一个pod:
$ kubectl get po |
3.2.5 Examine the Generated Stateful Pod
$ kubectl get po kubia-0 -o yaml |
可以看到, StatefulSet会为名为kubia-0的pod创造一个名为data-kubia-0的PVC, 也就是volumeClaimTemplates的名字加上pod的名字, 并其挂载到container的/var/data路径上:
$ kubectl get pvc |
3.3 Communicate with Your Pods
假设外部服务想要访问名为kubia-0的pod, 可将API server作为中间代理, 则访问路径如下:
<apiServerHost>:<port>/api/v1/namespaces/default/pods/kubia-0/proxy/<path> |
为避免配置SSL certificate, 可使用kubectl proxy简化与API server的通信:
$ kubectl proxy |
整个GET请求的流程如下: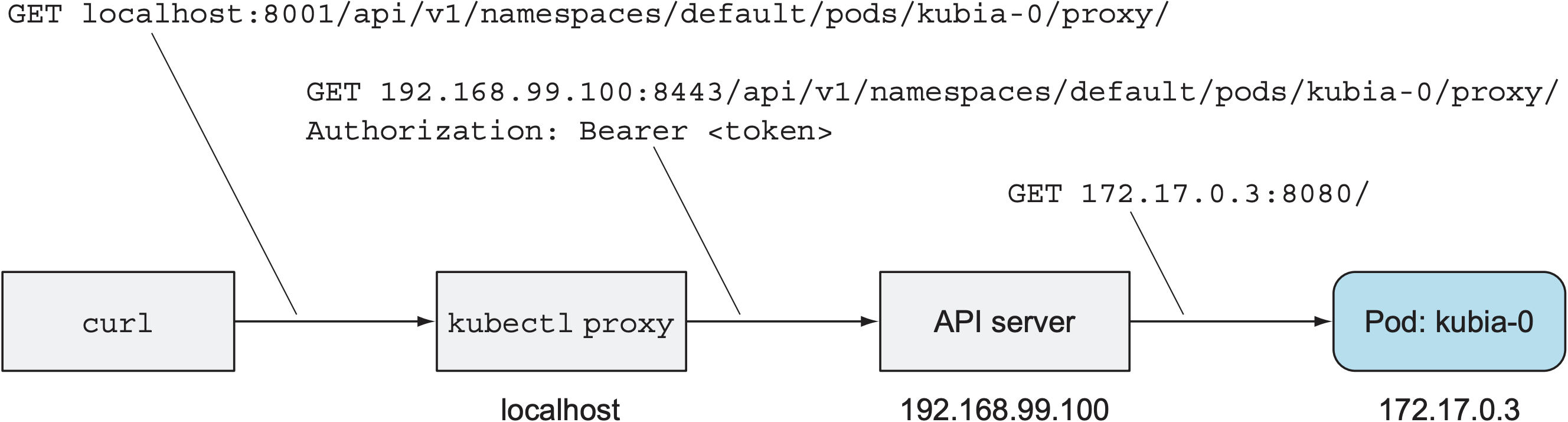
也可通过API server向pod发送POST请求:
$ curl -X POST -d "Hey there!" localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/ |
删除pod后, StatefulSet会像ReplicaSet一样创建新的pod, 新创建的pod会使用被删除pod的名字, hostname和volume: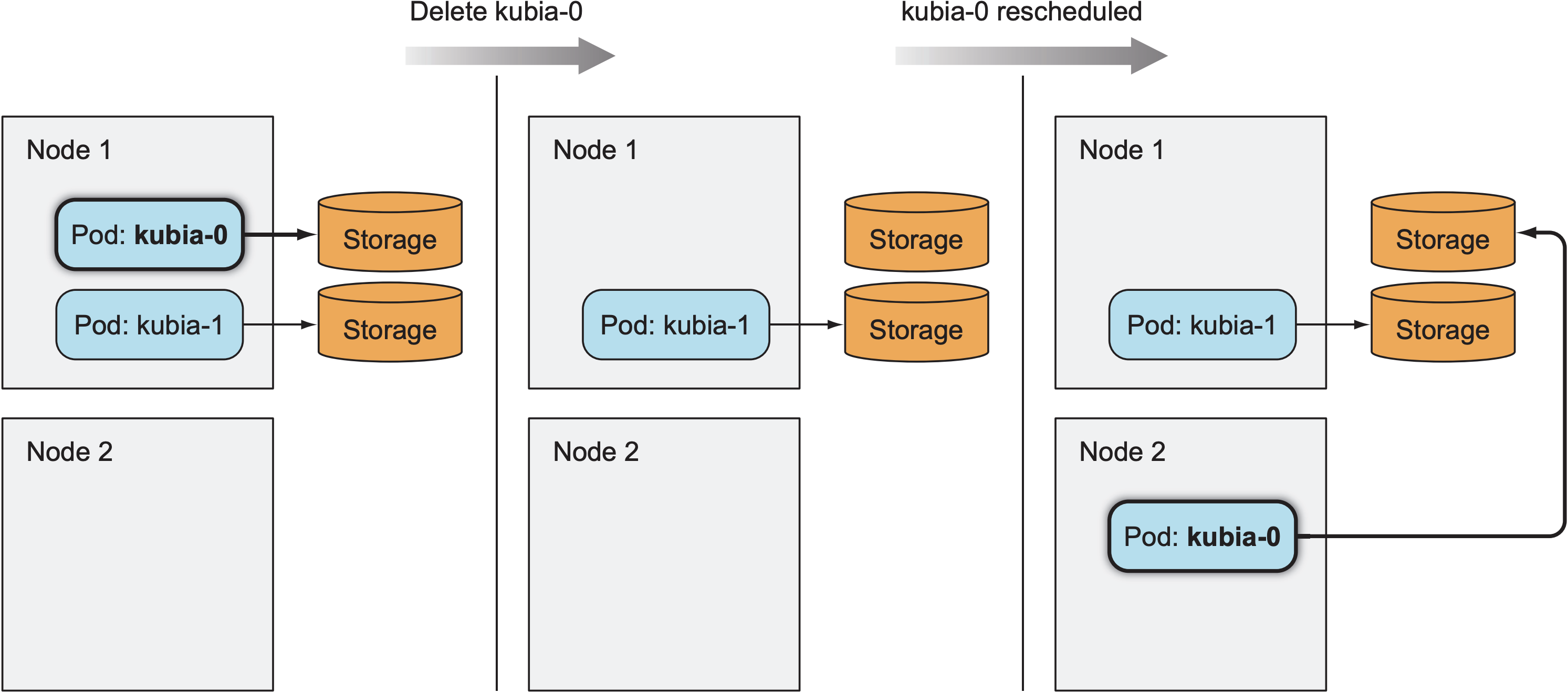
减小replica count时, StatefulSet按照序号从大到小关闭pod, 同一时间只会有一个pod处于terminating状态.
4. Discovering peers in a StatefulSet
虽然外部服务可通过API server与pod沟通, 但我们需要一种不依赖于k8s的方式与pod直接通信: SRV record. SRV记录用于表示一组拥有相同服务的服务器的hostname和port. 为获取StatefulSet的SRV记录, 可执行dig命令(在临时运行的pod中):
$ kubectl run -it srvlookup --image=tutum/dnsutils --rm --restart=Never -- dig SRV kubia.default.svc.cluster.local |
ANSWER SECTION中有两条SRV记录, 分别表示kubia-0和kubia-1. 若想在运行时获取所有SRV记录, 可在程序中执行SRV DNS lookup获取StatefulSet的所有SRV记录:
dns.resolveSrv("kubia.default.svc.cluster.local", callBackFunction); // service name |
需要注意的是, SRV记录没有前后顺序, 因此SRV记录的显示顺序不表示pod的创建顺序.
4.1 Implement peer discovery through DNS
由于StatefulSet中的pod各自拥有不同的数据, 当外部服务想要获取StatefulSet的所有数据时, 需要外部服务查找SRV记录, 并逐个获取每个pod的数据; 为方便获取全部数据, 可让pod接收外部服务的请求时从其他pod中收集数据, 并将全部数据回复给外部服务.
... |
经过上述修改后, 外部服务可向StatefulSet的任意一个pod发送GET请求, 收到请求的pod会通过SRV DNS lookup获取StatefulSet中所有pod的hostname, 并向所有hostname的/data路径发送GET请求获取数据, 最后组合数据并返回给外部服务, 整个流程如下: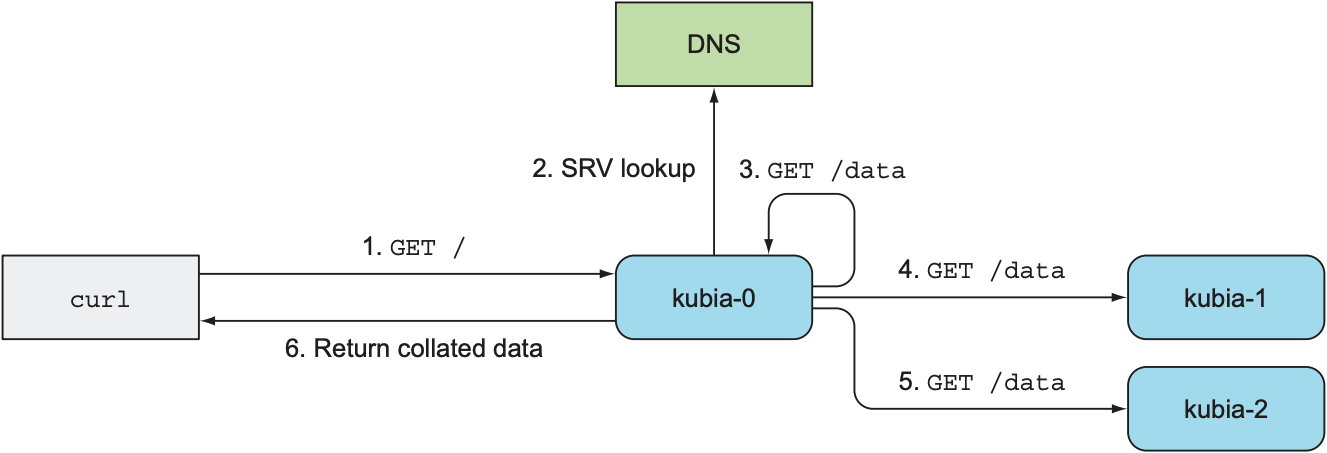
4.2 Update a StatefulSet
更新StatefulSet时, 可使用kubectl edit命令修改StatefulSet的YAML文件. 需要注意的是, 修改StatefulSet的YAML文件后, StatefulSet不会替换已有的pod, 只有新创建的pod使用新的manifest. 若需替换旧的pod, 则需删除已有pod:
$ kubectl edit statefulset kubia |
例如, 将spec.relicas从2改为3, 并将spec.template.spec.containers.image从luksa/kubiapet改为luksa/kubia-pet-peers:
$ kubectl get pods |
kubia-0和kubia-1没有任何更新, kubia-2则使用新的image.
5. Understand How StatefulSets Deal with Node Failures
由于每个pod都是唯一的, StatefulSet需保证同一时间不能存在两个相同的pod同时运行, 只有确认pod没有在运行时才会创建新的pod.
5.1 Simulate a Node's Disconnection From the Network
假设k8s clsuter中一个StatefulSet管理3个pod, 分别名为kubia-0, kubia-1和kubia-2, 分别运行在不同的worker node上. 为测试node不可用时StatefulSet的应对策略, 需先断开其中一个worker node的网络接口:
$ gcloud compute ssh gke-kubia-m0g1 |
断开连接后, node上的kubelet无法与k8s API server通信, 因此k8s API server无法得知node和其pod的状态:
$ kubectl get node |
Control plane将该node的状态标记为NotReady, 并将pod状态标记为Unknown. 可以发现, StatefulSet并没有创建新的pod来替换该pod, 因为StatefulSet无法确定该pod的状态.
若node重新上线, 该pod会回到Running状态; 但若pod的Unknown状态超过一定时间, control plane会试图将该pod移除, 并将pod状态改为Terminating; 但由于node断开连接, kubelet无法回应master的删除请求, 所以pod会一直处于Terminating状态.
$ kubectl describe po kubia-0 |
以下三种情况会让k8s会从API server上删除该pod的信息:
- 删除worker node
- worker node重新连接, kubelet响应删除请求
- 强制删除Pod
5.2 Delete the Pod Forcibly
$ kubectl delete po kubia-0 |
删除pod操作并不会真正移除pod, 这是因为control plane只会在kubelet确认删除请求后才会移除该pod, 由于node断开连接, kubelet也就无法回应API server的删除请求.
强制删除则不会等待kubelet的确认: 无论pod是否被终止, API server都会删除该pod的信息, StatefulSet也会创建新的pod来替代被删除的pod:
$ kubectl delete pod kubia-0 --grace-period=0 --force |
强制删除可能违背StatefulSet的at-most-one原则, 因此执行强制删除前需保证node不可用; 若node重新上线, 两个相同pod可能会导致数据丢失.