Deployment
1. Update Applications Running in Pods
我们已经讨论了很多关于k8s的资源, 每种资源都有其功能:
- pod: 运行应用程序的最小单元
- service: 负责pod之间的沟通
- volume: 负责pod的数据存储
- configMap/secret: 负责pod的密钥和配置信息管理
- ReplicaSet: 负责管理一组同类型的pod
但始终没有涉及一个问题: 如何更新pod. 当开发者发布一个新的container image时, 需要让该image替换现有k8s cluster上的container. 假设cluster中有一个ReplicationController或ReplicaSet管理多个pod, 一个service负责为pod提供通信接口, 我们需要将所有pod从v1版本提升到v2版本.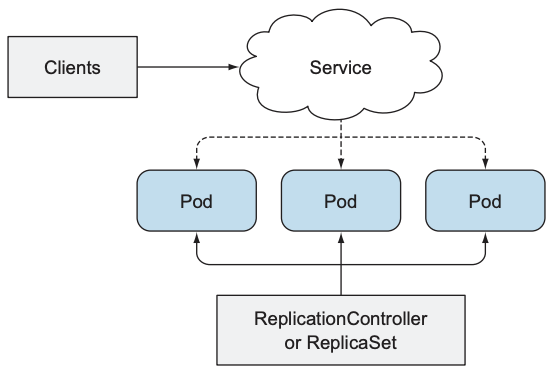
更新pod有以下方法:
- 先删除所有v1版本的pod, 再部署v2版本的pod
- 先部署v2版本的pod, 再删除v1版本的pod:
- 一次部署: 先启动所有v2版本的pod, 再删除所有v1版本的pod
- 交替部署: 先启动一个v2版本的pod, 再删除一个v1版本的pod, 如此往复直至所有pod从v1升级为v2
上述所有方法都有其优点和缺陷:
- 先删除所有旧版本pod, 再部署新版本pod:
- 优点: 操作简单; 不会占用过多计算资源
- 缺点: 会出现服务空档期(以v1版本pod被关闭为起点, 以v2版本pod上线为终点)
- 先部署新版本pod, 再部署旧版本pod:
- 一次部署:
- 优点: 操作简单; 不会出现服务空档期
- 缺点: 由于cluster需要同时运行两个版本的所有pod, 因此需要额外的计算资源
- 交替部署:
- 优点: 不会出现服务空档期; 不会占用过多计算资源
- 缺点: 操作复杂, 需要一步步手动操作
- 一次部署:
1.1 Delete Old Pods and Replace with New Ones
假设cluster中有一个Replication负责管理三个v1版本的pod, 现在需将pod提升到v2版本. 可直接替换ReplicationController的manifest文件(修改container.template为v2, 不修改label selector), 然后手动删除所有v1版本的pod, ReplicationController检测到pod数量不满足replica count后会启动v2版本的pod. 流程如下: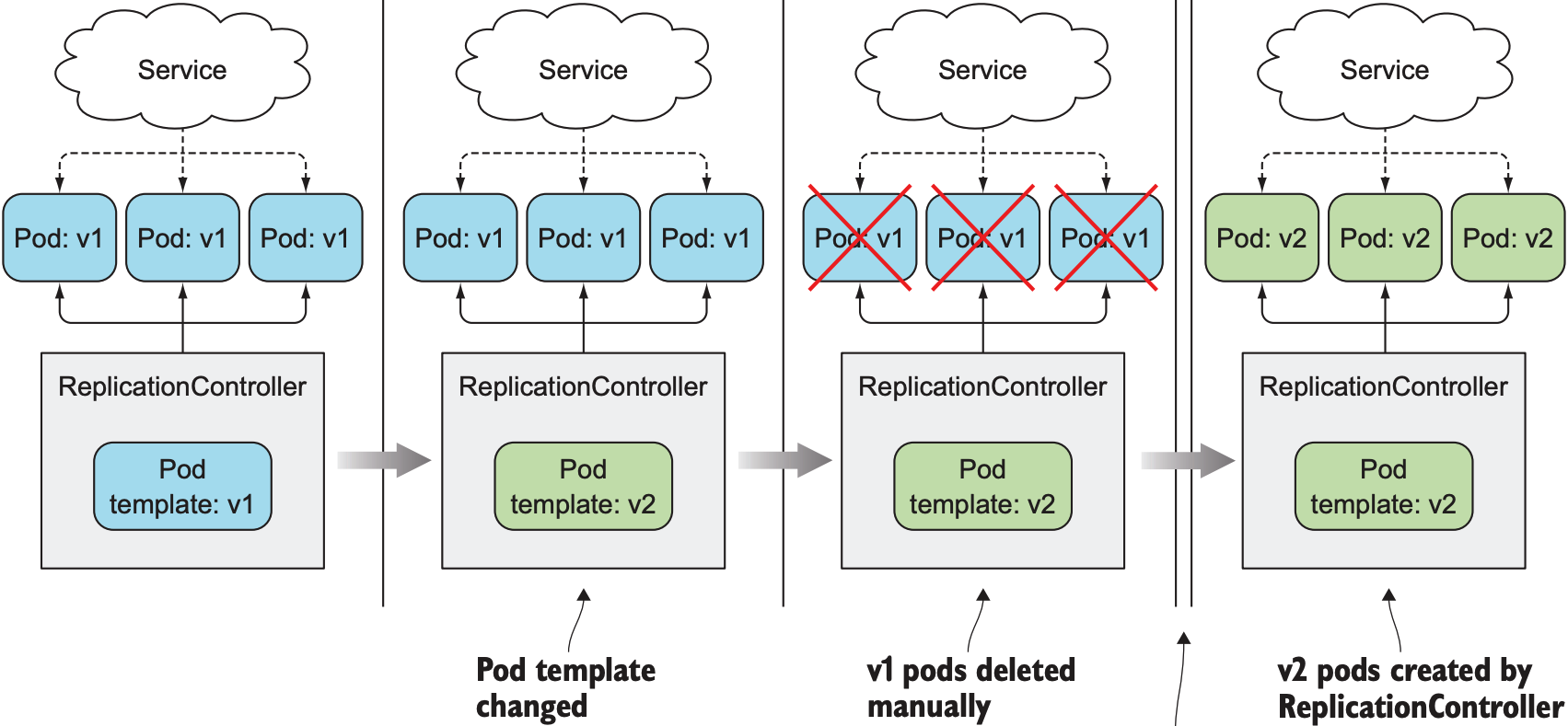
1.2 Spin up New Pods and Delete the Old Ones
若不想出现任何服务空档期, 则需要支持clsuter中存在不同版本的pod, 也就是说, 在生成v2版本pod的同时保留v1版本pod, 分为以下两种方案:
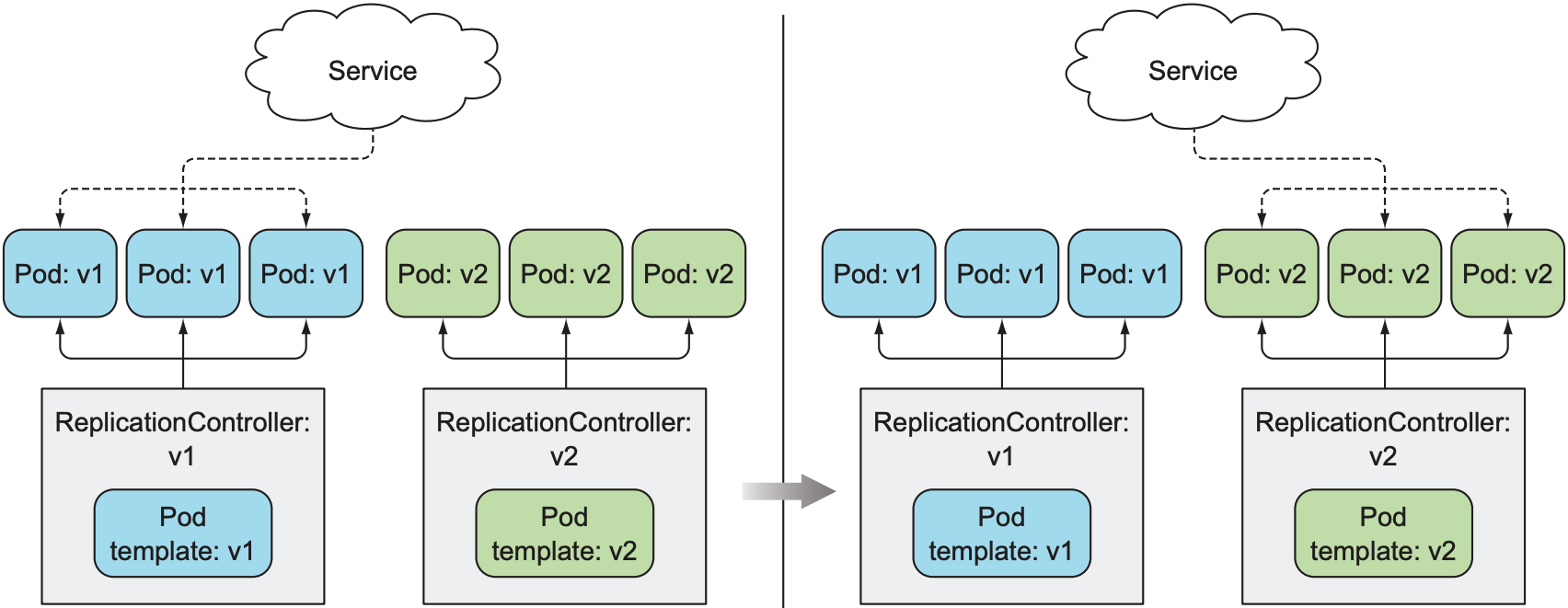
- Blue-green Deployment: 通常同类型的pod会共享一个service, 这时我们再加入版本维度: 同类型且同版本的pod共享一个service. 例如, 先创建新版本(v2版本的container image和新的label selector)的ReplicationController, 其中包含所有v2版本的pod, 再将service重定向到新的ReplicationController, 最后删除旧版本(管理v1版本的pod)的ReplicationController. 流程如下:
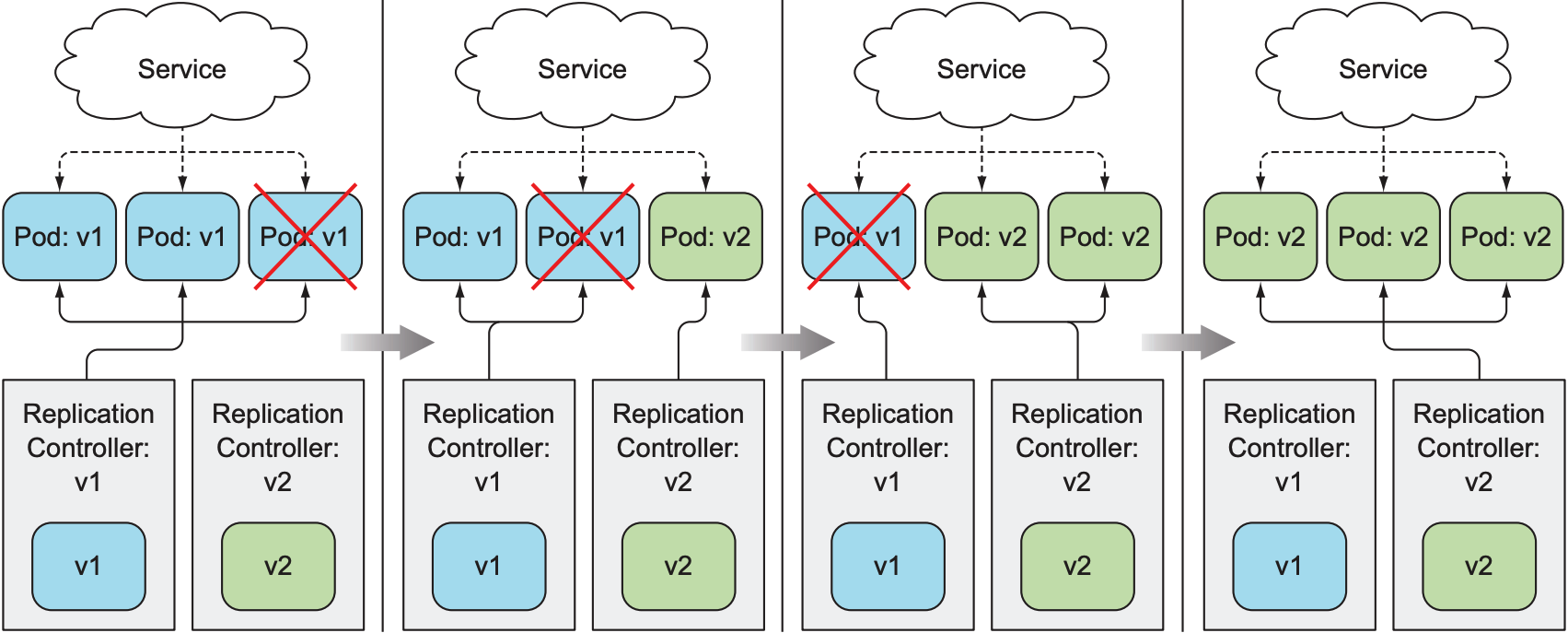
- Rolling Update: blue-green deployment虽然简单有效且避免服务空档期, 但更新时会导致pod数量翻倍, 从而增加硬件需求; 为避免计算资源不足, 可以边生成v2版本的pod, 边删除v1版本的pod; 缺点在于操作繁琐, 极易产生错误. 流程如下:
2. Perform an Automatic Rolling Update with a ReplicationController
kubectl提供了rolling-update指令, 相比于手动更新ReplicationController中的pod, 该指令可自动执行所有操作.
2.1 Preparation
我们以一个网络应用服务为例: 假设container中运行名为kubia的NodeJS程序, 其监听8080端口, 接收到HTTP请求后回复"This is v1 running in pod", v2版本的kubia接收到HTTP请求后回复"This is v2 running in pod". 以下是管理v1版本pod的ReplicationController和service:
apiVersion: v1 |
一个YAML文件中可定义多个资源, 用三个破折号(dash)隔开.
$ while true; do curl http://130.211.109.222; done |
需要注意的是, 本例中将不同版本的程序放入不同tag(luksa/kubia:v1和luksa/kubia:v2)的image中. 若更新代码时不更新tag, 会出现以下问题:
- 若
container.image的tag为latest, 则新产生的pod会尝试获取最新的image - 若
container.image的tag为某个版本号, 一旦pod中已有该版本号的image, 则不会尝试获取该版本的image
若想要每个新的pod都使用最新的image, 可采用以下方法:
- 将
container.image的tag设置为latest - 将
imagePullPolicy设置为Always - 每次更新程序后分配不同tag, 并更新image的tag
2.2 Perform a Rolling Update with kubectl
调用kubectl rolling-update可实现自动滚动更新Pod:
$ kubectl rolling-update kubia-v1 kubia-v2 --image=luksa/kubia:v2 |
该命令会保留名为kubia-v1的ReplicationController, 并创建名为kubia-2的ReplicationController, 新创建的ReplicationController使用luksa/kubia:v2作为pod的image. 为避免kubia-v2包含kubia-v1的pod, kubectl会为两个ReplicationController添加名为deployment的selector, 也会为所有kubia-v1和kubia-v2管理的pod添加对应的label. 以下是刚调用命令时的情况: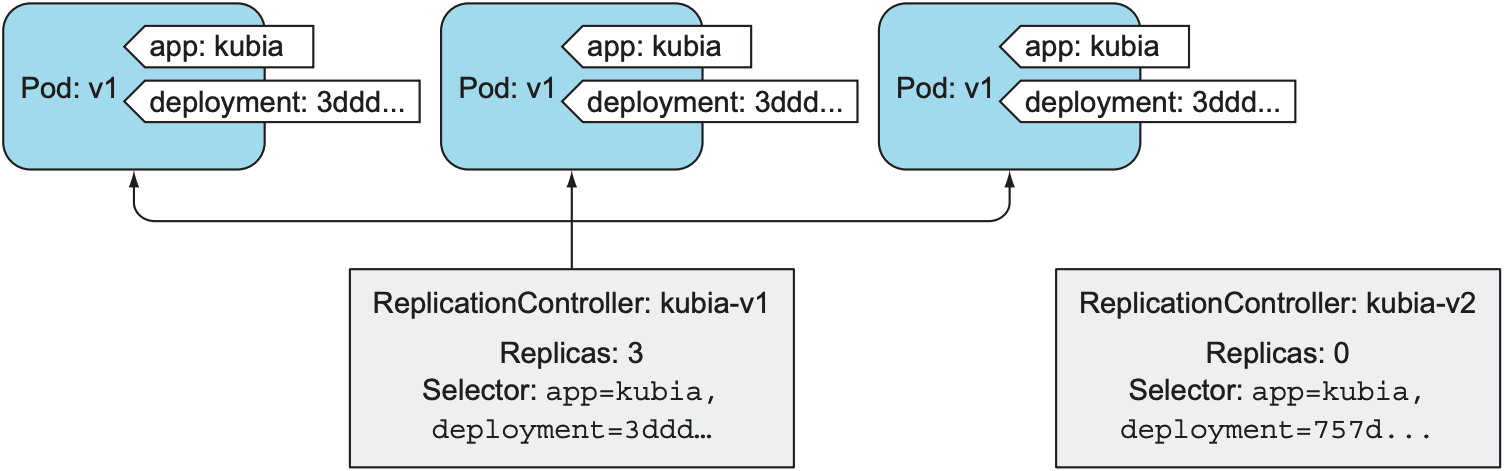
为了防止创建过多pod导致计算资源不足, 开始时kubia-v2的replica count为0, 因此不会创建任何v2版本的pod. 之后kubectl会逐步增加kubia-v2的replica count, 并减小kubia-v1的replica count, 直到v2版本的pod完全替代v1版本的pod: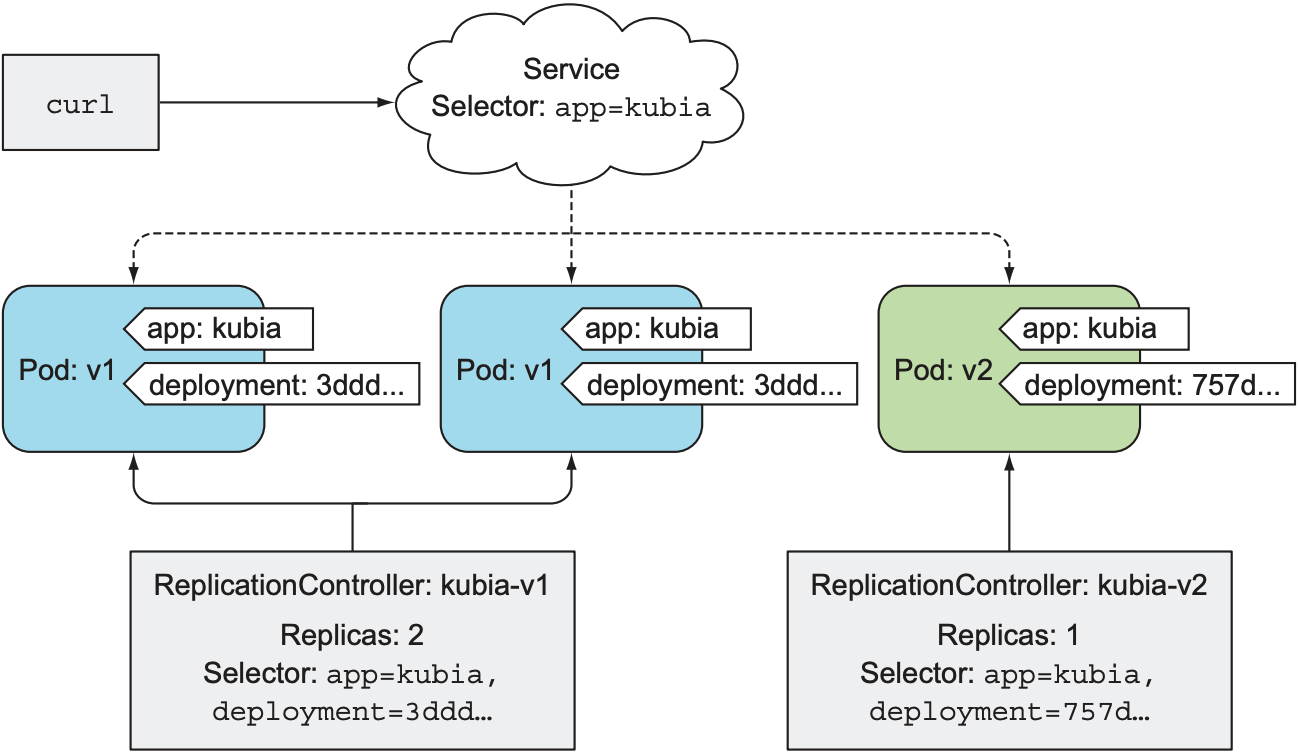
最终kubia-v2的replica count会增加到3, 而kubia-v1的replica count会减少到0. 尽管这种方法可以减少手动操作ReplicationController而导致的问题, 但该方式存在以下缺点:
- 该方法会向pod和ReplicationController添加不必要的label和selector
- 由于整个过程由kubectl操作, 而kubectl只是一个命令行程序, 其可以在k8s cluster中运行, 也可以在管理员的电脑中运行, 其通过向API server发送请求实现一系列操作, 一旦kubectl与master连接中断, 则更新中断且不会自动回滚
3. Use Deployment for Updating Apps
Deployment是k8s中一种更高维度的资源. Deployment并不直接管理pod, 而是通过ReplicaSet管理pod, 从而避免用户手动操作ReplicaSet.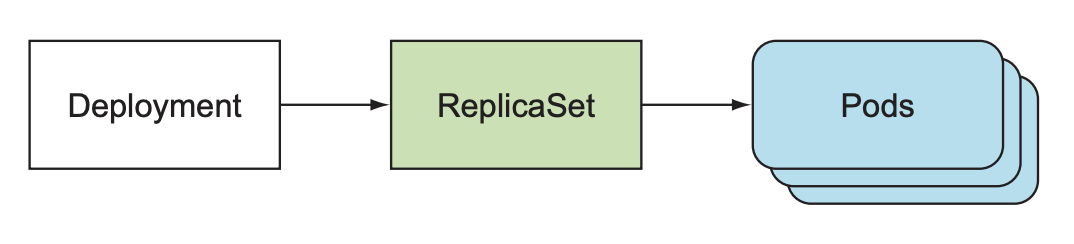
3.1 Create a Deployment
之所以在ReplicationSet基础上引入一个新的资源, 是因为ReplicaSet无法满足很多需求, 如更新pod. Deployment作为k8s的一种资源, 会由k8s control plane直接管理, 从而更符合k8s的终态思想(用户声明期望状态, k8s不断检查并执行相应操作, 最终达成期望状态). 以下是deployment的manifest:
apiVersion: apps/v1beta1 |
Deployment与ReplicationController的manifest基本相同, 但deployment不需要在name中设置版本号, 因为deployment并不属于某个版本号. 以下是Deployment的Service:
apiVersion: v1 |
调用kubectl create即可创建Deployment, --record会记录该deployment的每一次更新, 用于回滚操作:
$ kubectl create -f kubia-deployment-v1.yaml --record |
调用kubectl rollout status可查看deployment的rollout状态:
$ kubectl rollout status deployment kubia |
Deployment会自动创建pod:
$ kubectl get po |
可以发现, Deployment管理的pod的名字带有一串随机字符, 其由ReplicaSet创建, 因此Deployment并不直接管理pod, 而是通过创建ReplicaSet来管理pod:
$ kubectl get replicasets |
3.2 Update a Deployment
使用ReplicaController更新pod的image时, 需使用kubectl rolling-update指定当前ReplicationController的名字, 新的ReplicationController的名字, 和pod的image. 相比之下, 更新deployment只需更新deployment中的pod template. Deployment支持两种更新策略:
- RollingUpdate(默认): 边创建新版本pod, 边删除旧版本pod
- Recreate: 先删除所有旧版本pod, 再创建新版本pod
调用kubectl set image可替换deployment中的pod image:
$ kubectl set image deployment kubia nodejs=luksa/kubia:v2 |
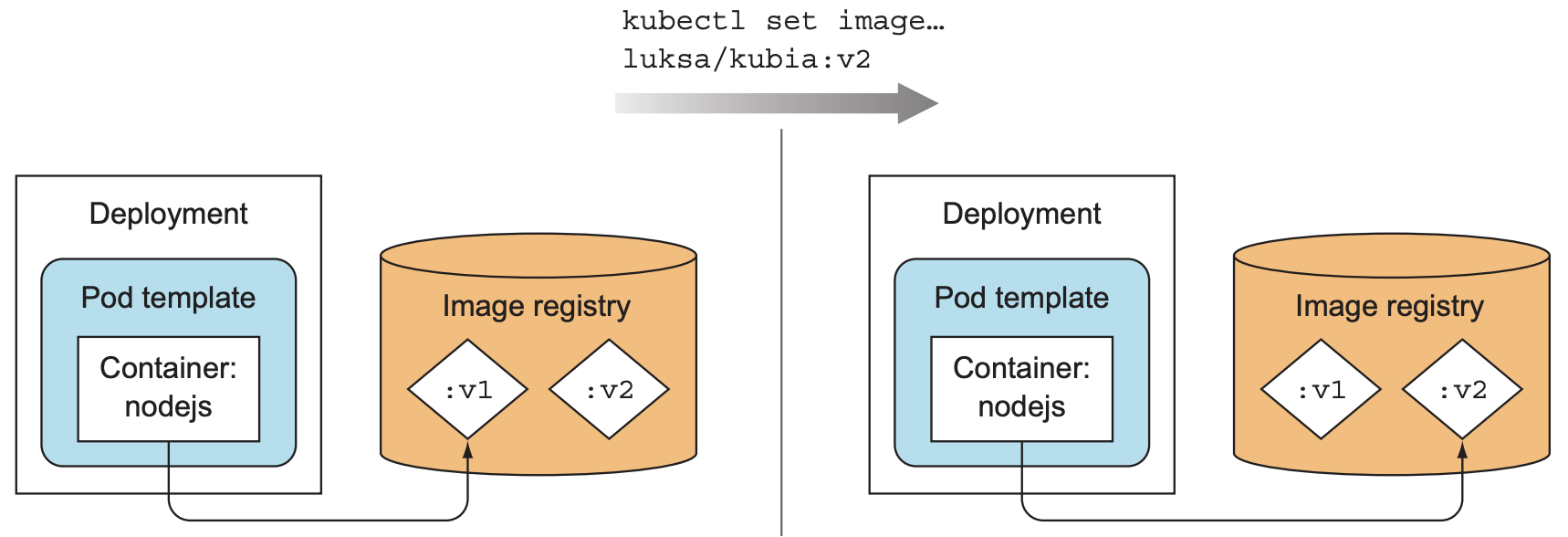
Deployment不会删除旧版本ReplicaSet, 保留其用于回滚:
$ kubectl get rs |
以下是修改Deployment的几种方式:
- kubectl edit: 使用editor打开Deployment manifest, 修改后保存并推出editor
- kubectl patch: 修改Deployment中的一个或多个属性
- kubectl apply: 使用JSON或YAML文件替换或创建Deployment. 若存在同名Deployment, 则替换; 否则创建新的Deployment
- kubectl replace: 使用JSON或YAML文件替换Deployment. 若不存在同名Deployment, 则报错
- kubectl set image: 修改Deployment中的container image
相比于kubectl rolling-update, 更新deployment由k8s control plane操作. 虽然更新pod的过程相似, 但deployment提供了一种保障: k8s会不断尝试将所有pod从v1升级到v2, 直到所有deployment管理的pod都升级为v2.
需要注意的是, 更新pod指向的ConfigMap并不会触发pod更新; 若需要更新pod的ConfigMap, 可创建一个新的ConfigMap, 并让pod指向新的ConfigMap.
3.3 Rolling back a Deployment
首先我们需要创建一个需要回滚的情景: 假设v3版本pod回复前5个HTTP请求状态码200, 第6个HTTP请求开始返回状态码500. 调用kubectl set image更新Deployment来部署v3版本pod:
$ kubectl set image deployment kubia nodejs=luksa/kubia:v3 |
调用kubectl rollout undo可回滚至上一个版本:
$ kubectl rollout undo deployment kubia |
即使deployment处于更新之中, 也可以回滚更新. 之所以deployment能实现回滚, 是因为deployment保留每个版本的ReplicaSet, 调用kubectl rollout history可查看所有更新历史:
$ kubectl rollout history deployment kubia |
若创建deployment时不添加--record选项, 则CHANGE-CAUSE为空. 除了回滚到之前版本, 还可通过--to-revision选项指定回滚版本:
$ kubectl rollout undo deployment kubia --to-revision=1 |
以下是Deployment中ReplicaSet的保存记录: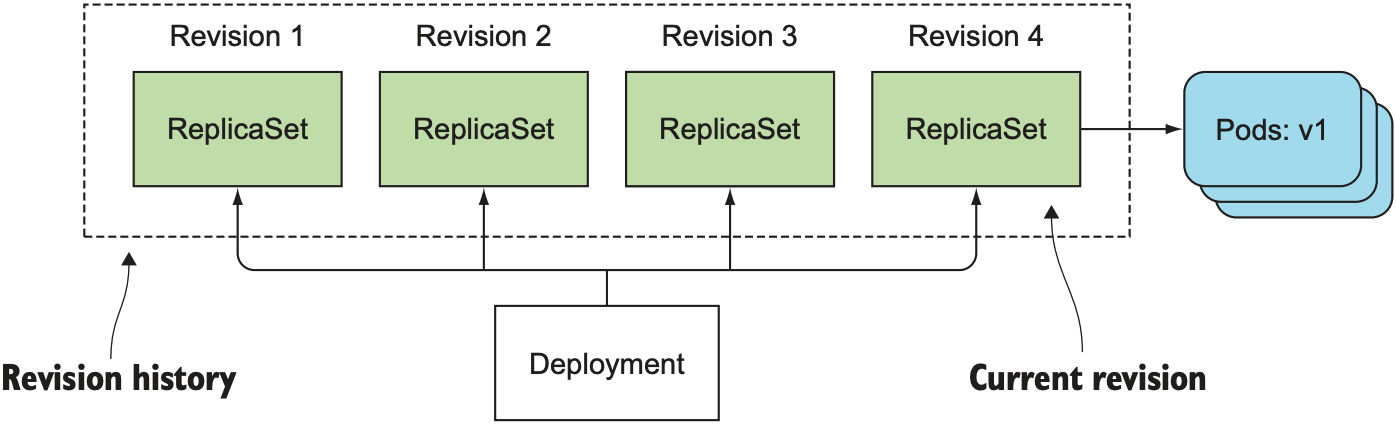
为防止revision history过长而导致大量旧版replicaSet占用资源, 可设置Deployment的revisionHistoryLimit属性来限制保留的ReplicaSet数量, 默认为10.
3.4 Controlling the Rate of the Rollout
Deployment提供了两个属性来控制更新时的资源占用情况:
- maxSurge: 超出desired replica count的pod数量或比例, 默认为25%
- maxUnavailable: 更新期间相对于desired replica count, 允许多少pod不可用, 默认为25%
上述两个属性可定义在strategy.rollingUpdate属性中:
... |
假设Deployment的replica count为3, maxSurge为1, maxUnavailable为0, 更新过程如下: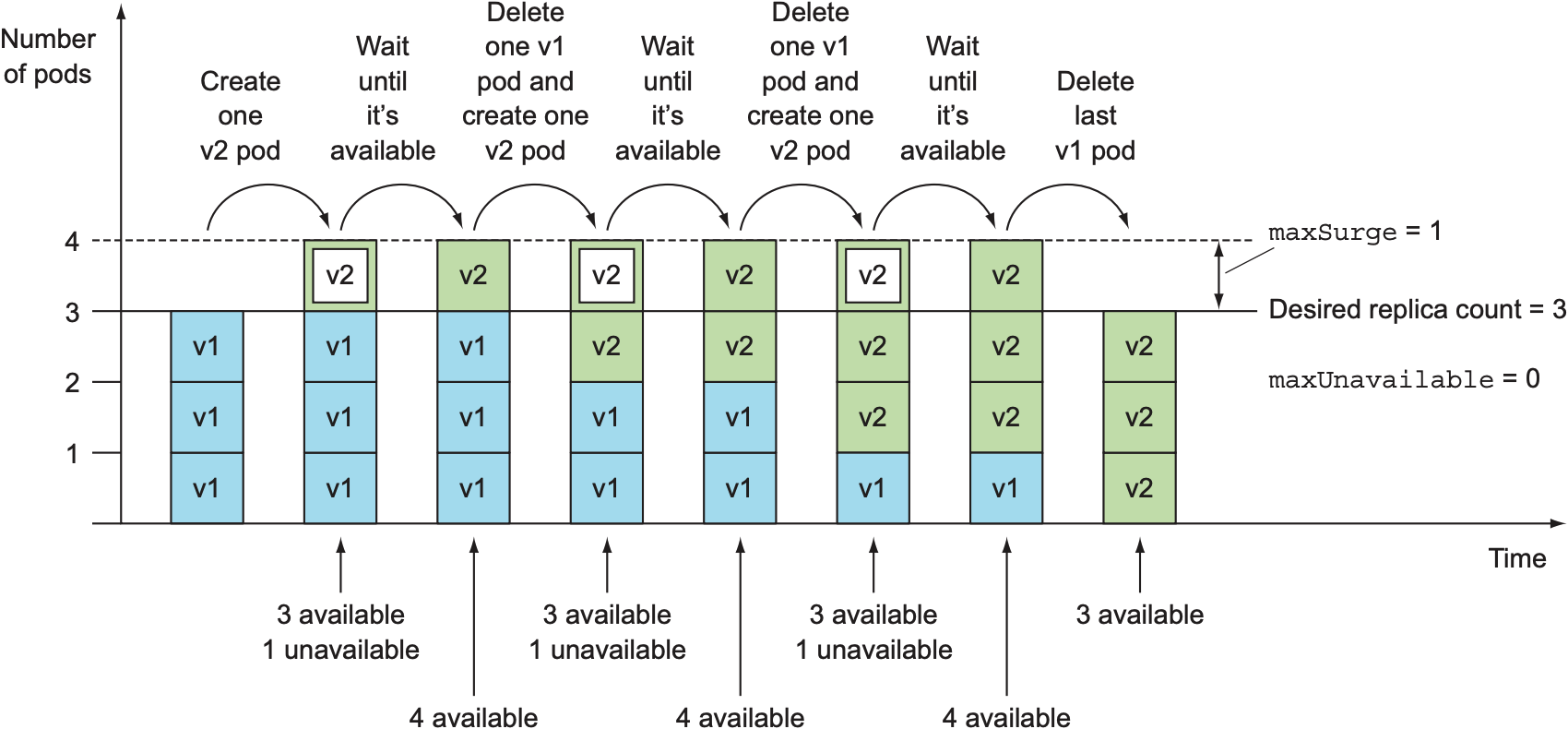
假设Deployment的replica count为3, maxSurge为1, maxUnavailable为1, 更新过程如下: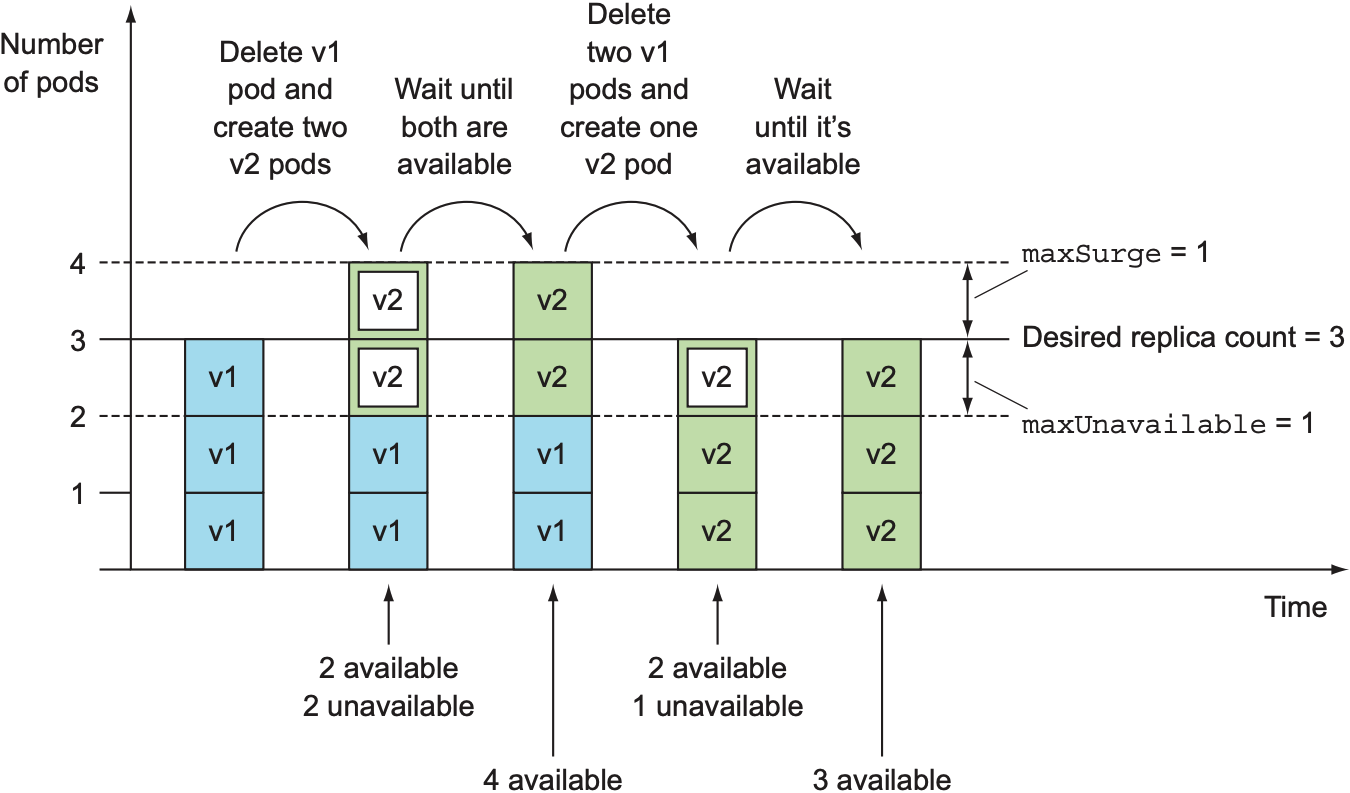
可以发现, maxSurge和maxUnavailable设置的数值越大, 整个更新过程越快, 但计算资源/可用pod数量越少. 因此配置时需考虑一下几点:
- deployment的更新时间长短
- maxSurge: 空闲计算资源用于分配超过replica count的pod
- maxUnavailable: 可用pod用于处理用户请求
3.5 Pause the Rollout Process
调用kubectl rollout pause可暂停deployment的更新:
$ kubectl set image deployment kubia nodejs=luksa/kubia:v4 |
调用kubectl rollout resume可恢复更新进程:
$ kubectl rollout resume deployment kubia |
注意: 若deployment被暂停, 则无法回滚该deployment; 必须恢复运行后才可以回滚.
3.6 Block Rollouts of Bad Versions
Deployment还提供minReadySeconds属性来防止有缺陷的pod部署到cluster中. 介绍该属性之前需要先了解pod的ready和available状态:
- ready: 表示pod的container准备就绪, 通常readiness probe决定pod是否可以切换为ready状态
- available: 表示pod可以接收外部请求
minReadySeconds表示pod从ready状态切换到available状态的最小等待时间, 只有上一个pod处于ready状态超过一定时间才会创建下一个pod. 虽然这会导致整个更新过程变慢, 但可有效防止意外情况发生. minReadySeconds通常需要配合Readiness一起使用:
apiVersion: apps/v1beta1 |
Pod中的container包含一个readiness, 每隔一秒会向8080端口发出HTTP请求, 每个新创建的pod的间隔时间为10秒; 将deployment从v2更新至v3时, v3版本程序的前五次HTTP请求返回状态码200, 之后返回状态码500:
$ kubectl set image deployment kubia nodejs=luksa/kubia:v3 |
v3版本的pod(kubia-7ws0i)刚被创建时, 其通过readiness probe因此状态变为ready, 但由于minReadySeconds为10, 因此deployment会在创建kubia-7ws0i后等待10秒; 由于readiness probe在第6秒发送HTTP请求后得到错误回复, 因此kubia-7ws0i状态变为Not Ready, Deployment的rollout update也暂停: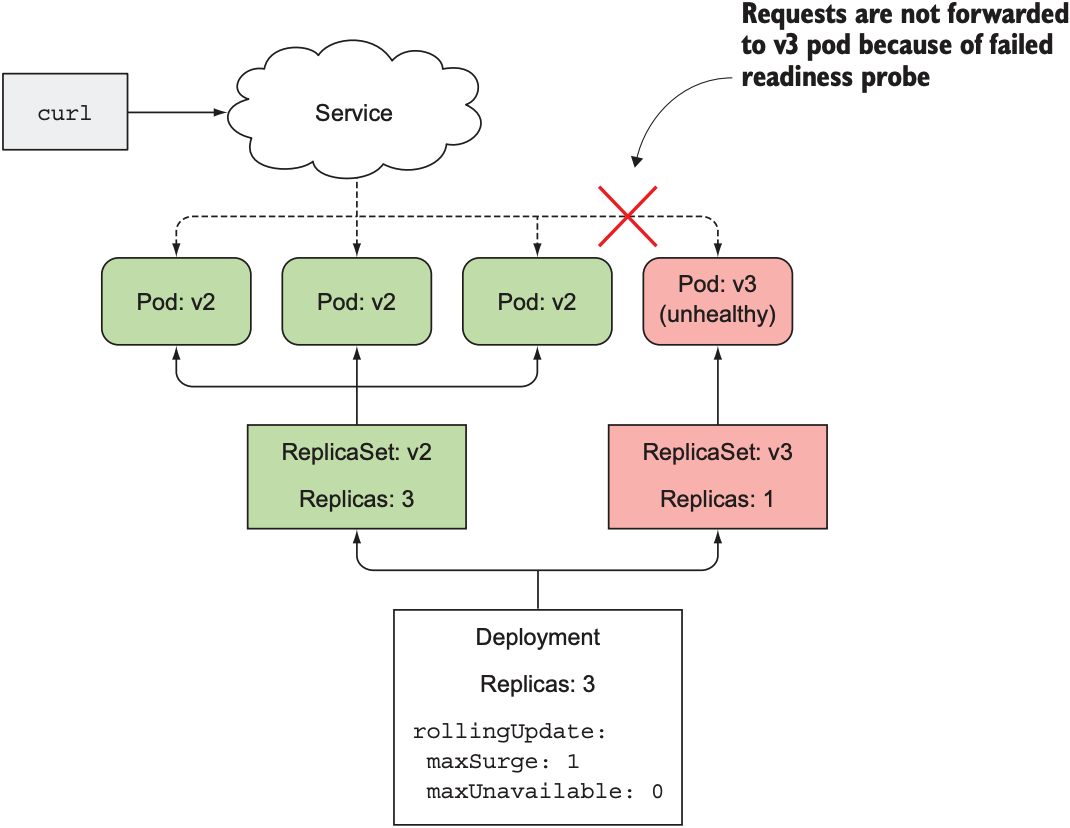
默认情况下, 若rollout未能在10分钟内完成, 则自动标记为failed, 理由为ProgressDeadlineExceeded. 若想手动取消本次rollout, 可回滚至上一版本:
$ kubectl rollout undo deployment kubia |