Kafka Essential
1. Introduction
Kafka作为Message oriented middleware(MOM, 消息中间件)的一种实现, 同类工具还有RabbitMQ, RocketMQ. 该类工具主要服务于分布式系统中的message delivery(消息传递): 服务调用方(Kafka中称为provider, 生产者)向MOM系统发送message(消息), 服务提供方(Kafka中称为consumer, 消费者)从MOM系统接收并处理消息. 相比于两个服务直接沟通, Kafka类MOM系统具有以下优势:
- 松耦合: provider无需知道consumer的地址, 无需与consumer提前建立连接(确认其是否在线), 也无需确认consumer是否完成处理. 在大型分布式项目中, 通常会包含几百种服务, 若每一种服务都与其他多个服务有依赖关系, 服务间沟通的维护成本会十分昂贵.
- 削峰填谷: consumer可根据自身处理能力, 不必一次处理全部消息, 防止provider的大量消息压垮下游的consumer, 甚至导致整个服务链崩溃.
- 消息模型: Kafka的topic概念提供了一种消息容器, 多个provider可向同一个消息容器中投递消息, 多个consumer可同时处理同一个消息容器内的多个消息.
- 日志缓存: 当全体consumer不在线时(如系统维护), Kafka可临时保存消息, 防止消息丢失
2. Main Concepts and Terminology
对于外部服务, Kafka分为两个部分:
- Server: Kafka以一个集群的形式运行, 也就是说, 一个Kafka由多个服务器组成. 服务器中运行的服务进程称为broker, 负责接收和处理client的请求, 以及消息的持久化. 虽然多个broker可运行在一台服务器上, 但通常一台服务器只运行一个broker, 因此一个broker也可表示一个服务器; 若某个服务器宕机, 其他服务器上的broker不会受影响.
- Client: client与server进行交流, 用于读取, 写入和处理消息. 发送消息的client称为producer, 读取并处理消息的client称为consumer
从Kafka Server内部观察, 其包含以下几种概念:
- Message(消息): 表示业务中发生了某件事, 每个message有一个key, 一个value, 一个timestamp, 和一个可选的metadata
- Topic(主题): 用于分类message, topic中的message可随时读取, 且读取后不会被删除(过期后自动删除). 需要注意的是, topic只是一个逻辑概念, 并不固定存放在某个服务器或文件中, producer发送的每个message都必须拥有一个topic的属性, 同一topic的message组成整个topic. 一个topic支持多个producer同时写入, 也支持多个consumer同时读取.
- Partition(分区): 一个topic可拆分为一个或多个partition, 一个broker可拥有一个topic中的一个partition. 与topic不同的是, partition不是一个逻辑概念, 其作为kafka中最小的存储单元, 每个partition都是一个log文件. 需要注意的是, 一个topic下的partition拥有不同的message, partition之间并不是互为备份关系. 单个topic内的partition编号从零开始, 依次递增, 假设某个topic有100个partition, 则partition编号为0到99.
- Offset(偏移量): partition中的每条message都会分配一个序号, 称为offset, 当producer写入message时, 会向对应topic中的其中一个partition追加该message. 由于每个partition内的offset不同, 因此一个topic下的message是无序的, 但一个partition内的message是有序的; 如果要求topic整体有序, 则只能拥有一个partition.
之所以提出上述概念, 是因为kafka在设计之初需保证的两个特性:
- Fault-tolerant(容错性): 为保证容错性, kafka集群需由多个服务器组成, 从而保证单个服务器宕机时不会影响到整个集群的运行. 虽然单个服务器宕机的概率极低, 但随着服务器数量的增加, 集群中出现宕机的概率也随之增加(假设宕机是随机独立事件). 若某个服务器宕机, 则其保存的数据也不可用, 因此需对数据进行冗余备份, 也就是拷贝到多台机器上(replication). 同一partition的不同副本称为replica, 分为两类:
- Leader: 其中一个replica所在的broker作为leader, 负责与client交互(producer向leader写消息, consumer从leader读取消息).
- Follower: 其他replica作为follower, 不与任何client交互, 只负责将最新message备份到本地
- Scalability(可拓展性), 分为两个部分:
- 容量拓展性: 单个topic内的message会超过单个服务器的存储上限, 因此将topic拆分为多个partition. 根据数据总量和单机容量, 可计算出需要多少个partition.
- 负载拓展性: 若没有partition的概念, 那么一个topic的所有读写压力会集中在某个broker上, 导致失去水平拓展; 将topic拆分为多个partition后, 若分区规则合理, 则消息会被均匀地分布到不同的partition. kafka集群中的每个broker都可作为一个partition的leader, 因此同一topic下的消息会由不同broker读写.
总结: 一个Kafka集群包含多个topic(消息分类), 一个topic包含多个partition(可拓展性), 一个partition拥有多个replica, 且每个replica放置在不同broker(防止单点故障导致数据不可用), replica所在的broker分为leader和follower, producer和consumer只与leader交互. Replica身份划分延伸出一个问题: Redis和MySQL都支持读写分离(leader负责写请求, follower负责读请求), 但Kafka选择读写不分离, 其设计原因如下:
- 读写是否分离并没有优劣之分, 每个工具都有各自的应用场景, 选择合适的架构更重要: MySQL和Redis的使用场景中, 读请求的数量通常比写入高一个或多个数量级, 因此需横向拓展处理读请求的能力(增加follower数量); Kafka作为MOM系统, 而不是数据存储引擎, 不会出现读多写少的情况.
- Kafka的数据同步方式为异步, 因此leader和follower会存在数据不一致情况, 无论是将其改为同步模式(producer延迟增加, leader写入能力下降), 还是忍受数据不一致性(consumer从follower读取到过期数据), 都存在很多问题.
- Kafka的最小读写单元为partition, 使得集群中每个broker都可以作为一个partition的leader, 从而不会出现某台机器负载过重
持久化数据对于Kafka十分重要, 这决定了Kafka的吞吐量. Kafak使用log(日志)文件保存数据, 日志只能append-only(追加写), 从而避免了随机I/O操作; 但一直写入总会耗尽磁盘, 因此需定期删除旧消息以回收磁盘. Kafka将一个日志拆分为多个log segment(日志段), 当一个日志段写满后, 会创建新的日志段, 并将旧的日志段封存起来, Kafka会定期检查日志段是否过期(默认七天), 并删除过期的日志段.
3. Message Pattern
主流的消息模型有两种:
- P2P(点对点模型): 消息发布者将消息直接发送给消息接收者
- Pub/Sub(发布订阅模型): 消息发布者先将消息发送给消息通道, 订阅对应主题的消息订阅者获得消息推送
传统的消息队列的缺陷在于, 消息一旦被消息, 就会从队列中删除, 且只能被一个consumer消费; 发布/订阅模型允许多个consumer同时消费, 但单个consumer必须订阅整个主题, 导致伸缩性不高. Kafka引入了Consumer Group(消费者组)概念: consumer group包含一组consumer, topic中的partition会分配给topic中不同的consumer, 从而解决了伸缩性差的问题(consumer不必消费topic的所有partition), 提高了消费端的吞吐量(多个consumer同时消费同一topic).
每个consumer group拥有一个全局唯一ID, 称为Group ID. 需要注意的是, topic中一个partition只能由consumer group中的一个consumer消费(consumer与partition呈一一对应关系). Consumer消费信息时, 会保留一个字段记录已经消费到哪个partition的哪个位置, 该字段称为consumer offset(消费者位移).
虽然多个consumer同时消费单个topic带来了极大的伸缩性, 但也引入诸多问题:
- Kafka如何记录consumer消费到哪个partition的哪一条消息: Kafka使用offset(与consumer offset不同)表示consumer已消费了哪些消息. 对于单个consumer group, 其包含一组键值对, key为
<topic, partition>, value为partition的最新位移. 老版本Kafka将位移信息保存在ZooKeeper上, 但ZooKeeper不适合频繁的写操作, 会拖慢整体性能, 因此新版本Kafka将位移信息保存在内部的topic中, 称为**__consumer_offsets**. - Kafka如何为每个consumer分配partition: Kafka会自动分配单个consumer group中每个consumer要消费的partition, 假设某个consumer挂掉, Kafka会自动检测并将该consumer负责的partition分配给其他consumer, 称为Rebalance. 对于rebalance, 存在以下注意点:
- Rebalance何时触发
- Rebalance的分配策略
- Rebalance的缺陷
3.1 Partition Assignment Strategy
Kafka提供了三种partition分配策略:
- range: 对consumer group订阅的topic中的partition按照序号排序, 并将consumer按字典序排序, 每个consumer负责消费topic中固定范围的partition, 若不能平均分配, 则排序靠前的consumer会处理额外partition.
- RoundRobin: 对consumer group订阅的所有topic的所有partition按照字典序排序, 然后通过轮询方式将各个partition分配给每个consumer.
- StickyAssignor: 该分区策略遵循两个原则:
- paritition的分配尽量均匀
- partition的分配尽可能与上次分配相同, 若与第一条冲突, 则遵循第一条
3.2 Kafka Group Coordinator
Rebalance看似美好, 但也有很多弊端:
- Rebalance会暂停所有consumer, 影响consumer端的吞吐量
- Rebalance的执行时间很长
由于rebalance目前没有很好的优化方案, 因此最好的方案就是尽量避免触发rebalance. 在讨论如何避免rebalance之前, 需先明白Kafka如何让consumer group中的所有consumer达成共识.
每个consumer group都有一个broker作为group coordinator(组协调者)负责管理位移信息和组成员, 执行rebalance. 当consumer加入一个consumer group时, 会向对应的group coordinator发送请求; 当consumer离开consumer group时, coordinator负责rebalance. 整个过程存在两个问题:
- group coordinator如何启动: 所有broker启动时都开启一个group coordinator组件, 因此所有broker都可成为group coordinator
- consumer如何找到group coordinator所在的broker:
- consumer向任意一个broker发送
FindCoordinator请求, 并附带consumer group的Group ID - 收到请求的broker计算
Group ID的hash值, 并从__consumer_offsets获得该consumer group的partition数量 hash值 % partition数即为某个paritition的编号- 该partition的leader为group coordinator, 返回给consumer
- consumer向任意一个broker发送
3.3 How to Avoid Rebalance
要想避免触发rebalance, 必须先清楚rebalance何时触发, 分为以下三种情况:
- Consumer group下的consumer数量发生变化: 新的consumer加入group, 或已有consumer离开group
- 订阅的topic数量发生变化: consumer group可用正则表达式匹配topic, 因此新建topic可能增加consumer group的topic数量增加
- Topic的partition数量发生变化: 当增加partition数量时, 订阅对应topic的consumer group会开启rebalance
以上三种触发条件中, consumer group订阅的topic数量变化和topic中的partition数量变化都是人工操作导致的, 因此只要不手动添加就不会触发rebalance. 99%的rebalance都是因为consumer数量的变化, 分为两种情况:
- consumer的数量增加: 启动新的consumer时, 会向对应
Group ID的consumer group中添加新的consumer, 一般是运维添加, 因此不可避免 - consumer的数量减少: 若手动关闭某个consumer, 则不可避免; 但某些情况下, group coordinator会错误地认为某个consumer已停止工作, 从而将其移除consumer group
因此需了解group coordinator如何判断consumer是否存活, 以下是consumer端的一些配置参数:
session.timeout.ms: consumer会定期向group coordinator发送heartbeat, 表示自己仍存活, 该参数表示heartbeat超时时间. 若某个consumer不能及时发送heartbeat, group coordinator会认为该consumer已死, 并开启rebalance. 默认为45秒.heartbeat.interval.ms: 该参数表示heartbeat发送频率, 值越小, heartbeat发送的频率越高, 可以更快速地让group coordinator决定是否开启rebalance, 但会额外消耗带宽. 默认为3秒.max.poll.interval.ms该参数表示两次poll之间的最大时间间隔, 若consumer无法在指定时间内完成消费, 会主动离开consumer group. 默认为5分钟.
因此, 为避免不必要的rebalance, 可按照以下规则设置参数:
- session.timeout.ms = 6s
- heartbeat.interval.ms = 2s, 保证
$\text{session.timeout.ms} \ge 3 * \text{heartbeat.interval.ms}$, 也就是, 超时前至少发送三次heartbeat - max.poll.interval.ms的数值根据consumer的处理时间而定, 假设每次消费需要5分钟, 则该参数必须大于5分钟
4. High Throughput and High Availability
4.1 High Throughput
以下是Kafka高吞吐量的原因:
- 操作系统层面:
- Append only: 只在日志结尾追加数据, 写入速度比随机写快很多
- Zero copy(零拷贝): 读取数据时, 直接将数据从kernel space复制到socket buffer中, 无需经过user space
- Page Cache(页缓存): 将磁盘中的文件缓存到内存中, 减少I/O操作, 并将数据是否刷入磁盘的决定权交由操作系统
- 网络通信方面:
- 批量发送: producer先将消息写入一个缓存池, 达到一定数量后组成一个batch, 一并发送
- 数据压缩: producer可使用不同压缩算法减少数据传输量
- 系统设计方面:
- Producer推送消息时, 可无需等待Kafka集群的任何确认(
acks = 0) - Kafka的topic概念让数据处理的单元变为partition, 让Kafka具有横向拓展能力
- 新版Kafka将一些频繁写入的数据从ZooKeeper剥离, 避免ZooKeeper成为集群的瓶颈
- ISR(In-Sync Replicas): Follower不会与leader保持完全同步, 只需周期性(
replica.lag.time.max.ms)向leader发送FetchRequest请求. Leader负责维护ISR列表并同步到ZooKeeper.
- Producer推送消息时, 可无需等待Kafka集群的任何确认(
- JVM方面: 由于GC(垃圾回收)会导致所有线程停止工作, 因此Kafka需减少GC的出现频率. 当producer发送信息后, 由于没有任何引用指向该内存, 很容易触发GC, 因此producer端设计了一个缓存池: 当消息来临时, 从缓存池申请一个batch; 发送batch后, 将内存还回缓存池. 若producer的写入占满整个缓存池, 会阻塞所有写入, 只能等待batch发送.
4.2 High Availability
以下是Kafka能做到高可用性的原因:
- Producer端:
- 多producer一起提交
- 同步提交消息:
commitSync() - 当写入速度过快, 会阻塞写入操作, 防止消息丢失
- Kafka集群端:
- 消息备份: 每个partition存在多个replica, 且分布在不同机器上
- 主从不分离: Leader负责读写操作, 保证消息新鲜度
- Leader选举: 当leader宕机时, 会选举出新的leader
- Consumer端:
- 可关闭自动提交位移, 防止重复消费
- 多consumer一起消费, 且支持rebalance
5. Data Loss
很多开发者会使用Kafka时遇到消息丢失的情况, 从而认为Kafka不可靠, 这是错误的. 在解决消息丢失问题前, 需清楚Kafka在什么情况下保持消息不丢失, 从而找到一些消息丢失的原因, 并提出相应方案: 当消息被committed(提交)后, Kafka会为该消息提供有限的持久化保证. 其中有两个关键点:
- 提交消息: Producer向broker发送消息, 该消息被多个broker写入日志, 并回复producer该消息已提交, 此时producer可认为消息提交成功
- 有限的持久化保证: 若集群中所有broker同时丢失数据, 则会导致消息永久丢失, 因此需保证至少一台broker存活
因此, 我们可以思考下一个问题: 什么情况下Kafka会丢失数据. 大体来说分为以下三种:
5.1 Producer Loses Data
Producer丢失数据是最常见的场景. 首先, producer的send(msg)为异步发送消息, 该函数调用后立即返回, 因此producer不能认为消息已成功提交. 例如, 网络中断会导致消息未发送至broker, 或由于消息格式不正确而被broker拒收. 解决方案是改用send(msg, callback), callback会告诉producer消息是否提交成功, 以便后续处理.
当然, 消息的接收端leader也可能宕机, 存在两种情况:
- 若单个broker宕机, producer会自动获得最新的metadata, 其中包含新选举的leader
- 若所有broker宕机, producer怎么重试都会失败, 此时更需要处理Kafka集群内的问题
5.2 Broker Failure
Kafka为做到高吞吐量和低延迟, broker接收到消息后不会立即写入磁盘, 而是由操作系统的page cache(页缓存)决定何时写入磁盘, 写入前消息会保留在内存中. 因此, 若所有broker在写入磁盘前全部宕机, 也会导致消息丢失, 不过该情况的出现概率极低.
5.3 Consumer Loses Data
Consumer端的消息丢失分为两种情况:
- consumer错误提交位移信息. Consumer端会保留一个offset(位移)字段, 表示已消费到
<Topic, Partition>的哪个消息. 因此consumer应先消费消息, 再向group coordinator提交位移; 若consumer先提交位移, 并在消费消息前崩溃, 则会导致消息丢失. 解决方法是关闭自动提交位移, 改为手动提交 - consumer从leader获得多个消息, 并开启多个线程异步处理消息, 且自动提交位移. 假设某个线程运行失败, 其负责的消息未被处理, 也会导致消息丢失. 多线程消费的实现十分困难, 需尽量避免使用多线程消费消息.
5.4 Summary
- Producer使用
send(msg, callback), 在callback中确认消息提交 - Producer端的
acks参数: 表示消息被认为提交成功前, 需要多少个broker返回ack, 该参数有三个选项, 默认为all(Kafka >= 3.0):acks = 0: 只要producer发出信息, 就认为消息写入成功, 无需等待leader回复ack. 该选项拥有最大消息吞吐量, 也容易丢失消息acks = 1: leader写入信息后立即回复ack, 无需等待其他replica同步成功; 若replica同步前leader宕机, 也会造成消息丢失.acks = all: leader等待足够数量的replica同步, 再向producer发送ack; 这里的足够数量由Kafka集群的min.insync.replicas参数决定, 并不一定是partition的所有replica; 若没有足够数量的replica同步, 则向producer抛出NotEnoughReplicasException.
- Producer端的
retries参数: 表示producer提交消息失败时重试多少次, 默认为2147483647, 可将其设置为一个较大的值以应对网络中断等临时故障 - Broker端的
unclean.leader.election.enable参数: 表示一个落后的replica是否有资格选为leader, 默认为false. 当一个落后的broker成为leader, 必然造成消息丢失. - Broker端的
replication.factor参数: 表示新建的topic的副本数量, 默认为1, 可将该参数设置为$\ge 3$以防止消息丢失. - Broker端的
min.insync.replicas参数: 当producer将ack设置为all时, leader收到多少个replica的ack才算是写入成功, 默认为1, 可设置为更高值. - 确保
$\text{replication.factor} \gt \text{min.insync.replicas}$, 若两者相等, 则任意一个replica宕机都会导致数据无法写入, 可设置为$\text{replication.factor} = \text{min.insync.replicas} + 1$ - Consumer端的
enable.auto.commit参数: 表示是否自动提交offset, 默认为true. 可设置为false, 消费消息后手动提交位移.
6. TCP Connections
Kafka中的所有通信都基于TCP, 而不是HTTP, 因为TCP具有更多底层特性, 例如:
- 多路复用: 多个数据流使用同一链接, 减少TCP handshake次数
- 消息顺序一致: TCP保证消息发送顺序与消息接收顺序一致
- 轮询I/O连接: 可使用Linux的
epoll高效轮询多个TCP连接
6.1 TCP Connection of Producer
以下是producer创建TCP连接的几种情况:
- 创建producer实例时, 会在后台创建一个线程, 该线程与
bootstrap.servers中的broker创建连接. 由于未指定topic, 因此会与所有broker建立连接. 连接建立完毕后, 会向其中一个broker发送metadata请求, 以获取Kafka集群的所有信息.Producer producer = new KafkaProducer(props);
- 更新metadata时: 若producer需要更新metadata且与broker没有连接, 则会创建连接. 以下是更新metadata的情况:
- 初始producer实例
- Producer端
metadata.max.age.ms参数的倒计时结束 - Broker收到broker的异常响应, 如发送的消息不属于任何topic
- Producer无法找到partition对应的leader
- Producer发送消息: 若producer未与消息对应的leader建立连接, 则会创建一个新的连接
producer.send(msg, callback)
以下是producer关闭TCP连接的两种方式:
- 主动关闭: kill进程, 或调用
producer.close()关闭实例 - 自动关闭: producer端的
connections.max.idle.ms参数: 表示某个TCP连接在指定期间内没有任何数据传输(不包括heartbeat), 则关闭该连接. 默认为9分钟, 可设置为-1, 表示禁止自动关闭连接.
6.2 TCP Connection of Consumer
以下是consumer创建TCP连接的几种情况:
- 发送
FindCoordinator请求: 每个consumer group都有一个group coordinator负责管理组内consumer提交的位移. 当consumer首次调用poll方法, 会向任意broker发送FindCoordinator请求, broker回复consumer group对应的group coordinator地址. - 连接group coordinator: consumer收到group coordinator的地址后, 会连接group coordinator, 并请求加入consumer group.
- 获取metadata: 由于消息保存在leader, 而不是group coordinator, 因此consumer需与partition对应的leader建立连接, 在此之前, 需向任意broker请求metadata信息.
- 消费消息: consumer为每个partition创建对应leader的连接. 假设consumer需消费5个partition, 这些partition的leader分布在4台服务器上, 则consumer需建立4个连接.
以下是consumer关闭TCP连接的几种情况:
- 主动关闭: kill掉consumer实例, 或调用
consumer.close() - 自动关闭: TCP连接在指定期间内(
connections.max.idle.ms)没有任何数据传输, 会自动关闭该连接.
7. Consumer Offset
在讨论consumer如何提交offset之前, 需先区分两种offset:
- offset: partition的每个消息都有一个offset, 值从0开始, 假设producer发送三条消息, 则offset分别是
0, 1, 2. 消息的offset单调递增, 且提交后不可更改. - consumer offset: 每个consumer需记录自己消费到partition的哪个消息, 缩写为offset.
7.1 How Consumer Commits Offset
Consumer之所以要提交offset, 是为了避免其他consumer重复消费. 若consumer提交的offset为X, 表示offset小于X的消息都已被消费. Group coordinator不会验证consumer是否完成消费, 因此需要consumer自行保证正确性. Consumer端有两种提交offset的方式:
- 自动提交: 无需用户参与, consumer会定时提交offset. Consumer端的
enable.auto.commit = true参数表示开启自动提交, 并根据auto.commit.interval.ms参数(默认为5秒)每隔一段时间自动提交最新获得的offset. 自动提交的问题在于可能出现重复消费. 假设consumer每5秒自动提交一次offset, consumer在第3秒崩溃, 那么group coordinator会将前三秒的消息再次分配给其他consumer. 即便调小auto.commit.interval.ms来提高提交频率也无法避免重复消费. - 手动提交: 需consumer手动提交offset, 分为两种.
- commitSync(): 同步提交. 该函数会一直等待, 直到offset成功提交至group coordinator.
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
process(records);
try {
consumer.commitSync();
} catch (CommitFailedException e) {
handle(e);
}
} - commitAsync(): 异步提交. 该函数立即返回. 该函数提供了
callback用于提交后的处理, 如记录日志或异常处理.while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
process(records);
consumer.commitAsync((offsets, exception) -> {
if (exception != null)
handle(exception);
});
}
- commitSync(): 同步提交. 该函数会一直等待, 直到offset成功提交至group coordinator.
上述两种提交offset方式各有优劣:
commitSync: 保证位移成功提交, 但影响consumer吞吐量commitAsync: 保证consumer吞吐量不受影响, 但可能提交失败
因此可结合两者优点: 若外部条件一切正常, 使用commitAsync; 出现网络波动等临时故障时, 使用commitSync处理.
try { |
7.2 __consumer_offsets Topic
新版本Kafka将offset信息保存在__consumer_offsets topic中, 因此offset信息也是一条普通消息, 这么做既满足了offset的持久性, 也弥补了ZooKeeper写操作效率过低的缺点. 用户无需操作该topic, 其消息格式由Kafka定义, consumer通过Kafka的API提交offset信息, 而不是向该topic发送消息.
__consumer_offsets内每一个消息都是一个Key-Value Pair. Key为<Group ID, Topic, Partition>; Value包含offset信息, 还有一些时间戳和用户自定义数据, 这些额外信息可帮助Kafka进行维护工作, 如删除过期的offset信息.
当第一个consumer启动时, Kafka集群会自动创建__consumer_offsets. 该topic的partition数量取决于broker端的offsets.topic.num.partitions参数, 默认为50; 其replica数量取决于broker端的offsets.topic.replication.factor参数, 默认为3.
当使用自动提交时, 即使consumer没有进行消费, 也会不断提交最后一次获取的offset, 最终导致__consumer_offsets不断膨胀, 因此Kafka需要删除重复消息, 称为Compaction(压缩). 由于每条offset消息都有一个key, 假设__consumer_offsets中存在相同key的两条消息M1和M2, 若M1的发送时间早于M2, 那么M1为过期消息.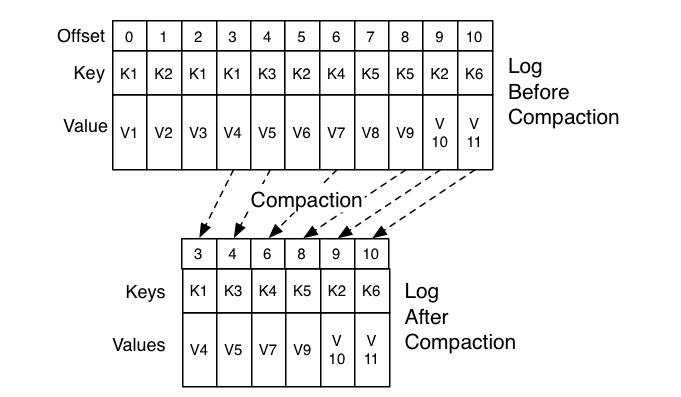
Kafka有专门的后台线程(Log Cleaner)定期查看哪些消息过期.
8.Idempotence in Kafka
8.1 What is Idempotence
Idempotence(幂等性): 当系统多次收到同一请求时, 可保证该请求只被处理一次. 作为系统对外的一种承诺, 让开发者在不破坏系统状态的前提下安全地重试任何请求. 例如用户付款时, 网络波动可能导致系统未收到第一次付款请求, 因此用户再次付款, 系统会收到两笔付款, 若系统不支持幂等性, 则扣款两次. 但并不是所有请求都需要幂等性:
- 查询操作: 无论执行多少遍, 都不会改变系统状态
SELECT * FROM table1 WHERE col1 = 1;
- 常量赋值更新: 无论执行多少遍, 系统状态仍保持一致
UPDATE table1 SET col1 = 1 WHERE col2 = 2;
- 变量赋值更新: 每次执行都会产生新的系统状态
UPDATE table1 SET col1 = col1 + 1 WHERE col2 = 2;
以下是网站架构中可能导致幂等性问题的情况:
- 网络波动: 第一个请求遭遇网络延迟, 客户请求第二次请求
- 重复操作: 用户无意中发起了两次或多次请求(重复点击按钮)
- 自动超时重试
- 页面刷新
- 定时任务
实现幂等的关键在于如何区分当前请求是否与已处理的请求重复, 若系统可以过滤重复请求, 则达成幂等. 区分请求是否重复的关键有以下两点:
- 如何生成唯一标识: 请求中的唯一标识必须能够区分当前请求与其他请求
- 如何记录已处理请求: 处理完某个请求后, 必须通过某种机制记录该请求; 当新的请求到达时, 可比较并判断是否为重复请求
8.2 Messaging semantics
对于发布订阅式的分布式消息系统, 系统中的每个机器都随时可能宕机. 对于Kafka来说, 每个服务器随时可能宕机, producer与Kafka集群的网络随时可能中断. 为应对此类失败, Kafka(0.11版本)为producer提供了三种messageing semantic(消息语义):
- At-least-once(至少一次): 若producer端的配置为
acks=all, 且收到broker的ack, 说明消息已写入; 若producer收到错误信息, 或ack超时, 则会重发该消息; 若broker成功写入消息, 但在回复ack前宕机, 则会导致同一消息多次写入. 该语义保证消息不会丢失, 但可能重复发送. - At-most-once(至多一次): 若producer收到错误或ack超时, producer不会重发消息, 则消息不会被写入, 也不会传递给consumer. 该语义保证消息不会重复发送, 但可能丢失.
- Exactly-once(精确一次): 出错时producer会重发信息, 且broker保证消息不会被重复消费. 该语义是最理想的保证, 但也十分难以实现, 因为这需要producer和broker合作. 该语义不会丢失消息, 也不会重复发送.
以下是导致Kafka中幂等性问题的一些情况:
- Broker宕机: 当消息写入Kafka时, 会被持久化并复制多份, 因此Kafka能承受
n-1个broker宕机, 换句话说, 只要有一个broker在线, 就有partition可用. 若所有broker都宕机, 则消息丢失. - Producer与broker之间的通信中断: producer发送消息后未收到ack, 不代表消息未被写入, 因为broker可能在写入消息前或写入消息后宕机. 由于producer无法知道Kafka集群出现什么问题, 为防止消息丢失, 只能重发消息.
- Consumer出错: kafka集群也无法得知consumer的状况. 若consumer消费完消息后, 还未提交offset就宕机, 则broker无法知道该消息是否消费, 只能将消息分配给其他consumer, 从而导致重复消费.
8.3 Idempotent Producer
Producer默认是不幂等的, 开启需在producer端设置enable.idempoten = true. 为实现producer端的幂等性, Kafka引入两个新字段:
- Producer ID(PID): 每个producer初始化时会被分配一个唯一PID
- Sequence Number: producer发送消息时, 会为每个
<Topic, Partition>附带一个从零开始且单调递增的序列号
Broker端会为<PID, Topic, Partition>维护对应的序列号, 当producer提交消息时, 存在以下三种情况:
Producer提供的序列号 = Broker的序列号 + 1: 接收该消息Producer提供的序列号 > Broker的序列号 + 1: 存在消息未写入, 抛出InvalidSequenceNumberProducer提供的序列号 < Broker的序列号 + 1: 该消息重复, 抛出DuplicateSequenceNumber
上述设计解决了两个问题:
- Broker写入消息, 但在回复ack前宕机, 若producer再次提交该消息, broker会识别为重复消息
- Producer发送两条消息, 第一条消息丢失, broker会拒绝第二条消息, 防止消息乱序
由于broker通过<PID, Topic, Partition>区分消息, 存在以下缺陷:
- Producer只能保证单个topic中单个partition内不会出现重复消息, 无法做到跨partition的幂等性
- Producer只能保证单会话上的消息幂等性, 因为producer重启会导致PID更改, 从而无法保证幂等性
8.4 Transactional Producer
为解决跨partition和跨会话的幂等性, Kafka引入transaction(事务). 开启事务需在producer端设置enable.idempotence = true, 并为每个producer设置一个transctional.id, 代码如下:
producer.initTransactions(); |
为实现事务特性, Kafka引入一些新机制:
- Transaction Coordinator: 用于管理每个producer的消息事务, 维护Transaction Log, 该log存于一个内部topic中, 名为
__transaction_state - Epoch: 一个单调递增的整数值, 用于标识最新的producer. 当两个producer拥有相同transactional id时, transaction coordinator无法区分两者, 因此producer初始化事务时, 会从transaction coordinator获取producer id和epoch; producer提交消息时会携带epoch. 当producer发送消息时(假设transactional id为
t1, epoch为e1), transaction coordinator已有transactional id为t1且epoch为e2的producer(e2 > e1), 则拒绝当前producer, 避免事务干扰. - ControlBatch: producer产生的一种特殊消息, 有两种类型:
- commit: 提交事务
- abort: 中止事务
以下是执行事务的流程:
8.4.1 Find Transaction Coordinator
Producer向任意一个broker发送FindCoordinatorRequest请求, 获取transaction coordinator的地址
8.4.2 Initialize Transaction
Producer向transaction coordinator发送InitpidRequest请求, 其中带有transaction id, transaction coordinator回复PID和epoch; 若transaction coordinator第一次收到该transaction id, 则将<Transaction ID, PID>存入transaction log; 此外, transaction coordinator还会执行以下任务:
- 增加该PID对应的epoch, 若PID相同但小于当前epoch的producer尝试开启事务, 则会拒绝该producer
- 若该PID有未完成的事务, 则恢复之前的事务
8.4.3 Begin Transaction
Producer调用beginTransaction(), 将自身状态改为BEGIN, 且无需通知transaction coordinator, 因为transaction coordinator会在producer发送第一条消息后开启事务
8.4.4 Send Message
当producer调用send()发送消息时, 会进行以下操作:
waitOnMetadata(): 确认metadata准备完毕, 否则阻塞等待partition(): 根据消息分区器计算消息存入的partition编号- 将消息封装到
ProducerBatch中 - 若
ProducerBatch中消息数量达到阈值, 调用Sender.wakeup()发送消息
Sender向leader发送消息前, 会先向transaction coordinator发送AddPartitionsToTxnRequest. Transaction coordinator将<Transaction, Topic, Partition>存入transaction log, 并将事务状态设置为BEGIN.
Consumer通常会在消费后调用commit(A)Sync()提交位移; 但事务中可能出现consume-transform-produce模式: 当前producer生成的消息来自consumer从上游producer读取的消息, 若consumer获得消息后调用commit(A)Sync(), 无法保证消息被下游producer成功使用并生成新的消息, 因此需要下游producer调用sendOffsetsToTransaction()提交位移, 该函数会进行两步操作:
- 向transaction coordinator发送
AddOffsetsToTxnRequests请求, transaction coordinator会将对应的<Topic, Partition>保存在transaction log中 - 向group coordinator发送
TxnOffsetCommitRequest, group coordinator会将<Topic, Partition>对应的offset保存在__consumer_offsets中
需注意两点:
- 写入
__consumer_offsets中的offset信息在提交前是不可见的 - Group coordinator会通过PID和epoch验证producer是否有资格提交offset
8.4.5 Commit/Abort transaction
Producer调用commitTransaction()或abortTransaction()提交或中止事务. 无论是commit还是abort, producer都会向transaction coordinator发送EndTxnRequest请求; 当transaction coordinator收到该请求后, 会进行如下操作:
- 根据commit或abort, 将
PREPARE_COMMIT或PREPARE_ABORT写入transaction log - 通过
WriteTxnMarker请求, 以Transaction Marker的形式将COMMIT或ABORT信息发送给当前事务中每个<Topic, Partition>的leader, 并写入group coordinator的__consumer_offsets中 - 将
COMPLETE_COMMIT或COMPLETE_ABORT写入transaction log中
8.5. Consume Message
Consumer开启事务需配置为 isolation.level=READ_COMMITTED. Consumer不会与transaction coordinator建立任何连接, 只与group coordinator沟通. Consumer会从group coordinator不断获取消息, 收到commit的ControlBatch时才会读取消息; 若事务被abort, 则丢弃该事务的所有消息.
8.6. Impact to Performance
8.6.1 Produce Message
开启事务后, producer端有以下性能影响:
- 事务开始时, producer需将partition注册到transaction coordinator
- 事务结束时, transaction coordinator需将
Transaction Marker发送给对应的leader - 事务进行时, transaction coordinator需将事务状态写入transaction log, 涉及磁盘写操作
可以看到, 事务的开销与实际消息无关, 而是一些事务的控制消息, 因此提高单个事务中的消息数量来提高吞吐量.
8.6.2 Consume Message
开启事务后, consumer端的性能影响很小, 因为consumer无需与transaction coordinator建立连接, 只需过滤一些额外消息, 如ControlBatch; 并且consumer无需缓存读取的消息以等待事务结束, 仍可用zero-copy来读取消息.