Linux namespace
1. Introduction
Linux的namespace负责实现资源隔离, 其包含以下资源:
| namespace | Flag | Isolate |
|---|---|---|
| UTS | CLONE_NEWUTS | hostname(主机名)和domain name(域名) |
| IPC | CLONE_NEWIPC | System V IPC和POSIX message queue |
| PID | CLONE_NEWPID | process ID |
| Network | CLONE_NEWNET | network device(网络设备), stack(网络栈), port(端口) |
| Mount | CLONE_NEWNS | mount ID |
| User | CLONE_NEWUSER | user id和group id |
同一namespace内的进程可感知到彼此存在, 但对其他namespace的进程一无所知, 从而让进程有一种自己处于独立系统环境的错觉, 从而达到隔离资源的目的.
2. namespace API
namespace API包含以下四种:
clone()setns()unshare()/proc目录下的部分文件
2.1 clone()
clone()是Docker为新进程创建一个新的namespace的最常用方法:
/** |
flags可使用CLONE_*标识符, 与namespace相关的标识符包括: CLONE_NEWIPC, CLONE_NEWNS, CLONE_NEWNET, CLONE_NEWPID, CLONE_NEWUTS
2.2 /proc/[pid]/ns
proc是Linux中的一个pseudo-filesystem(伪文件系统), 也就是说, 其中的文件并不是真正的文件, 也不存在于存储设备, 而是内存中的系统信息, 并包装成文件系统, 向进程提供了一个访问kernel数据结构的接口.
该文件系统的类型为proc, 通常由系统自动挂载在/proc, 进程也可手动挂载: mount -t proc proc /proc. 绝大多数文件都是read-only(只读), 部分文件可写入, 且绝大多文件的大小为0.
从Linux 3.8开始, 用户可在/proc/[pid]/ns中看到指向不同namespace的文件, 如下:
$ ls -l /proc/$$/ns |
其中, $$表示当前进程的PID, [4026533275]即为namespace编号, 若两个进程指向的namespace编号相同, 则说明两个进程处于同一namespace中, 否则处于不同namespace中.
需要注意的是, 若进程退出, 其目录下的namespace也会被删除; 但只要namespace文件的file descriptor存在于系统中, 即使进程退出, 还会保留该namespace文件, 例如:
touch ~/uts |
上述命令将PID为27514的UTS namespace文件挂载到~/uts, 即使该进程退出, 也不会删除对应的uts namespace文件.
2.3 setns()
/** |
为利用新的namespace, 需调用execve系列函数, 该函数会执行用户命令, 如下:
fd = open(argv[1], O_RDONLY); // obtain namespace fd |
假设编译后的程序名为setns-test, 执行以下命令:
$ ./setns-test ~/uts /bin/bash |
上述命令中, ~/uts为/proc/27514/ns/uts的bind mount, 因此执行完毕后, 当前进程加入PID为27514的uts namespace, 并启动一个shell.
2.4 unshare()
/** |
相对于clone(), unshare()运行在原先的进程上, 因此不需要启动一个新进程. Docker目前并没有使用该系统调用, 因此不做展开.
3. UTS namespace
UTS(UNIX Time-sharing System) namespace提供了hostname(主机名)和domain name(域名)的隔离, 让每个docker container都能拥有独立的主机名和域名, 而非主机上的一个进程.
|
编译并运行上述代码, 执行结果如下:
root@ubuntu:/code# gcc -Wall uts.c -o uts.o && ./uts.o |
在上述代码中加入UTS隔离, 代码如下:
|
结果如下:
root@ubuntu:/code# gcc -Wall uts.c -o uts.o && ./uts.o |
可以看到, child process改为新的主机名, 若不添加CLONE_NEWUTS, 则parent process的hostname也会改变.
4. IPC namespace
IPC(Inter-Process Communication, 进程间通信)涉及的资源包括semaphore(信号量), message queue(消息队列)和shared memory(共享内存). 申请IPC资源时会申请一个全局唯一的32位ID, 因此IPC namespace包含IPC标识符, 以及实现POSIX message queue的文件系统. 同一IPC namespace的进程可查看共享的IPC资源.
在上一节代码中加入CLONE_NEWIPC, 并重命名为ipc.c, 修改部分如下:
// ... |
在shell中使用ipcmk -Q命令创建一个message queue:
root@ubuntu:/code# ipcmk -Q |
ipcs -q可查看当前所有message queue:
root@ubuntu:/code# ipcs -q |
编译并运行代码, 在child process中查看message queue:
root@ubuntu:/code# gcc -Wall ipc.c -o ipc.o && ./ipc.o |
可以看到, child process无法看到parent process声明的message queue, 说明已实现IPC隔离.
5. PID namespace
PID namespace会对PID重新编号, 因此两个PID namespace下的进程可能拥有相同PID. Kernel会为每个namespace维护一个树状结构和一个计数器, 最顶层的PID namespace在系统初始化时创建, 称为root namespace; 新创建的PID namespace与原本的PID namespace构成父子关系, 因此原先的PID namespace称为parent namespace, 新创建的PID namespace称为child namespace, parent namespace可看到child namespace中的进程, 并可通过signal等方式对child namespace中的进程产生影响; 但child namespace不能看到parent namespace中的任何进程.
- PID namespace中第一个创建的进程(调用
clone(CLONE_NEWPID)创建的进程, 或进程调用unshare(CLONE_NEWPID)创建的第一个子进程)的PID为1, 作为该PID namespace的init进程, 该进程作为所有orphaed进程的parent process. - 除了root namespace, 所有PID namespace都有一个parent namespace, Linux 3.7将PID namespace树状结构的深度限制为32.
- child namespace中的进程可被其parent namespace, 以及所有直系ancestor namespace看到; 也就是说, 进程可向同一PID namespace中的其他进程, 或child namespace中的所有进程调用
kill()发送signal, 或调用setpriority()设置nice值.
Docker daemon则利用PID namespace监控所有运行的进程, 以下是添加了PID隔离的代码, 并命名为pid.c:
// ... |
编译并运行代码, 结果如下:
root@ubuntu:/code# gcc -Wall pid.c -o pid.o && ./pid.o |
可以发现, child process的PID变为1, 说明该进程成为新的PID namespace的init进程; 但若在child process的shell中执行ps aux, 仍能看到parent process的PID, 因此该命令查看的是/proc文件系统下的内容, 由于此时还未进行文件系统的mount隔离, 因此能看到全部进程.
5.1 init process in PID namespace
UNIX系统中, init进程的PID为1, 其会维护一个进程表, 不断检查每个进程的状态. 若某个进程因其parent process提前中止而成为orphaned进程, init会成为该进程的parent process, 并回收资源, 结束该进程. 因此, init进程的设计目的在于监控和回收进程资源. PID namespace沿用了相同的树状结构, 保证每个PID namespace不会出现资源泄露.
5.2 signal and init process
PID namespace中的init进程拥有信号屏蔽的特权, 也就是说, 只要init没有设置signal handler, 则init会忽略同一PID namespace中的进程向其发送的signal, 以防止init被误杀.
但若parent namespace中的进程向child namespace中的init进程发送signal, 只要不是SIGKILL或SIGSTOP, init也可选择忽略; 但若是SIGKILL或SIGSTOP, init则无法捕获或忽略, 也就是说, parent namespace中的进程有权中止child namespace中的进程.
若init进程中止, kernel会向init所处的PID namespace中的所有进程发送SIGKILL, 因此该PID namespace也不复存在; 但若/proc/[pid]/ns/pid处于被挂载或打开状态, 则会保留该PID namespace, 但该PID namespace调用fork()会返回ENOMEM错误, 因此无法在PID namespace中创建任何进程.
5.3 mount proc filesystem
由于ps命令通过proc文件系统查看进程信息, 因此即使child process加入新的PID namespace, 其仍能看到所有进程, 因此需在child process中重新挂载proc:
root@NewHostname:/code# mount -t proc proc /proc |
可以看到, 新的PID namespace中只有两个进程运行; 但这么做会影响parent process, 因此代码并未实现mount point的隔离, 再次执行mount -t proc proc /proc即可恢复.
5.3 unshare() and setns()
unshare()允许当前进程建立新的namespace, 以实现资源隔离, 但PID namespace是一个例外: unshare()的调用进程不会进入新的PID namespace, 其创建的child process才会进入新的PID namespace, setns()也是相同原理.
之所以这么设计, 是因为程序调用getpid()获得进程的PID后, 会一直使用该PID作为进程的唯一标识; 若PID发生变化, 会引起一些库函数和程序的崩溃, 因此一旦创建进程, 其PID namespace和PID就不可改变. docker exec会使用setns()加入已存在的namespace, 但最终还是会调用clone().
6. mount namespace
mount namespace通过隔离filesystem的mount point实现filesystem的隔离, 由于是Linux的第一个namespace, 因此标识位为CLONE_NEWNS. 可通过/proc/[pid]/mounts查看某个进程所处的mount namespace的filesystem, 也可通过/proc/[pid]/mountstats查看某个进程所处的mount namespace的文件设备信息, 包括挂载文件的名字, 文件系统类型, 挂载位置等.
使用clone()或unshare()创建新的mount namespace时, 新的mount namespace会按照以下规则初始化:
- 若mount namespace由
clone()创建, child process会复制parent process的mount list - 若mount namespace由
unshare()创建, 则会复制当前进程的mount namespace
6.1 shared subtrees
引入mount namespace后, 人们发现某些情景下mount namespace的隔离效果过强, 例如, 若想为多个mount namespace挂载同一光盘, 需在每个mount namespace中执行相同挂载操作, 因此Linxu 2.6.15引入了shared subtree, 该功能允许mount/unmount event在不同mount namespace之间传播(更准确的说法是, mount/unmount event在一个peer group中传播).
在shared subtree中, 每个mount point都携带一个propagation type(调用mount()), propagation type决定该mount point下面(immediately under this mount)的mount/unmount event是否传播(例如, /x目录的propagation type决定/x/y上的mount操作是否传播给peer group的其他成员). 以下是四种不同的propagation type:
- MS_SHARED: 该mount point下面的mount/unmount event会传播到同一peer group内的其他mount point(表示peer group的其他mount point会执行相同操作)
- MS_PRIVATE: 该mount point下面的mount/unmount event不会传播到其他mount point, 也不接收任何event
- MS_SLAVE: 介于
MS_SHARED和MS_PRIVATE之间, 该mount point下面的mount/unmount event不会传播到其他mount point, 但他人(shared mount point)的event会传播到自己 - MS_UNBINDABLE: 与
MS_PRIVATE相同, 该mount point下面的mount/unmount event不会传播到其他mount point, 且该mount point不能成为bind mount的目标
以下是shared subtree的总结:
- propagation type的单位为mount point, 一个mount namespace中, 不同mount point可拥有不同的propagation type
- propagation type只决定该mount point下面的mount/unmount event的传播方式
- propagation type不会影响二级目录, 例如,
/x不会决定/x/y/z的传播方式
6.2 peer groups
一个peer group包含多个mount point, 以下是peer group的特性:
- peer group中的mount point发生mount/unmount event时, 该event会传播给其他成员
- 若propagation type为shared, 且满足以下其中一种情况时, peer group会添加新的成员:
- 生成新的mount namespace: 复制的mount point与原本的mount point属于同一peer group
- bind mount一个mount point: 新的mount point与原本的mount point属于同一peer group
- mount point退出peer group的情况如下:
- 显式unmount一个mount point(执行
umount命令) - 隐式unmount一个mount point(由于mount namespace内的进程都中止, mount namespace被删除)
- 显式unmount一个mount point(执行
6.3 mount states
一个mount point可处于以下几种状态之一:
- shared mount: 该状态的mount point属于某个peer group, 例如:
mount --make-shared /mnt
mount --bind /mnt /tmp/mnt和/tmp的propagation type都是shared, 并属于同一个peer group./mnt或/tmp上发生的任何mount/unmount event会传播给对方 - slave mount: 每个slave mount都有一个master mount, slave mount会从master mount接收mount/unmount event, 但不能向master mount传播event. 只有shared mount才能通过以下命令改为slave mount:
mount --make-slave mount_point
- shared and slave: 一个mount既可以是shared, 也可以是slave, 该状态下的mount可接收master mount传播的event, 并拥有一个peer group, 因此可将event传播给peer group的其他mount. 严格来说, mount的状态仍为shared, 但所在的peer group是另一个peer group的slave. 当slave mount遇到以下其中一种情况时, 才会改为shared-and-slave状态:
- 执行
mount --make-shared mount - 将slave mount移动到shared mount下面
- 执行
- private mount: 不接收也不传播任何mount/unmount event
- unbindable mount: 不接收也不传播任何mount/unmount event, 也不能作为bind mount目标
以下是mount point的状态转换图:
| make-shared | make-slave | make-private | make-unbindable | |
|---|---|---|---|---|
| shared | shared | 若该mount是peer group的唯一mount, 则为private; 否则为slave | private | unbindable |
| slave | shared-and-slave | slave | private | unbindable |
| shared-and-slave | shared-and-slave | slave | private | unbindable |
| private | shared | private | private | unbindable |
| unbindable | shared | unbindable | private | unbindable |
6.4 example
假设shell运行在最初的mount namespace, 并创建一个private mount point和两个shared mount point:
sh1# mount --make-private / |
另外一个shell中, 使用unshare命令创建一个新的mount namespace:
sh2# unshare -m --propagation unchanged sh |
回到第一个shell, 创建/x mount point的bind mount:
sh1# mkdir /Z |

上图中存在两个peer group:
- 第一个peer group包含
X,X'(创建第二个mount namespace时复制X)和Z(bind mountX创建) - 第二个peer group包含
Y和Y'(创建第二个mount namespace时复制Y)
Z由bind mount创建, 但由于parent mount point /的propagation type为private, 因此没有复制到第二个mount namespace.
7. network namespace
Network namespace负责隔离网络相关的系统资源, 例如: 网络设备, IPv4和IPv6 protocol stack, IP routing table, firewall rules, /proc/net目录(proc/[pid]/net的symbolic link), /sys/class/net目录, /proc/sys/net目录, port number(socket)等.
一个物理设备只能存在于一个network namespace中, 可通过veth pair(虚拟网络设备对)在两个network space间创建通道并通信.
物理网路设备一开始分配在initial network namespace(系统默认的network namespace), 但若存在多块物理网卡, 可将其中一块或多块分配给新创建的network namespace; 当network namespace被删除时(该network namespace中的所有进程都中止, 且network namespace的文件没有被挂载或打开), 则该network namespace的物理网卡会回到initial network namespace, 而非最后进程的父进程.
7.1 veth
veth device全称virtual Ethernet device(虚拟以太网设备), 其作为两个network namespace的桥梁, 可让两个network namespace内的网络设备彼此交流.
veth device总是成对出现(pair), 创建veth pair的命令如下:
# ip link add <p1-name> type veth peer name <p2-name> |
<p1-name>和<p2-name>为两个veth device的自定义名称, 可将一个veth device想象成一根网线, 一端连接另一个veth device, 另一端连接一个network namespace. 首先创建一对veth pair(一个veth device名为veth0, 另一个veth device名为veth1):
root@ubuntu:/# ip link add veth0 type veth peer name veth1 |
再创建两个network namespace(名为ns0和ns1), 并设置两个network namespace的IP address(ns0为10.0.0.1, ns1为10.0.0.2):
root@ubuntu:/# ip netns add ns0 |
将veth0和veth1放入ns0和ns1中, 并启动veth device:
root@ubuntu:/# ip link set veth0 netns ns0 |
设置ns0和ns1的IP address:
root@ubuntu:/# ip netns exec ns0 ip addr add 10.0.0.1/24 dev veth0 |
查看ns0的routing table:
root@ubuntu:/# ip netns exec ns0 route -n |
最后测试ns0和ns1是否连通:
root@ubuntu:/# ip netns exec ns0 ping 10.0.0.2 |
7.2 pipe
启动Docker时, 会在主机上创建一个名为docker0的virtual bridge(虚拟网桥), 该主机上的container会连接到docker0, 使得所有container通过网桥连接到一起.
Docker daemon启动一个container时, 会创建一个veth pair, 将一端绑定到docker0网桥上, 另一端接入新建的network namespace(默认为eth0). 连接期间, Docker daemon与container初始化进程通过pipe进行通信: Docker daemon完成veth pair的创建前, container的初始化进程在pipe的另一端等待, 直到收到veth device的信息; 收到后, 初始化进程会关闭管道, 并启动eth0, 如下图: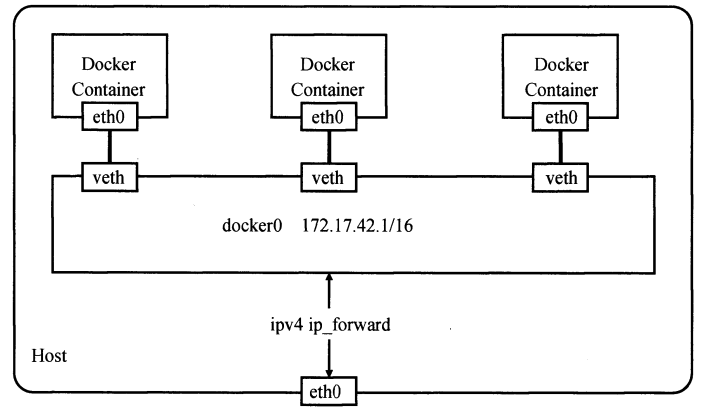
8. user namespace
User namespace用于隔离安全相关的标识符和属性, 包括user ID, group ID, root目录, key(密钥), 以及特殊权限. 一个进程只能存在于一个user namespace内, 但将一个user namespace的进程的user ID或group ID映射到另一个user namespace的进程. 通常情况下, 新建的user namespace的进程为root(该进程拥有所有权限), 并映射到外部user namesapce中的一个unprivileged user ID. 该技术给container极大的操作自由.
因此, container中的root并不代表container所在主机的root, 可能是一个普通用户. 以下代码用于展示user namespace中进程的user ID与其权限:
|
执行上述代码前, 先查看主机上当前进程UID和GID:
jason@ubuntu:/code$ id -u |
执行代码后, 结果如下:
jason@ubuntu:/code$ gcc userns.c -lcap -Wall -o userns.o && ./userns.o |
- 在新建的user namespace中, 进程的UID和GID均为66534. 新建的user namespace不与任何user namespace的进程建立映射, 因此会将user ID/group ID设置为overflow user/group ID, 该值通常保存在
/proc/sys/kernel/overflowuid capabilities: =ep表示进程在新建的user namespace内拥有所有capabilities(权限)
8.1 Nested namespace, namespace membership
User namespace是一个层层嵌套的树状结构: 根节点为initial user namespace(启动系统时创建), 其他user namespace必须拥有一个parent user namespace, 以及零个或多个child user namespace. Linux规定, user namespace最多嵌套32层, 否则返回EUSERS错误.
一个进程只属于一个user namespace, 执行fork()/clone()/unshare()时, 存在以下两种情况:
fork()/clone()不包含CLONE_NEWUSER: child process与parent process同属一个user namespaceclone()/unshare()包含CLONE_NEWUSER: child process(clone())或unshare()调用者创建新的user namespace, 且新的进程属于该user namespace
创建user namespace后, 第一个进程拥有所有权限, 但在parent user namespace中(clone())或之前的user namespace中(unshare())不拥有任何权限 因此container的初始化进程可完成所有工作, 不会出现权限不足的问题.
8.2 Capabilities
以下规则用于判断进程是否在某个user namespace中拥有权限(capability):
- 进程处于该user namespace中, 且拥有对应的权限(effective capability set)
- 若进程在当前user namespace拥有某一项权限, 则其在child user namespace仍保留该权限
- 创建新的user namespace时, kernel会记录创建该user namespace的进程的EUID, parent user namespace中相同EUID的进程在child user namespace中拥有所有权限
需要注意的是, 一个进程在某个user namespace拥有权限, 并不意味着其可以做任何权限允许的事: 每个non-user namespace(如UTS namespace)都有一个关联的user namespace, 当进程访问或修改non-user namespace管理的资源时, 该资源关联的user namespace可能不是进程所在的user namespace.
也有一些资源不归属user namespace管理, 例如: 修改系统时间(CAP_SYS_TIME), 加载某个kernel module(CAP_SYS_MODULE), 或创建一个device(CAP_MKNOD), 上述操作要求进程满足两个条件:
- 进程处于initial user namespace
- 进程拥有响应权限
以UTS namespace为例, 创建一个新的user namesapce, 由于第一个进程拥有所有权限, 理论上可以修改hostname:
jason@ubuntu:/$ unshare -U /bin/bash |
实际上nobody并不能修改hostname, 因此kernel检查权限时, 会按照以下步骤:
- 查看资源所属的non-user namespace: nobody尝试修改hostname, 因此属于UTS namespace
- 查看进程所在的non-user namespace: 进程只创建了新的user namespace, 没有创建新的UTS namespace, 因此进程处于initial UTS namespace(系统启动时创建)
- 查看non-user namespace关联的user namespace: 系统启动时, initial user namespace与其他initial non-user namespace相关联, 因此initial UTS namespace与initial user namespace相关联
- 查看进程是否在user namespace中拥有相应权限: nobody没有initial user namespace中映射的uid和gid, 因此没有权限
8.3 User and group ID mappings
创建新的user namespace时, 不存在与parent user namespace的任何映射user/group ID映射. /proc/[PID]/uid_map和/proc/[PID]/gid_map可实现user/group ID的绑定, 文件格式如下:
ID-inside-ns ID-outside-ns length |
- ID-inside-ns: 表示PID所在user namespace的起始UID/GID
- ID-outside-ns: 表示某个user namespace的起始UID/GID, user namespace的选择取决于写入进程与PID的关系:
- 若写入进程与PID处于同一user namespace, 则
ID-outside-ns为PID的parent user namespace中的UID/GID - 若写入进程与PID处于不同user namespace, 则
ID-outside-ns为写入进程所在的user namespace中的UID/GID
- 若写入进程与PID处于同一user namespace, 则
- length: 表示UID/GID的映射范围, 通常为1. 假设
uid_pid中一行为uid1 uid2 n, 表示[uid1, uid1+n)映射到[uid2, uid2+n)
写入/proc/[PID]/uid_map和/proc/[PID]/gid_map必须满足以下所有条件:
- 写入进程拥有PID所在user namespace的
CAP_SETUID权限 - 写入进程要么处于PID所在的user namespace, 要么处于PID的parent user namespace
- 若映射的uid为parent namespace中的root(0), 则需满足以下其中一种条件:
- 若写入进程处于parent user namespace, 则该进程必须拥有
CAP_SETFCAP权限 - 若写入进程处于child user namespace, 则创建该user namespace的进程需拥有
CAP_SETFCAP权限
- 若写入进程处于parent user namespace, 则该进程必须拥有
- 需满足以下其中一种条件
- 写入
uid_map/gid_map的一行将写入进程的EUID/EGID映射为parent user namespace的user/group ID. 该规则允许新建user namespace的进程将自身映射到parent user namespace. - 若写入进程拥有
CAP_SETUID/CAP_SETGID, 则将parent user namespace的任何user/group ID映射到child user namespace
- 写入
修改后的代码如下:
|
执行后的结果如下:
jason@ubuntu:/code$ gcc userns.c -Wall -lcap -o userns.o && ./userns.o |
可以看到, child user namespace中的进程成为root, 映射的进程uid为1000