ZooKeeper
1. Introduction
ZooKeeper是一个分布式开源协调服务(coordination service), 服务于各种分布式应用(Distributed Application). 这里存在两个关键点:
- 分布式应用
- 协调服务
明白上述两个关键点, 也就明白ZooKeeper的设计目的, 优缺点, 以及应用场景.
1.1 Distributed Application
分布式系统的定义为: 其组件位于不同的计算机上, 通过网络传递消息, 以此协调彼此的行为. 分布式应用就是运行在分布式系统中的程序. 其出现的主要原因是: 单机处理能力与业务负载的不匹配, 很多业务已经无法在单机上完成(运行效率问题, 地理分布问题, 存储空间问题等), 必须将负载分流到多个节点; 分布式系统还可提供容错性: 单个机器发生故障不会导致整个服务停止运行; 最后, 分布式系统能提供可拓展性: 随着时间推移, 业务负载(可以是用户数, 存储量, 每秒请求数等)也在不断增加, 分布式系统让集群中的节点数与处理能力成正比, 换句话说, 一台机器可以处理一定的吞吐量, 两台计算机就能处理两倍的吞吐量, 无需切分业务或优化性能就能实现增强性能.
但分布式应用并不是没有代价, 其带来了单机中没有的挑战:
- Hardware faults: 单机上的程序要么运行成功, 要么失败, 一旦单机出现硬件问题, 更倾向于直接宕机; 分布式系统则会出现许多意想不到的硬件故障, 且这些故障通常只会影响一个或多个机器.
- Unreliable Networks: 由于分布式系统中的机器通过网络通信, 且绝大多数网络没有一个延迟上限保证(消息在一定时间内传达), 发送端在没有收到回复前, 无法知道发生了什么(可能是网络问题, 也可能是接收方宕机).
- Unreliable Clocks: 由于通信不是即时的, 分布式系统中无法拥有统一的时钟.
上述挑战会直接导致分布式系统的设计十分复杂:
- Inconsistency: 数据的partial failure(部分失效)
- Race condition: 两个机器同时使用同一资源
- Deadlock: 两个操作等待对方释放资源, 陷入永久等待
1.2 Coordination Service
分布式系统中的很多问题在于: 集群中节点无法对某件事达成共识, 如: 单leader复制中, 所有节点都必须承认某个节点成为leader; 否则, 集群中会出现两个leader, 导致脑裂.
ZooKeeper就是为此而生, 其作为集群的一个服务, 让所有节点都对某个事件达成一致. 从功能上看, ZooKeeper提供了一个key-value存储服务, 任何节点都可以读取或写入数据.
2. Design Goals and Guarantees
ZooKeeper的设计目的如下:
- ZooKeeper is simple: 其允许分布式应用通过共享hierarchical namespace(分层命名空间)相互协调. ZooKeeper将数据保存在内存中, 以实现高吞吐量和低延迟.
- ZooKeeper is replicated: 作为分布式系统的协调服务, 必须保证高可用性, 因此其本身也由一组机器构成, 只要大多数机器存活, ZooKeeper就能提供服务.
- ZooKeeper is ordered: 其会为每次更新操作分配一个数字, 来表示所有事务顺序
- ZooKeeper is fast: 若大部分操作都是读取, 其运行效率会十分快.
为实现上述目标, ZooKeeper需提供一些保证:
- Sequential Consistency(顺序一致性): 客户端的请求顺序与处理顺序一致
- Atomicity(原子性): 更新要么成功, 要么失败, 不存在部分结果
- Single System Image(单一视图): 无论客户端连接到哪一个服务器, 都会看到相同数据. 也就是说, 一旦客户端看到新数据, 就不会再看到旧数据
- Reliability(可靠性): 一旦完成更新, 该更新会一直存在, 直到下一次更新覆盖本次更新
- Timeliness(时效性): 客户端看到的视图在一定时间范围内是最新的
3. Consistency
ZooKeeper使用Sequential Consistency作为其Consistency Model(一致性模型), 但分布式系统中还存在其他一致性模型.
3.1 What is Consistency
当多个进程读写共享数据时, 一旦数据涉及replication(复制)和caching(缓存), 就会出现一致性问题.
为追求容错性与高性能, 分布式系统中存在大量共享数据, 每个节点都有自己的数据副本, 也可自行处理用户请求. 然而, 数据不一致会导致业务层面出现很多意想不到的问题, 例如, 两个用户向不同服务器预定同一班次飞机的同一个座位, 由于两个服务器的数据并非一致, 可能导致两个用户都预定成功.
因此, 当某个节点更新数据时, 其他节点需以某种方式保持同步. 然而, 数据同步的方式有很多: 越严格的同步要求, 对性能影响越大; 反之, 对性能影响越小. 我们需要一套模型来理解和分析数据同步(也称为数据复制)中的问题和基本假设.
3.2 What is Consistency Model
一致性模型的定义为: 进程(应用)与数据存储的约定, 换句话说, 进程有了某种数据同步的保证(进程对数据的读写操作是可预期的). 虽然存在各种一致性模型, 但它们之间的区别主要在于两点:
- 对于读取到旧数据的容忍程度
- 数据副本的写入顺序
4. Consistency Models
以下一致性模型对数据一致性的要求依次降低.
4.1 Strict Consistency
严格一致性, 最严格的一致性模型, 所有事务遵循一个total order(全序), 也就是说, 所有事务都按照一个全局时间顺序执行. 该一致性模型具备以下属性:
- 事务未完成时, 其包含的所有写入都不可读
- 一旦读取到新值, 之后的所有读取都会获得该值(直到下次写入)
该一致性模型的优点在于, 事务的正确性得到保证; 但缺点在于, 读写操作的延迟变得十分高
4.2 Linearizability
线性一致性, 也称为atomic consistency(原子一致性), 或strong consistency(强一致性), 所有读写操作遵循一个全序, 也就是说, 当某个写入成功执行, 之后的读取都会读取到新值. 但与strict consistency不同, 线性一致性的执行单元是单个读写操作, 而不是事务.
该一致性模型的优点在于, 很容易推导操作的正确性; 缺点在于, 读写操作的延迟较高.
4.3 Sequential Consistency
顺序一致性, 单个进程内的读写操作遵循一个全序, 也就是说, 当进程成功写入后, 该进程之后的读取一定读取到新值. 与linearizability不同, 顺序一致性中的跨进程的操作之间没有顺序关系.
该一致性模型的优点在于, 比上述两种一致性模型更加灵活; 缺点在于, 系统中存在多种执行顺序的组合
4.4 Causal Consistency
因果一致性, 所有因果相关的操作遵循一个全序, 也就是说, 所有进程看到的因果相关的操作都遵循相同顺序. 与sequential consistency相比有两点不同:
- 因果一致性不存在一个全序, 只有因果相关的操作需要排序
- 不同进程中, 无因果相关的操作可能执行顺序不同
该一致性模型的优点在于, 无需为所有操作排序, 即使是单个进程内的操作也无需按顺序执行; 缺点在于, 每个应用都有不同的因果关系, 需对并发操作进行因果判断
4.5 FIFO Consistency
FIFO一致性, 对于单个进程的写入, 其他进程会按照其顺序执行; 但不同进程的写入在其他进程中可能交错执行. 与causal consistency不同, FIFO一致性不关心不同进程的写入是否存在任何关系.
4.6 Eventual Consistency
最终一致性, 若没有写入, 所有数据副本会在一段时间后完成同步, 也就是说, 当用户写入后立即读取, 有可能读取到旧值; 但等待一段时间后, 还是能读取到新值. Eventual并没有一个确切的等待上限, 实际运行的系统需提供一个时间范围.
该一致性模型的优点在于, 拥有极高的性能与可用性; 缺点在于, 没有任何数据新鲜度保证
5. Data model and the hierarchical namespace
ZooKeeper的namespace与标准文件系统类似. 节点名由一连串路径构成, 用/分开.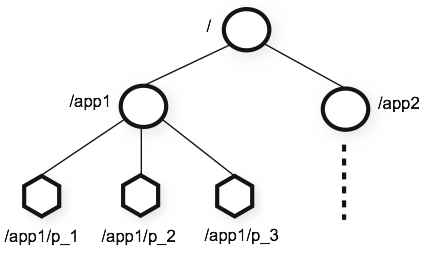
5.1 Nodes and ephemeral nodes
Namespace中的每个节点都有与之关联的数据, 以及子节点. 因此, 其与标准文件系统不同: namespace中的节点可看作一个文件, 也可作为一个文件夹. 每个节点都用于存储协调数据, 如状态信息, 配置, 位置信息. ZooKeeper中的节点一般称为znode.
5.2 Znode
Znode维护一个统计结构, 其中包含数据版本号, ACL更改, 时间戳, 以允许缓存验证和协调更新. 每当znode发生数据更新, 都会自增版本号:
- 当客户端请求更改或删除znode时, 需提供一个版本号, 若版本号不匹配当前znode的版本号, 请求会被拒绝
- 当客户端查询znode时, znode也会传回当前版本号.
ZooKeeper中的znode指数据节点, server(服务器)指组成ZooKeeper服务的机器, quorum peer(法定人数)指组成一个整体的服务器, client(客户端)指任何使用ZooKeeper的进程或主机.
5.3 Data Access
Znode的读写操作是原子性的: 读取会获得全部数据, 写入会覆盖所有数据. 每个znode都有Access Control List(ACL)来控制访问权限.
ZooKeeper客户端和服务器会确保znode的数据小于1M, 相对较大的数据需花费更多时间操作. 如果需要大数据存储, 可将数据放置在NFS或HDFS上, 并在ZooKeeper保存文件位置.
5.4 Ephemeral Nodes
ZooKeeper支持创建ephemeral node(临时节点): 只要创建临时节点的session(会话)处于活动状态, 该节点就会一直存在; 一旦session结束, 该节点会被自动删除. 因此, 临时节点不能拥有子节点, 可使用getEphemerals()来查询某个session的所有临时节点.
6. Time in ZooKeeper
ZooKeeper以多种方式跟踪时间:
- Zxid: 每当ZooKeeper的状态发生变化(写入数据或重新选举), 都会生成新的zxid. 该id表示所有修改的全序: 如果zxid1小于zxid2, 则zxid1发生在zxid1之前.
- Version number: 每当znode发生变化, 都会增加版本号. 以下是znode的三种版本号:
- version: znode的修改次数
- cversion: znode子节点的修改次数
- aversion: ACL的修改次数
- Ticks: 用于在multi-server的ZooKeeper中定义事件间隔时间, 如session超时, 连接超时, 状态上传. 客户端通常不会知道tick, 只有客户端请求的session超时小于最小session超时时间(2倍tick)时, server会告诉客户端最小session超时是多少.
- Real Time: ZooKeeper几乎不用物理时钟时间, 只有创建和修改znode时会将时间戳放入stat结构
7. ZooKeeper Stat Structure
ZooKeeper中每个znode都有一个stat结构, 字段如下:
- czxid: 创建该znode时分配的zxid
- mzxid: 该znode触发数据修改时, 最后一次分配的zxid
- pzxid: 该znode的子节点触发数据修改时, 最后一次分配的zxid
- ctime: 创建该znode的时钟时间(毫秒)
- mtime: 最后一次修改znode的时钟时间(毫秒)
- version: 该znode修改数据的次数
- cversion: 该znode的子节点修改的次数
- aversion: 该znode修改ACL的次数
- ephemeralOwner: 若该znode为临时节点, 该值为该节点会话的session id; 否则该值为0
- dataLength: 该znode的数据长度
- numChildren: 该znode的子节点数量
8. ZooKeeper Sessions
Client通过创建一个Zookeeper handle来与server建立session. Handle是一个client-side的zookeeper应用, 负责创建并维护session, 管理session状态, 向server发送请求, 与从server获取数据等操作. 用户创建handle时提供一个字符串, 以逗号分割, 每个子字符串以host:port的形式表示一个ZooKeeper server. 成功创建handle后, 其状态会切换到CONNECTING; client会尝试与server列表中其中一个server建立TCP连接, 建立完毕后client与server开始交换数据:
- client向server发送一个请求, 其中包含session的超时时长; 若client想恢复之前的session, 则还会包含session ID和密码
- server回复client最终协商的超时时长, 如果是新的session, 还会包含一个64-bits的session ID, 以及session密码
client收到回复后将其状态切换到CONNECTED; 若中途发生错误, 如session超时, 身份验证失败, 或client被关闭, 会切换到CLOSED状态. 每当client需要与server重新创建session时, 都需要上传自己的session id和密码. 以下是客户端的状态变换图: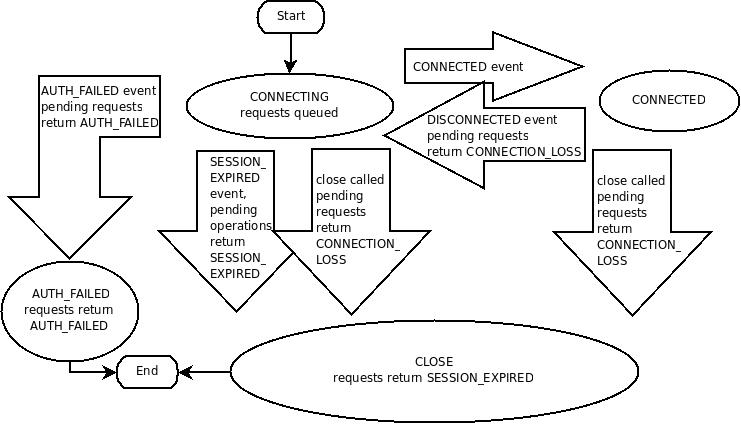
当client与server断开连接时, 其会自动搜索session创建期间指定的server列表. 当客户端最终与某个server重新连接时, 有两种可能:
- session重新回到CONNECTED状态
- session超时, 切换到EXPIRED状态
不建议断开连接后创建新的session, 因为ZooKeeper客户端会自动重连, 只有收到session超时提醒时才需要创建新的session.
Session超时由ZooKeeper集群管理, 不由客户端管理. 当客户端与集群建立session时, 会提供一个超时时间, 若客户端在该时间内没有发送心跳包, 则集群认为session过期, 集群会删除该session创建的所有临时节点, 并立即通知正在查看这些节点的客户端; 由于客户端已经断开连接, 只有等重新连接时, watcher才能收到session expired通知. 以下是客户端收到"session expired"的过程:
- 成功创建session, 客户端与集群正常通信
- 客户端与集群失去连接
- 集群检测到session超时, 但客户端仍没有连接到集群
- 客户端最终重连到集群
- 客户端收到"session expired"通知
Client的任何状态变更以event的形式通知注册的watcher:
- client与server之间出现网络波动时, watcher会收到
DISCONNECTEDevent - 若client与server失去通信超过一段时间, watcher会收到
Expiredevent. - 当创建新连接时, watcher收到的第一个event通常是
SyncConnected.
若client和server之间没有数据传输, client会向server发送与一个PING请求来维持session存活. PING请求不仅让server知道client仍然存活, 也让client知道server处于活跃状态. 一旦成功与server建立连接, client会在以下两种情况下抛出ConnectionLossException(C语言中返回结果码, Java抛出异常):
- 应用程序在死亡/无效的session上进行操作
- 当server有挂起的操作时, 客户端与服务器断开连接
9. ZooKeeper Watches
ZooKeeper客户端可通过watch机制来订阅服务器中某个节点的数据变化或状态变化, 并在变化时收到响应通知.
new ZooKeeper(String connectString, int sessionTimeout, Watcher watcher); |
Watcher将作为当前session的defaultWatcher. 客户端通过读取操作(getData(), getChildren(), exists())向服务器注册watch.
Watch具备以下属性:
- 单次触发: 一旦watch被触发, 服务器端会将其移除. 例如, 客户端请求
getData("/znode1", true), 之后/znode1的数据被修改, 客户端会收到通知; 但若/znode1再次被修改, 客户端不会任何通知. - 串行执行: 客户端在收到watch通知前, 不会看到被修改的数据. 网络延迟和其他原因会导致不同客户端在不同时间点接收到watch通知, 但每个客户端看到的视图是一致的.
- 轻量: 客户端并不会将watcher发送给服务器, watch的具体状态保存在客户端中; 只有客户端连接的服务器负责监视节点, 不会同步到集群; 服务器不会告诉客户端数据具体修改了哪些部分.
getData()和exists()用于监视节点, getChildren()用于监视子节点. 客户端可以监视一个还未创建的节点, create()会触发该watch和其父节点的watch; delete()会触发被删除节点的watch和其子节点的watch.
Watcher包含一个回调函数(void process(WatchedEvent event);), 客户端可重写该函数来处理通知, WatchedEvent包含以下内容:
- keeperState: 通知状态, 如Disconnected, SyncConnected, AuthFailed, Expired, Closed等
- eventType: 通知类型, 如None, NodeCreated, NodeDeleted, NodeDataChanged, NodeChildrenChanged等
- path: 节点路径
当节点发生变更时, 服务器并不会向该节点上所有设置watch的客户端发送通知, watch的触发取决于session的连接状态(state)和watch的事件类型(event). 以下是客户端断开连接的情况:
- 若客户端网络中断, 或服务器宕机, 客户端检测到距离上次收到服务器回复超过一定时间, 会触发SessionTimeoutException, 并会向所有watch添加Disconnected通知.
- 客户端尝试重新连接, 调用
HostProvider的next()获取一个服务器地址:- 若在session过期前连接到上一个服务器, watch正常触发
- 若在session过期前连接到新的服务器, 由于所有服务器共享session, 但不共享watch, 因此会在新的服务器上注册所有watch
- session过期, 服务器返回
session expired, 客户端放弃当前session的所有watch, 并自动开启新的session
使用watch时需注意几点:
- 由于单次触发的属性, 收到通知和再次注册watch之间有一定时间差, 需先注册watch, 再获取变更的节点数据/信息, 这样可确保不会丢失最新的变更.
- 服务器的watch通知发送后不会缓存, 也不能确保一定抵达客户端
- 某种特殊情况下watch可能会丢失: 对于未创建的znode的exist watch, 若客户端断开连接期间创建了该节点, 且在重新连接前被删除, 该watch事件会丢失
- 一个watch对象只会被通知一次: 例如, 某个watch对象在
exists()和getData()中对同一文件监视, 之后该文件被删除, watch对象只会收到一次文件被删除的通知。
10. Details of Design
10.1 Zookeeper session
Zookeeper其中一个设计重点是如何维护client与zookeeper集群之间持久且容错的连接, 这就涉及到以下问题:
- client如何判断与集群的连接是否已断开
- client与集群的连接断开后, 集群如何处理ephemeral node
- 如何保持server顺序执行client发送的请求
Zookeeper的解决方案是在TCP session的基础上额外维护一个session, 以下是Zookeeper session和TCP session的区别:
- Network level: TCP在传输层; Zookeeper session在应用层
- Scope: TCP session只覆盖client与当前server的连接; Zookeeper session维护client与整个Zookeeper集群的连接
- Resilience: TCP session会在当前server连接中断时终止; Zookeeper session会在client与当前server断开连接后尝试与其他server创建连接
- Timeout: TCP session的超时由TCP/IP栈配置决定; Zookeeper session的超时则是由application和server协商所得
Zookeeper session解决了以下问题:
- 当TCP连接断开时, zookeeper session仍会保持active状态. Client会自动尝试与集群中的其他server建立连接, 只要在超时前与其他server成功创建连接, 则session不会终止.
- Zookeeper session是ephemeral node的管理者, 只有当session超时失效时才会删除ephemeral node
- 尽管TCP自带心跳机制, 但Zookeeper session仍然设计了自己的心跳机制: 从client的角度来说, 与当前server断开连接并不意味着与整个集群断开连接, server会在session超时前尝试与其他server建立连接; 从zookeeper cluster的角度出发, 每当一个server收到心跳包后会将其加入到
expiry queue中, session超时失效后移除ephemeral node - TCP连接只能保证client与当前server的数据包传输顺序一致; 由于一个session中client可能会与多个server创建连接, 因此zookeeper session需保证session的所有请求都遵循FIFO顺序