HDFS Recovery Process
HDFS最重要的设计目的之一是容错性. HDFS应保证, 无论出现节点故障还是网络故障, 写入都能正确执行. HDFS为此设计了一系列方案: lease恢复, block恢复, pipeline恢复.
1. Background
在HDFS中, 文件被拆分为多个block, 遵循单写入, 多读取语义. 为了容错性, block需备份到多个datanode上. block的副本数称为replication factor(复制因子). 当创建文件, 或追加文件时, HDFS会在多个datanode间创建pipeline, 上游datanode将block传递给下游datanode, 复制因子决定了pipeline的数量. 每个datatnode会周期性(默认一小时)向namenode汇报自己拥有的block, 并定时向namenode发送心跳(默认3秒)来证明自身存活, namenode超过一段时间(默认10分钟)收不到心跳, 则认为datanode死亡, 不会将请求交给该datanode.
心跳除了证明datanode存活, namenode还会通过心跳将命令传回给datanode, 因此心跳的间隔比较短.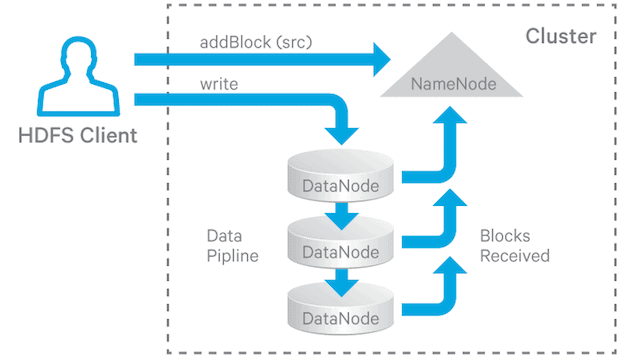
2. Failures in HDFS
HDFS在写入过程中会遇到以下三种故障:
- 写入时, 客户端发生故障
- 写入时, datanode发生故障
- 写入时, namenode发生故障
为此HDFS也有三种恢复方案:
- Lease recovery: 客户端写入文件前, 必须先获得一个lease. lease可看作一个锁, 确保当前只有一个客户端写入. 客户端必须在lease过期前续约. 当client发生故障后, lease会在一段时间后过期, HDFS会关闭文件并释放该lease, 允许其他客户端写入.
- Block recovery: 当客户端发生故障时, 写入的最后一个block很可能没有写完, 为保证该block的每个replica都有相同的长度, 需在lease recovery完成后进行block recovery, 来确保所有replica一致.
- pipeline recovery: 若datanode发生故障, HDFS会尝试修复该错误: 将该datanode从集群中剔除, 并将数据写入其他datanode, 这一过程称为pipeline recovery. 如果其他datanode也写入失败, 则本地写入失败.
若namenode发生故障, 并不会影响客户端向datanode写数据, 因为namenode已经完成了datanode的分配, 且之后都无法写入. 当datanode向定期namenode汇报其状态, 但如果namenode不回复, datanode也会继续工作; 但客户端向namenode请求关闭文件时会报错, 需要人工介入恢复
3. Generation Stamp
Generation Stamp(简称为GS)是一个8字节长的数字, namenode会为每个replica维护一个GS, GS主要有两个设计目的:
- 检测陈旧的replica: 同一个block中, 某个replica没有执行追加操作, 该replica的GS会小于其他replica
- 检测过期的replica: datanode重启后加入集群
发生以下情况时, 会创建新的GS:
- 创建新文件
- 对文件进行追加或截断
- 客户端写入数据时遇到错误
- NameNode为某个文件启动lease recovery
4. Blocks, Replicas, and Their States
为区分namenode中的block和datanode中的block, 我们将前者称为block, 后者称为replica.
4.1 Replica States
Datanode将replica的状态保存在磁盘中, replica的所有状态如下:
- FINALIZED: 表示replica已经完成写入, 不会再做任何修改(本次写入中), 且与同一block的其他replica拥有相同数据(校验)和GS.
- RBW(Replica Being Written): 表示replica正在被写入(创建/追加文件). 该replica一定是文件的最后一个block; 该replica可被读取; 发生故障时, datanode会尽量保留该replica中的数据.
- RWR(Replica Waiting to be Recovered): 当datanode发生故障并重启后, 所有RBW replica都会变为该状态. 该状态的replica要么因为过期而被抛弃, 要么进行lease recovery.
- TEMPORARY: 表示replica是因集群平衡而创建的. 由于文件被不断添加和删除, 集群中每个datanode拥有的数据会愈发失衡. 该状态的replica不会被读取; datanode崩溃并恢复后, 该replica会被直接删除, 不会进行任何修复.
- RUR(Replica Under Recovery): 表示replica正处于恢复过程.
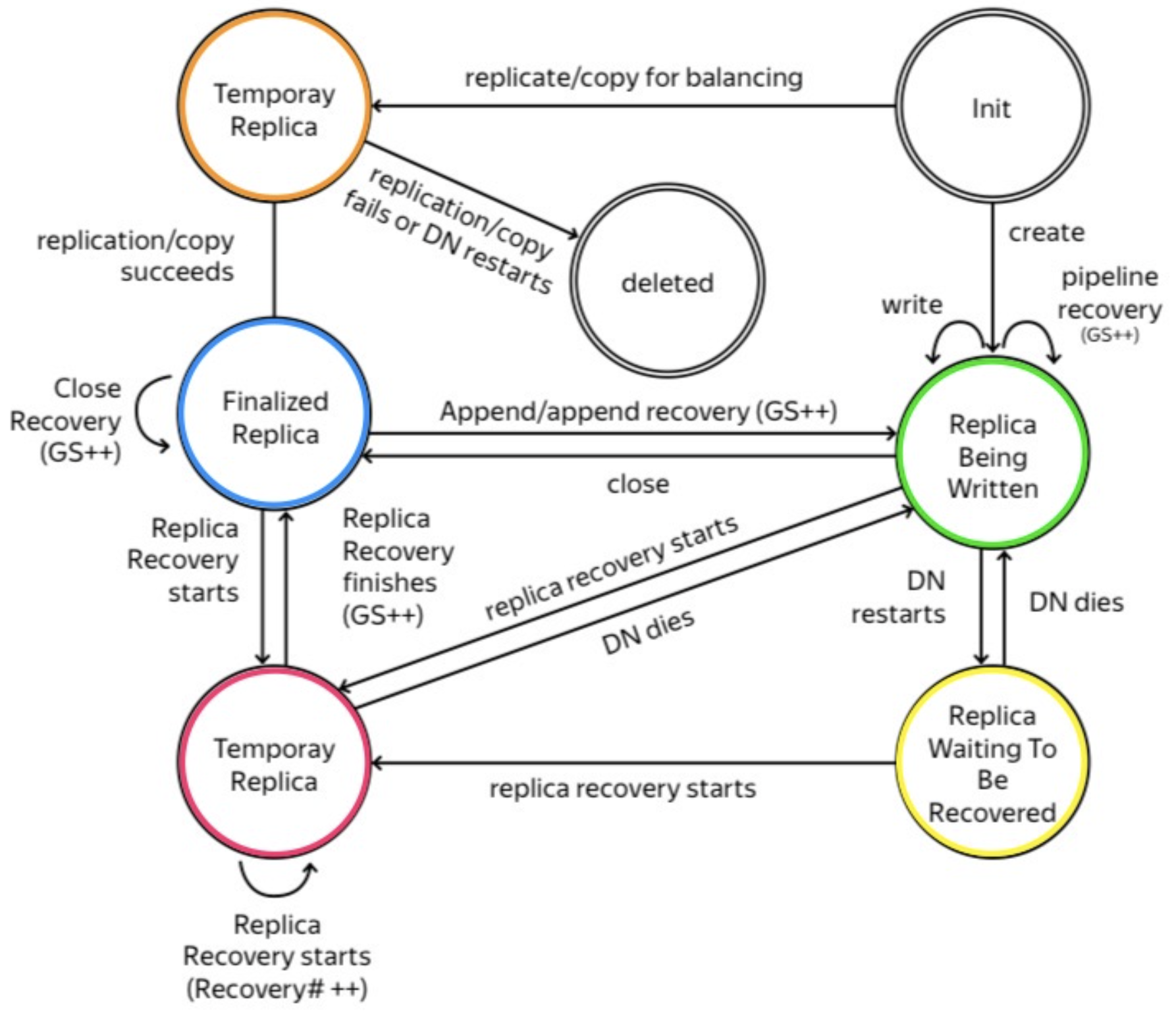
以下为replica的状态变换路线:
- 新建replica:
- 由客户端请求, 新建的replica用于保存文件, 状态变为
RBW - 由namenode请求, 新建的replica用于集群平衡或备份复制, 状态改为
TEMPORARY
- 由客户端请求, 新建的replica用于保存文件, 状态变为
- 从RBW出发:
- 客户端收到datanode的确认, 所有block都传输完毕, 发送close请求. Datanode收到后改为
FINALIZED - replica所在的datanode重启, 切换到
RWR - replica进行block recovery, 切换到
RUR
- 客户端收到datanode的确认, 所有block都传输完毕, 发送close请求. Datanode收到后改为
- 从TEMPORARY出发:
- 复制或集群平衡成功, 切换到
FINALIZED - 复制或集群平衡失败, 或datanode重启, 删除该replica
- 复制或集群平衡成功, 切换到
- 从RWR出发:
- datanode重启, 状态不变
- replica进行block recovery, 切换到
RUR
- 从RUR出发:
- datanode重启, 切换到
RWR - 恢复完成, 切换到
FINALIZED
- datanode重启, 切换到
- 从FINALIZED出发:
- 文件被打开追加写入, 文件最后一个block的所有replica切换到
RBW - replica进行block recovery, 切换到
RUR
- 文件被打开追加写入, 文件最后一个block的所有replica切换到
4.2 Block States
Namenode将block的状态放在内存中. 当namenode重启时, 会将所有未关闭文件的最后一个block状态改为UNDER_CONSTRUCTION, 其他block设置为COMPLETE. Block的所有状态如下:
- UNDER_CONSTRUCTION: 表示block正在被写入. 该block一定是文件的最后一个正在写入的block. 其长度和GS都是可变的, 且可被读取. 该block会跟踪
RBW replica和RWR replica的位置. - UNDER_RECOVERY: 当客户端的lease过期时, 文件的最后一个block(处于UNDER_CONSTRUCTION状态)将在block recovery进行时切换为该状态.
- COMMITTED: block不再修改(数据和GS都不能修改), 但
FINALIZED replica少于最小副本数. 为处理读请求, 该block必须跟踪RBW replica的位置, 以及FINALIZED replica的长度和GS. 当client向namenode请求添加新的block, 或关闭文件时, UNDER_CONSTRUCTION会变为此状态. - COMPLETE: 当
FINALIZED replica满足最小副本数时, 会切换为此状态. 只有文件中所有block都处于此状态时才能关闭文件.
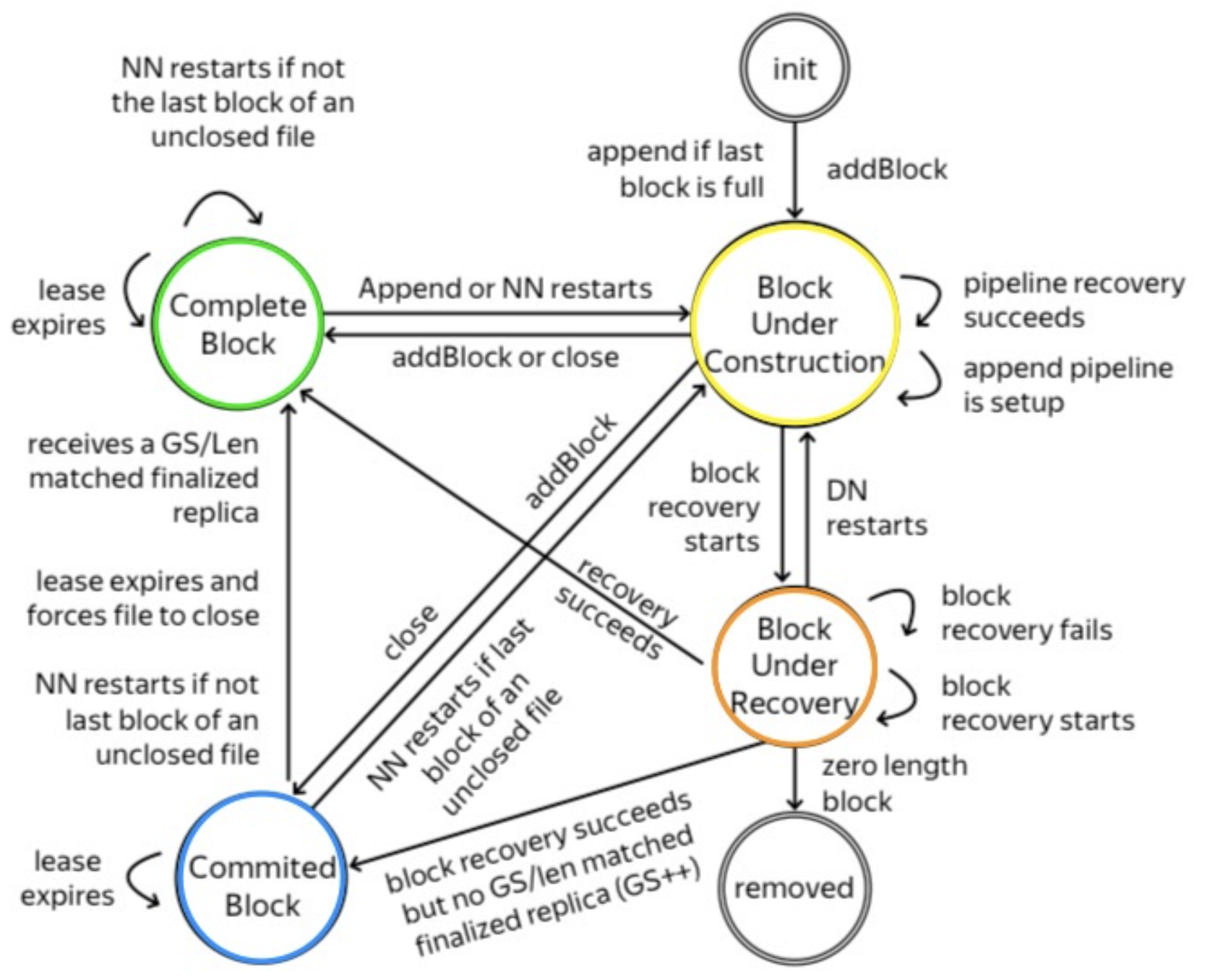
以下为block的状态变换路线:
- 新建文件, 或追加文件, 切换为
UNDER_CONSTRUCTION - 从UNDER_CONSTRUCTION出发:
- 若客户端请求添加新的block, 或关闭文件, 且
FINALIZED replica少于最小副本数, 则切换到COMMITTED - 若客户端请求添加新的block, 或关闭文件, 且
FINALIZED replica达到最小副本数, 则切换到COMPLETE - 若进行block recovery, 则切换到
UNDER_RECOVERY
- 若客户端请求添加新的block, 或关闭文件, 且
- 从UNDER_RECOVERY出发:
- 删除0字节长度的replica
- 恢复成功, 切换到
COMPLETE - NameNode重启, 所有打开文件的最后一个block切换为
UNDER_CONSTRUCTION
- 从COMMITTED出发:
FINALIZED replica达到最小副本数, 或文件被强制关闭, 或NameNode重启且不是最后一个block, 切换为COMPLETE- NameNode重启, 且是文件的最后一个block, 切换为
UNDER_CONSTRUCTION
- 从COMPLETE出发: NameNode重启, 且是文件的最后一个block, 则切换为
UNDER_CONSTRUCTION. 这时若客户端存活, 则由客户端关闭文件, 否则由lease recovery恢复
5. Lease Recovery and Block Recovery
- Lease Recovery: 当前客户端发生故障后, 回收lease以允许其他客户端写入
- Block Recovery: 确保写入的block的所有replica一致
5.1 Lease Manager
NameNode中有一个lease manager, 其负责管理lease. NameNode会跟踪客户端写入的文件, 因此客户端不需要续约时上报所有自己打开的文件, 只需周期性续约(RPC调用namenode的renewLease()), namenode会为其打开的所有文件续约.
Lease manager有两个超时时间: soft limit(1分钟), hard limit(1小时), 且不可修改. 客户端在达到soft limit前拥有独占写入权限; 若达到soft limit, 且另一个客户端请求写入, 则由另一个客户端接管lease. 若检测到超时时间达到hard limit, namenode会强制关闭文件, 并撤销lease.
Lease包含三个部分:
- lease的持有者(String)
- 上次续约时间(long)
- 打开的文件集合(HashSet)
Lease manager包含两个数据结构:
- lease持有者到lease的映射:
HashMap<String, Lease> leases: - INode到lease的映射:
TreeMap<Long, Lease> leasesById
客户端, lease, 和文件的关系如下:
- 一个客户端只能有一个lease
- 一个客户端可打开多个文件
- 一个lease可包含多个文件, 但只能有一个持有者(客户端)
以下是lease manager支持的操作:
- 为某个路径添加一个lease: 若发出请求的客户端已拥有lease, 则将路径添加到该lease(并续约); 否则, 为该客户端创建新的lease, 并将路径添加到该lease
- 删除某个路径的lease: 若该路径是客户端的最后一个路径, 则删除该lease
- 检查超时时间是否达到soft limit和hard limit
- 为某个客户端续约
Lease manager有一个monitor线程, 每2秒检查是否存在lease达到hard limit, 并触发lease recovery.
客户端有一个LeaseRenewer线程, 每30秒让namenode为该客户端(所有打开的文件)续约: namenode端的NameNodeRpcServer接受RPC远程调用, 调用FSNamesystem的LeaseManager为客户端续约.
5.2 Lease Recovery Process
Lease recovery会在以下两种情况下触发:
- NameNode的monitor线程检测到某个客户端的超时时间达到hard limit
- 当前客户端想要写文件或追加文件, 发现上一任客户端的超时时间达到soft limit
Lease recovery会回收lease并关闭文件, 但在关闭文件前, 需确保文件block的replica一致. 由于block是一个个写入, 只有文件的最后一个block存在不一致风险,
假设某个客户端超时时间达到hard limit, 其打开的文件为f, 以下是block recovery的算法流程:
- 获得文件
f中最后一个block所对应的datanode - 指定其中一个datanode作为primary datanode(主导恢复的节点), 假设为
p p从namenode获得一个GSp从其他datanode获得其block信息p计算最小block长度p向其他节点发起更新, 将所有replica更新为最小长度, 并使用新的GSp向namenode报告最终结果- NameNode更新BlockInfo
- NameNode移除
f的lease - NameNode将修改提交到edits
6. Pipeline Recovery
6.1 The Write Pipeline
当客户端写入文件时, 文件会被拆分为多个block, 每个block又被拆分为多个packet, packet通过pipeline传递给datanode. 以下是写入pipeline的过程(假设客户端已从namenode拿到datanode列表):
- Pipeline setup: 客户端调用
createBlockOutputStream(), 与第一个datanode建立pipeline(操作码为WRITE_BLOCK). 假设datanode列表为: A, B, C, 客户端与A建立pipeline, A会尝试与B建立pipeline(writeBlock()), B会尝试和C建立pipeline:client -> A -> B -> C. - Data streaming: 数据通过pipeline以packet的形式传输. 客户端会缓存数据, 直到数据填满一个packet, 之后将packet发送到pipeline. 若客户端调用
hflush(), 即使packet没有填满, 也会发送到pipeline; 只有前一个packet被确认, 客户端才会传输下一个packet. - Close(完成replica并关闭pipeline): 所有packet都被确认后, 客户端会发送close请求. 所有datanode将相应的replica改为
FINALIZED, 并上报给namenode. 如果FINALIZED replica数量满足最小副本数, namenode会将block的状态改为COMPLETE.
6.2 Pipeline Recovery process
当一个或多个datanode在上述任何一个阶段出现故障, 都会启动pipeline recovery.
- Recovery from Pipeline Setup Failure
- 若pipeline是为了添加新文件, 则客户端会重新申请新的block和datanode列表
- 若pipeline是为了追加文件, 则客户端会使用剩余可用的datanode重新建立pipeline, 并增加block的GS
- Recovery from Data Streaming Failure
- 若pipeline中的datanode检测到错误(如校验错误或写入磁盘失败), 该datanode会关闭所有TCP连接, 以此关闭pipeline
- 若client检测到错误, 其会停止向pipeline发送数据, 并为剩余可用的datanode创建新的pipeline, 所有该block的replica都会使用新的GS
- 客户端使用新的GS发送packet. 若datanode之前收到过, 会忽略该packet并传给下游
- Recovery from Close Failure
- 若客户端在close状态下检测到错误, 会使用剩余可用的datanode创建pipeline. 若replica处于
RBW, 则使用新的GS并切换为FINALIZED
- 若客户端在close状态下检测到错误, 会使用剩余可用的datanode创建pipeline. 若replica处于
6.3 DataNode Replacement Policy upon Failure
当datanode出现故障, 客户端需根据datanode replacement policy(datanode替换策略)来决定是否使用剩下可用的datanode创建新的pipeline. HDFS中有两个配置选项可以设置替换策略:
dfs.client.block.write.replace-datanode-on-failure.enable: 默认为true, 若设置为false, 则不替换datanode并抛出错误dfs.client.block.write.replace-datanode-on-failure.policy: 默认为DEFAULT, 假设r为复制数,n为现有的replica数量, 若$r \geq 3$, 且满足以下任意一条, 则添加新的datanode:- $floor(r/2) \geq n$
- $r > n$且block被hflush/append
除了DEFAULT, 还有另外两种选项:
- NEVER: 不替换datanode(与enable=false相同)
- ALWAYS: 当datanode发生故障时, 总会替换新的datanode
dfs.client.block.write.replace-datanode-on-failure.best-effort: 默认为false, 替换失败时抛出错误. 若设置为true, 意味着客户端会尝试替换datanode, 若替换失败, 客户端仍会使用剩余可用的datanode继续写入. 该选项增强了可用性, 但增加了数据丢失的可能.dfs.client.block.write.replace-datanode-on-failure.min-replication: 默认为0, 表示替换失败时抛出错误. 若大于0, 则在替换失败时, 判断剩余可用datanode数量是否满足该选项: 满足则继续写入, 否则抛出错误.