Hardware
1. Pipelined
CPU通常需要五步来执行指令:
- Fetch(从register取出一个32位的指令)
- Decode(指令解码)
- Execute(执行指令)
- Memory Access(需要访问内存时使用, 例如load/store指令)
- Write-back(将运算结果写回register)
为提高CPU的throughput(吞吐量), 运用instruction pipelining(指令管道化)技术来实现instruction-level的平行化. 通过将连续的instruction切分成多个部分来保证CPU的每个部分都在不断运行.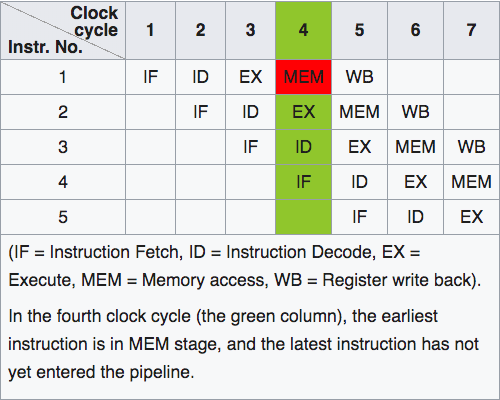
使用instruction pipelining技术通常需要高度可预测的指令流, 例如多次循环和矩阵中的算术运算. 但当指令流无法准确预测时, CPU就需要等待pipeline flush(重新加载新的指令), 例如C++中virtual object所指向的real object就无法预测. 频繁的pipeline flush会极大影响CPU性能.
2. Memory Reference
1980年的CPU从memory读取数据所需时间比处理一条指令时间短, 但如今CPU从内存读取数据所需时间是执行一条指令时间的几千倍, 这得益于Moore's Law(摩尔定律)下CPU性能的指数级提升. 基于Principle of Locality(局部性原理, CPU在一小段时间内倾向于访问一小块内存空间), CPU使用多级cache(体积更小, 访问速度更快的缓存)来减少内存访问的延迟.
3. Atomic Operations
有时thread需要执行一个操作, 该操作在其他thread眼中是瞬间完成的, 不可分割的, 这种操作称为atomic operation(原子操作). atomic operation的优缺点如下:
- 优点:
- 耗时比锁机制短
- 不会出现Dead Lock(死锁)和Lock Convey(锁封护)
- 缺点:
- 只支持部分操作
但从原理来说, atomic operation与CPU pipeline矛盾. 即使一些看似很简单的操作, 其实也无法通过多个指令完成, 例如:
uint64_t sharedValue = 0; |
所以为实现atomic operation, 需要pipeline delayed或pipeline flush, 从而造成CPU性能下降.
4. Memory Barrier
由于CPU的性能优化会导致out-of-order execution(指令乱序执行), 这会导致多线程的并发编程出现意外结果, 例如:
// Processor 1 |
x和f的assignment operation乱序执行会导致print的结果不同, 这时需要memory barrier(内存屏障)来保证CPU按照某种顺序执行, 也必然导致CPU性能下降.
5. Cache Miss
对于单个CPU来说, cache极大地降低了访问内存延迟. 但对于多个CPU来说, 由于每个CPU都有各自的cache, 某个CPU访问的变量可能在其他CPU的cache中, 发生cache miss. 例如: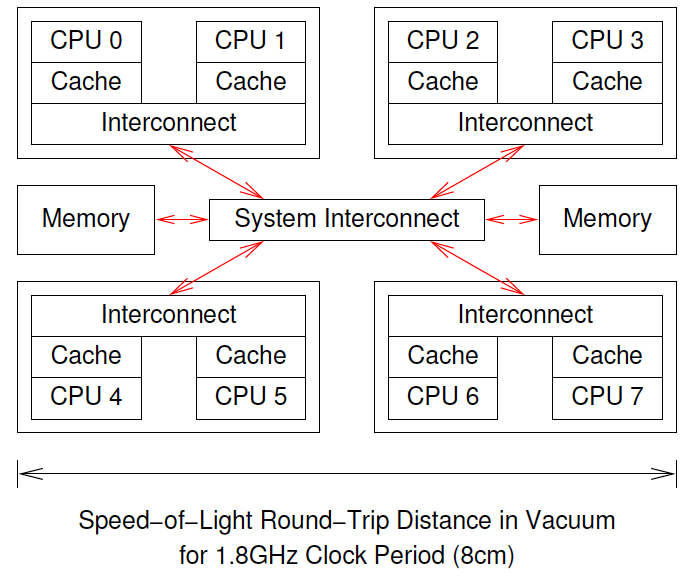
当CPU0想要对CPU7中cache的数据进行CAS operation(compare and swap)时, 必须进行以下步骤:
- CPU0检查自身的cache, 没有找到数据
- 请求被发送到CPU0和CPU1的interconnect, 并未在CPU1的cache中找到数据
- 请求被发送到system interconnect并检查了其他三组CPU, 得知数据在CPU6和CPU7的cache中
- 请求被发送到CPU6和CPU7的interconnect, 得知数据在CPU7的cache中
- CPU7把数据发送给直连的interconnect, 并清除自身数据
- CPU6和CPU7的interconnect将数据传给system interconnect
- System interconnect将数据传给CPU0和CPU1的interconnect
- CPU0和CPU1的interconnect将数据传给CPU0的cache
- CPU0执行CAS操作
6. I/O Operations
I/O operations包括网络, 大容量存储器或人的操作. 这些操作的延迟性也会造成CPU效率降低.
7. Costs of Operations
假设system clock(系统时钟)的周期为0.6ns, 各项操作的开销如下:
| Operation | Cost(ns) | Ratio(cost/clock) |
|---|---|---|
| Clock period | 0.6 | 1.0 |
| Best-case CAS | 37.9 | 63.2 |
| Best-case lock | 65.6 | 109.3 |
| Single cache miss | 139.5 | 232.5 |
| CAS cache miss | 306.0 | 510.0 |
| Comms Fabric | 5,000.0 | 8,330.0 |
| Global Comms | 195,000,000.0 | 325,000,000.0 |
- Best-case CAS: CPU不需要从其他CPU的cache获取数据, 可直接从自身的cache获得数据并进行CAS operation
- Best-case lock: 代表lock的数据结构已经在CPU的cache中, 不会发生cache miss.
- Comms Fabric: 一套系统中不同部件之间的数据交换, 例如infiniband
- Global Comms: 以太网上的数据交换, 更远的物理距离和协议解析