System Design - Key Value Store
1. Introduction
In key-value store(or key-value database), Each unique identifier is stored as a key with its associated value. This data pairing is known as a "key-value" pair.
In a key-value pair, the key must be unique, and the value associated with the key can be accessed through the key. The value can be strings, lists, objects.
Here's some characteristics of key-value store:
- The size of a key-value pair is small
- Ability to store big data.
- High availability: The system responds quickly, even during failures.
- High scalability
- Automatic scaling
- Tunable consistency
- Low latency
2. Single server key-value store
The easist approach: store key-value pair in a hash table.
Two optimizations:
- Data compression
- Store only frequently used data in memeory and rest on disk
3. Distributed key-value store
3.1 CAP theorem
It is impossible for a distributed system to guarantee all of three guarantees:
- Consistency: all clients see the same data at the same time no matter which node they connect to
- Availability: request sent from client always gets a response even if some of the nodes are down
- Partition Tolerance: the system continues to operate despite network partitions
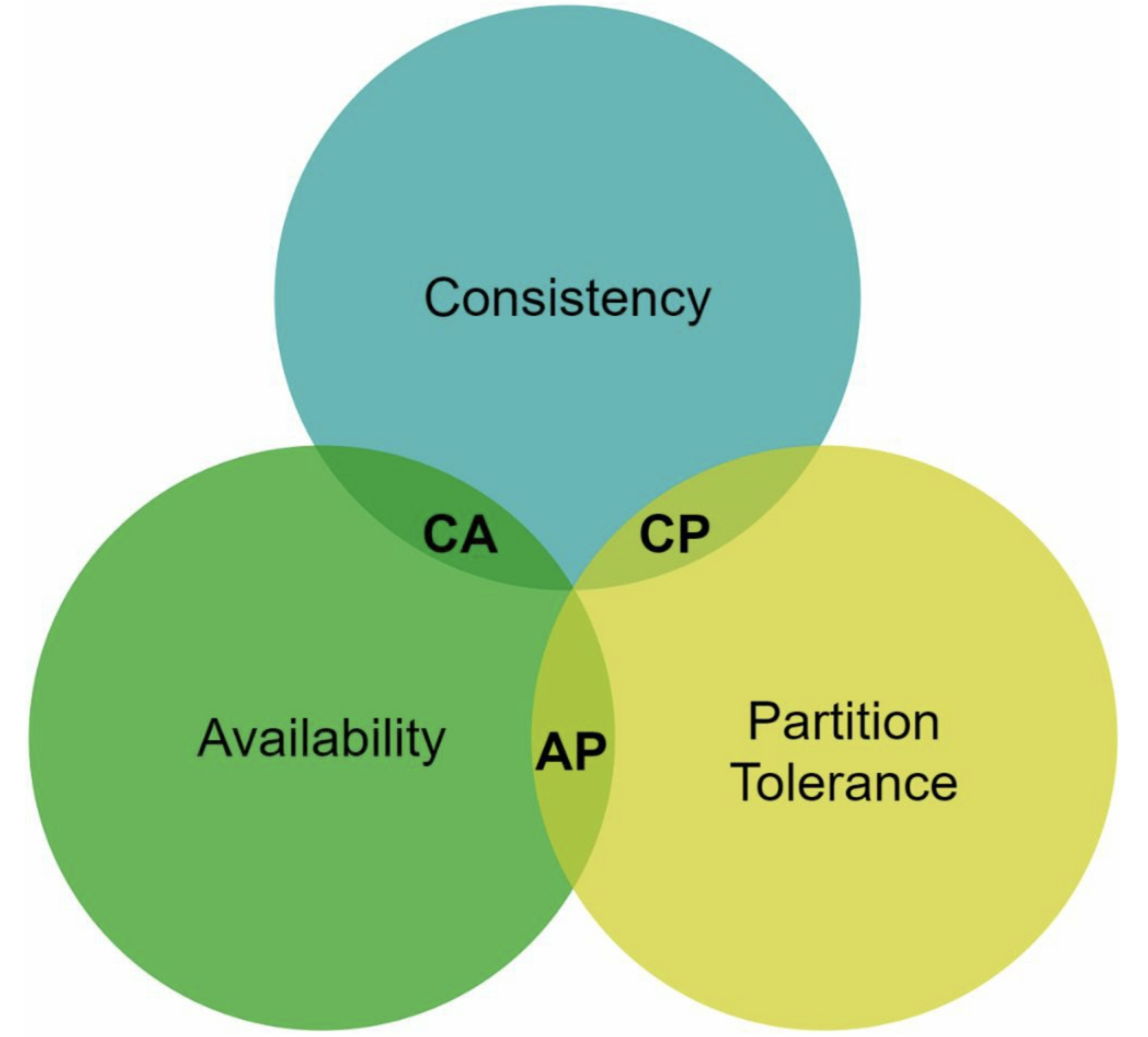
- CP system: supports consistency and partition tolerance, sacrifice availability
- AP system: supports availability and partition tolerance, sacrifice consistency
- CA system: supports consistency and availability, sacrifice partition tolerance
Since network failure is unavoidable, a distributed system must tolerate network partition. Thus, a CA system cannot exist in real-world applications.
3.2 Real-world distributed systems
Since network partition cannot be avoided, we must choose between consistency and availability. Assume we have 3 servers(s1, s2, s3) in a distributed system, and s3 goes down:
- choose consistency: block all write operation on
s1ands2to avoid data inconsistency - choose availability: keep accepting read even
s1ors2returns old data.s1ands2keep accepting writes, and synced tos3when network partition is resolved.
4. System components
4.1 Data partition
Split the data into smaller partitions and store them in multiple servers.
Two challenges:
- Distribute data across multiple servers evenly
- Minimize data movement when nodes are added or removed
Solution: Consistent hashing
Advantages:
- Automatic scaling: servers could be added and removed automatically depending on the load.
- Heterogenrity: the number of virtual nodes for a server is proportional to the server capacity
4.2 Data replication
To achieve high availability and reliability, , data must be replicated asynchronously over N servers: after a key is mapped to a position on the hash ring, walk clockwise from that position and choose the first N servers on the ring.
With virtual nodes, the first N nodes on the ring may be owned by fewer than N physical servers. To avoid this issue, we only choose unique servers while performing the clockwise walk logic. Nodes in the same data center often fail at the same time: replicas should be placed in distinct data centers, and data centers are connected through high-speed networks.
4.3 Consistency
Quorum consensus can guarantee consistency for both read and write operations
- N: The number of replicas
- W: A write quorum. For a successful write operation, write operation must be acknowledged from W replicas.
- R: A read quorum. For a successful read operation, read operation must wait for responses from at least R replicas.
For example, Consider the following example with N = 3.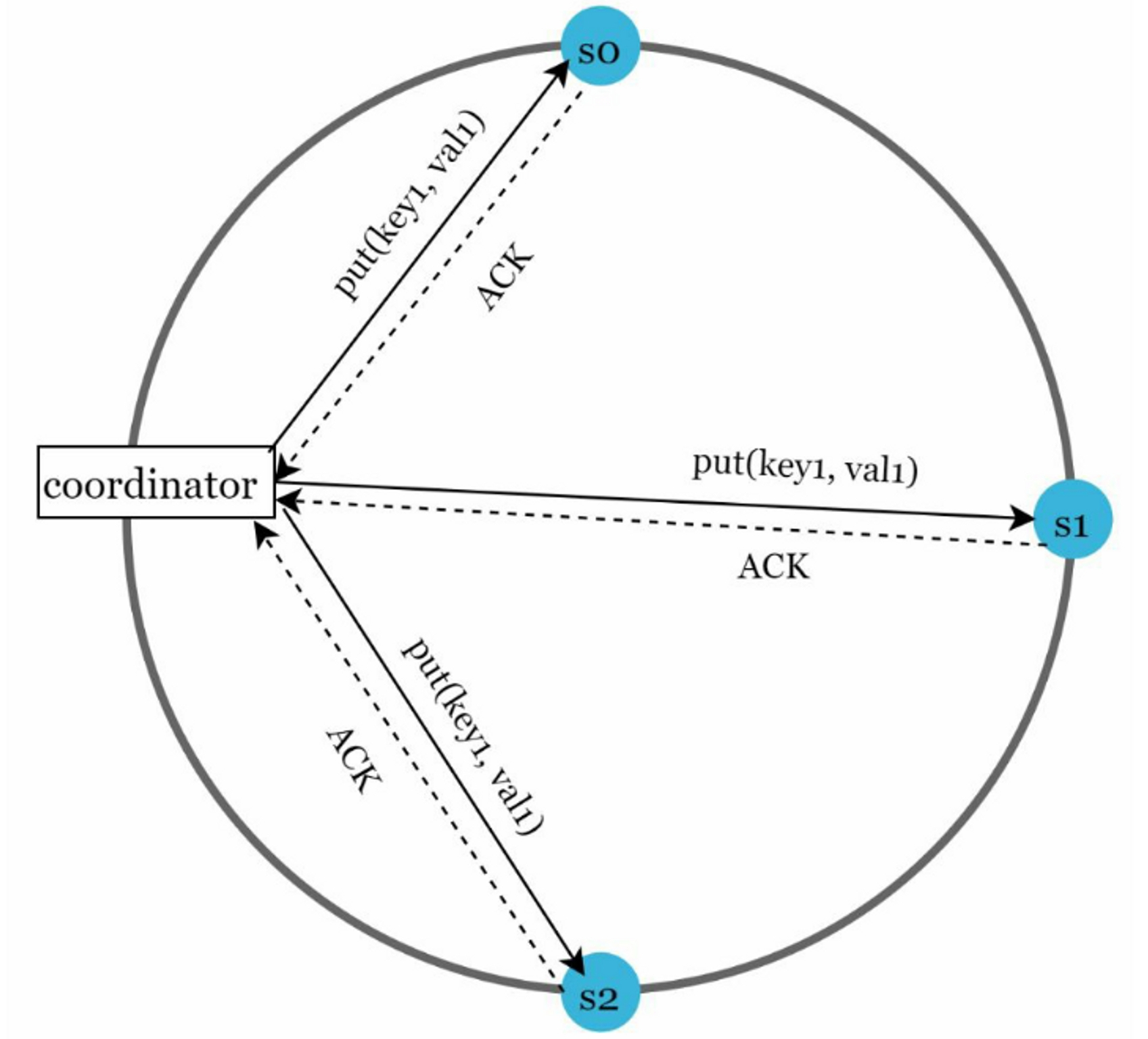
W = 1: the coordinator must receive at least one acknowledgment before the write operation is considered as successful. If we get an acknowledgment from s1, we no longer need to wait for acknowledgements from s0 and s2. A coordinator acts as a proxy between the client and the nodes.
The configuration of W, R and N is a typical tradeoff between latency and consistency:
- W or R = 1: coordinator only needs to wait for a response from any of the replicas, operation is quick but with bad consistency
- W or R > 1: coordinator must wait for the response from the slowest replica, the query will be slower but with better consistency
- W + R > N: strong consistency is guaranteed because there must be at least one overlapping node that has the latest data
- R = 1 and W = N: the system is optimized for fast read
- W = 1 and R = N: the system is optimized for fast write
4.3.1 Consistency models
- Strong consistency: any read operation returns the most updated write data item. A client never sees out-of-date data. It forces a replica not to accept new reads/writes until every replica has agreed on current write, and this approach is not ideal for highly available systems because it could block new operations.
- Weak consistency: read operations may not see the most updated value.
- Eventual consistency: a specific form of weak consistency. Given enough time, all updates are propagated, and all replicas are consistent.
4.3.2 Inconsistency resolution: versioning
Data replication:
- pros: high availability
- cons: inconsistencies among replicas
Solution for inconsistency problem: versioning and vector locks. Versioning means treating each data modification as a new immutable version of data.
An example of how inconsistency happens: Assume we have two servers(s1 and s2), and each server has a replica nodes(n1 and n2): name: john.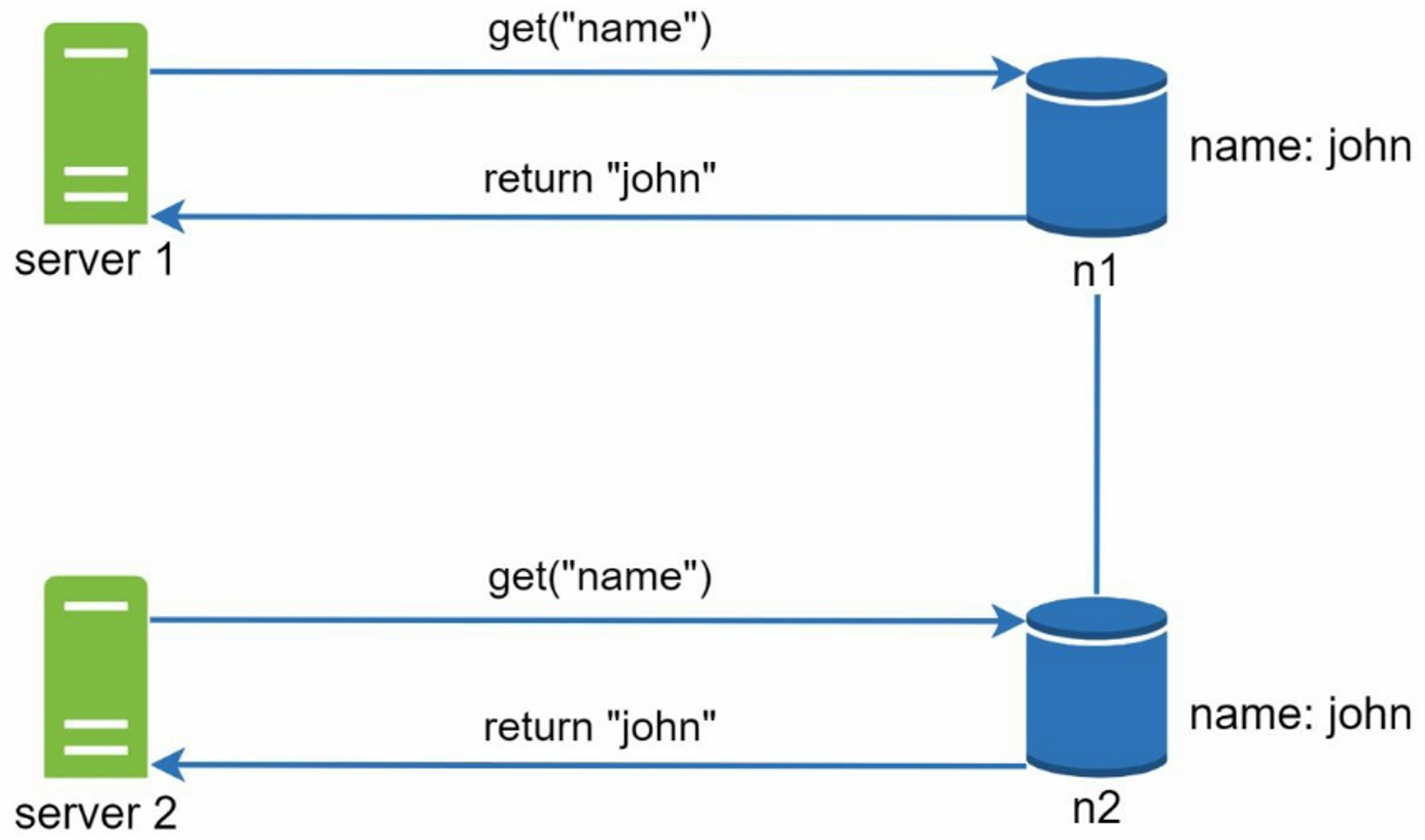
Server 1 changes the name to johnSanFrancisco and server 2 changes the name to johnNewYork. These two changes are performed simultaneously. Now, we have conflicting values, called versions v1 and v2.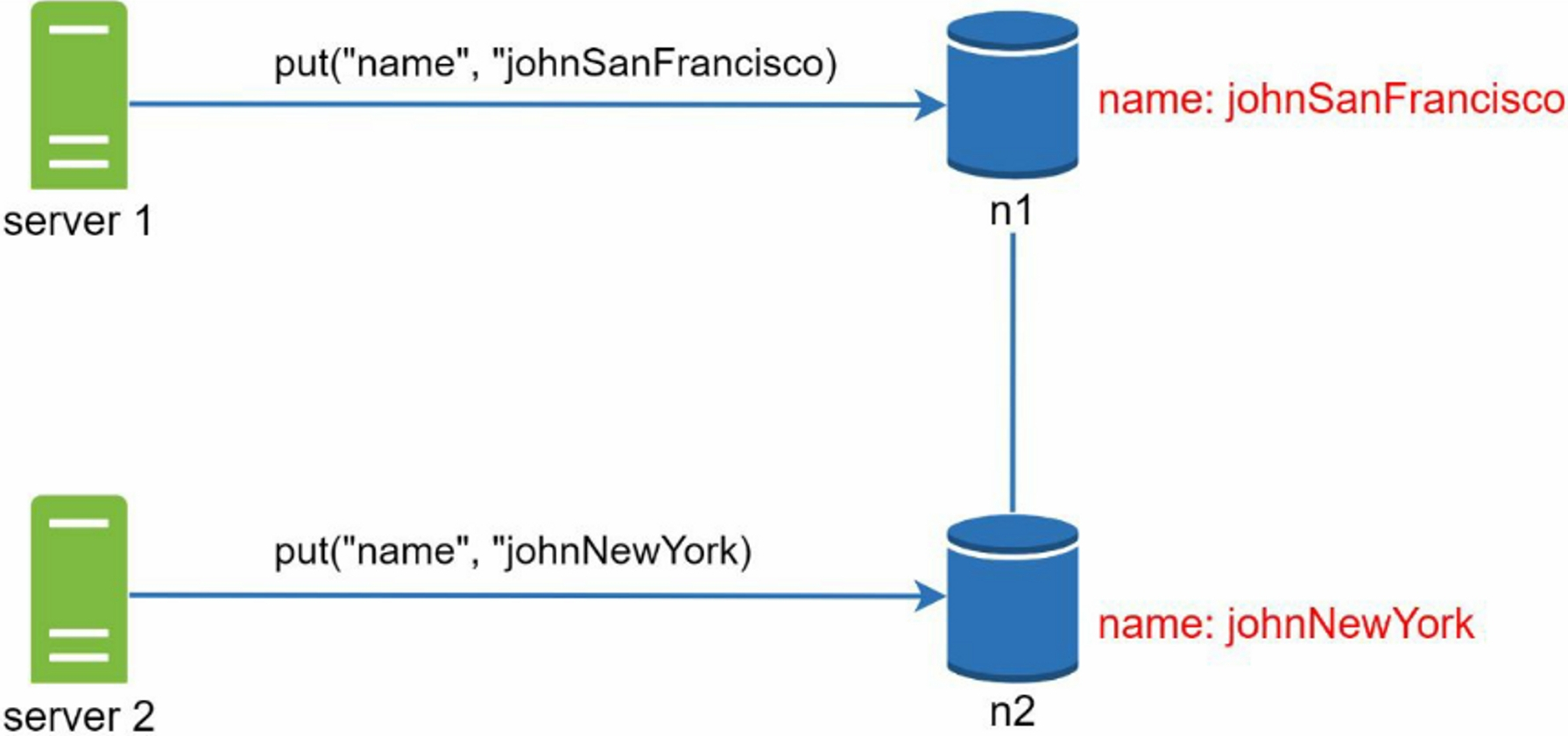
To resolve the conflict of the last two versions, we need a versioning system that can detect conflicts and reconcile conflicts, called vector clock.
A vector clock is a [server, version] pair associated with a data item. It can be used to check if one version precedes, succeeds, or in conflict with others. Assume a vector clock is represented by $D([S_1, v_1], [S_2, v_2], …, [S_n, v_n])$:
D: data item$s_1$: server number$v_1$: version counter
If data item D is written to server $S_i$, the system must perform one of the following tasks:
- Increment
$v_i$if$[S_i, vi]$exists - Otherwise, create a new entry
$[S_i, 1]$
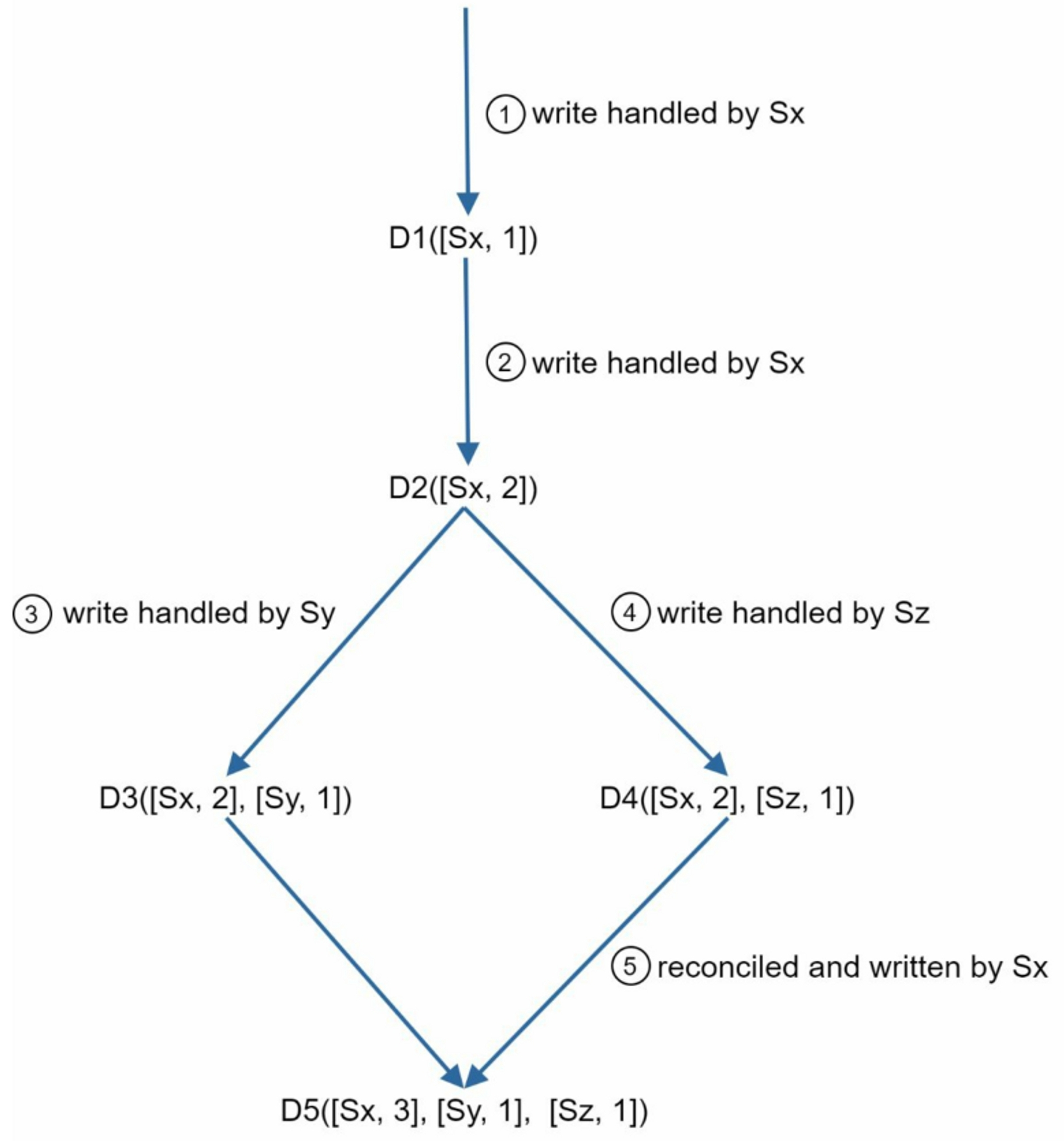
- client writes
D1to the system: the write is handled by serverSx, andSxcreates a vector clockD1[(Sx, 1)]. - Another client reads the latest
D1, updates it toD2, and writes it back. Assume the write is handled by the same serverSx, which now has vector clockD2([Sx, 2]). - Another client reads the latest
D2, updates it toD3, and writes it back. Assume the write is handled by serverSy, which now has vector clockD3([Sx, 2], [Sy, 1]). - Another client reads the latest
D2, updates it toD4, and writes it back. Assume the write is handled by serverSz, which now hasD4([Sx, 2], [Sz, 1]). - When another client reads
D3andD4, it discovers a conflict, which is caused by data item D2 being modified by bothSyandSz. The conflict is resolved by the client and updated data is sent to the server. Assume the write is handled by Sx, which now hasD5([Sx, 3], [Sy, 1], [Sz, 1]).
X is an ancestor of Y (no conflict): the version counters for each participant in the vector clock of Y is greater than or equal to the ones in X. For example, the vector clock D([s0, 1], [s1, 1]) is an ancestor of D([s0, 1], [s1, 2]).
X is a sibling of Y (conflict exists): there is any participant in Y's vector clock who has a counter that is less than its corresponding counter in X. For example, D([s0, 1], [s1, 2]) and D([s0, 2], [s1, 1]).
Downsides:
- vector clocks add complexity to the client because it needs to implement conflict resolution logic
- the
[server: version]pairs in the vector clock could grow rapidly: set a threshold for the length, and if it exceeds the limit, the oldest pairs are removed
4.4 Handling failures
4.4.1 Failure detection
In a distributed system, it's hard to believe to say the other server is down. Easiest approach is all-to-all multicasting, but this is inefficient when many servers are in the system
A better solution is to use decentralized failure detection methods like gossip protocol, works as follows:
- Each node maintains a node membership list, which contains member IDs and heartbeat counters
- Each node periodically increments its heartbeat counter
- Each node periodically sends heartbeats to a set of random nodes, which in turn
propagate to another set of nodes - Once node receive heartbeats, update membership list to the latest
- If the heartbeat has not increased for more than predefined periods, the member is considered as offline
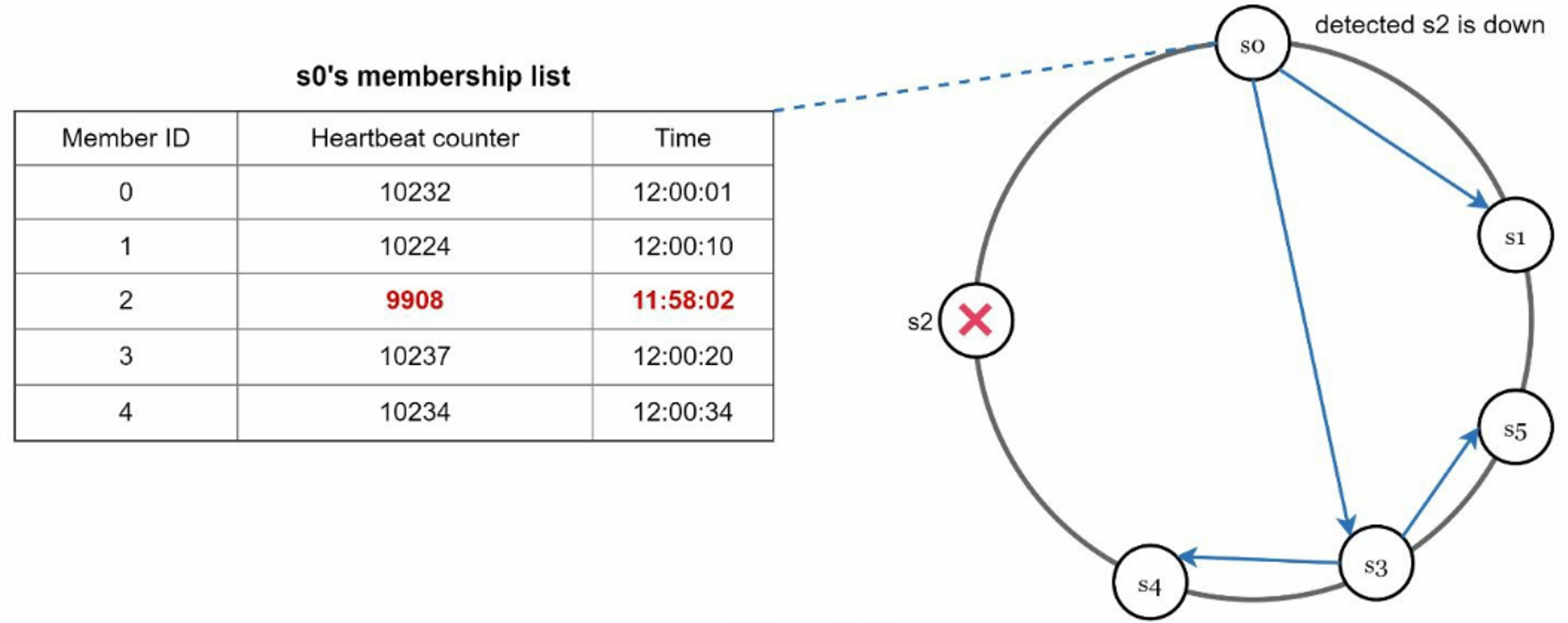
- Node
s0maintains a membership list. - Node
s0notices that nodes2's heartbeat counter has not increased for a long time. - Node
s0sends heartbeats that includes2's info to a set of random nodes. Once other nodes confirm thats2's heartbeat counter has not been updated for a long time, nodes2is marked down.
4.4.2 Handle Temporary Failures
After failures have been detected, the system needs to deploy certain mechanisms to ensure availability. In the strict quorum approach, read and write operations could be blocked.
Sloppy quorum is used to improve availability: Instead of enforcing the quorum requirement, the system chooses the first W healthy servers for writes and first R healthy servers for reads on the hash ring. Offline servers are ignored.
If a server is unavailable due to network or server failures, another server will process requests temporarily. When the down server is up, changes will be pushed back to achieve data consistency. This process is called hinted handoff.
4.4.3 Handling permanent failures
To handle permanent failure, we have to compare each piece of data on replicas and update each replica to the newest version. Merkle tree is used for inconsistency detection and minimizing the amount of data transferred.
Steps of building a Merkle tree:
- Divide
key spaceintobuckets - Hash each
keyin a bucket using a uniform hashing method - Create a single hash node per
bucket - Build the tree upwards till root by calculating hashes of children
To compare two Merkle trees:
- start by comparing the root hashes:
- If root hashes match: both servers have the same data
- If not: compare its left chold and right child
Traverse the tree to find which buckets are not synchronized and synchronize those buckets only.
4.4.4 Handling data center outage
It's important to replicate data across multiple data centers to handle data center outage.
5. System architecture diagram
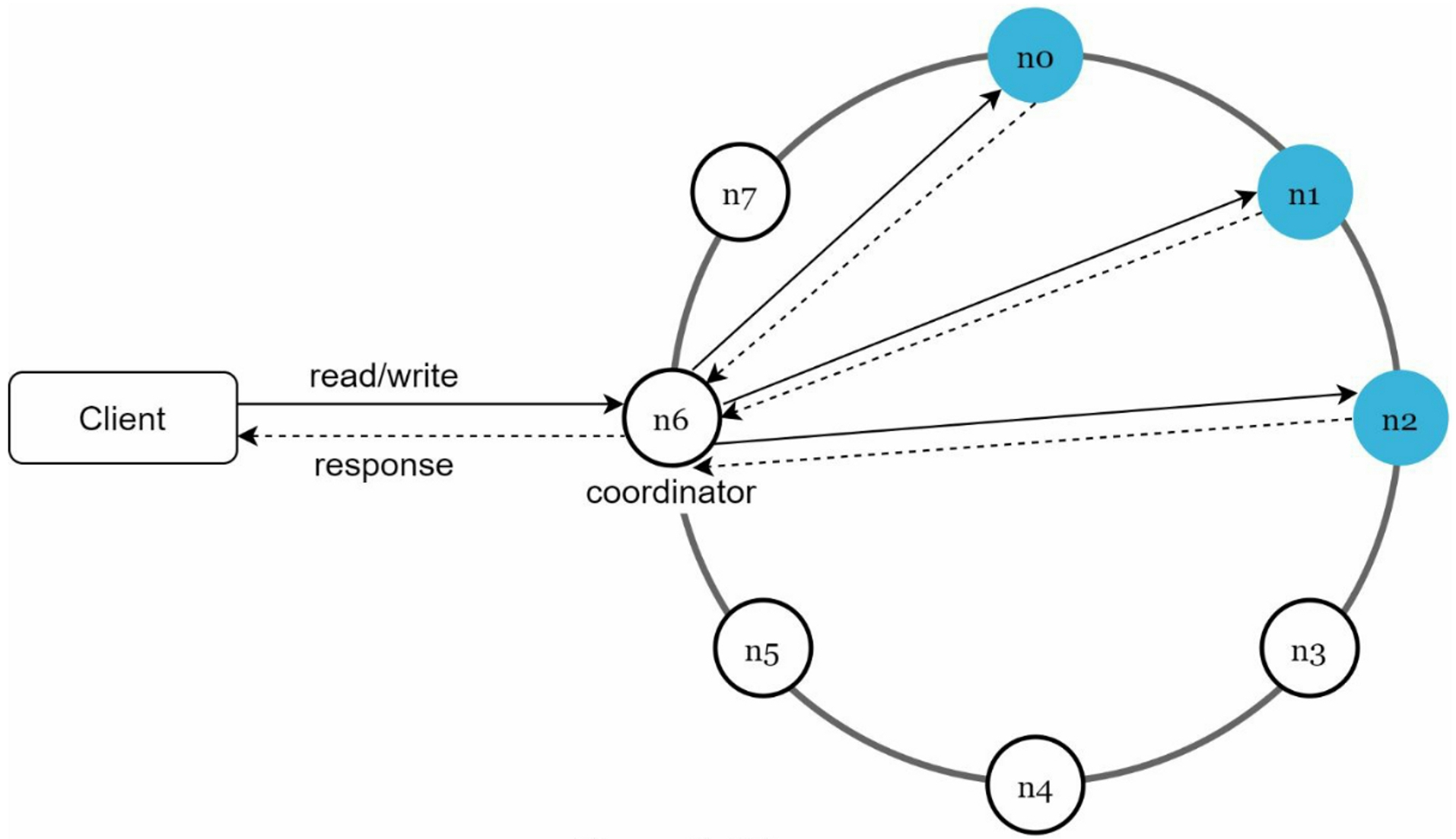
Main features of the architecture:
- Clients communicate with the key-value store through simple APIs:
get(key)andput(key, value) - A coordinator is a node that acts as a proxy between the client and the key-value store
- Nodes are distributed on a ring using consistent hashing
- The system is decentralized so adding and moving nodes can be automatic
- Data is replicated at multiple nodes
- Every node has the same set of responsibilities: avoid single point of failure
5.1 Write Path
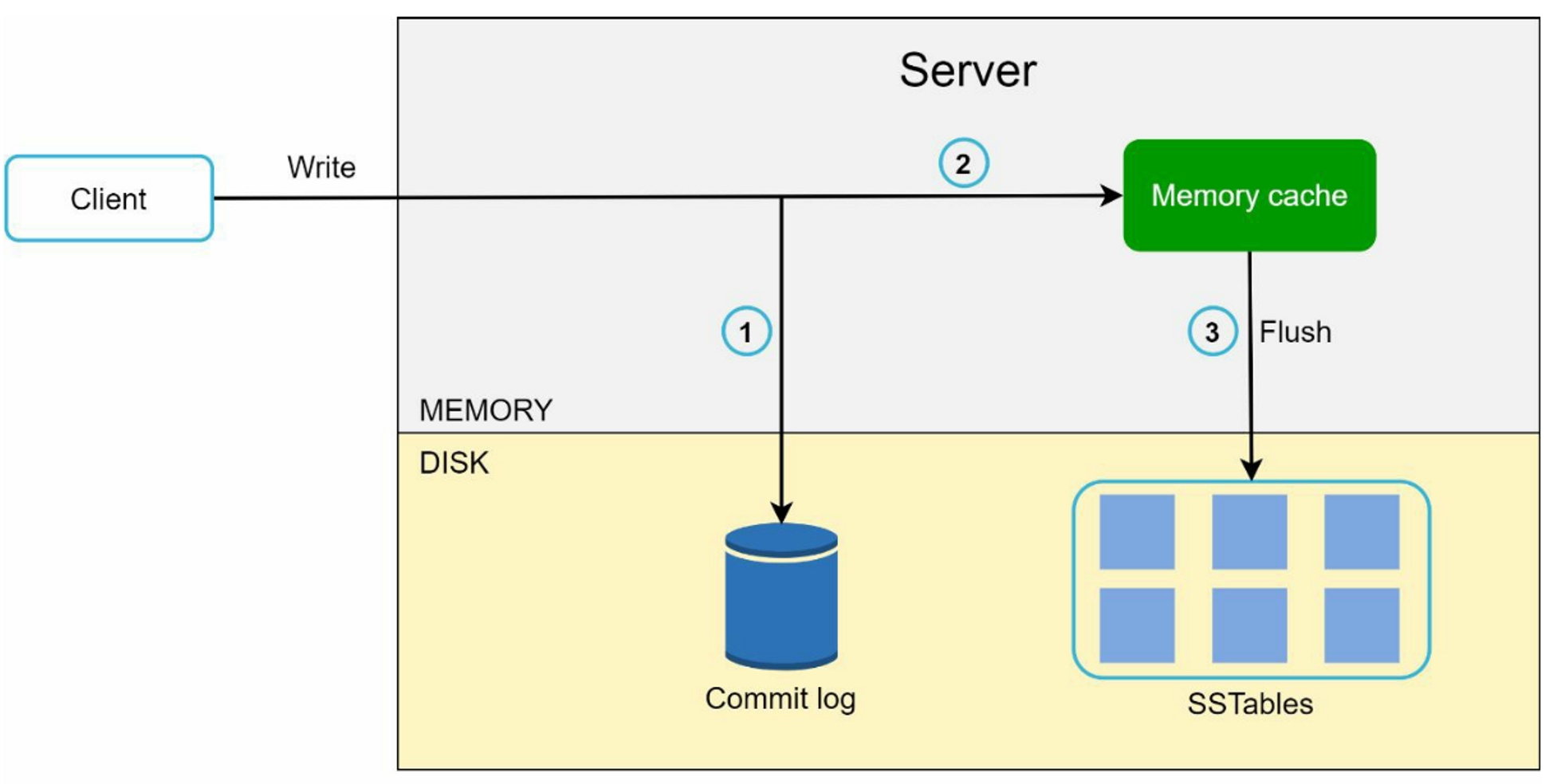
- The write request is persisted on a commit log file
- Data is saved in the memory cache
- When the memory cache is full or reaches a predefined threshold, data is flushed to SSTable on disk
5.2 Read Path
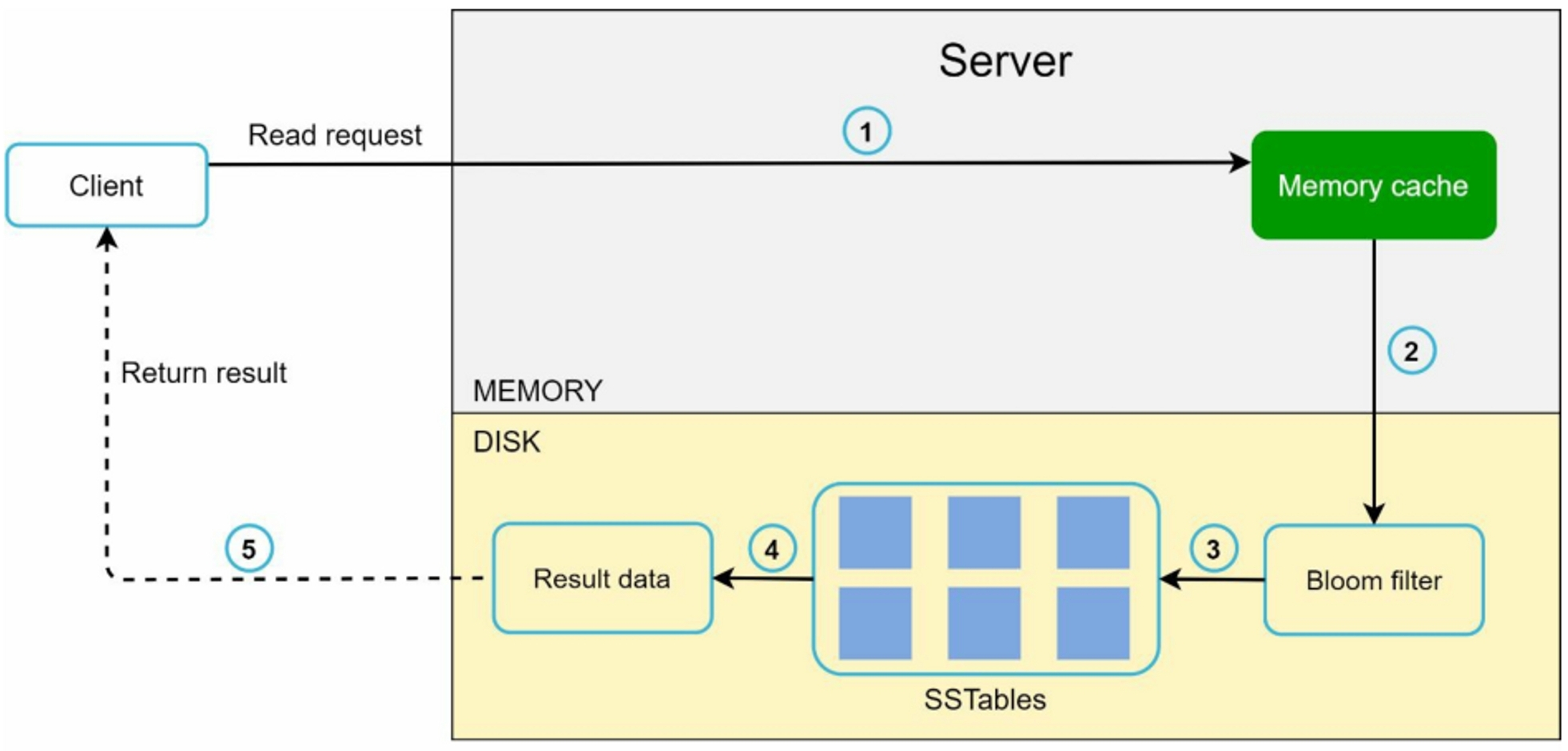
- First check if data is in the memory cache
- If so, the data is returned to the client
- If not, check the bloom filter to find out which SSTable contains the key
- SSTables return the result of the data set
- The result of the data set is returned to the client
6. Summary
- Store big data: use consistent hashing to spread the load across servers
- High available read: data replication, multi-data center
- High available write: versioning and conflict resolution with vector clock
- Dataset partition: consistent hashing
- Incremental scalability: consistent hashing
- Heterogeneity: consistent hashing
- Tunable consistency: Quorum consensus
- Temporary failure: sloppy quorum and hinted handoff
- Permanent failure: merkle tree
- Data center outage: cross-data center replication