System Design - Consistent Hashing
1. The rehashing problem
If you have n cache servers, a common way to balance the load is to use the following hash method: serverIndex = hash(key) % N, where N is the size of the server pool.
This approach works well when the size of the server pool is fixed. However, problems arise when new servers are added, or existing servers are removed: client will connect to the wrong server to fetch data.
2. Consistent hashing
Comparsion:
- Traditional hashing: when making change on the number of slots, all keys need to be remapped
- Consistent hashing: when making change on the number of slots, only
k/nneed to be remapped (kis the number of keys,nis the number of slots)
2.1 Hash space and hash ring
Assume hash function is f, and the output range of the hash function is: $x_0, x_1, x_2, x_3, ..., x_n$. For example, SHA-1's hash space is $[0, 2^{160} - 1]$, $x_0$ corresponds to 0, $x_n$ corresponds to $2^{160} - 1$.
By connecting the $x_0$ and $x_n$, we got a hash ring.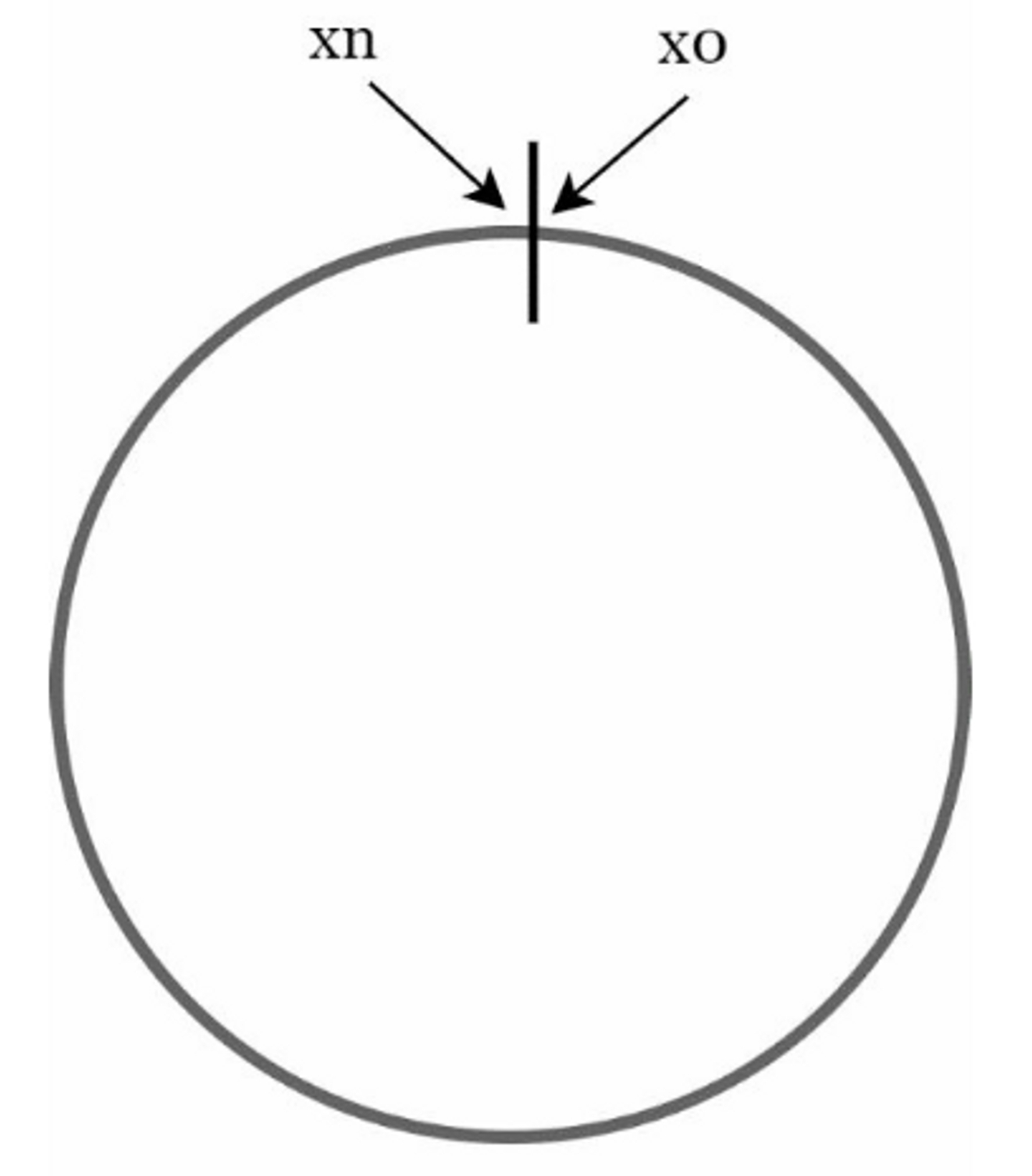
2.2 Hash servers
We map the servers based on their IP address or name onto the ring using hash function f.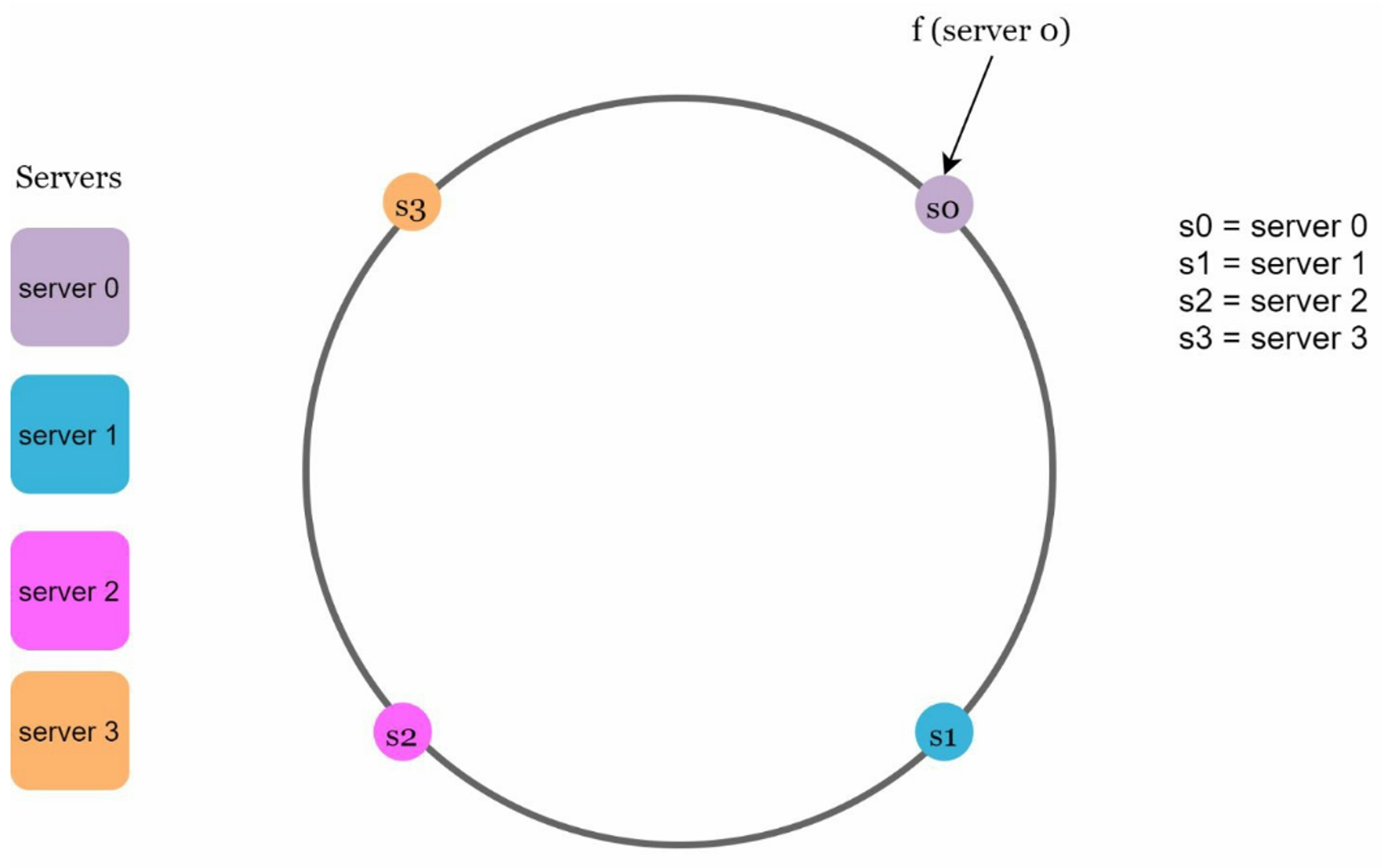
2.3 Hash keys
The cache keys(key0, key1, key2, and key3) are also hashed onto the hash ring, and there is no modular operation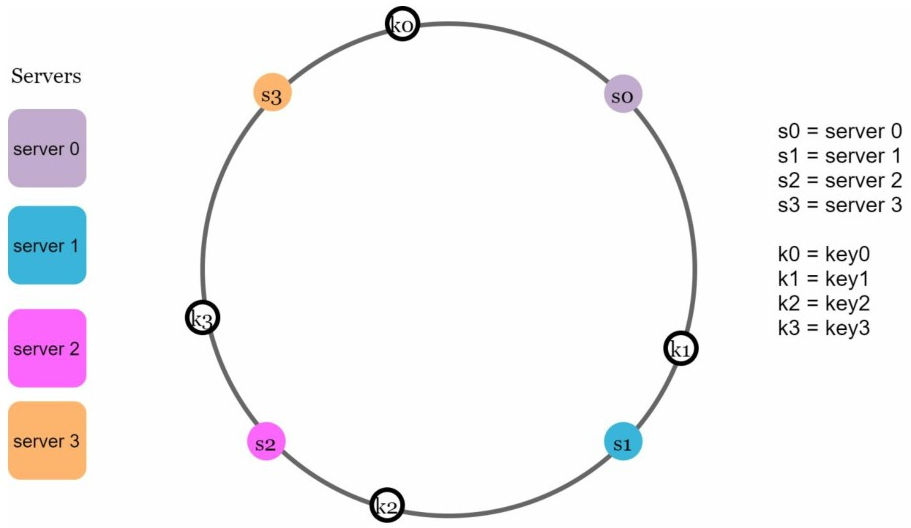
2.4 Server lookup
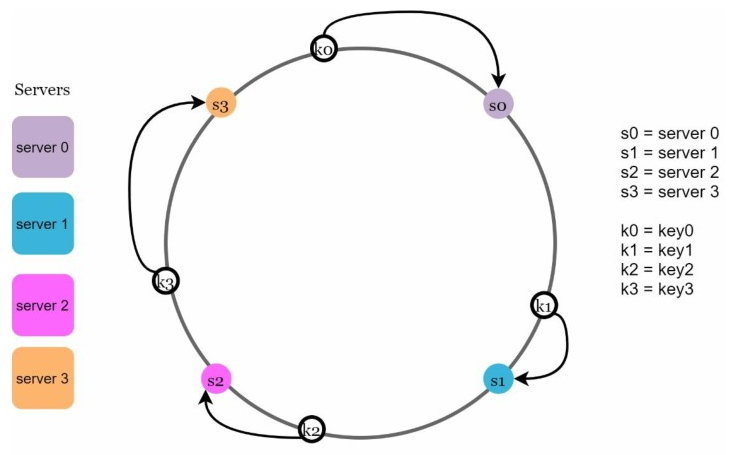
To determine which server a key is stored on, we go clockwise from the key position on the ring until a server is found. For example:
- key0 is stored on server 0
- key1 is stored on server 1
- key2 is stored on server 2
- key3 is stored on server 3.
2.5 Add a server
adding a new server will only need to redistribute part of keys. For example, after server 4 is added, only key0 needs to be redistributed; The rest of the keys are unaffected.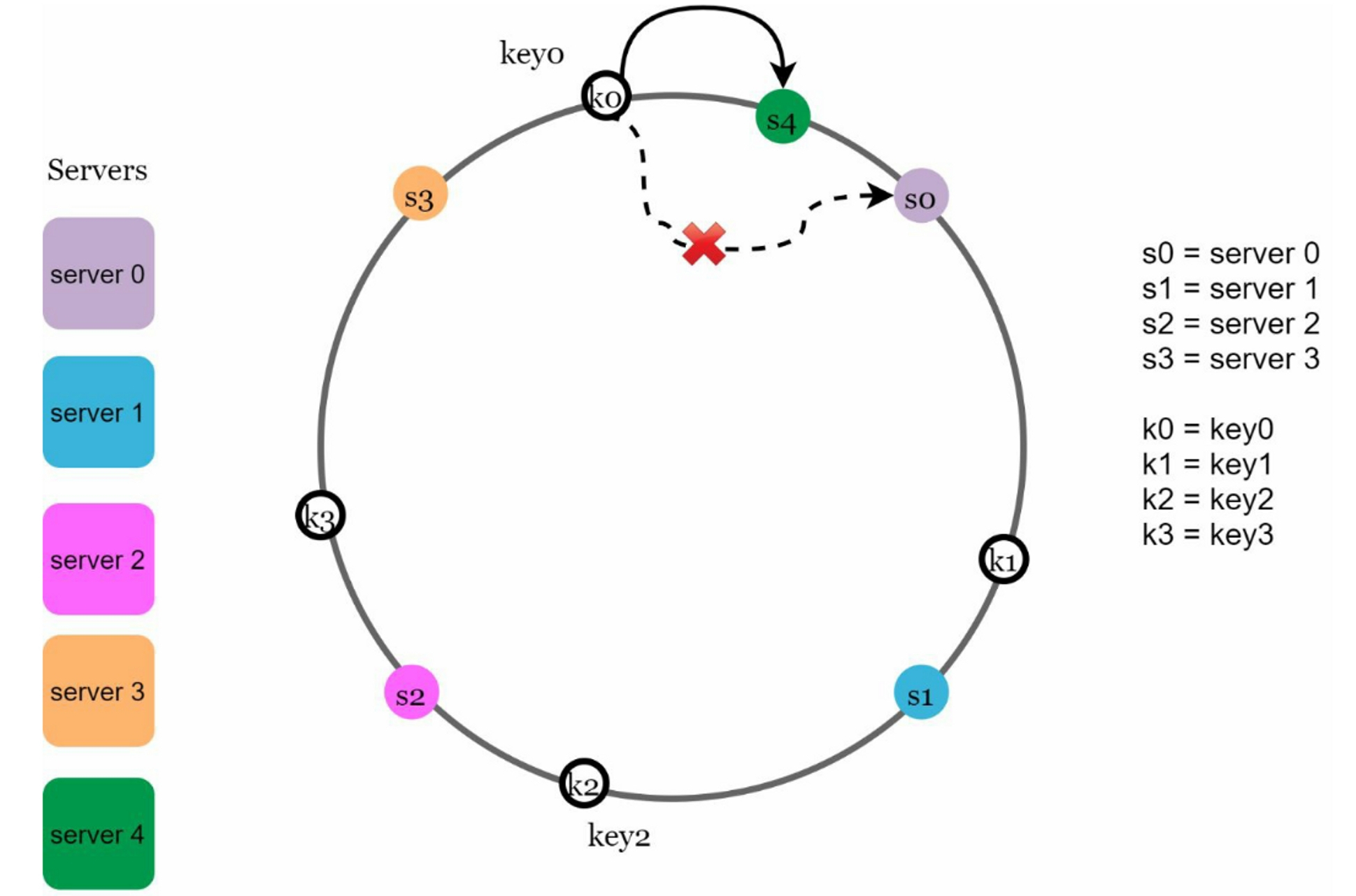
2.6 Remove a server
When a server is removed, only part of keys require redistribution with consistent hashing. For example, when server 1 is removed, only key1 needs to be remapped to server 2. The rest of the keys are unaffected.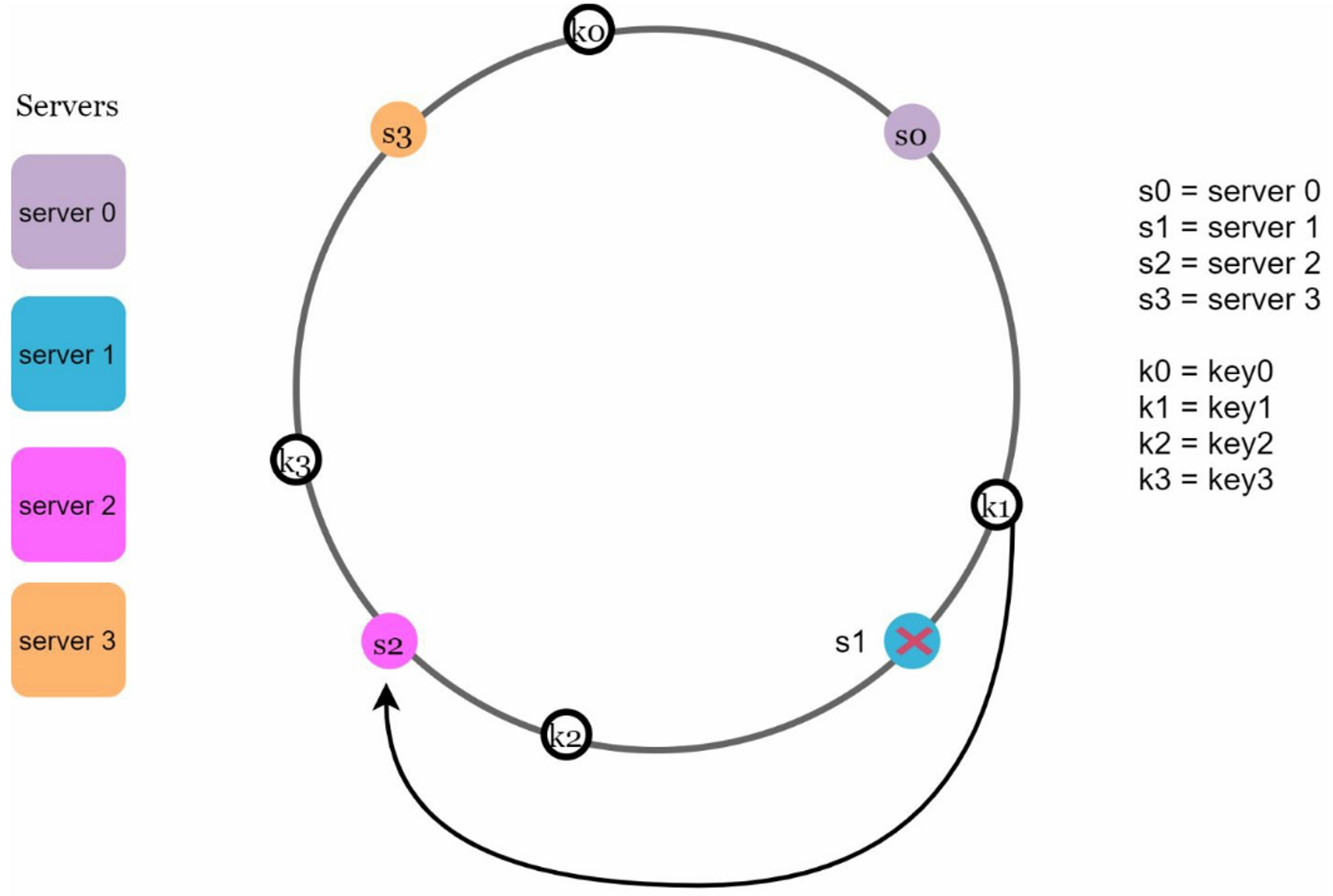
3. Two issue in the basic approach
Basic approach of consistent hashing algorithm:
- Map servers and keys on to the ring using a uniformly distributed hash function
- To find out which server a key is mapped to, go clockwise from the key position until the first server on the ring is found
Two problems with the basic approach:
- When add or remove a server, its impossible to keep the same size of partition for each server
- It is possible to have a non-uniform key distribution on the ring
3.1 Virtual nodes
A virtual node refers to the real node, and each server is represented by multiple virtual nodes on the ring. To find which server a key is stored on, we go clockwise from the key's location and find the first virtual node encountered on the ring.
For example, both server 0 and server 1 have 3 virtual nodes:
- server 0: s0_0, s0_1, and s0_2
- server 1: s1_0, s1_1, and s1_2
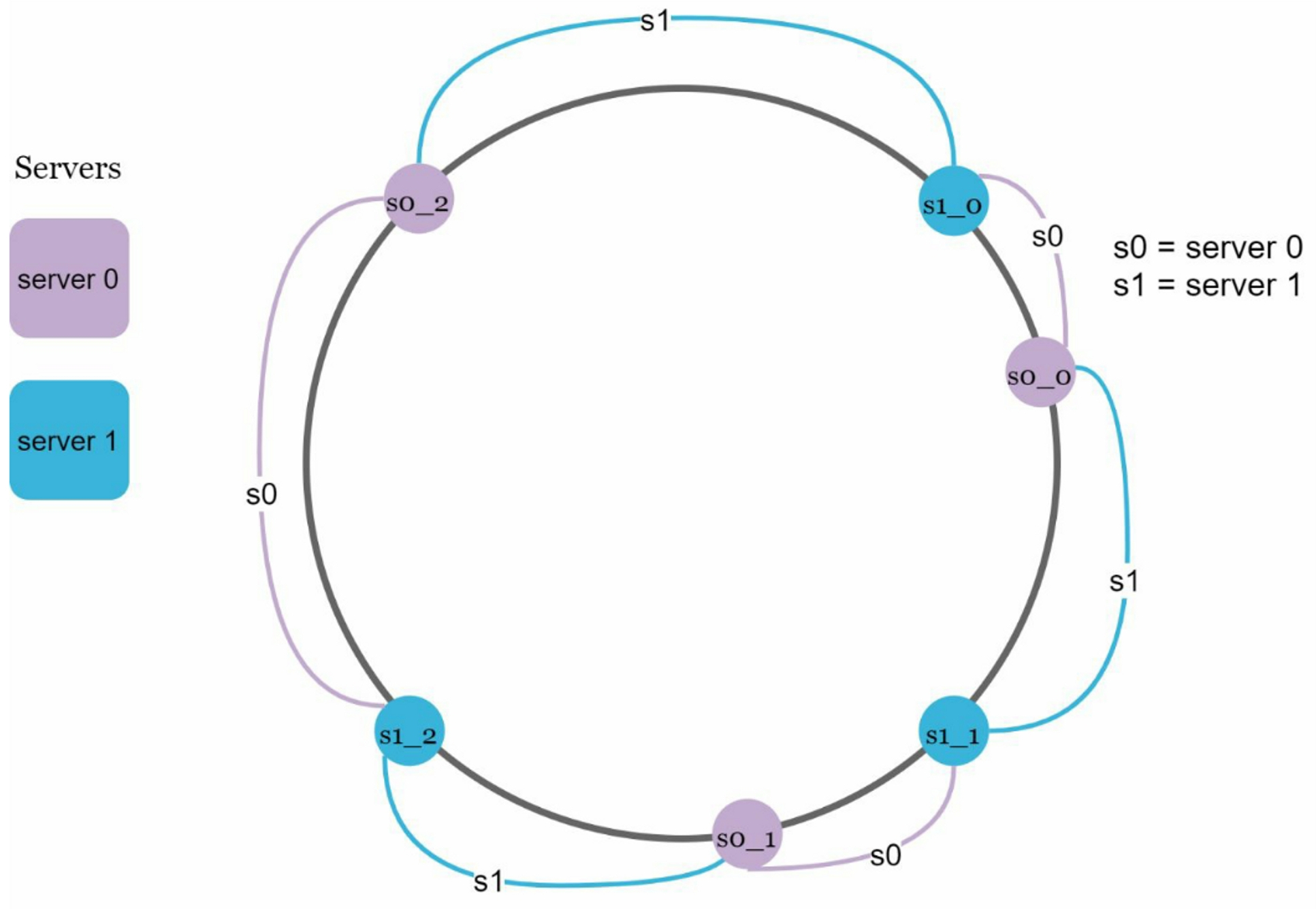
As the number of virtual nodes increases, the distribution of keys becomes more balanced; However, more spaces are needed to store data about virtual nodes. This is a tradeoff, and we can tune the number of virtual nodes to fit our system requirements.
3.2 Find affected keys
Add new server: when server
Sis added onto the ring. The affected range starts fromSand moves anticlockwise around the ring until a server is foundS'. Thus, keys located betweenS'andSneed to be redistributed toS. For example, server 4 is added onto the ring, keys located between s3 and s4 need to be redistributed to s4.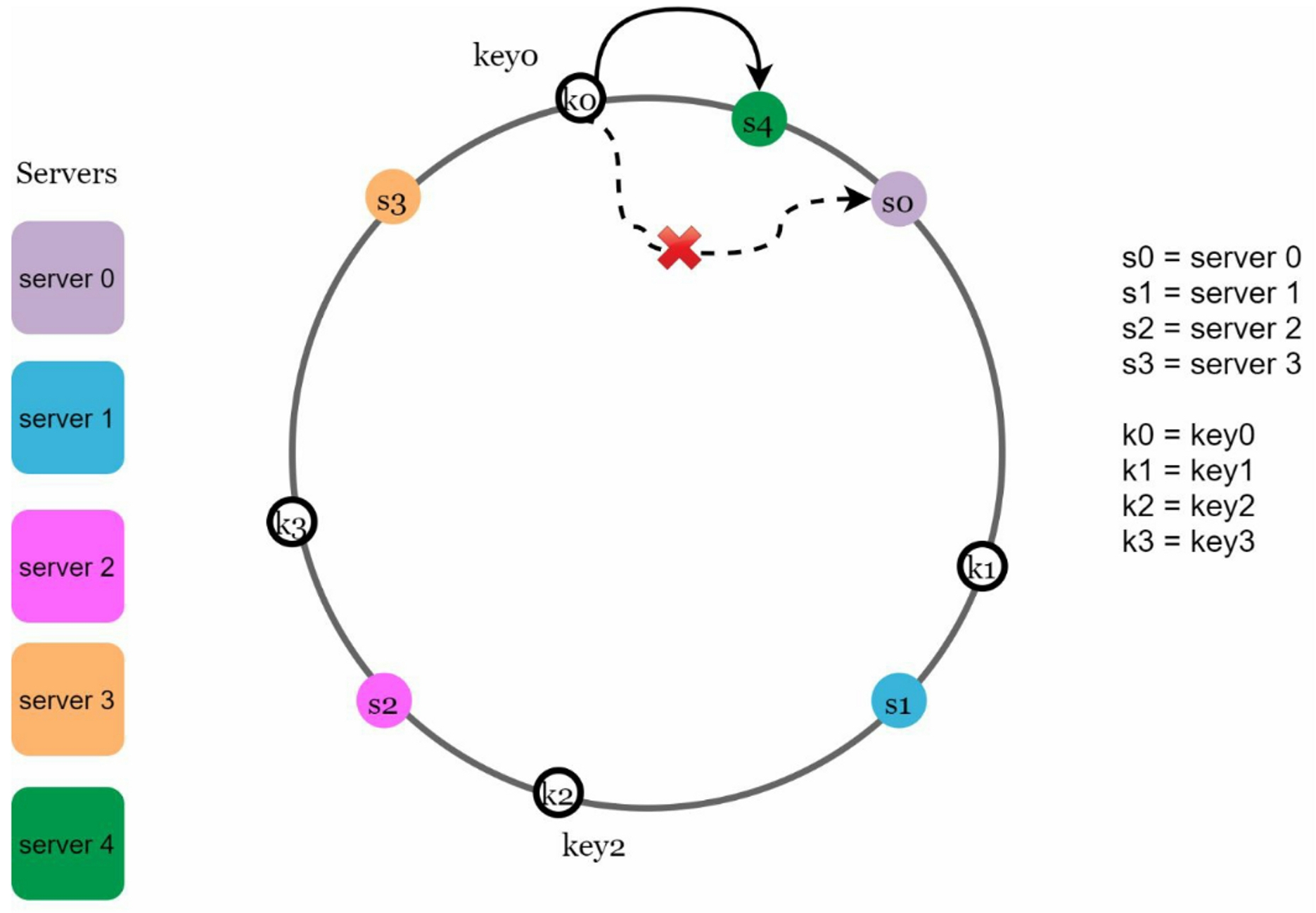
Remove existing server: the affected range starts from
S(removed node) and moves anticlockwise around the ring until a server is foundS'. Thus, keys located betweenSandS'must be redistributed toS'. For example, When a server 1 is removed, the affected range is between server 0 and server 1.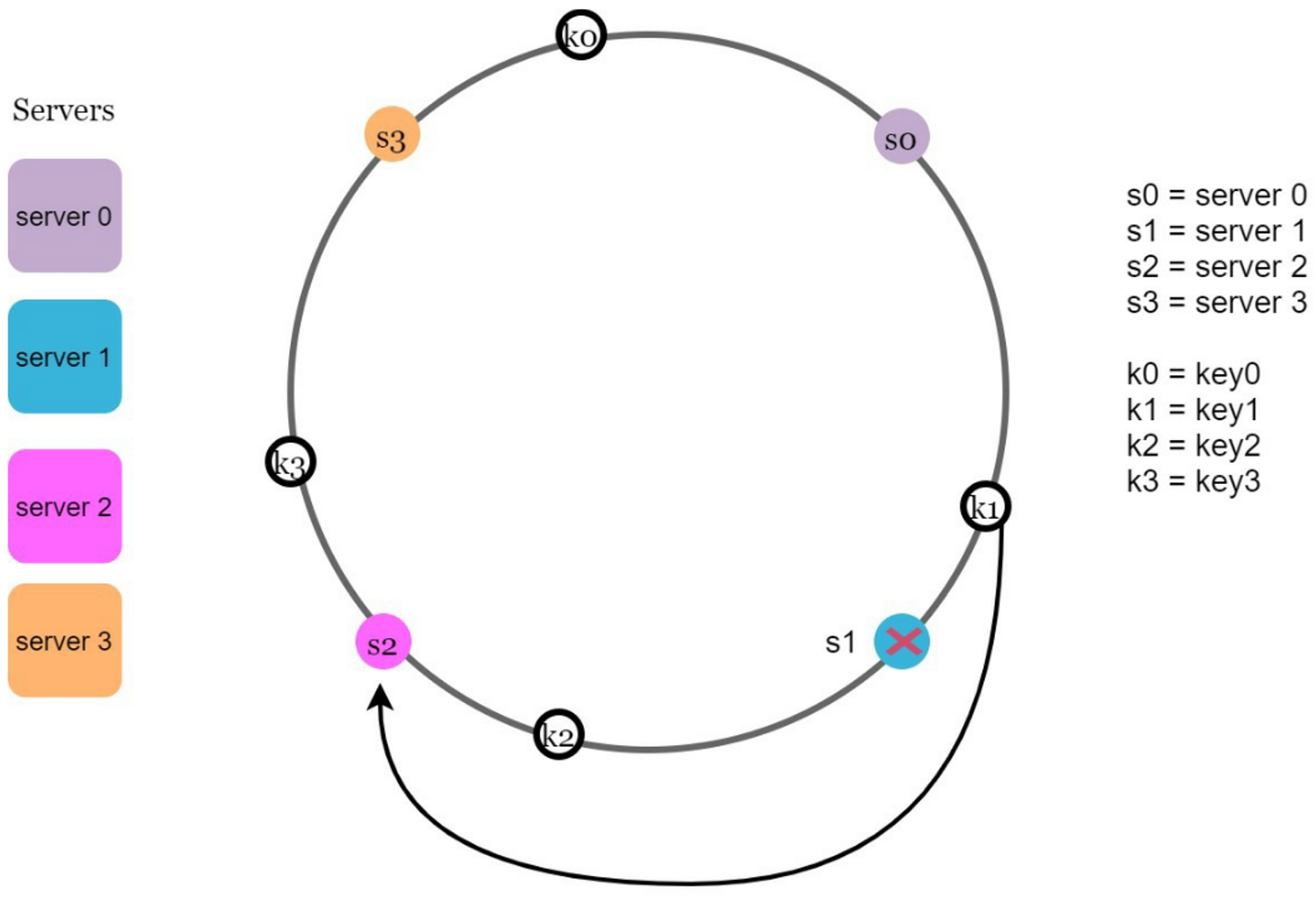
4. Data Replication
To ensure highly available, Consistent Hashing replicates each data item on multiple N nodes. N is equivalent to the replication factor (the number of nodes that will receive the copy of the same data).
- Each key is assigned to a coordinator node (usually the first node that falls in the hash range)
- coordinator node stores the data locally
- coordinator node replicates it to
'N-1'clockwise successor nodes on the ring asynchronously.
This results in each node owning the region on the ring between it and its 'Nth' predecessor.
5. Summary
The benefits of consistent hashing:
- Minimized the number of redistributed keys when servers are added or removed
- Data are more evenly distributed, so it's easy to scale horizontally
- Mitigate hotspot key problem. Excessive access to a specific shard could cause server overload
Consistent hashing use case:
- Partitioning component of Amazon's Dynamo database
- Data partitioning across the cluster in Apache Cassandra
- Discord chat application
- Akamai content delivery network
- Maglev network load balancer