Overview of Compilation
1. Introduction
1.1 Conceptual Roadmap
编译器作为一种计算机程序, 负责将一种语言转换为另一种语言. 为了实现这个目的, 编译器必须理解源语言和目标语言的形式, 内容, 语法和语义, 并需要一种策略将源语言映射到目标语言. 典型的编译器结构为: front-end负责处理源语言, back-end负责处理目标语言, front-end和back-end之间用一种形式化结构来表示程序, 该结构独立于源语言和目标语言. 为提高翻译效率, 编译器还会包含optimizer(优化器), 用于分析和重写形式化结构体.
1.2 Overview
计算机程序使用programming language(编程语言)实现一系列抽象行为. 相对于自然语言的模糊性, programming language十分简洁和明确, 并极力避免二义性. 用户可使用programming language来表示一系列计算行为, 并交由computer processor运行并得到结果. 一般来说, 程序员提交的source language(源语言)相对于编译器输出的target language(目标语言)来说, 会更加抽象, 简洁. 一行programming language可能会被翻译为几百行machine operation. 以下是编译器的功能示意图:
源语言可以为C, C++, FORTRAN, Java或其他编程语言, 目标语言一般为processor的instruction set(指令集), 但也可能为其他编程语言. 很多research compiler的目标语言为C, 因为C可在绝大多数计算机上运行; 这些不以instruction set为目标语言的compiler也被称为source-to-source translator.
除了compiler, 还有一种程序称为interpreter(解释器), interpreter会直接执行源程序并输出结果, 如下图:
还有一些编程语言需要compiler和interpreter的协同合作, Java先由compiler编译为bytecode, 然后由JVM(Java Virtual Machine)运行bytecode. Compiler和interpreter有很多共同之处, 它们都需要分析源代码并分析, 也需要在运行时保存程序信息.
1.3 The Fundamental Principles of Compilation
Compiler作为一个复杂且缜密的工程项目, 依赖于很多方案的实现. 以下是compiler必须遵守的两条准则:
- compiler需保留源程序的所有涵义
- compiler需以某些明确的方式提升程序性能
2. Compiler Structure
简单来说, compiler可分为两个部分: front-end和back-end.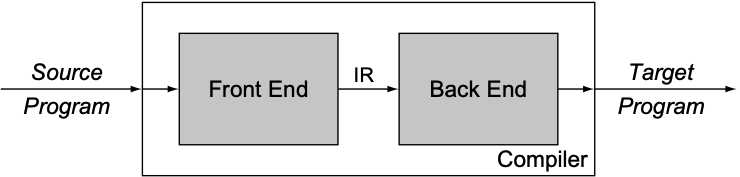
Front-end负责理解源语言并转换为intermediate representation(IR), 而back-end负责将IR映射为目标语言. 在得到目标语言之前, compiler需要对IR进行多次迭代, 用于提升编译质量. 这种two-phase structure的设计也简化了compiler的重定目标过程: 针对不同机器, 可使用不同的back-end生成相应的指令集; front-end则可以保持不变, 因为front-end不直接服务于目标语言, 只需要产生IR即可.
IR的引入使得编译阶段可添加其他阶段, 例如: optimizer. Optimizer以IR作为输入, 输出优化后的IR. 这种compiler结构被称为three-phase compiler:
Three-phase structure中的每个阶段也可分为多个小阶段:
- front-end: 识别源语言, 验证合法性, 并输出IR
- optimizer: 多次迭代IR, 每次迭代都采取不同的优化策略
- back-end: 多次迭代IR, 每次迭代输出更准确的目标语言
以下是Compiler的结构图: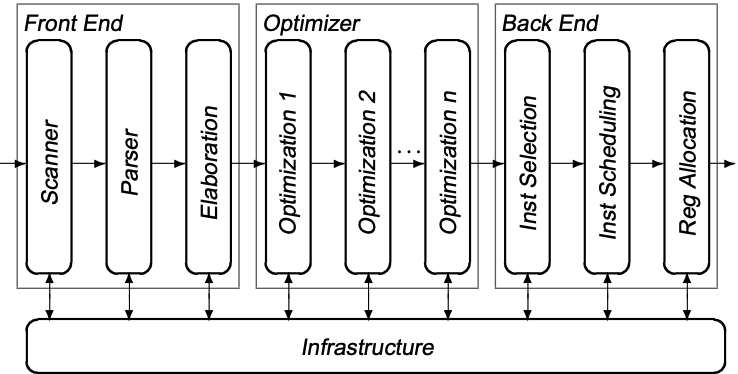
Compiler的三个阶段中, optimizer的描述最模糊. 优化意味着需要为某些问题找到更优方案, 但优化也可能导致更多问题. 编译后的代码性能取决于optimizer和back-end的共同协作, 即使optimizer选择了最优方案, 也可能因为和back-end产生冲突而导致性能下降. 因此, 相对于源代码, optimizer的确提升了代码质量, 但通常无法产生最优代码.
优化部分可以是一个单次迭代的处理过程, 也可以为多次迭代处理. 单词迭代虽然更为高效, 但设计更为复杂; 多次迭代虽然耗时较长, 但设计更加简单灵活. 这两种设计的选择取决于compiler的各种约束条件.
3. Overview of Translation
以 $a \leftarrow a \times 2 \times b \times c \times d$ 为例, a, b, c, d表示变量, $\leftarrow$表示赋值, $\times$表示相乘操作符. 接下来会显示compiler对于该表达式的处理全过程.
3.1 The Front End
Front-end会根据语法或语义判断输入的代码是否正确. 若语法和语义都没问题, 则生成IR; 若出错, 则直接报错.
3.1.1 Check Syntax
Source language(源语言)是一个无限集, 而由grammer(语法)规定的字符串集合为有限集. Front-end中有两个部分来判断输入的代码是否正确: scanner和parser. Programming language中每个词都属于一个词类(part of speech), 例如: 英语中, 每句话都有以下结构:
$$
\textit{Sentence} \rightarrow \textit{Subject} \ \text{verb} \ \textit{Object} \ \text{endmark}
$$
其中, verb和endmark为词类, Sentence, Subject和Object属于语法变量(syntactic variables), $\rightarrow$表示箭头右边的实例可抽象为左边的语法变量. 以"“Compilers are engineered objects."这句话为例, compiler会将这句话交给scanner来获取每个单词对应的词类. Scanner会根据输入生成一个个pair, 以$(p, s)$的形式存在, 其中p为该单词的词类, s为单词的拼写, 最后得到的结果如下:
$$
\text{(noun,“Compilers”), (verb,“are”), (adjective,“engineered”),} \\
\text{(noun,“objects”), (endmark,“.”)}
$$
下一步, compiler根据input language的语法规则, 和上一步scanner获得的每个代码的词类, 来判断是否符合语法语意. 假设语法规则如下:
- $\textit{Sentence} \rightarrow \textit{Subject} \ \text{verb} \ \textit{Object} \ \text{endmark}$
- $\textit{Subject} \rightarrow \text{noun}$
- $\textit{Subject} \rightarrow \textit{Modifier} \ \text{noun}$
- $\textit{Object} \rightarrow \text{noun}$
- $\textit{Object} \rightarrow \textit{Modifier} \ \text{noun}$
- $\textit{Modifer} \rightarrow \text{adjective}$
根据上述规则, 可为上述例句进行逐步推导(derivation):
- 根据rule 1推导出: $\text{Subject verb Object endmark}$
- 根据rule 2推导出: $\text{noun verb Object endmark}$
- 根据rule 5推导出: $\text{noun verb Modifier noun endmark}$
- 根据rule 6推导出: $\text{noun verb adjective noun endmark}$
到此为止, "Compilers are engineered objects."完全符合语法规则. 但一个语法上没错的句子是没有意义的, 例如: "Rocks are green vegetables"同样没有语法错误, 但句子没有任何合理性. 因此为了判断句子是否合理, compiler还需要理解句子的语义.
programming language中的语义模型比自然语言简单的多, compiler可为其建立数学模型并检测代码中的不一致性. 以 $a \leftarrow a \times 2 \times b \times c \times d$ 为例, 若b为字符类型, 则句子不合法; 当数组的维数和数组声明的维数不相等时, 也存在不一致性问题.
3.1.2 Intermediate Representations
Front-end最后的任务是生成代码对应的IR. 根据输入语言和输出语言的不同, 使用的IR类型也会有所不同. 一些IR将代码表示为一个图, 另一些IR表示为有序的汇编代码, 以下是IR可能的表达方式:
$$
t_0 \leftarrow a \times 2 \\
t_1 \leftarrow t_0 \times b \\
t_2 \leftarrow t_1 \times c \\
t_3 \leftarrow t_2 \times d \\
a \leftarrow t_3
$$
3.2 The Optimizer
当front-end为源代码产生IR时, 会遵循源代码中的执行顺序, 因此产生的IR虽然在代码逻辑上没有问题, 但在性能上可能存在缺陷. Optimizer负责减少代码运行时间, 减小编译后的代码长度, 并降低CPU执行代码时的耗能. 假设原始代码如下:
b ← ··· |
由于b, c的值在上述循环中不变, 只有a和d在循环内部改变, 所以可以重写为以下代码:
b ← ··· |
优化后的版本, 乘法操作的次数从4n降低为2n+2. Compiler中的优化分为两个部分:
- Analysis: 判断代码何处可进行优化, 一般有以下几种分析技术:
- 数据流分析(Dataflow analysis): 编译时推断运行时值的流动
- 相关性分析(Dependence analysis): 利用number-theoretic(数论)推断下标表达式的合理性
- Transformation: 分析代码后还需要一种重写代码的方式, 从而让代码可高效运行. 例如: 找到循环中不变的计算并将其移至不那么频繁执行的位置. 代码转换的方式十分丰富, 每种代码转换的运行范围和所需技术都不同.
3.3 The Back End
Back-end负责将IR转换为目标语言的代码. Back-end会决定操作执行的顺序, 并选择哪些数值存放在register(寄存器), 哪些数值存在内存中. 本章使用ILOC指令集, 可以看做RISC(reduced instruction set computer, 精简指令集)的简化版.
3.3.1 Instruction Selection
将IR转换为目标语言的第一步为instruction selection(指令选择). 以 $a \leftarrow a \times 2 \times b \times c \times d$ 为例, 经过front-end的处理后可得到以下IR:
$$
t_0 \leftarrow a \times 2 \\
t_1 \leftarrow t_0 \times b \\
t_2 \leftarrow t_1 \times c \\
t_3 \leftarrow t_2 \times d \\
a \leftarrow t_3
$$
假设a, b, c, d分别从寄存器$r_{arp}$指定的地址开始, 偏移量分别为@a, @b, @c, @d, 以下是生成的ILOC代码:
| ILOC instructions | Comment |
|---|---|
| $\text{loadAI} \quad r_{\textrm{arp}}, @a \Rightarrow r_{\textrm{a}}$ | load a |
| $\text{loadI} \quad 2 \Rightarrow r_2$ | constant 2 into $r_2$ |
| $\text{loadAI} \quad r_{\textrm{arp}}, @b \Rightarrow r_{\textrm{b}}$ | load b |
| $\text{loadAI} \quad r_{\textrm{arp}}, @c \Rightarrow r_{\textrm{c}}$ | load c |
| $\text{loadAI} \quad r_{\textrm{arp}}, @d \Rightarrow r_{\textrm{d}}$ | load d |
| $\text{mult} \quad r_{\textrm{a}}, r_2 \Rightarrow r_{\textrm{a}}$ | $r_{\textrm{a}} \leftarrow a \times 2$ |
| $\text{mult} \quad r_{\textrm{a}}, r_{\textrm{b}} \Rightarrow r_{\textrm{a}}$ | $r_{\textrm{a}} \leftarrow (a \times 2) \times b$ |
| $\text{mult} \quad r_{\textrm{a}}, r_{\textrm{c}} \Rightarrow r_{\textrm{a}}$ | $r_{\textrm{a}} \leftarrow (a \times 2 \times b) \times c$ |
| $\text{mult} \quad r_{\textrm{a}}, r_{\textrm{d}} \Rightarrow r_{\textrm{a}}$ | $r_{\textrm{a}} \leftarrow (a \times 2 \times b \times c) \times d$ |
| $\text{storeAI} \quad r_{\textrm{a}} \Rightarrow r_{\textrm{arp}}, @a$ | write $r_a$ back to a |
可以看到, compiler将所有相关值都加载到register中, 并按照IR执行乘法, 最后将结果存放在a所对应的内存地址. 这里假设register数量不受限, 并用符号名来命名register, 也称为virtual register. 这时instruction selector就可发挥作用, 例如: 用multI替换mult, 将 $\text{mult} \ r_a, r_2 \Rightarrow r_a$ 替换为 $\text{multI} \ r_a, 2 \Rightarrow r_a$, 这样就减少了一次 $\text{LoadI} \ 2 \Leftarrow r_2$ 的操作; 也可以进一步优化: 将 $\text{multI} \ r_a, 2 \Rightarrow r_a$ 替换为 $\text{add} \ r_a, r_a \Rightarrow r_a$, 这样避免了$r_2$的加载和乘法操作.
3.3.2 Register Allocation
Instruction selection阶段假设register数量没有上限要求, 使用virtual register而忽略了register数量有限的事实. 实际中, virtual register的数量很可能高于硬件支持的数量, 必须将每个virtual register映射到实际register上. Register allocator负责决定哪些数值留在register中, 哪些数值留在内存, 从而减少register使用数量.
| Instruction | Comment |
|---|---|
| $\text{loadAI} \quad r_{\textrm{arp}}, @a \Rightarrow r_1$ | load a |
| $\text{add} \quad r_1, r_1 \Rightarrow r_1$ | $r_1 \leftarrow a \times 2$ |
| $\text{loadAI} \quad r_{\textrm{arp}}, @b \Rightarrow r_2$ | load b |
| $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2) \times b$ |
| $\text{loadAI} \quad r_{\textrm{arp}}, @c \Rightarrow r_2$ | load c |
| $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2 \times b) \times c$ |
| $\text{loadAI} \quad r_{\textrm{arp}}, @d \Rightarrow r_2$ | load d |
| $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2 \times b \times c) \times d$ |
| $\text{storeAI} \quad r_1 \Rightarrow r_{\textrm{arp}}, @a$ | write $r_a$ back to a |
上述重写后的指令序列只使用了三个register, 而不是之前的六个. 但指令序列的优化也可能导致相反作用, 例如: 重复计算已经计算过的表达式.
3.3.3 Instruction Scheduling
由于不同的指令执行时间不同, 适当调整指令顺序可提高执行效率. 一般来说, 内存访问操作会消耗几十甚至上百个CPU周期, 算术操作则只需要几个CPU周期. 假设指令的耗时如下:
- loadAI, storeAI: 3个CPU周期
- mult: 2个CPU周期
- other instruction: 1个CPU周期
| Start | End | Instruction | comment |
|---|---|---|---|
| 1 | 3 | $\text{loadAI} \quad r_{arp}, @a \Rightarrow r_1$ | load a |
| 4 | 4 | $\text{add} \quad r_1, r_1 \Rightarrow r_1$ | $r_1 \leftarrow a \times 2$ |
| 5 | 7 | $\text{loadAI} \quad r_{arp}, @b \Rightarrow r_2$ | load b |
| 8 | 9 | $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2) \times b$ |
| 10 | 12 | $\text{loadAI} \quad r_{arp}, @c \Rightarrow r_2$ | load c |
| 13 | 14 | $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2 \times b) \times c$ |
| 15 | 17 | $\text{loadAI} \quad r_{arp}, @d \Rightarrow r_2$ | load d |
| 18 | 19 | $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2 \times b \times c) \times d$ |
| 20 | 22 | $\text{storeAI} \quad r_1 \Rightarrow r_{arp}, @a$ | write $r_a$ back to a |
上述9个指令共需22个CPU时间. 许多CPU都有一个特性: 等待指令执行期间可发起新的操作, 只要新指令不引用之前未完成的执行结果, 就可正常执行; 但若当前指令需要使用之前未完成的指令结果, 则CPU会阻塞并等待长延迟指令. Instruction scheduler会重新排序各个指令, 并试图最小化所需的CPU时间, 以下是优化后的指令序列:
| Start | End | Instruction | comment |
|---|---|---|---|
| 1 | 3 | $\text{loadAI} \quad r_{arp}, @a \Rightarrow r_1$ | load a |
| 2 | 4 | $\text{loadAI} \quad r_{arp}, @b \Rightarrow r_2$ | load b |
| 3 | 5 | $\text{loadAI} \quad r_{arp}, @c \Rightarrow r_3$ | load c |
| 4 | 4 | $\text{add} \quad r_1, r_1 \Rightarrow r_1$ | $r_1 \leftarrow a \times 2$ |
| 5 | 6 | $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2) \times b$ |
| 6 | 8 | $\text{loadAI} \quad r_{arp}, @d \Rightarrow r_2$ | load d |
| 7 | 8 | $\text{mult} \quad r_1, r_3 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2 \times b) \times c$ |
| 9 | 10 | $\text{mult} \quad r_1, r_2 \Rightarrow r_1$ | $r_1 \leftarrow (a \times 2 \times b \times c) \times d$ |
| 11 | 13 | $\text{storeAI} \quad r_1 \Rightarrow r_{arp}, @a$ | write $r_a$ back to a |
可以看到, 重新排序后的指令序列只需13个CPU周期, 虽然多用了一个register, 但耗时减少了近一半.