Types of Locks
1. Exclusive Locks
某一时刻, 一把锁只能被一个线程持有, 被称为Exclusive Lock(互斥锁). 锁的持有者对受锁保护的区域有排他性访问权. 互斥锁作为最基础的一类锁, 以最简单的方式展现了锁的基本属性: 为限制资源的访问提供了一套同步机制. 锁还有Granularity(粒度)属性, 锁的Granularity关系到两个方面:
- lock overhead: 为使用或实现锁而消耗的资源, 包含锁占用的内存大小, CPU用于初始化, 获得和释放锁的时间.
- lock contention: 某一线程试图获取其他线程已持有的锁, 这一情况称为lock contention. lock的精细度越小, 线程争夺锁的情况越少. 例如: 数据库中锁可能用于保护整个database, 也可能只用于保护某个table, 或某个row.
通常来说粒度越大, lock overhead越小, lock contention越大; 反之, 粒度越小, lock overhead越大, lock contention越小.
2. Reader-Writer Locks
读写锁包含两个部分:
- 同一时刻可有多个读者拥有锁.
- 同一时刻最多允许一个写者拥有锁.
理论上, 在面对频繁读取且较少写入的情况, 读写锁有较好的可拓展性. 但现实中, 读写锁的可拓展性取决于其如何实现. 最经典的读写锁实现涉及到counter和flag, 在面对较短的critical section(锁保护的代码区域)时性能不佳, 因为获得和释放锁操作十分耗时. 但若critical section足够长, 则可以忽略获得和释放锁的开销.
使用per-thread exclusive lock可以设计一种偏向于读者的读写锁. 对于读操作, 每个线程可以获取各自的锁; 对于写操作, 线程需要获得所有锁. 在没有写者的情况下, 读者只需要atomic operation和memory barrier, 不再出现cache miss; 但对于写者来说会发生大量cache miss. 每一种读写锁的实现都有其优缺点, 但都需要较长的critical section.
3. Beyond Reader-Writer Locks
Reader-Writer Locks和Exclusive Locks的区别在于不同的访问策略: 互斥锁只运行同一时刻最多一位访问者, 读写锁允许多个读者同时访问. 除此之外还有其他访问策略, VAX/VMS distributed lock manager(DLM)就是其中之一. 图中每一格表示兼容情况, "X"表示不兼容:
| Null | Concurrent Read | Concurrent Write | Protected Read | Protected Write | Exclusive | |
|---|---|---|---|---|---|---|
| Null | ||||||
| Concurrent Read | X | |||||
| Concurrent Write | X | X | X | |||
| Protected Read | X | X | X | |||
| Protected Write | X | X | X | X | ||
| Exclusive | X | X | X | X | X |
- Null(无锁): 这个模式可以和任何模式兼容. 因为如果一个线程不拥有锁, 就不需要防止其他线程争抢.
- Concurrent Read(并发读): 该模式只与exclusive不兼容, 其他的都兼容. 一般用于统计粗略的计数结果, 允许与Concurrent Write同时操作.
- Concurrent Write(并发写): 与Null, Concurrent Read, Concurrent Write兼容, 一般用于更新粗略的计数结果.
- Protected Read(受保护读): 与Null, Concurrent Read, Protected Write兼容, 一般用于读取精确的计数结果, 可允许多个读操作同时进行, 但不允许与写操作同时进行.
- Protected Write(受保护写): 与Null, Concurrent Read兼容. 允许与Concurrent Read同时发生, 但会与Protected Read争抢锁.
- Exclusive(互斥): 仅与Null兼容, 用于排他性访问时使用.
4. Scoped Locking
4.1 Intro
以上所说的锁都需要显式地获取或释放锁, 例如spin_lock()和spin_unlock(), 另一种方式则是使用resource allocation is initialization(RAII). 许多编程语言都用到RAII来实现automatic variable(local variable进入作用域时自动初始化, 离开作用域时自动销毁), 在C++中, object在进入作用域后自动调用constructor, 离开作用域后自动调用destructor.
RAII locking最大的特性在于, 程序员不必仔细检查获取的锁是否正确释放, 因为锁会在离开作用域后自动释放. C++提供了std::lock_guard()实现RAII-Style的范围锁:
|
4.2 Benefits and Limitations
RAII作为一项资源管理方案, 其优点如下:
- Encapsulation: 封装性让资源有特定的作用域, 固定的生存周期, 所以可以确保其自动的初始化与销毁.
- Exception Safety: 由于资源被固定在一个作用域范围内, 所以资源其实被分配到stack上, 当异常发生时会正常地销毁资源. 例如C++中的stack unwinding, 所有分配在stack上的变量无论是否发生异常都会正常析构.
- Locality: 资源初始化和释放的定义写在一块(同一个class内)
但RAII也有其缺陷和限制:
- RAII只用于stack上分配的资源, 这样才能确定资源的生存周期. 对于heap上分配的资源, 则需要隐式或显式地调用析构. 或使用smart pointer来管理heap上的资源.
- RAII需要一定的封装性来限制资源的作用域. 但有些资源并不能很好的封装, 例如iterator: 当使用iterator遍历某数据结构时, 很难将iterator的初始化和终止遍历封装在一个作用域内.
- RAII不能实现critical section的重叠, 因为作用域只能嵌套. 当存在大量并发尝试时, 只能有一个线程能成功. 这时就需要让大部分线程尽快放弃尝试, 否则lock contention将会大量消耗资源.
4.3 Lock Tree
RAII的特性需要不同于其他锁类型的数据结构, 这里介绍RCU的实现作为一个例子. 每个CPU都被分配一个rcu_node结构体, 每一个rcu_node有一个parent指针指向其父节点. 父节点同样为rcu_node, 其parent指针指向NULL. 每一个父节点一般拥有32或64个子节点. 每个rcu_node还有fqslock指针指向一把锁, 如下图: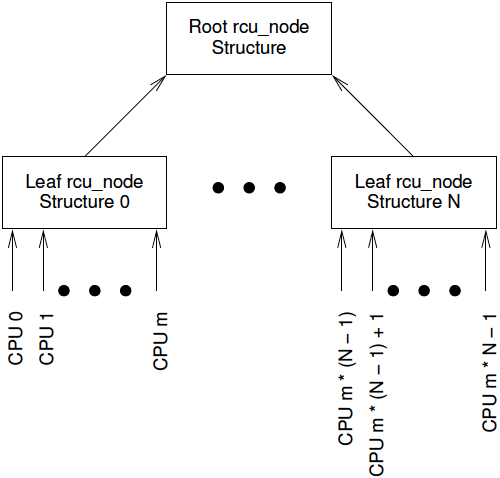
为选出一个胜利者获得critical section的使用权, 需要从下向上进行一场竞赛. CPU首先从叶子节点rcu_node的出发, 尝试获取该节点的fqslock. 如果成功获得锁, 则尝试获取其父亲节点的fqslock. 如果成功获取父节点的锁, 则释放原节点的锁并晋升到其父节点, 依次循环. 如果有CPU成功拿到根节点的fqslock, 说明该CPU获得了critical section的使用权, 在操作前需修改全局变量gp_flags, 该变量用于通知是否有CPU(线程)赢得了本次竞赛. 另外, 每次尝试获取锁前, CPU都需要检查gp_flags. 简易代码实现如下:
void force_quiescent_state(struct rcu_node *rnp_leaf) |