C++ Basic (1)
1. pointer to array / array of pointers
由于[]的优先级比*高, 若想表达一个指向数组的指针, 必须对指针加括号
int *arr[8]; // an array of int pointers |
2. array and pointer
对于数组:
- 当使用
sizeof或者单目操作符&时, 数组作为一个整体 - 其他情况下, 数组会被转化为对应的指针类型, 指向数组的首地址
例如:
- name of array represents the whole array
int arr[5];
printf("%d", sizeof(arr)); // 20 - pointer to array
int arr[5] = {1, 2, 3, 4, 5};
int *p = arr;
printf("%d", *(p + 1)); // 2
printf("%d", sizeof(p)); // 4 - 2d array and pointer
int a[2][3] = {{1, 2, 3}, {4, 5, 6}};
int *p1 = (int*)(&a + 1); // p1为整个数组后的指针(int**)
int (*p2)[3] = a + 1; // p2的类型为(int*)[], 指向{4,5,6}
printf("%d\n", *(p1 - 2)); // p1指向6后面的地址, p1-2指向5
printf("%d\n", *((*p2) + 1)); // p2指向{4,5,6}, (*p2)+1指向5
printf("%d\n", *(a[1] + 1)); // a[1]的类型为int[3], 一个长度为3的数组, 第二个元素为5
printf("%d\n", *(*(a + 1) + 1)); // *(a+1)等同于a[1], 5
printf("%d\n", *(&a[0][0] + 4)); // a[0][0]的类型为int, &a[0][0]的类型为int* - 函数参数
形参为数组类型, 则传过去的实参为数组的第一个元素的指针
3. judege the type of variable
char (*(*x[3])())[5] |
x[3]is an array.*x[3]is an array of pointers.*(*x[3])()is an array of pointers, each pointer is a pointer of function with no parameter.char (*(*x[3])())[5]is an array of pointers, each pointer is a pointer of function with no parameter, and the return of the function is a char array of 5 elements.
4. sizeof()
对于结构体的存储, 编译器遵循两条原则:
- 成员的偏移量必须是该成员大小的整数倍(0被认为是任何数的整数倍)
- 结构体大小必须是所有成员大小的整数倍
以下是两个例子:
struct s1 |
5. default parameter
一旦某个形参被赋予了默认值,它后面的所有形参都必须有默认值
6. Memory layout
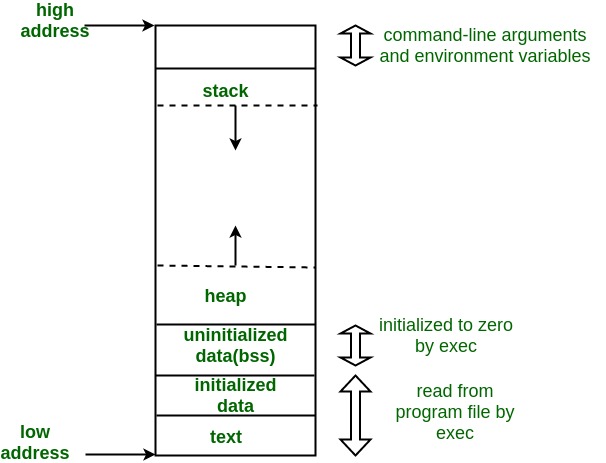
- Stack: 该区域包含program stack, 遵循LIFO. 从低地址开始向高地址扩展, stack pointer始终跟踪stack的顶端, 当添加或弹出数据时, stack pointer的地址改变. 由编译器自动分配释放, 每次调用函数时都会在stack创建一个新的stack frame, 里面存储着函数运行所需要的所有信息.
- Heap: 动态内存申请的区域. 从BBS区域开始向高地址方向扩展. 程序员可通过调用malloc, realloc和free来申请和释放该区域的内存.
- Initialized Data Segment: 包含global, static, constant variable
- Text Segment: 包含代码和可执行指令.
- Uninitialized Data Segment: 未初始化的global和static变量, 将会被内核自动初始化为0和NULL
7. Flexible array
作为struct中的一个成员, 用一个无参数的数组来表示, 必须作为struct中的最后一个成员. 通过为该struct申请多余空间作为变长数组的空间. 如下:
struct vectord { |
8. Three keywords which can be used on variable and function
- static: 静态变量和静态函数都可以在类外访问
- extern: 声明该函数或全局变量的作用范围为本模块和其他模块
- const:
- const变量变为常数, 初始化后不可变
- const函数只能用在成员函数上, 表示不可修改成员变量
- const类对象只能调用const成员函数
9. Location of main Method
但建议main函数放在最下面, 因为在main函数下面的函数必须在main之前声明
void test(); // 必须声明, 否则不能使用 |
10. Operator Precedence
优先级从高到低依次如下:
| Precedence | Operator |
|---|---|
| 1 | :: |
| 2 | a++ a-- type() type{} a() a[] . -> |
| 3 | ++a --a +a -a ! ~ (type) *a &a sizeof new new[] delete delete[] |
| 4 | .* ->* |
| 5 | a*b a/b a%b |
| 6 | a+b a-b |
| 7 | << >> |
| 8 | <=> |
| 9 | < <= > >= |
| 10 | == != |
| 11 | & |
| 12 | ^ |
| 13 | | |
| 14 | && |
| 15 | || |
| 16 | a?b:c throw = += -= *= /= %= <<= >>= &= ^= |= |
| 17 | , |
11. Compare Floating Point Number to Zero
if( abs(f) <= 1e-15 ); // double |
12. Inline Method
由于函数的调用代价很大, 所以为了提高函数效率, 通常在函数定义时使用inline关键字. inline的实现和宏定义相似, 只是将代码在编译时展开到调用处. 但inline只能用于代码行数少于10的函数, 如果代码过长, 反而会影响效率(代码过长)
内联函数只是向编译器发出的一个请求, 编译器可以选择忽略这个请求. 内联函数中不允许出现的内容如下:
- 循环语句(for, while)和switch
- 异常声明
- 递归函数
13. const Variable
const修饰的变量理论上不能被修改, 但可通过强制类型转换来改变内存内容. 但这是undefined behavior(未定义行为), 不能保证每个编译器的结果一致.
const int a = 10; |
14. sizeof(class instance):
- virtual函数: 存在虚函数的话需建立虚函数表, 虚函数表的指针占4字节
- static成员变量属于类域, 不算入对象大小
- 若类为空: 占1字节
- 普通成员函数不算入字节里面
- 对齐法则
15. kernel mode and user mode
CPU将特权级分为0到3, 一共四个等级. 0为最高级, 3为最低级. 硬件上在执行每条指令时都会对指令所具有的特权级做相应的检查. Linux只是用了0级和3级, 作为内核态和用户态的特权级. 以下是用户态到内核态的三种方式
- 系统调用
- 异常
- 外围设备的中断
16. named return value(NRV)
当函数返回一个局部对象时, 需要调用一次构造函数, 一次拷贝构造函数和一次析构函数. 而如果使用NRV优化, 则只需要调用一次构造函数
class A{}; |
17. const and pointer
const char *p1 = "hello"; // const使得字符串变为常量 |
18. cin>>
该操作符是根据后面变量的类型读取数据
- 输入结束条件: Enter, Space, Tab
- 对结束符的处理: 丢弃缓冲区中的结束符(Enter, Space, Tab)
- 若需要输入带有空格的字符串, 可用
getline()
19. Address of Base Class
class C1 { int a; }; |
20. overload, override, hide
- overload(重载):
- 相同的范围(在同一个类中)
- 函数名字相同
- 参数不同(数量和类型不同)
- const成员函数也可构成重载
- virtual关键字不影响重载
- override(覆盖):
- 不同的范围(分别位于派生类与基类)
- 函数名字相同
- 参数相同
- 基类成员函数必须带有virtual
- hide: 派生类的函数屏蔽了同名的基类函数
- 派生类与基类的函数同名, 参数不同: 无论有无virtual, 都隐藏基类函数
- 派生类与基类的函数同名, 参数相同: 若基类没有virtual函数, 则隐藏基类函数
21. Abstract Class
含有纯虚函数(Pure Virtual Function)的类都叫做抽象类(Abstract Class), 抽象类有以下几个特征:
- 抽象类无法实例化. 但可以定义指向抽象类的指针和引用, 用于指向派生类(
A* b = new B();) - 如果继承类没有定义, 那么继承类也变为抽象类
- 抽象类不能作为参数类型, 函数返回类型和显式转换类型
- 虚函数不代表该函数不被实现, 只是表示基类函数都调用子类函数. 纯虚函数才表示不被实现
- 纯虚函数的意义在于提供接口, 用于提供一个缺省接口
22. Order of Execution in Initializer List
类初始化的顺序并不是按照初始化列表的顺序, 而是按照类成员声明的顺序
class C1 { |
23. typedef in C/C++
typedef struct tagMystruct |
- C语言中, tagMystruct只是一个tag, 与"struct"关键字一起使用才能作为一个结构体类型.
Mystruct可作为一个结构体类型tagMystruct m1; // 报错
Mystruct m2; // 正常编译 - C++中,
tagMystruct和Mystruct都可作为结构体类型使用tagMystruct m1; // 正常编译
Mystruct m2; // 正常编译
24. sizeof() in Base Class
由于基类需要在子类中保持完整性, 因此基类的padding不会被消除.
/* C1总共占 4 + 1 + 3 = 8字节 */ |
25. Uninitialized Value in Array
数组未定义的部分默认为0, 例如:
int a[2][3]={{1, 2}, {3, 4}}; |
a为二维数组, 包含两个长度为3的一维数组, 分别为
a[0]: 1 2 0a[1]: 3 4 0
26. #pragma pack(n)
#pragma pack(n)以n字节对齐方式, 变量起始地址的偏移有两种情况:
- 若n大于等于该变量的字节数, 则偏移量遵循默认的对齐方式
- 若n小于该变量的字节数, 则偏移量为n的倍数, 不用满足默认的对齐方式
最后, 结构的总大小必须为占用空间最大的变量占用的空间数的倍数
27. Order of Execution of Initialization
构造函数的调用顺序:
- 基类构造函数:
- 多继承中, 构造函数的调用顺序根据继承的顺序决定
/* 构造顺序: A -> C -> B */
class B: public A, public C - 若使用列表初始化(C++11), 则根据声明顺序决定构造顺序
class A {};
class C {};
/* 构造顺序: C->A->B */
class B {
public:
B(): a(A()), c(C()) {}
~B() {}
C c; // C类第一个声明
A a; // A类第二个声明
};
- 多继承中, 构造函数的调用顺序根据继承的顺序决定
- 类成员对象构造函数: 若有多个成员类对象, 则根据对象声明的顺序决定构造函数的调用顺序
- 派生类构造函数: 类的指针数组并不会调用构造函数
class A {}
int main()
{
A *a[3]; // 没有调用构造函数
A b[3]; // 调用三次构造函数
}
28. Operator Overloading With Friend Function
- 友元函数重载时, 若参数列表长度为1, 则说明是一元操作符
- 成员函数重载时, 若参数列表为空, 则说明是一元操作符(this作为参数)
29. Catalan Number
$ h(n) = C^{n}_{2n} - C^{n + 1}_{2n} = C^{n}_{2n} / (n + 1) $, 适用于出栈情况求和
30. unsigned int + int
有符号整数转化为无符号整数, 负数将变为大数
unsigned int i = 1; |
31. fseek and rewind
|
32. Koenig Lookup
如果你提供给一个函数的参数一个类型(例如: A::X), 那么编译器就会到相应的命名空间(这里是A)中去查找匹配的函数
namespace A |
下面的例子也发生了函数调用混淆, 因为全局f和namespace A下的f冲突
namespace A |
然而以下代码就不存在混淆问题, 因为类成员函数的优先级高于其他namespace中同名函数
namespace A |
33. Derived Class and Based Class
指向子类的基本指针只能作用到子类的virtual函数, 不能作用到子类的non-virtual成员
class Base { |
34. Default Value of Static Variable
全局对象会被初始化为0, 局部变量会被赋予随机值
class C1 { |
35. Class Scope typedef
一般提前声明nested type name, 防止extern type name的覆盖
typedef int type1; |
但如果nested type name放在函数定义的后面, 编译器则会由于类内部类型的变动而报错(函数参数类型或参数数据的选择不会受到影响, 编译器会适当的决策)
typedef int type1; |
以下是报错代码
typedef int type1; |