The Trouble with Distributed Systems
前几章主要讨论的问题是, 系统如何处理出错. 例如, 故障切换, 复制延迟, 事务隔离. 当我们能考虑到系统中可能的边缘情况时, 就可更好地处理它们.
然而, 即使已经讨论了很多问题, 之前几章仍过于乐观, 现实只会更加糟糕. 现在我们会假设任何东西都会出错. 使用分布式系统与在单个机器上编写软件有着根本上的不同: 分布式存在很多特殊的出错方式. 本章将讨论一些实践中出现的错误, 并理解什么可依赖, 什么不可依赖.
1. Faults and Partial Failures
单台计算机上编写的程序会以一个可预测的方式运行: 程序要么成功, 要么不成功. 软件的错误主要由于代码写的不好.
单个计算机上的软件没有根本性的不可靠原因: 当硬件正常运作, 相同的操作总会产生相同的结果. 若出现硬件错误(如内存损坏或连接器松动), 通常会导致整个系统故障(如kernel panic, 蓝屏, 无法启动). 软件在单机上要么正常运行, 要么完全失效, 不会介于两者之间.
这是一个有意为之的计算机设计: 若发生内部错误, 更偏向于让计算机完全崩溃, 而不是返回错误结果, 因为错误原因可能非常复杂, 很难让用户解决. 因此, 计算机隐藏其物理实现, 呈现一个理想化的系统模型. CPU指令也遵循相同的理念: 向内存或磁盘写入数据时, 数据将保持不变, 不会被随机破坏. 从第一台计算机开始, 计算机的设计目的就是always-correct computation(始终正确地计算).
当软件需要在多台机器上运行时, 情况变得完全不同: 分布式系统中没有理想化的系统模型, 必须要面对现实中的各种混乱. 真实世界中会出现各种各样的问题. 就像Coda Hale所说: 在我有限的经验中, 单个数据中心存在多个长期运行的网络分区, 配电单元故障, 交换机故障, 整个数据中心的主干网络故障, 甚至会有卡车撞在数据中心的温度调节系统.
分布式系统中, 尽管系统中的其他部分正常工作, 但也有某些部分会以意想不到的方式损坏, 被称为partial failure(部分失效). 难点在于, 部分失效是不确定的: 当执行一些涉及多个节点和网络的操作时, 有时成功, 有时失败. 我们甚至无法知道执行是否成功, 因为网络传输的时间也是不确定的.
1.1 Cloud Computing and Supercomputing
关于如何构建大型计算系统, 存在以下设计哲学:
- 一种极端是high performance computing(HPC, 高性能计算)领域. 超级计算机拥有上千个CPU, 用于计算密集型的科学计算任务, 如天气预报或分子动力学(模拟原子或分子运动)
- 另一个极端是cloud computing(云计算)领域, 虽然其没有一个明确定义, 但与多租户数据中心, 连接IP网络的商用计算机, 弹性/按需资源分配, 以及计量计费等相关
- 传统企业数据中心处于上述两者之间
不同的设计哲学会导致不同的故障处理方法. 对于超级计算机, 其会频繁地将计算的状态写入持久存储中. 若某个节点宕机, 通常会停止整个集群的工作负载. 待节点恢复后, 从最近的检查点重新开始. 因此, 超级计算机更像是一个单点计算机, 而不是分布式系统: 让部分失败升级为整体失败, 就像单机的内核恐慌.
互联网服务系统与超级计算机存在很多不同之处:
- 大多数互联网相关的应用程序都是online(在线)的, 其需要随时服务用户. 让整个服务不可用(如停止集群以进行维护)是不可接受的. 相比之下, 离线工作(如天气模拟)可被随时暂停或重启
- 超级计算机由专用硬件构成, 每个节点的可靠性都十分高, 节点通过共享内存或remote direct memory access(RDMA, 远程直接内存访问)通信; 云服务中的节点由商用机器构成, 处于成本考虑, 这些硬件以更低的成本提供相同的性能, 但故障率较高
- 大型数据中心网络基于IP和以太网, 以CLOS拓扑排列, 以提供更高的bisection bandwidth(对分带宽); 超级计算机使用专用的网络拓扑, 例如多维网络和Torus网络, 为HPC负载提供更好的性能
- 系统越大, 组件崩溃的概率越高. 随时间推移, 损坏的组件会被修复, 新组件也会损坏, 但在成千上万个节点的系统中, 几乎每时每刻都有组件损坏. 如果一旦遇到错误就停止提供服务, 则系统会花费大量时间修复错误, 而不是做有用的工作
- 若系统可以容忍故障节点, 并继续保持工作状态, 将十分有利于运营和运维: 例如, 可以使用滚动更新, 每次重启单个节点, 同时保持服务不中断. 在云环境中, 若某台虚拟机出现异常, 可中止并重启一台新的虚拟机
- 对于地理位置分散的部署(让数据与用户地理位置更近), 需要通过互联网进行通信. 与本地网络相比, 互联网速度较慢且不可靠. 超级计算机通常假设所有节点都紧密相连.
若想让分布式系统工作, 必须接受随时出故障的可能性, 并建立一套故障容错机制. 换句话说, 需要在不稳定的组件上构建一个可靠的系统.
即使节点数量较少, 也需要考虑部分故障. 对于小型系统, 绝大多数组件都能正常工作. 然而, 系统中的某些部件迟早会出错, 软件必须以某种方式处理. 故障处理必须作为软件设计的一环, 运维人员需要了解发生故障时, 软件会表现出什么行为.
用不可靠的组件构建可靠的系统, 这是计算机领域中的一个古老思想, 例如:
- 纠错码允许数据在通信信道的传输中, 偶尔出现一些错误, 如无限网络上的无线电干扰
- IP(互联网协议)是不可靠的: 可能丢弃, 延迟, 重复, 或重排数据包. TCP(Transmission Control Protocol)在IP的基础上提供了更可靠的传输层: 其会重传丢失的数据包, 移除重复的数据包, 并确保数据包的传输顺序.
虽然上述的系统比其底层系统更可靠, 但也有局限性. 例如, 纠错码只能处理少量的单比特错误; TCP不能消除网络中的延迟. 虽然不完美, 但已经非常有用, 可帮忙处理很多低级错误.
2. Unreliable Networks
分布式系统也称为shared-nothing systems(无共享系统), 即通过网络连接的大量机器. 网络是机器间通信的唯一方式, 每个机器都有自己的内存和磁盘, 且不能直接访问其他机器的内存或磁盘.
无共享并不是构建系统的唯一方式, 但却是构建互联网服务的主要方式, 原因如下:
- 成本较低, 无需特殊硬件
- 可利用商用的云计算服务
- 跨地理分布的数据中心提供冗余, 以实现高可靠性
互联网和数据中心(通常是以太网)中的大多数内部网络是asynchronous packet networks(异步分组网络). 该网络下一个节点向另一个节点发送信息, 网络无法保证该消息何时到达, 或是否到达. 如果节点发送请求并等待回应, 可能会遇到以下问题:
- 请求丢失(网线被拔掉)
- 请求正在排队, 稍后才能被处理(网络或接收方过载)
- 接收方宕机(崩溃或关机)
- 接收方暂时停止响应(长时间的垃圾收集暂停), 稍后再次响应
- 接收方处理了请求, 但响应在网络上丢失
- 接收方处理了请求, 但响应因网络问题而被延迟
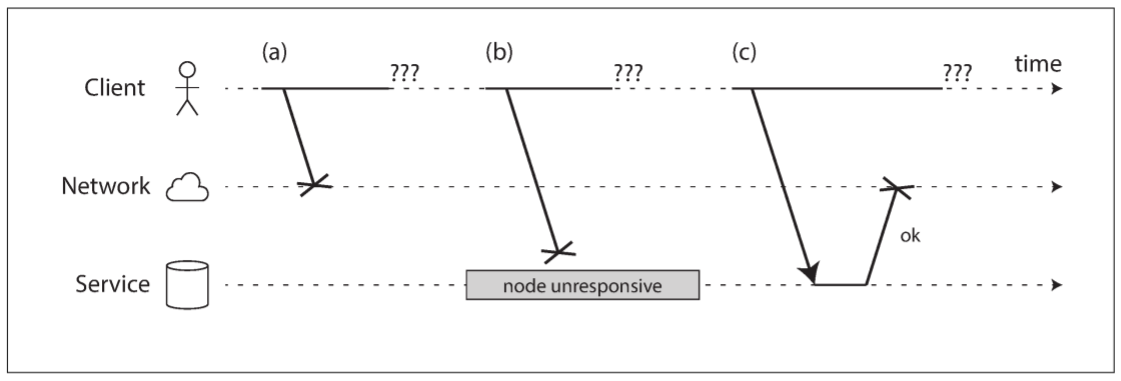
发送者甚至无法判断数据包是否被发送: 唯一选择是等待接收方传回响应, 但响应可能丢失或延迟. 这些问题在异步网络中难以区分: 唯一确定的是尚未收到响应. 如果向其他节点发送请求且没有收到响应, 不可能知道是什么原因导致的.
处理该问题的通用方法是timeout(超时): 一段时间后放弃等待, 并判定该响应不会传达. 即便发生超时, 仍无法知道对方是否收到了请求.
2.1 Network Faults in Practice
计算机网络已经发展了几十年, 有人可能认为我们已经实现了可靠的网络. 然而, 可靠的网络从未实现.
有研究表明, 即使是公司运营的数据中心, 在这种受控环境下也会频繁发生网络问题. 某中型数据中心的研究表明, 平均每月会发生12起网络故障, 其中一半断开一台机器, 一半断开整个机架. 另一项研究评估了top-of-rack switch(架顶式交换机, 每个机柜上部署1~2台交换机), aggregation switch(汇聚交换机, 将多个ToR交换机连接到一个core交换机上), 和load balancer(负载均衡器)的故障率, 添加冗余网络设备并不能像预期那样减少故障率, 因为大部分故障由人为错误导致(如, 错误配置交换机).
公有云服务因频繁的暂态网络(网络由节点构成, 但节点随时离开或加入网络)故障而饱受诟病, 私有数据中心可提供更稳定的网络. 然而, 没有人可不受网络问题的影响: 例如, 交换机软件升级期间的一个问题会导致整个网络拓扑重构, 数据包的延迟可能超过一分钟. 海底电缆也可能被鲨鱼咬坏. 网络接口也可能出问题: 网络链接在某个方向上工作, 而另一方向不工作, 致使所有进站数据包被丢弃, 出站数据包正常发送.
无论何时通过网络进行通信, 都可能失败. 若没有定义或测试处理网络故障的错误处理, 则可能发生各种错误: 例如, 集群死锁, 永久性停止服务, 甚至删除所有数据.
处理网络故障并不意味着容忍错误: 若大部分时间网络都是可靠的, 可在网络故障时向用户显示一条错误信息. 需要明确自己的软件如何处理网络问题, 并确保系统能从网络故障中恢复, 有意识地制造网络故障来测试系统响应.
2.2 Detecting Faults
很多系统都需要自动检测故障节点, 例如:
- Load balancer需停止向已死节点发送请求(如, 移除轮询列表)
- 对于单leader复制的分布式数据库, 若leader宕机, 会将其中一个follower提升为leader
然而, 网络的不确定性让我们很难确定节点是否存活. 某些特定条件下, 可能会收到一些反馈信息, 明确表示某些事情没有成功:
- 如果可以连接到运行节点的机器, 但没有进程监听目标端口(如, 进程崩溃), 系统会发送RST或FIN数据包来关闭并重用TCP连接; 若节点处理请求时崩溃, 则无法知道其实际处理了多少数据
- 若节点的进程崩溃(被管理员kill掉), 但节点的操作系统仍在运行, 可让脚本提醒其他节点, 其他节点就不用等待超时. HBase就是这么做的.
- 若可以访问数据中心中网络交换机的管理界面, 则可以查询硬件级别的链路故障(例如, 远程机器是否关闭电源). 若通过互联网连接, 或处于共享数据中心而无法访问路由器, 或由于网络问题而无法访问管理界面, 则无法使用此方法
- 若路由器发现你尝试连接的IP地址不可用, 则会返回ICMP Destination Unreachable数据包. 然而, 路由器不具备故障检测能力, 其同样受到限制
远程节点关闭的快速响应很有用, 但不能完全依赖. 即使发送了TCP acknowledge, 应用程序也可能在处理前崩溃. 若想确定请求成功, 还需应用程序的响应.
相反, 若出现任何问题, 可能会在堆栈的某个层面上收到一个错误响应, 但必须假设不会收到任何响应. 我们可多次重试(TCP重试是透明的, 但还可以在应用层面重试), 等待超时, 若没有收到响应, 则认为该节点已死.
2.3 Timeouts and Unbounded Delays
如果超时是检测故障的唯一方法, 那么应等待多久? 长时间的超时意味着长时间的等待(在此期间, 用户可能需要等待, 或收到错误信息). 短时间的超时可快速检测到故障, 但会误判节点失效(例如, 由于节点或网络上的负载峰值而响应变慢).
过早声明节点失效存在很大问题: 若节点存活且正在执行一些操作(如发送邮件), 其他节点接管后会重新执行一遍, 导致操作被执行两次.
当节点被宣告死亡, 需将任务分配给其他节点, 这会给其他节点和网络带来额外负载. 若系统已经处于高负荷状态, 过早宣布节点死亡只会让情况更糟糕. 若节点没有死亡, 只是由于过载而响应缓慢, 将负载转移到其他节点可能导致cascading failure(级联失效, 某些极端情况下, 所有节点都认为对方死亡, 所有节点都停止工作).
假设系统中的数据包存在最大延迟: 数据包要么在时间$d$内传达, 要么丢失, 传输时间不会超过$d$. 此外, 假设一个节点可在时间$r$内处理完请求, 因此, 从发送请求到接收响应, 可在$2d+r$时间内完成. 若未收到响应, 则可认为网络或节点失效. 因此, $2d+r$是一个合理的超时设置.
然而, 大多数系统都无法提供上述保证: 异步网络拥有unbounded delays(无上限的延迟, 只能保证尽快发送数据包), 并且绝大多数服务器都无法保证在一定时间内处理请求. 如果超时时间设置的很短, 即使系统中大部分时间都能快速运行, 往返时间只需出现一个瞬间峰值就可以让系统失衡.
2.3.1 Network congestion and queueing
当驾驶车辆时, 通行时间受到交通拥堵的影响. 同理, 数据包延迟受到排队的影响:
- 若多个节点同时向同一目的地发送数据包, 则交换机需将它们排队并依次发往目的地. 若网络链路繁忙, 则数据包需等待一段时间(称为网络拥塞); 若交换机的队列已满, 数据包将被丢弃, 需要重传.
- 当数据包抵达目标机器时, 若所有CPU核心都处于繁忙状态, 操作系统会让请求排队, 直到应用程序准备好处理. 根据机器的负载, 等待时间或长或短.
- 对于虚拟化环境, 由于共享CPU内核, 当其他虚拟机使用CPU时, 操作系统需要暂停几十毫秒. 这时虚拟机无法从网络中获得任何数据, 数据会被虚拟机监视器排队, 进一步增大了网络延迟波动.
- TCP执行flow control(流量控制), 也称为congestion avoidance(拥塞避免): 节点会限制自身的数据发送速率以防止网络链路或接收方过载. 因此, 数据包在进入网络前还要排队.
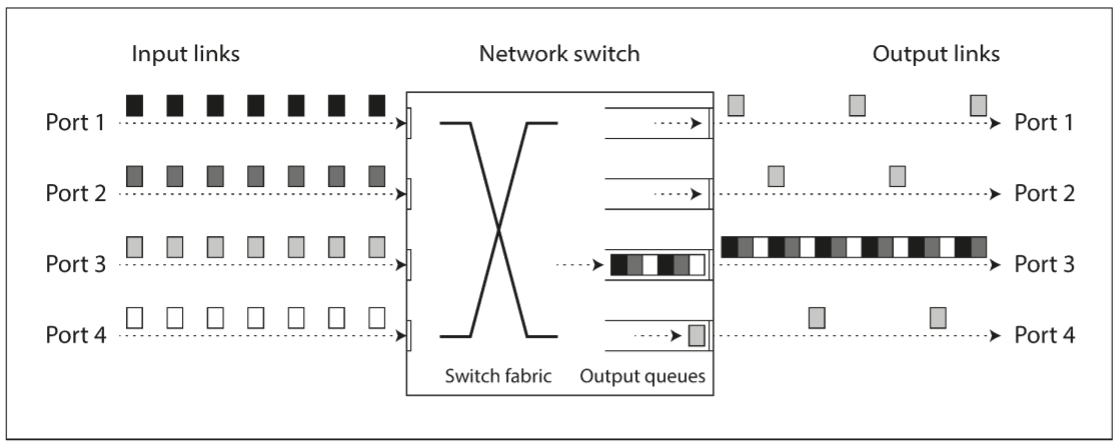
而且, 当TCP发现数据包在一定时间内(根据观察的往返时间计算)未被确认, 会认为数据包丢失, 并自动重传. 尽管应用程序不会觉察到数据包的丢失和重传, 但能感受到延迟(等待数据包超时, 并等待重传的数据包得到确认).
上述因素导致网络延迟波动很大. 当系统接近最大负荷时, 排队延迟的波动范围非常大: 拥有足够备用容量的系统可以轻松清空队列, 然而高负载的系统很容易形成很长的队列.
对于公有云和多租户数据中心, 资源被多个用户共享: 网络链路, 交换机, 甚至机器的网卡和CPU. 批处理工作负载(如MapReduce)很容易让网络链路饱和. 由于无法控制或了解其他用户对共享资源的使用情况, 若附近某个人占用大量资源, 则网络延迟可能发生剧烈波动.
这种环境下, 可通过实验方式选择超时时间: 在一段较长的时间内, 在多台机器上测量网络往返时间的分布, 以确定延迟的预期波动. 然而根据应用程序的特性, 权衡故障检测延迟与过早超时风险之间的利弊.
还可以让系统测量响应时间及其波动, 并根据响应时间分布自动调整超时时间. Akka和Cassandra使用Phi Accrual故障检测器实现. TCP的超时重传机制也是类似的方法.
2.4 Synchronous Versus Asynchronous Networks
若分布式系统运行在固定最大延迟且从不丢包的网络上, 问题会简单很多. 为何不从硬件层面出发, 让网络更加可靠?
为回答这个问题, 需要对比数据中心网络和传统固定电话网络(非蜂窝, 非VoIP): 固定电话网络十分可靠, 延迟的音频帧和掉线都十分罕见. 通话需要很低的端对端延迟, 以及足够的带宽来传输音频采样数据. 为何不在计算机网络中实现类似的可靠性和可预测性?
拨打电话时, 会建立一个电路: 在两个通话者之间的整个路线上, 分配固定且足够的带宽. 整个电路会一直保持到通话结束. 例如, ISDN网络以每秒4000帧的固定速率运行. 当建立某个通话时, 每个帧内分配16位空间(双向). 因此, 通话期间双方都能保证每250微秒发送一个16位的音频数据.
这种网络是synchronous(同步的): 即使数据经过多个跳, 也不会受到排队的影响, 因为网络中的每一跳都为该连接保留了16位空间. 由于没有排队, 网络的最大端对端延迟也是固定的, 被称为bounded delay(有限延迟).
2.4.1 Can we not simply make network delays predictable?
电话网络中的电路与TCP连接完全不同: 电路是一个固定大小的保留带宽, 在电路建立期间, 其他人无法使用该电路; 而TCP连接的数据包会选择任何可用的网络带宽. TCP中的数据包大小不固定(可以是一封邮件或一个网页), 且会尽量以最短时间传送. TCP连接在闲置期间不占用任何带宽.
若数据中心和互联网是circuit-switched network(电路交换网络), 则建立电路时可保证最大往返时间. 然而, 以太网和IP是packet-switched protocol(分组交换协议), 由于排队会带来无限网络延迟, 这些协议没有电路概念.
那么数据中心网络和互联网为什么使用分组交换? 因为它们的设计目标是为了解决突发流量. 电路适用于音频或视频通话, 通话期间需要每秒传输一定数量的比特; 而请求网页, 发送邮件, 或传输文件没有固定的带宽要求, 只希望尽快完成.
若想通过电路传输文件, 需要决定分配的带宽大小: 若分配的太少, 传输会很慢, 导致网络闲置; 若分配的太多, 可能无法建立电路(其他电路占用大量带宽). 因此, 对于突发数据, 电路只会浪费网络带宽并让传输变慢. 相比之下, TCP会根据当前网络带宽来动态调整数据传输速率.
也有一些方法尝试建立混合网络, 同时支持电路交换和分组交换, 例如ATM. InfiniBand也有一些相似之处: 其在链路层实现了端对端的流量控制, 尽管会因链路拥塞而导致延迟, 但可以减少排队需求. 通过使用quality of service(QoS, 服务质量, 数据包的有限集和调度)和admission control(准入控制, 发送端限速), 可在分组网络上模拟电路交换, 或提供统计上的有限延迟.
但多租户数据中心与公用云目前不提供QoS, 无法提供网络延迟或可靠性的任何保证: 我们只能假设网络拥塞, 排队, 和无限延迟随时发生. 结论就是, 超时时间没有统一答案, 只能通过实验确定.
3. Unreliable Clocks
时钟和时间很重要. 应用程序会依赖时钟解决以下问题:
- 请求是否超时
- 这项服务的第99百分位响应时间是多少
- 在过去5分钟内, 这项服务平均每秒处理多少个请求
- 用户在网站上花了多少时间
- 文章何时发布
- 何时发送提醒邮件
- 缓存何时过期
- 日志文件中, 错误信息的时间戳是什么
分布式系统中, 由于通信不是即时的, 时间成为一件很棘手的事情: 消息通过网络从一个节点传输到另一个节点需要一定时间. 消息的接收时间总是晚于消息的发送时间, 由于网络的可变延迟, 无法确定具体晚了多久, 因此很难确定多个节点中某个事情的发生顺序.
而且, 网络上每个机器都有自己的时钟, 这是一个硬件设备: 通常是石英晶体振荡器. 这些设计不是完全准确的, 因此每个机器都有自己的时间, 可能比其他机器稍快或稍慢. 同步时间最常用的方法为Network Time Protocol(NTP, 网络时间协议), 其允许计算机通过一组服务器提供的时间来调整自身时钟. 服务器则从更精确的时间源(如GPS接收机)获取时间.
3.1 Monotonic Versus Time-of-Day Clocks
现代计算机至少有两种时钟: time-of-day clock(日历时钟)和monotonic clock(单调时钟). 虽然它们都用于衡量时间, 但目的不同.
3.1.1 Time-of-day clocks
日历时钟是人们对于时钟的直观印象: 其根据日历(也称为wall-clock time, 挂钟时间)返回当前日期和时间. 例如, Linux的clock_gettime(CLOCK_REALTIME), Java的System.currentTimeMillis(), 它们都返回自epoch(UTC时间1970年1月1号零点)以来的秒数(或毫秒), 不包含闰秒. 有些系统使用其他日期作为参考点.
日历时钟通常与NTP同步, 意味着不同机器的时间戳保持相同. 然而, 日历时钟有很多问题. 若本地时钟比NTP服务器快太多, 可能会被强制重置, 就像穿越到过去. 由于存在时间跳跃以及忽略闰秒, 因此日历时钟不能用于测量elapsed time(经过时间).
日历时钟具有相当粗的颗粒度. 例如, 早期Windows系统上以10毫秒为一个单位.
3.1.2 Monotonic clocks
单调时钟很适合测量持续时间(时间间隔), 例如, 超时或服务的响应时间: Linux的clock_gettime(CLOCK_MONOTONIC), Java的System.nanoTime()都是单调时钟. 该时钟可保证时间总是往前走(日历时钟可以往回跳).
我们可在某个时间点查看单调时钟的值, 之后再次查看, 两个值的差值表示经过了多长时间. 然而, 单调时钟的绝对值没有任何意义: 它可能是计算机启动以来的纳秒数, 或类似的任意值. 比较两台计算机的单调时钟也没有意义.
对于具有多个CPU的服务器, 每个CPU有一个单独的计时器, 但不一定与其他CPU同步. 操作系统会补偿所有的差异, 并尝试表现出单调时钟的样子, 即使这些线程被调度到不同的CPU上. 因此, 不要太依赖于这种单调性保证.
若NTP协议检测到计算机的本地石英钟更快或更慢, 可调整单调时钟前进的频率(也称为skewing clock, 偏移时钟). 默认情况下, NTP允许时钟速率增加或减少最多0.05%, 但NTP不能让单调时钟向前或向后跳跃. 单调时钟的分辨率很好: 大多数系统可测量几微妙或更短的时间间隔.
分布式系统中, 可使用单调时钟测量经过的时间, 因为不需要与其他时钟同步, 并且对测量的准确度没有过高要求.
3.2 Clock Synchronization and Accuracy
单调时钟无需同步, 而日历时钟依赖于NTP服务器或其他外部时间源. 然而, 获得时钟的方法并没有那么简单, 硬件时钟和NTP都存在很多问题:
- 计算机中的石英时钟不够精确: 其会drift(漂移, 即运行速度过快或过慢). 时钟漂移取决于机器的温度. Google认为时钟漂移为200ppm(百万分之一), 即每30秒同步一次的时钟漂移为6毫秒, 每天同步一次的时钟漂移为17秒. 即使一切工作正常, 这种漂移也会限制我们可以达到最佳精确度.
- 若计算机的时钟与NTP服务器的时钟差距过大, 可能会拒绝同步, 或强制重置本地时钟. 应用会看到时间后退或跳跃.
- 若某个节点被NTP服务器的防火墙阻塞, 可能很长一段时间都不会被人觉察. 有证据标明, 这的确在实践中发生过.
- 数据包的延迟会限制NTP同步的准确度. 实验表明, 当通过互联网同步时, 35毫秒的最小误差是可实现的, 偶尔的网络延迟峰值会导致大约一秒的误差. 根据配置, NTP客户端会因网络延迟较大而直接放弃.
- 一些错误配置的NTP服务器, 其报告的时间可能相差几个小时. 由于NTP客户端会查询多个服务器并忽略异常值, 因此具有一定的鲁棒性. 无论如何, 依赖其他人来决定自己系统的正确性, 这比较令人担忧.
- 闰秒会导致一分钟有59秒或61秒, 对于未考虑到闰秒的系统, 这会打破时序的假设. 闰秒已经让很多大型系统崩溃过, 证明了系统会容易出现时钟的错误假设. 处理闰秒的最好方法是让NTP服务器撒谎, 并在一天内逐渐调整闰秒(称为smearing, 托尾).
- 在虚拟机中, 硬件时钟被虚拟化, 这对于需要精确计时的应用提出了额外挑战. 当单个CPU核心被多个虚拟机共享时, 每个虚拟机都会暂停几十毫秒, 与此同时有一个虚拟机正在运行. 从应用程序的角度来看, 这种停顿就像时间突然向前跳跃.
- 如果软件对设备没有控制权(如移动或嵌入式设备), 则无法相信该设备的硬件时钟. 一些用户会将时钟设置为错误的时间. 例如, 为规避时间限制, 用户会将时间设置为过去或未来.
只要投入大量资源, 就可以达到非常好的时钟精度. 例如, 欧洲法规草案MiFID II针对金融机构提出要求: 所有高频交易基金必须在UTC时间100微妙内同步时钟, 以便调试flash crash(闪崩)等市场异常情况, 并帮助检测市场操纵.
通过GPS接收器, Precision Time Protocol(PTP, 精确时间协议), 和仔细部署监控, 就可实现这种精确度. 然而这需大量努力和专业知识, 且很容易导致时钟同步错误: NTP守护进程配置错误, 防火墙阻止NTP通信, 时钟漂移导致时钟误差越来越大.
3.3 Relying on Synchronized Clocks
时钟虽然简单易用, 但存在一些问题: 一天并非准确的86,400秒, 日历时钟可能前后跳跃, 不同节点的时间可能不同.
就像网络一样: 大多数情况下网络/时钟都能正常工作, 但偶尔会出现网络丢包/时钟错误, 软件必须处理这些故障.
不正确的时钟很容易被忽略. 若CPU出错或网络配置错误, 节点很可能无法工作, 很快就能被注意到; 但石英时钟出错, 或NTP客户端配置错误, 尽管时钟偏差越来越大, 但大部分情况仍可以正常工作. 若某些软件依赖于精确同步的时钟, 其后果可能是悄无声息的, 或少量数据丢失, 而不是软件崩溃.
因此, 若软件需要同步时钟, 最好监控各个机器间的时钟偏差. 时钟偏差过大的节点应被宣布死亡, 并从集群中移除. 这样可确保在发生损失前发现出错的时钟.
3.3.1 Timestamps for ordering events
现在考虑一个特殊情况: 依赖时钟对多个节点上的事件进行排序. 例如, 两个客户端写入分布式数据库, 哪个先写入?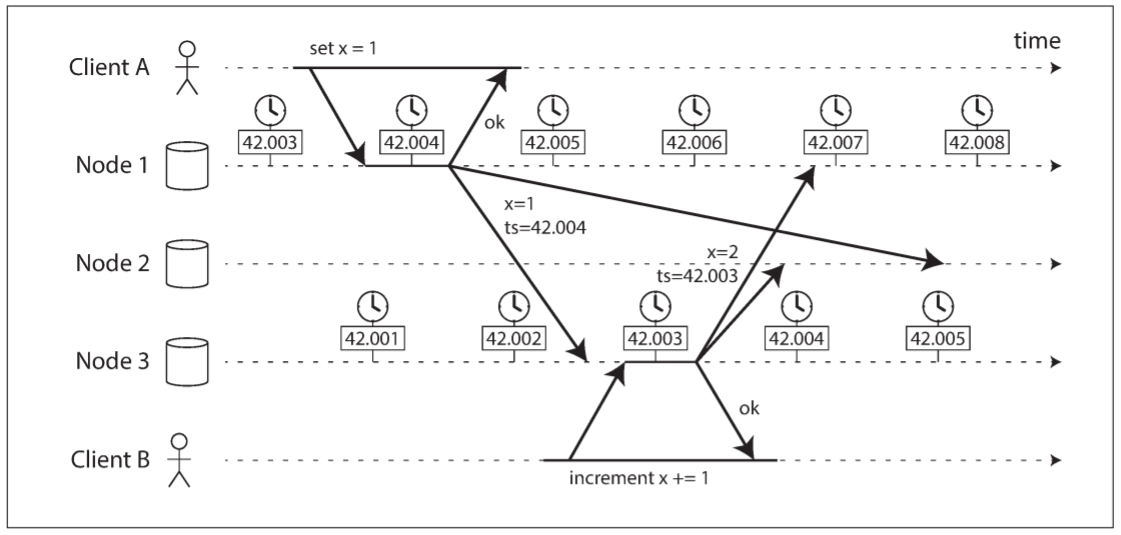
上图为多leader复制的数据库中时钟的危险使用: 客户端A在节点1上写入x = 1, 该写入被复制到节点3; 客户端B在节点3上增加$x$(此时x = 2); 最后, 两个写入被复制到节点2.
当一个写入被复制到其他节点时, 会根据发生写入的节点上的日历时钟生成一个时间戳. 本例中时钟同步的非常好: 节点1和节点3之间的时钟偏差只有3ms.
尽管如此, 时间戳还是无法正确排序事件: 写入请求x = 1的时间戳为42.004秒, 但写入请求x = 2的时间戳为42.003秒, 即使x = 2在x = 1之后出现. 当节点2收到这两个写入, 会错误地认为x = 1才是最新发生的请求, 从而抛弃x = 2, 导致客户端B的写入丢失.
这种冲突解决策略称为last write wins(LWW, 最后写入胜利), 其被广泛用于多leader复制和leaderless数据库, 如Cassandra和Riak. 有些实现会在客户端上生成时间戳, 但这并不能改变LWW的根本问题:
- 数据库写入可能神秘消失: 滞后的节点无法覆盖更快的节点的写入值
- LWW无法区分高频顺序写入(客户端B的写入发生在客户端A的写入之后)和真正并发写入(写入A完全不知道写入B的存在). 需要一些额外的因果关系追踪机制(如版本向量), 以防止违背因果关系.
- 很可能出现两个节点生成相同时间戳的写入, 尤其是时钟只有毫秒分辨率的情况. 这时需要一个额外的tiebreaker(决胜点, 例如随机数)来解决冲突, 但也可能违背因果关系.
因此, 尽管可以通过放弃旧值来解决冲突, 但日历时钟决定了什么是"最近", 这有可能是不正确的. 即使使用严格同步的NTP时钟, 数据包可能在100ms时发送(根据发送者的时钟), 并在99ms时抵达(根据接受者的时钟), 看起来就像数据包还未发送就已抵达.
如果NTP同步精确到一定地步, 能否让排序始终正确? 也许不能, 因为NTP的同步精度不仅与石英漂移有关, 还受到网络往返时间的限制. 为正确排序, 需要一个更精确的时钟.
对于排序事件来说, logical clock(逻辑时钟)是一种更安全的选择, 其基于递增计数器而不是振荡石英晶体. 逻辑时钟不用于测量经过的时间, 日历时钟和单调时钟才用于测量实际经过的时间, 也称为physical clock(物理时钟).
3.3.2 Clock readings have a confidence interval
虽然我们读取微妙甚至纳秒级别的时间, 但这不意味着该事件是准确的. 实际上, 读取的时间大概率是不准确的: 即使每分钟都与本地网络上的NTP服务器同步, 石英时钟的偏差也会达到几毫秒. 公共互联网上NTP服务器, 准确度可能只有几十毫秒, 而且网络拥塞时误差可能超过100毫秒.
因此, 时钟读数不能视作一个时间点, 而是一个时间段: 例如, 系统有95%把握认为当前时间处于第10.3秒到10.5秒. 若时间波动为100ms, 那么时间戳中的毫秒位是没有意义的.
我们可以根据时间源来计算不确定性边界. 若GPS接收器或原子时钟直连到计算机上, 预期的错误范围应由制造商告知; 若从服务器获得时间, 则不确定性取决于三个方面: 上次与服务器同步以来的石英时钟偏差的期望值, NTP服务器的不确定性, 和网络往返时间(假设NTP服务器是可信的).
不幸的是, 大多数系统不会公开这种不确定性: 例如, 调用clock_gettime()时, 返回值不会告诉时间戳的预期错误, 因此无法知道置信区间是5毫秒还是5年.
Spanner中Google TrueTime API是一个例外, 它会告知本地时钟的置信区间. 当查询当前时间时, 会返回两个值: [earliest, latest], 表示可能的最早时间戳和最晚时间戳. 区间的长度取决于本地石英时钟最后一次与时钟源同步后度过了多久时间.
3.3.3 Synchronized clocks for global snapshots
快照隔离是数据库中非常有用的特性, 用于短小快速的读写事务, 或长时间运行的只读事务(如备份或分析). 该隔离级别可在不锁定的情况下同时处理读写事务, 且允许只读事务看到某个时间点的一致性数据.
实现快照隔离的最常见方法为单调递增的事务ID. 若写入发生在快照之后(写入操作拥有更大的事务ID), 则快照事务无法看到该写入. 在单节点数据库中, 一个计数器就可以生成事务ID.
然而, 对于分布在多个机器的数据库, 很难生成一个全局单调递增的事务ID, 因为这需要多节点协作. 事务ID必须反映因果关系: 若事务B读取了事务A写入的数据, 则B必须拥有更大的事务ID, 否则快照无法保持一致. 当存在大量短小快速的事务时, 分布式系统中生成事务ID将成为一个瓶颈.
那么能否使用日历时钟的时间戳作为事务ID? 若时钟具有足够的同步性, 那么更晚的事务会拥有更大的时间戳. 但问题在于时钟精度的不确定性.
Spanner使用以下方法来实现跨数据中心的快照隔离: 其使用TrueTime API返回的时钟置信区间, 并基于以下观察结果: 若存在两个置信区间, 每个置信区间都有一个最早时间戳和一个最晚时间戳($A = [A_{earliest}, A_{latest}]$, $B=[B_{earliest}, B_{latest}]$), 且两者没有重叠(即$A_{earliest} < A_{latest} < B_{earliest} < B_{latest}$), 那么B肯定发生在A之后. 只有两个区间重叠时才无法确定先后顺序.
为了确保时间戳能正确反映因果关系, 提交读写事务前, Spanner会故意等待置信区间长度的时间. 这么做可以确保任何读取事务都处于足够晚的时间点, 保证它们的置信区间不会重叠. 为了保证等待时间足够短, Spanner需要保证时钟的不确定性尽可能的小. 为此, Google会为每个数据中心部署一个GPS接收器或原子时钟, 让时钟同步保持在7ms之内.
3.4 Process Pauses
接下来考虑分布式系统中一个危险时钟的例子. 假设某个数据库中, 每个分区只有一个leader, 且只有leader才能处理写入. 那么节点如何知道leader仍存活(leader可能被其他人宣告死亡), 并确保其能安全地接收写入?
其中一个方法为, 让leader从其他节点获取一个lease(租约), 类似一个带有超时的锁. 同一时间只有一个节点可以持有lease, 因此, 若节点持有lease, 则该节点在这段时间内可认为自己是leader, 直到租约到期. 为了保持leader地位, 节点必须在lease过期前续约. 若节点崩溃则不会续约, 超时后会由其他节点接管. 请求处理循环如下图:
while (true) { |
上述代码存在两个问题:
- 首先, 其依赖于同步时钟, lease到期时间由另一个机器配置(例如, 到期时间 = 当前时间 + 30秒), 并将其与本地时钟比较. 若时钟的同步偏差超过数秒, 代码很容易出错.
- 其次, 即使我们将协议改为本地单调时钟, 也存在一个问题: 代码会假设
System.currentTimeMillis()与process(request)之间的时间间隔很短. 通常代码运行的很快, 因此10秒的间隔足够保证处理请求时lease不会失效. 然而, 如果程序执行中出现意外停顿, 如线程在lease.isValid()周围停止了15秒. 这时lease已经失效, 其他节点已经成为新的leader. 然而线程无法意识到暂停, 因此不会注意到lease已过期, 直到下次循环才会意识到, 这期间可能错误地处理了请求.
然而线程可能暂停这么久么? 以下是几种可能性:
- 很多编程语言运行时(例如Java Virtual Machine)的garbage collector(GC, 垃圾收集)会暂停所有运行中的线程. 这种"stop-the-world"GC暂停有时会持续数分钟. 即使是HotSpot JVM这样的并发垃圾收集也不能完全让应用程序代码并发执行, 虽然可通过调整GC设置来减少暂停时长, 但也要假设最坏情况的发生.
- 在虚拟化环境中, 虚拟机会被挂起(暂停执行所有进程并将内存保存到磁盘)并恢复(恢复内存内容并继续执行). 这种暂停会在任何时间发生, 并持续任意长时间. 这种特性可让虚拟机在不重启的情况下从一台机器迁移到另一台机器, 暂停的时长取决于进程写入内存的速率.
- 对于终端用户设备(如笔记本电脑), 执行可能随时被暂停, 也可能随时被恢复. 例如, 用户盖上笔记本.
- 当操作系统上下文切换到另一个线程时, 或管理程序切换到其他虚拟机时, 当前运行的线程随时会被暂停. 花费在其他虚拟机的CPU时间称为steal time(窃取时间). 若机器处于高负荷下, 被暂停的线程需要很长时间才会被恢复(即大量线程在队列中排队)
- 若应用程序执行同步磁盘访问, 则线程会因等待磁盘I/O操作而被暂停. 即使代码中没有访问磁盘, 也可能随时磁盘访问, 例如, Java类加载器会在第一次使用时加载class文件. I/O暂停和GC暂停也可能同时发生. 若磁盘是一个网络文件系统或网络块设备, I/O延迟会进一步受到网络延迟的影响.
- 若操作系统允许paging(页面交换), 每次内存访问都可能导致page fault(页面错误), 并将磁盘中页面加载到内存中. 执行I/O操作时会暂停线程. 若内存压力过大, 则需将其他页面放回磁盘中. 极端情况下, 操作系统的绝大多数时间都在磁盘和内存之间来回搬运数据, 只有少部分时间用于工作(称为thrashing, 抖动). 为避免上述情况, 服务器会关闭页面调度(宁愿kill一个进程来释放内存, 也不愿看到抖动).
- 向UNIX进程发送SIGSTOP信号可暂停进程. 例如, 在shell中按Ctrl-Z. 收到信号的进程将无法执行更多CPU周期, 直到收到SIGCONT信号才能恢复. 即使其他进程不发送SIGSTOP, 运维工程师也可能意外发送该信号.
上述所有事件都随时可能prermpt(抢占)运行中的线程, 并在稍后恢复, 而线程无法注意到暂停. 该问题类似于多线程的线程安全: 无法对时序做出任何保证, 因为随时发生上下文切换或并发执行.
在单机上编写多线程代码时, 我们有很多保证线程安全的工具: mutexes, semaphores, atomic, counters, lock-free, blocking queue等数据结构. 然而这些工具不能直接用于分布式系统, 因为分布式系统没有共享内存, 消息只能通过网络传输.
3.4.1 Response time guarantees
在很多编程语言和操作系统中, 线程和进程可能被暂停任意时间. 只要投入足够精力, 这些暂停是可以被消除的. 某些软件的运行环境要求很高, 如果不能在特定时间内做出响应, 可能导致严重后果, 例如: 控制飞机, 火箭, 机器人, 汽车等, 系统必须对这些对象传感器的输入做出快速且可预测的响应. 这些系统的软件必须有一个特定的deadline(截止时间); 若无法在截止日期前完成, 可能导致整个系统的崩溃, 称为hard real-time system(硬实时系统).
例如, 当车辆传感器检测到碰撞时, 必须保证安全气囊及时弹出, 而不是因GC暂停而延迟弹出.
这种实时保证需要每一级软件栈的支持: 一个real-time operating system(RTOS, 实时操作系统)能保证在一定时间内CPU时间的分配; 库函数必须标注最坏情况下的执行时间; 动态内存分配会受到限制或禁止(实时垃圾收集依然存在, 但应用必须确保其不会给GC太大压力); 还需大量测试和测量以确保达成保证.
所有这些都需大量工作, 严重限制了可用的编程语言, 库, 和工具(因为绝大多数语言和工具都不提供实时保证). 出于上述原因, 开发一个实时系统代价昂贵, 因此主要用于安全要求较高的嵌入式设备. 而且"实时"并不等于"高性能", 由于实时系统需保证及时响应, 其吞吐量往往更低.
对于大多数服务器端的数据处理系统, 实时保证既不划算也不合适. 系统必须能忍受非实时环境中的暂停和时钟不稳定性.
3.4.2 Limiting the impact of garbage collection
即使不借助实时调度保证, 也可以缓解进程暂停的影响. 语言运行时在计划垃圾收集时拥有一定灵活性, 因为它可以跟踪对象分配的速率, 还有剩余的空闲内存.
其实可将GC暂停视为一个短暂且计划内的节点中断, 并让其他节点在该节点进行垃圾收集时接管工作. 若runtime能提醒应用即将有一个GC暂停, 应用可停止向该节点发送新的请求, 等待其处理未完成的请求, 然后在没有请求时进行GC. 这种方法可向客户端隐藏GC暂停, 并降低响应时间的高百分比. 对于延迟敏感的金融交易系统会使用这种方法.
该方法还有一个变体: 只对存活时间较短的对象使用垃圾收集(可快速回收), 并定期重启进程(避免garbage collector花费大量时间回收长期存在的对象). 每次重启一个节点, 并在重启前将流量转移到其他节点, 就像滚动升级.
这些方法都不能完全避免垃圾收集暂停, 但可减少其对应用的影响.
4. Knowledge, Truth, and Lies
迄今为止, 我们已经讨论了分布式系统与单机程序的不同: 没有共享内存, 只能通过可变延迟的不可靠网络传输消息, 系统会遭遇部分失效, 不可靠的时钟, 和处理暂停.
如果不习惯分布式系统, 上述问题的影响会让人十分困惑. 网络上的节点无法明确任何事, 只能通过网络传回的消息猜测. 节点间只能通过交换消息来推断对方的状态(存储了什么数据, 是否正确运行等). 若没有响应, 则无法知道其状态, 因为无法辨别是网络问题还是节点问题.
对这类系统的讨论类似于哲学: 系统中什么是真, 什么是假? 如果感知和测量都是不可靠的, 我们又如何相信所得的知识? 软件系统是否应该遵循我们对物理世界的期望, 如因果关系.
在分布式系统中, 我们可以对于行为(系统模型)做出假设, 并以符合假设为目的来设计系统. 特定系统模型中, 算法是可被证明在某个系统模型中正确工作. 这意味着, 即使底层系统模型提供了较少的保证, 也可实现可靠的行为.
4.1 The Truth Is Defined by the Majority
假设存在一个非对称故障的网络: 节点可接受到所有其他节点传来的消息, 但该节点发出的消息会被丢弃或延迟. 即使该节点运行正常, 且一直接收其他节点的请求, 其他节点也无法收到响应. 一段时间后, 其他节点会宣判该节点死亡.
半断开的节点可能注意到, 其所发送的消息没有被其他节点确认, 并意识到存在网络故障. 然而该节点已被其他节点宣判死亡, 该节点对此也无能为力.
假设某个节点经历了一个长时间的垃圾收集暂停, 节点内的所有线程都因GC而暂停一分钟, 没有任何请求被处理, 也未发送任何消息. 其他节点等待并重试后, 最终宣判该节点死亡. 当GC完成时, 节点内的线程恢复运行, 好似什么都未发生. 然而其他节点会感到惊讶, 因为被宣判死亡的节点传回了消息. GC后的节点甚至没有意识到已经度过了一分钟, 从自身的角度来看, 几乎没有经过任何时间.
上述情况表明, 节点无法完全相信自己的判断. 分布式系统也不能完全依赖单个节点, 因为节点随时可能失效, 并让整个系统卡住. 因此, 许多分布式算法依赖于quorum(法定人数), 即节点间进行投票: 为减少特定节点的依赖, 决策需多个节点的最少投票数.
决策可以做很多事, 其中包括宣判某个节点死亡. 若法定数量的节点认为某个节点死亡, 即使该节点自认为存活, 也会被认为已死, 节点必须服从投票决策.
最常见的法定人数为超过一半的绝对多数. 即使单个节点发生故障, 多数法定人数也可保证系统继续工作(3个节点时, 可容许1个节点失效; 5个节点时, 可容许2个节点失效).
4.1.1 The leader and the lock
系统中某些事物只能同时存在一个, 例如:
- 一个数据库分区的leader只能有一个节点, 以避免split brain(脑裂)
- 特定资源的锁或对象只允许一个事务或客户端拥有, 以避免同时写入和数据损坏
- 一个用户名只能由一个用户注册, 因为用户名用于唯一标识某个用户
实现分布式系统时需要注意: 节点认为自己是被选中的人(分区的leader, 锁的拥有者, 请求的处理者), 然而这并不意味着法定人数的节点同意. 节点可能曾经是leader, 但被其他节点宣判死亡(因网络中断或GC暂停), 则其可能已经被降级, 并由另一个leader替代.
若大多数节点宣判其死亡, 但该节点仍表现依旧, 则会导致很多问题. 该节点会向其他节点发送消息, 若其他节点相信了, 整个系统都会出错.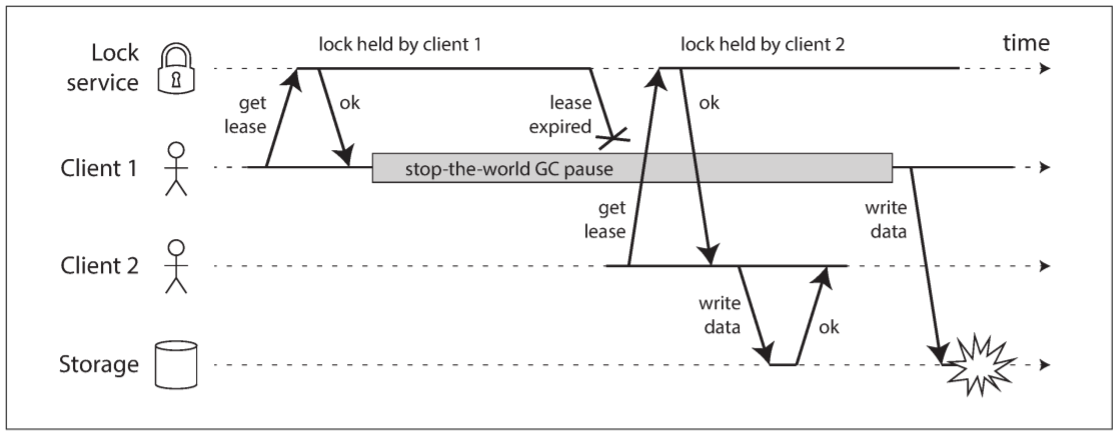
上图中, 不正确的锁实现会导致数据损坏(该bug曾出现在HBase中). 假设我们希望存储设备中的文件在同一时间只能被一个客户端访问, 客户端需要在访问文件前从lock service获得一个lease(租约).
若持有lease的客户端被暂停很久, 暂停期间lease已经过期, 而另一个客户端已经获得该文件的lease并开始访问文件. 当第一个客户端恢复运行时, 会认为自己的lease依然生效, 写入文件将导致数据损坏.
4.1.2 Fencing tokens
当使用lock或lease来保护资源的访问时, 需防止误认为自己lease依然生效的节点继续访问资源. 实现这一目标的技术称为fencing(防护), 如下图: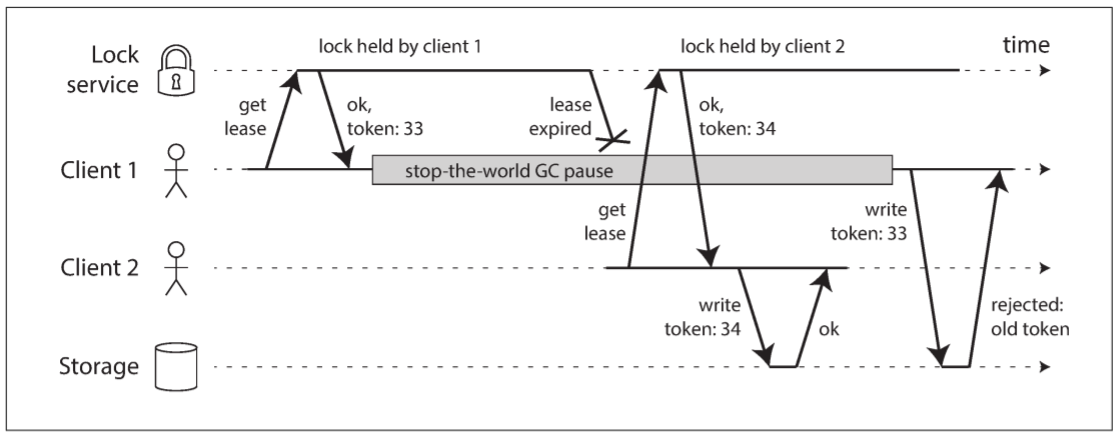
Lock service不仅授予lock或lease, 还会返回一个fencing token(防护令牌), 该token是一个单调递增的数值, 每次授予时会自增. 当客户端访问存储设备时, 必须携带这个token.
上图中, 客户端1持有的lease的token为33, 但在暂停期间而过期. 客户端2持有的lease的token为34, 并向存储设备发送写请求. 之后客户端1恢复运行并向存储设备发送写请求. 然而, 存储设备已经记录了一个更高的token(34), 因此会拒绝token为33的请求.
若将ZooKeeper作为lock service, 可将事务ID zxid或节点版本号cversion作为token, 因为这些值都保证单调递增.
该机制需要资源本身去检查token, 并拒绝较小token的请求, 不能只依赖客户端自身检查lease是否过期. 对于不支持token的资源, 也可通过其他方法解决(例如, 对于文件存储服务, 可将token放在文件名中).
服务器端检查token看起来像是个缺点, 但其实是件好事: 服务不应假设客户端做出行为总是正确的, 因为使用客户端的人与运维服务的人的目的不同, 需防止个别客户端的滥用服务.
4.2 Byzantine Faults
Fencing token可检测和阻止错误节点(节点未发现lease已过期). 然而, 若节点有意破坏, 可使用假token来发送消息.
目前为止, 我们假设节点不可靠, 但一定是诚实的: 节点可能响应缓慢或不回复(由于发生错误), 状态可能是过时的(由于GC暂停或网络延迟), 但节点的所有回应一定不是谎话: 节点按照协定规定扮演着自己的角色.
如果节点可能撒谎, 分布式系统的问题会更加复杂. 例如, 节点谎称没有收到消息. 这种行为称为Byzantine fault(拜占庭故障), 在不信任的环境下达成共识的问题被称为Byzantine Generals Problem(拜占庭将军问题).
即使某些节点发生故障, 不遵守协议, 或恶意攻击, 干扰网络, 系统仍能正确工作, 则该系统称为Byzantine fault-tolerant(拜占庭容错)的. 特定情况下, 这种担忧是有意义的:
- 在航空航天环境中, 内存或CPU寄存器中的数据可能因辐射而被损坏, 导致以不可预料的方式响应其他节点: 由于这种故障代价很大(例如, 飞机坠毁导致人员伤亡, 火箭与国际空间站相撞), 飞行控制系统必须容忍拜占庭故障.
- 对于多个机构参与的系统, 某些参与者可能会欺骗他人. 因此节点无法完全相信其他节点, 因为消息可能出于恶意目的而发送的. P2P网络(对等网络)可在不依赖中心机构的基础上(如Bitcoin)让互不信任的双方同意交易是否发生.
本书假设系统中没有拜占庭故障. 数据中心内所有节点都由自己控制, 辐射水平很低, 且内存故障不是大问题. 让系统实现拜占庭容错的协议十分复杂, 而且可以容错的嵌入式系统依赖于硬件支持. 对于大多数数据系统, 部署拜占庭式容错的成本过高.
Web应用程序需防止来自客户端的恶意行为, 因为终端由用户控制(如浏览器). 这就是为什么网页需要输入验证, 数据清洗, 和输出转义: 为防止SQL注入和跨站点脚本. 通常我们不会使用拜占庭容错协议, 而是让服务器来决定是否允许客户端的行为. 对于P2P网络, 由于没有一个权威中心, 因此拜占庭容错更重要.
软件中的bug也会被视为拜占庭式错误, 但若将软件部署到所有节点上, 拜占庭容错算法也无法防止这类问题. 绝大多数拜占庭容错算法要求超过$2/3$的节点正常运行(假设有四个节点, 最多只能有一个节点失效). 为防止软件bug, 至少需要四个独立实现的相同软件, 并期望bug只出现在其中一个实现中.
能够免受漏洞, 安全渗透和恶意攻击的协议并不存在: 在绝大多数系统中, 若攻击者可渗透一个节点, 那么就可以渗透所有节点, 因为它们可能运行着相同的软件. 因此, 传统机制(认证, 访问控制, 加密, 防火墙等)仍是抵御攻击者的主要保护措施.
4.2.1 Weak forms of lying
虽然我们假设节点都说实话, 但仍可为系统添加一些机制来防止一些撒谎(如硬件问题, 软件bug, 和错误配置). 这种保护机制并不是完全的拜占庭容错, 但实现简单, 且能提高可靠性. 例如:
- 网络, 操作系统, 驱动或路由器内的问题会导致数据包损坏. 通常来说, TCP和UDP的内置checksum会检测到数据损坏, 但也有小概率逃脱检查. 对于这种数据损坏, 检测方法很简单, 在应用层面协议添加一个checksum.
- 可公开访问的应用程序必须仔细检查用户输入, 例如, 输入值是否在合理范围内, 检查字符串大小以防止超出内存. 防火墙后的内部服务不用严格检查输入, 但可以采取一些合理性检查.
- NTP客户端可配置多个服务器地址. 同步时钟时, 客户端会联系所有服务器, 估算偏差, 并检查大多数服务器是否对某个时间范围达成一致. 只要大多数服务器没问题, 就可排除配置错误的NTP服务器. 使用多个NTP服务器比单个服务器更健壮.
4.3 System Model and Reality
分布式系统内的算法不应过度依赖硬件或软件配置. 这要求我们将系统中可能出现的错误形式化. 通过定义一个system model(系统模型)可做到这一点, 用于描述算法可以假设的事情.
关于时序假设, 以下三种系统模型最常用:
- Synchronous model(同步模型): 假设网络延迟, 进程暂停, 和时钟误差都是bounded(有界的). 这并不意味着完全同步的时钟或零网络延迟, 只表示网络延迟, 暂停, 和时钟漂移不会超过某个固定上限. 对于大多数系统, 由于总会发生无上限的延迟和暂停, 这种模型很难实现.
- Partially synchronous model(部分同步模型): 大部分情况下和同步模型一样, 但有时网络延迟, 进程暂停, 时钟漂移会超出界限. 这就是大多数系统的模型: 大多数时间中网络和进程都表现正常, 但任何时候都会打破时序假设, 这时网络延迟, 暂停, 时钟错误会非常大.
- Asynchronous model(异步模型): 不对时序做任何假设, 甚至没有任何时钟(因此不能使用超时). 异步模型的算法非常受限.
除了时序问题, 还要考虑节点失效. 以下是三种最常用的节点系统模型:
- Crash-stop faults(崩溃-停止故障): 该模型中, 节点只有一种失效方式, 就是crushing(崩溃). 这意味着, 节点会突然停止回应, 且永远不会上线.
- Crash-recovery faults(崩溃-恢复故障): 该模型中, 节点会随时崩溃, 且会在之后恢复运行. 这里假设节点具有稳定的存储(非易失性磁盘存储)且会在崩溃时保存数据, 而内存中的状态会丢失.
- Byzantine faults(拜占庭故障): 节点可做任何事情, 包括欺骗其他节点.
对于真实系统的建模, 具有crash-recovery的部分同步模型是最合适的模型. 但分布式算法如何应对这种模型?
4.3.1 Correctness of an algorithm
为了定义算法的正确性, 需先描述算法的properties(属性). 例如, 排序算法的输出具有的属性: 任意两个元素, 左侧的元素小于右侧的元素. 这只是定义排序列表的一种形式.
因此, 我们也可以定义分布式算法的属性, 以此定义正确性. 例如, 当为lock生成fencing token时, 所需的算法应具有以下属性:
- Uniqueness(唯一性): 任意两个token必须是不同值
- Monotonic sequence(单调序列): 若请求x返回token $t_{x}$, 请求y返回token $t_{y}$, 且x在y开始之前已经完成, 则$t_{x} < t_{y}$
- Availability(可用性): 若请求token的节点没有崩溃, 则最终会收到响应
如果一个算法在任何情况下总能满足属性, 那么这个算法就是正确的. 但这又有何意义? 若所有节点崩溃, 或所有网络延迟都无限长, 那么没有算法能完成任何事情.
4.3.2 Safety and liveness
为了澄清这种情况, 需区分两种不同的属性: safety(安全)和liveness(活性). 其中, uniqueness(单一性)和monotonic sequence(单调序列)是安全属性, 而availability(可用性)则是活性属性.
如何区分这两种属性? 活性属性通常在定义中包含eventually(最终)一词, 最终一致性就是活性属性.
安全的非正式定义为: 没有坏事发生. 而活性定义为: 好事终将发生. 但好和坏是主观的, 安全和活性的实际定义为:
- 若违反了安全属性, 则我们可找到一个破坏安全属性的时间点. 例如, 若违背了唯一性属性, 则可以确定重复的fencing token被返回的特定操作. 违法安全属性后, 违规操作无法撤销, 因为损失已经发生.
- 活性属性则反过来: 某个时间点可能不成立(例如, 节点发送请求后一直收不到响应), 但总是希望之后能成立(接收到响应).
之所以区分安全属性和活性属性, 是为了处理困难的系统模型. 对于分布式算法, 在系统模型的所有情况下, 通常要求其一直保证安全属性. 也就是说, 即使所有节点崩溃, 或整个网络瘫痪, 算法仍必须确保其不会返回错误结果.
然而, 对于活性属性, 我们可提出一些注意事项: 例如, 只有大多数节点未崩溃时, 或只有当网络恢复时, 我们才能说请求需要接收响应. 部分同步模型的定义要求系统最终必须回到同步状态, 即任何网络中断只会持续一段时间, 最终都会恢复.
4.3.3 Mapping system models to the real world
安全属性, 活性属性, 以及系统模型对于验证分布式算法的正确性非常有用. 然而实践算法时, 现实中会出现更加复杂的情况, 系统模型只是对现实的简化抽象.
例如, 在crash-recovery模型中, 算法通常假设存储设备中的数据在崩溃时依然保留. 但若磁盘中的数据损坏, 或由于硬件错误导致数据被抹除, 又会发生什么? 若服务器存在固件错误且在重启后无法识别硬盘驱动器, 又会发生什么?
法定人数算法需要节点记住其声称保存过的数据. 若某个节点忘记了之前存储的数据, 则会破坏法定人数的前提条件, 并因此破坏算法的正确性. 或许需要一个新的系统模型, 该模型假设大部分情况下存储设备在崩溃后仍保留数据, 但有时会丢失数据, 但这种模型更难推理.
算法的理论描述会假设某些事情不会发生, 在非拜占庭系统中, 我们需要对可能发生和不可能发生的故障做出假设. 然而在真实世界中, 仍会出现一些"不可能发生"的故障.
但抽象的系统模型并非毫无用处, 恰恰相反, 这些模型可将实际系统的复杂性提取成一个个可推理, 可处理的错误类型, 以便我们理解这个问题.
证明一个算法正确并不意味着它在现实系统中的实现就能如愿以偿. 但这迈出了很好的第一步, 因为理论分析可将隐藏在系统中的问题暴露出来, 这些问题通常会在异常环境中打破假设并暴露出来.