System Design - News Feed
1. Understand the problem and establish design scope
- Is this a mobile app or a web app: Both
- What are the important features: A user can publish a post and see her friends' posts on the news feed page
- Is the news feed sorted by reverse chronological order or any particular order: the feed is sorted by reverse chronological order
- How many friends can a user have: 5000
- What is the traffic volume: 10 million DAU
- Can feed contain images, videos, or just text: It can contain media files, including both images and videos.
2. Propose high-level design and get buy-in
The design is divided into two flows:
- Feed publishing: when a user publishes a post, data is written into cache and database. A post is populated to her friends' news feed.
- Newsfeed building: the news feed is built by aggregating friends' posts in reverse chronological order
2.1 Newsfeed APIs
- Feed publishing API: client sends a HTTP POST request to the server to publish a post. For example:
POST /v1/me/feed, params:- content: content is the text of the post
- auth_token: it is used to authenticate API request
- Newsfeed retrieval API: client sends a HTTP GET request to the server to retrieve news feed. For example:
GET /v1/me/feed, params:- auth_token: it is used to authenticate API requests
2.2 Feed publishing
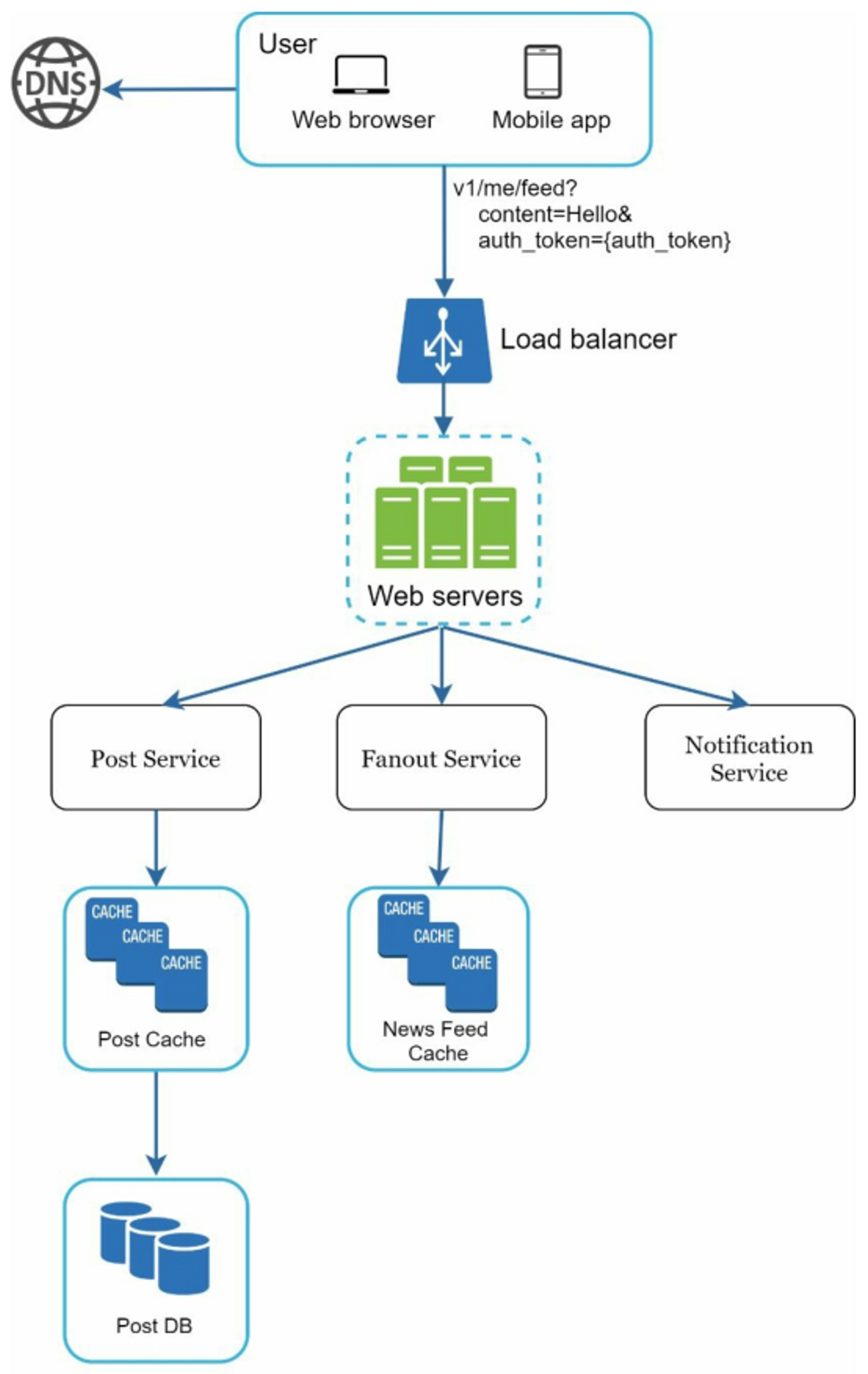
- User: user can view news feeds on a browser or mobile app
- Load balancer: distribute traffic to web servers
- Web servers: redirect traffic to different internal services
- Post service: persist post in the database and cache
- Fanout service: push new content to friends' news feed. Newsfeed data is stored in the cache for fast retrieval
- Notification service: inform friends that new content is available and send out push notifications
2.3 Newsfeed building
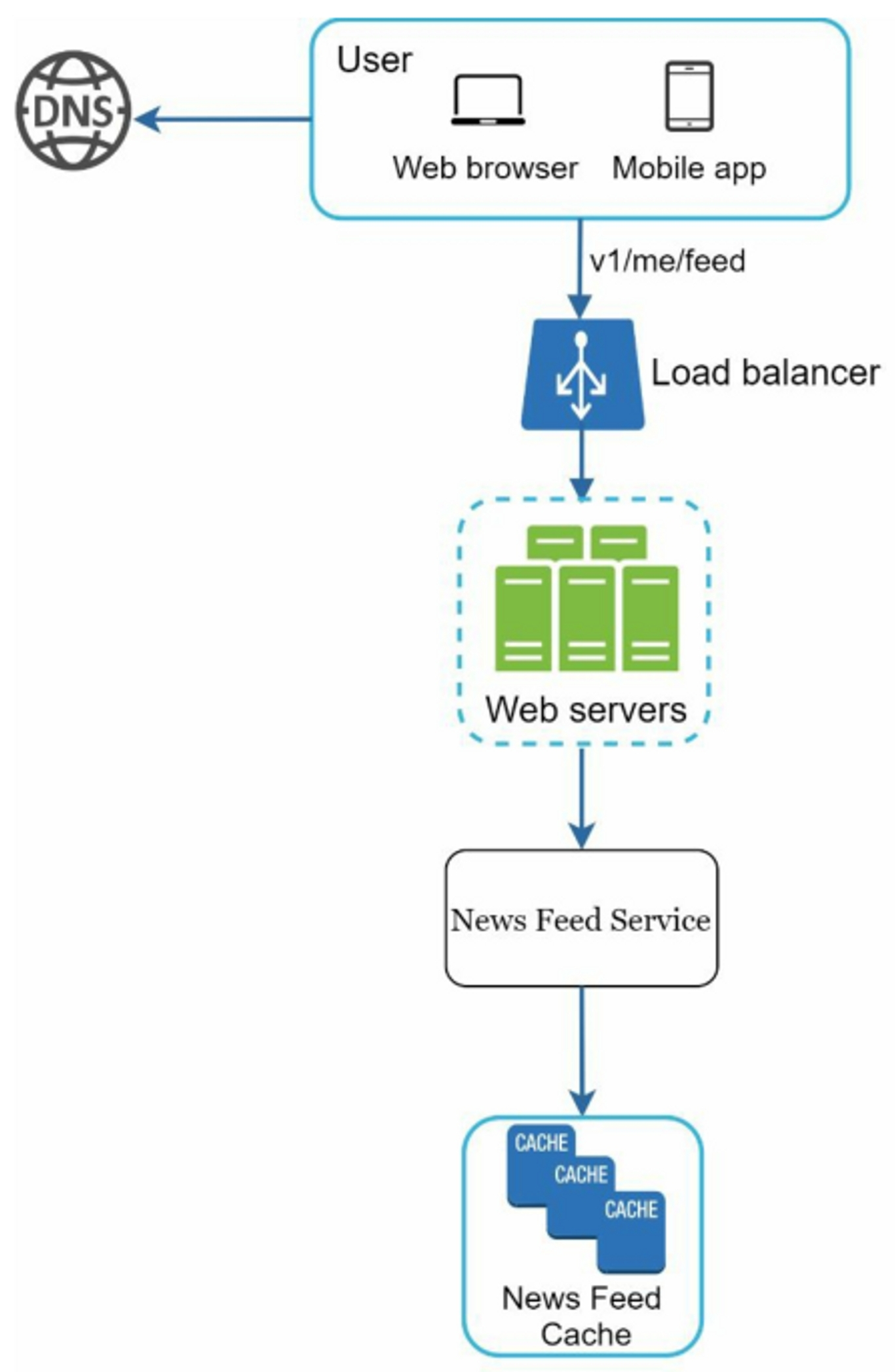
- User: send a request to retrieve her news feed
- Load balancer: distribute traffic to web servers
- Web servers: redirect requests to newsfeed service
- Newsfeed service: fetch news feed from the cache
- Newsfeed cache: store news feed IDs needed to render the news feed
3. Design deep dive
The high-level design briefly covered two flows: feed publishing and news feed building.
3.1 Feed publishing deep dive
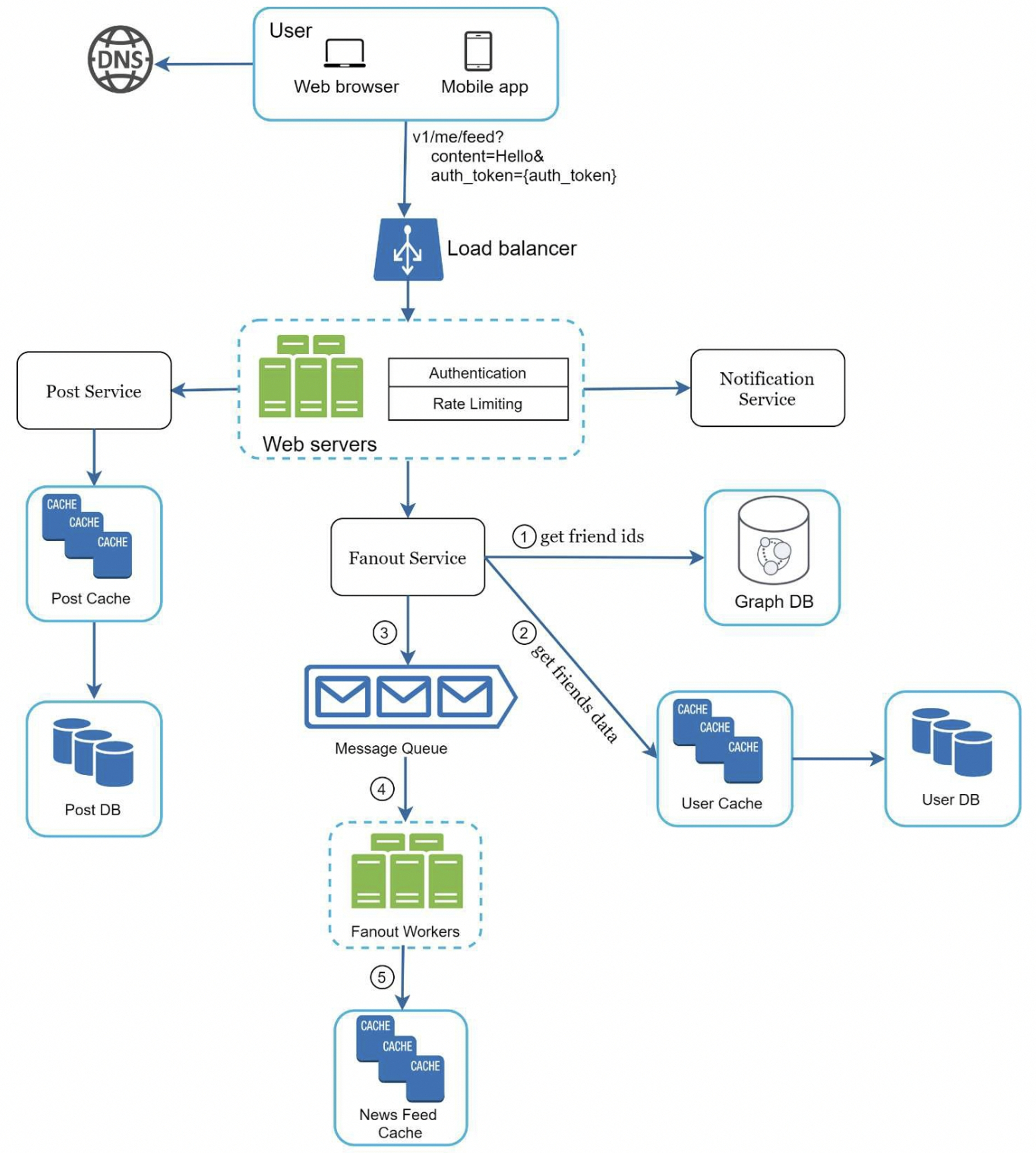
We will focus on two components:
- Web servers: only users signed in with valid
auth_tokenare allowed to make posts. The system limits the number of posts a user can make within a certain period, prevent spam and abusive content - fanout service: Fanout is the process of delivering a post to all friends. Two types of fanout models: fanout on write (also called push model) and fanout on read (also called pull model)
3.2 Fanout on write
News feed is pre-computed during write time. A new post is delivered to friends' cache immediately after it is published.
- Pros:
- The news feed can be pushed to friends immediately
- Fetching news feed is fast because the news feed is pre-computed
- Cons:
- If a user has many friends, fetching the friend list and generating news feeds for all of them are slow
- For inactive users or those rarely log in, pre-computing news feeds waste computing resources
3.3 Fanout on read
The news feed is generated during read time. Recent posts are pulled when a user loads her home page.
- Pros:
- For inactive users or those who rarely log in, fanout on read works better
- Data is not pushed to friends so there is no hotkey problem
- Cons:
- Fetching the news feed becomes slow
We adopt a hybrid approach to get benefits of both approaches and avoid pitfalls in them.
- For the majority of users: use a push model
- For users who have many friends/followers: let friends/followers pull news content to avoid system overload
3.4 The fanout service workflow
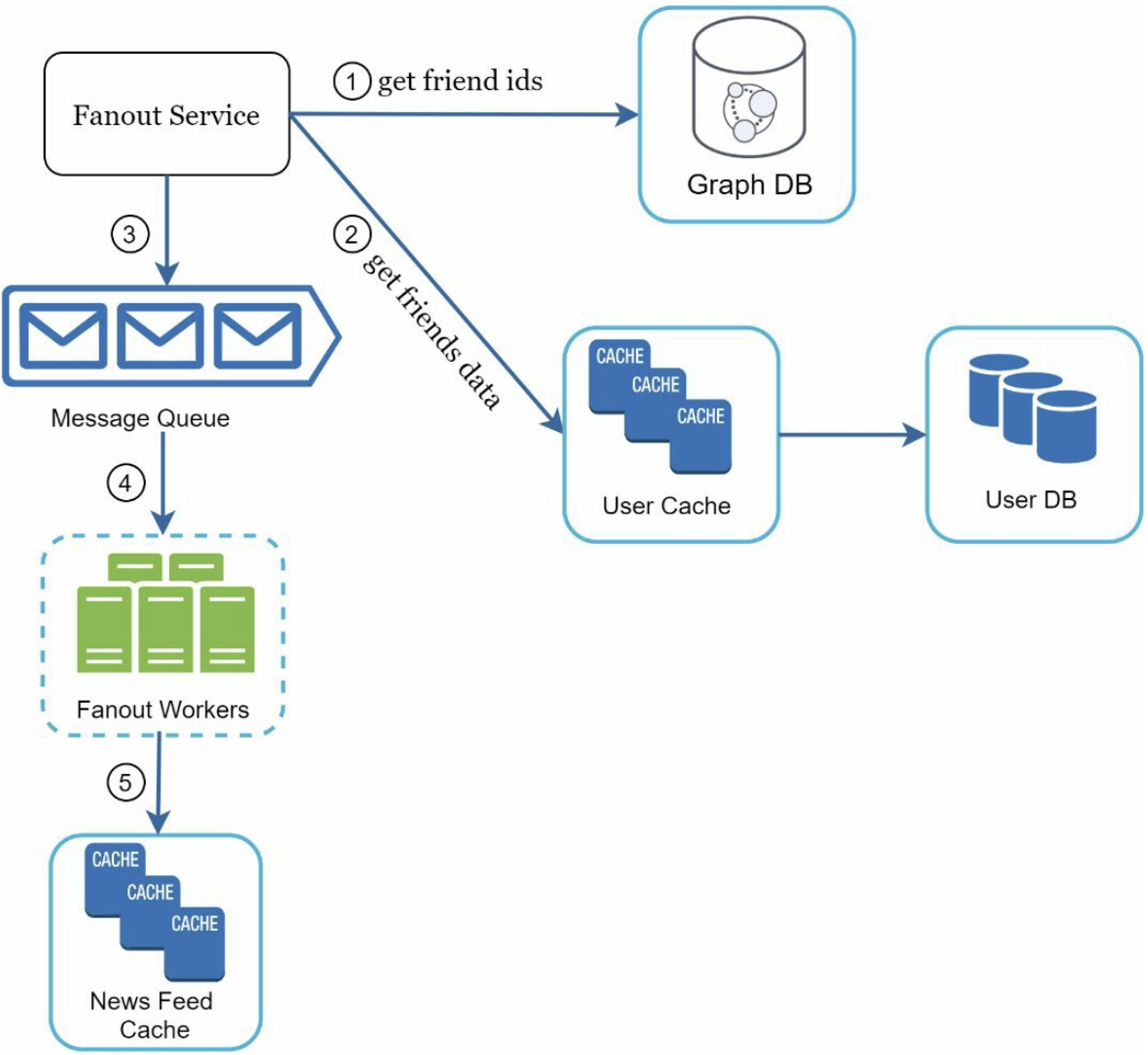
- Fetch friend IDs from the graph database. Graph databases are suited for managing friend relationship and friend recommendations.
- Get friends info from the user cache: filter out friends based on user settings
- If user mutes someone, user's posts will not show up on their news feed
- User could selectively share information with specific friends
- Send friends list and new post ID to the message queue
- Fanout workers fetch data from the message queue and store news feed data in the news feed cache
- Store
<post_id, user_id>in news feed cache
3.5 Newsfeed retrieval deep dive
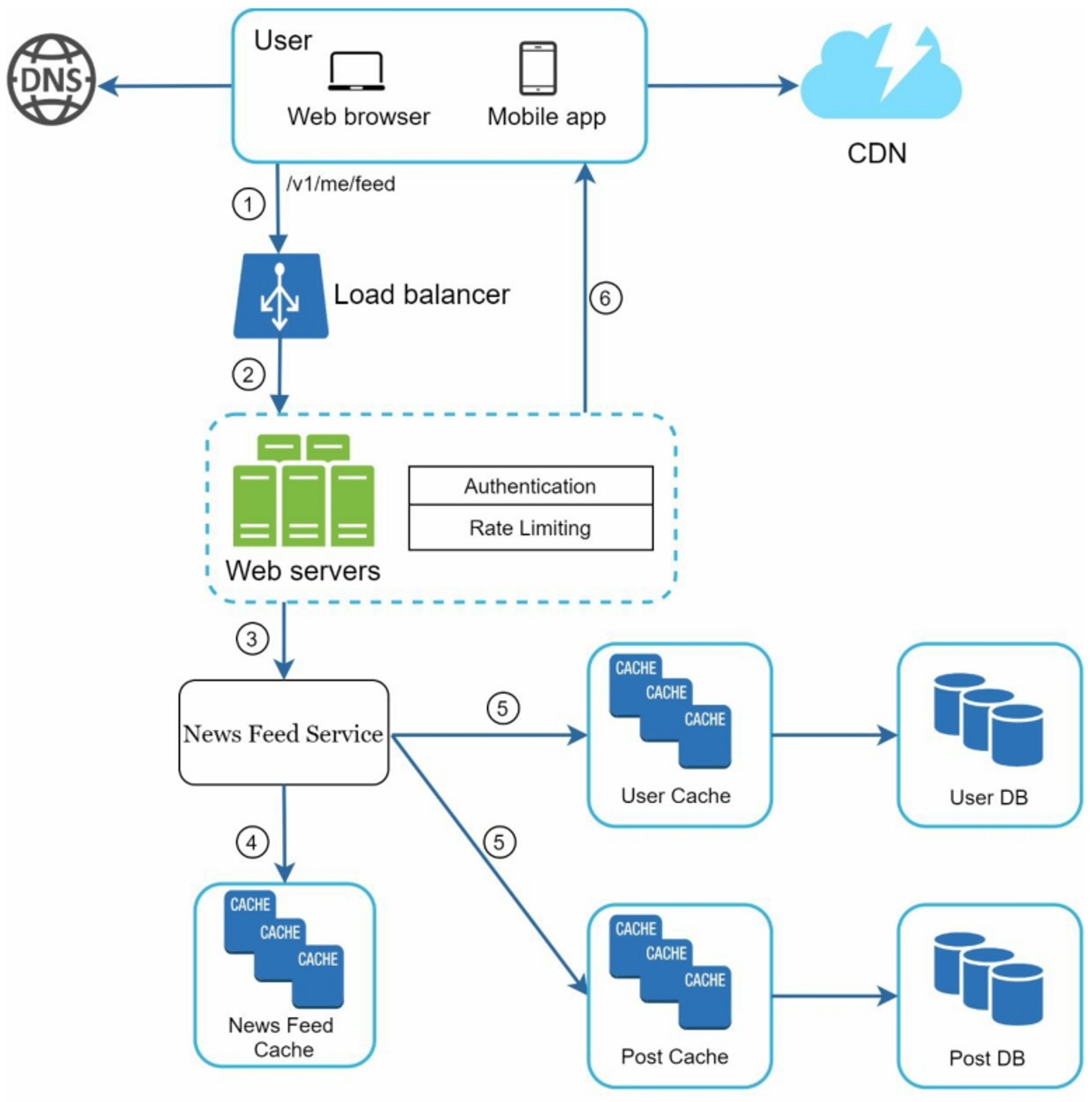
Media content (images, videos, etc.) are stored in CDN for fast retrieval. Below is how a client retrieves news feed:
- A user sends a request to retrieve her news feed
- The load balancer distributes requests to web servers
- Web servers call the news feed service to fetch news feeds
- News feed service gets a list post IDs from the news feed cache
- A user's news feed is more than just a list of feed IDs. It contains username, profile picture, post content, post image, etc.
- The fully hydrated news feed is returned in JSON format back to the client for rendering
3.6 Cache architecture
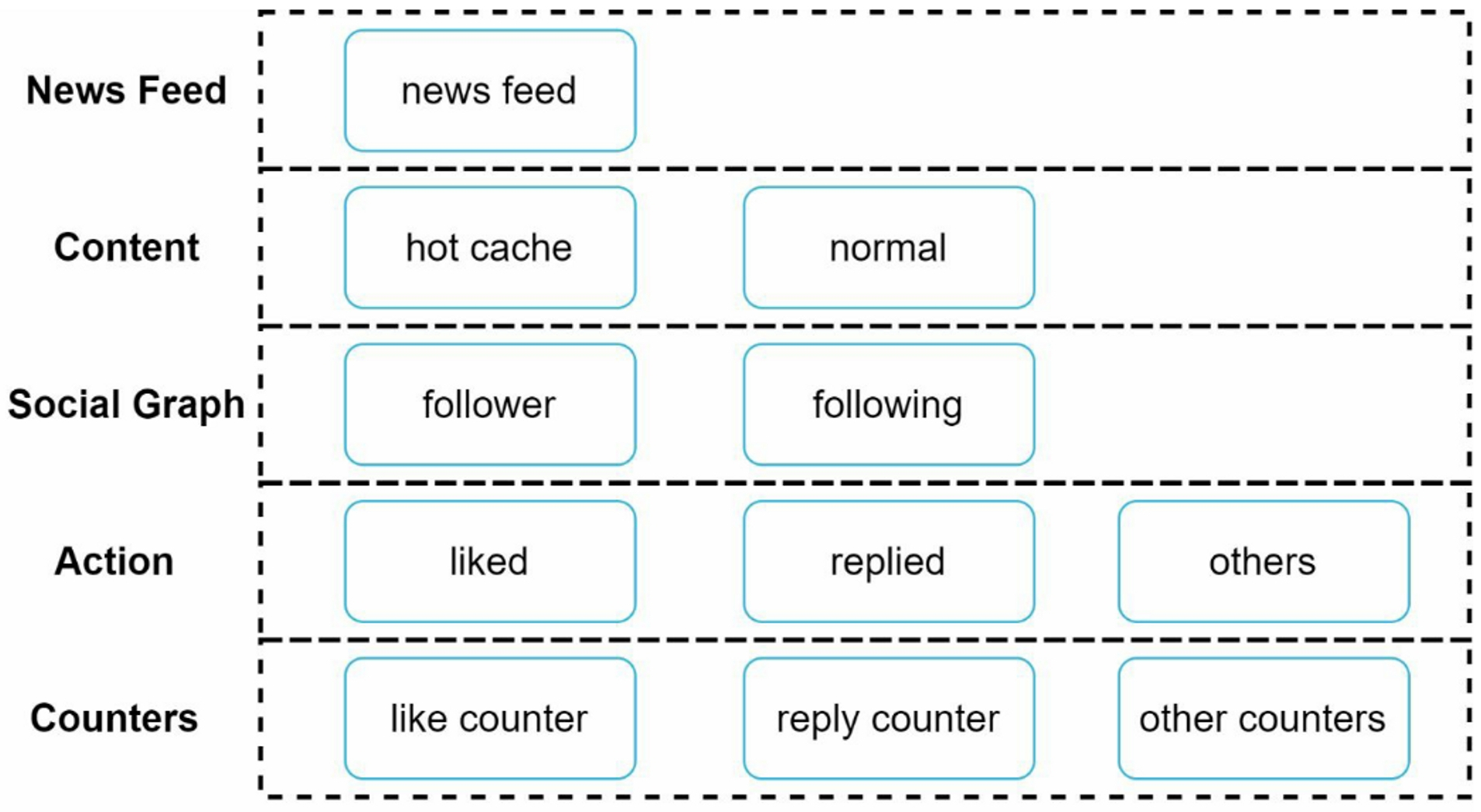
We divide the cache tier into 5 layers:
- News Feed: store IDs of news feeds
- Content: store every post data
- Social Graph: store user relationship data
- Action: store info about whether a user liked a post, replied a post, or took other actions on a post
- Counters: store counters for like, reply, follower, following, etc
4. Wrap up
Scaling the database:
- Vertical scaling vs Horizontal scaling
- SQL vs NoSQL
- Master-slave replication
- Read replicas
- Consistency models
- Database sharding
Other talking points:
- Keep web tier stateless
- Cache data as much as you can
- Support multiple data centers
- Lose couple components with message queues
- Monitor key metrics. For instance, QPS during peak