if (a->ob_shash != -1) return a->ob_shash; len = a->ob_size; p = (unsignedchar *) a->ob_sval; x = *p << 7; while (--len >= 0) x = (1000003*x) ^ *p++; x ^= a->ob_size; if (x == -1) x = -2; a->ob_shash = x; return x; }
// 判断字符串是否超长 size = strlen(str); if (size > PY_SSIZE_T_MAX - sizeof(PyStringObject)) { PyErr_SetString(PyExc_OverflowError, "string is too long for a Python string"); returnNULL; }
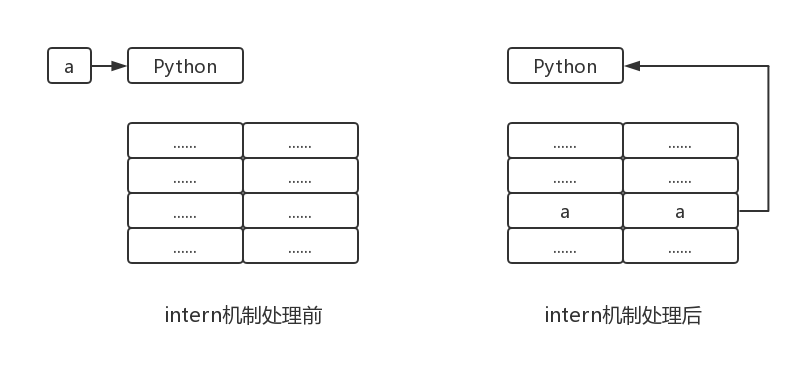
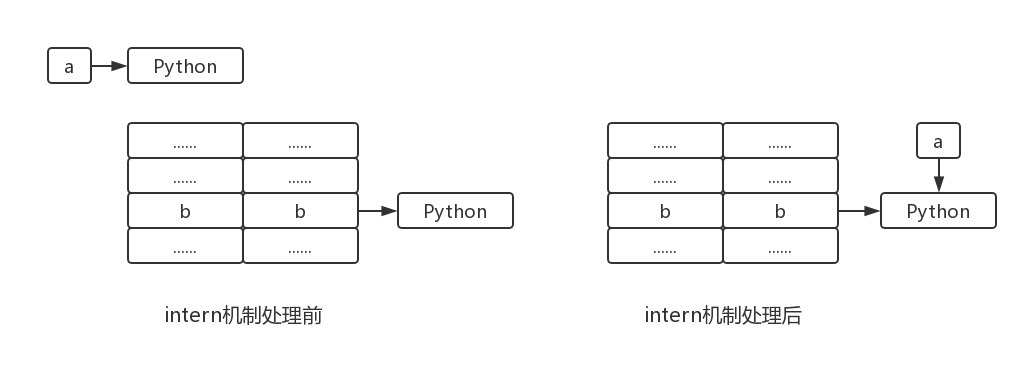
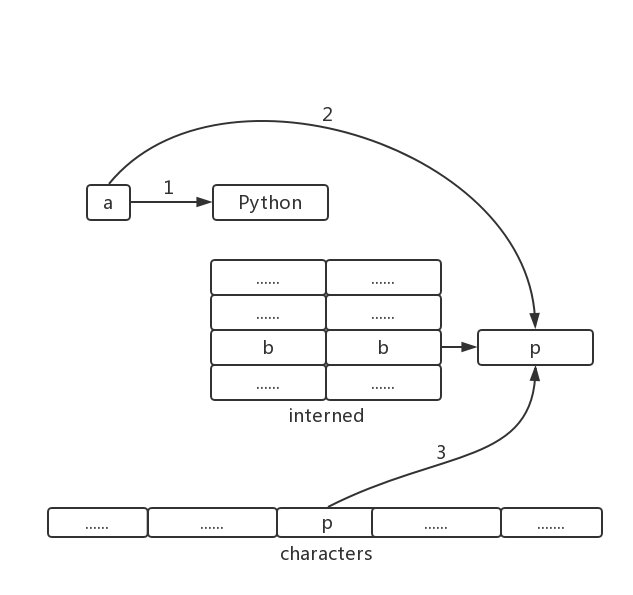
voidPyString_InternInPlace(PyObject **p) { register PyStringObject *s = (PyStringObject *)(*p); PyObject *t; if (s == NULL || !PyString_Check(s)) Py_FatalError("PyString_InternInPlace: strings only please!"); /* If it's a string subclass, we don't really know what putting it in the interned dict might do. */ // 对PyStringObject进行类型和状态检查 if (!PyString_CheckExact(s)) return; if (PyString_CHECK_INTERNED(s)) return; // 创建interned的dict if (interned == NULL) { interned = PyDict_New(); if (interned == NULL) { PyErr_Clear(); /* Don't leave an exception */ return; } }
// 检查intern的dict, 查看是否有对应的PyStringObject对象 t = PyDict_GetItem(interned, (PyObject *)s); if (t) { Py_INCREF(t); Py_DECREF(*p); *p = t; return; }
// interned的dict中没有该对象, 在dict中创建新的PyStringObject对象 if (PyDict_SetItem(interned, (PyObject *)s, (PyObject *)s) < 0) { PyErr_Clear(); return; } /* The two references in interned are not counted by refcnt. The string deallocator will take care of this */ s->ob_refcnt -= 2;
staticvoidstring_dealloc(PyObject *op) { switch (PyString_CHECK_INTERNED(op)) { case SSTATE_NOT_INTERNED: break;
case SSTATE_INTERNED_MORTAL: /* revive dead object temporarily for DelItem */ op->ob_refcnt = 3; if (PyDict_DelItem(interned, op) != 0) Py_FatalError("deletion of interned string failed"); break;
case SSTATE_INTERNED_IMMORTAL: Py_FatalError("Immortal interned string died.");
// 遍历list中的每个字符串, 并获得整个字符串长度 for (i = 0; i < seqlen; i++) { constsize_t old_sz = sz; item = PySequence_Fast_GET_ITEM(seq, i); if (!PyString_Check(item)){ PyErr_Format(PyExc_TypeError, "sequence item %zd: expected string," " %.80s found", i, item->ob_type->tp_name); Py_DECREF(seq); returnNULL; } sz += PyString_GET_SIZE(item); if (i != 0) sz += seplen; if (sz < old_sz || sz > PY_SSIZE_T_MAX) { PyErr_SetString(PyExc_OverflowError, "join() result is too long for a Python string"); Py_DECREF(seq); returnNULL; } }
/* 为新的PyStringObject对象分配空间 */ res = PyString_FromStringAndSize((char*)NULL, sz); if (res == NULL) { Py_DECREF(seq); returnNULL; }
/* 将list中的字符全部拷贝到新的PyStringObject对象中 */ p = PyString_AS_STRING(res); for (i = 0; i < seqlen; ++i) { size_t n; item = PySequence_Fast_GET_ITEM(seq, i); n = PyString_GET_SIZE(item); Py_MEMCPY(p, PyString_AS_STRING(item), n); p += n; if (i < seqlen - 1) { Py_MEMCPY(p, sep, seplen); p += seplen; } }