System Design - Basic
1. Vertical scaling vs horizontal scaling
Vertical scaling, referred to as "scale up", means the process of adding more power (CPU,
RAM, etc.) to your servers. Horizontal scaling, referred to as "scale-out", allows you to scale
by adding more servers into your pool of resources.
Pros:
- vertical scaling is a great option, and the simplicity of vertical scaling is its main advantage.
Cons:
- Vertical scaling has a hard limit. It is impossible to add unlimited CPU and memory to a single server.
- Vertical scaling does not have failover and redundancy. If one server goes down, the website/app goes down with it completely.
2. Load Balancing
Load balancing refers to efficiently distributing incoming network traffic across a group of backend servers, also known as a server farm or server pool.
load balancing configurations:
- Round-robin
- Weighted algorithm: different servers are assigned relative weights based on their capacity to handle traffic. if server A has twice the capacity of server B, then the load balancer would give twice the amount of traffic to server A compared to server B.
- Dynamic algorithm: consider server health and server response times when assigning requests.
- Geo-location is another widely used dynamic algorithm: load balancer assigns requests from a region to a defined server or server set.
- Sticky session: All requests from the client during the session are sent to the same target. This feature is useful for servers that maintain state information.
- Application-based stickiness: routing based on fields in the request, such as standard and custom HTTP headers and methods, query parameters, and source IP address
3. Database replication
A master database generally only supports write operations. A slave database gets copies of the data from the master database and only supports read operations. All the data-modifying commands like insert, delete, or update must be sent to the master database.
Most applications require a much higher ratio of reads to writes: The number of slave database is usually larger than the number of master databases
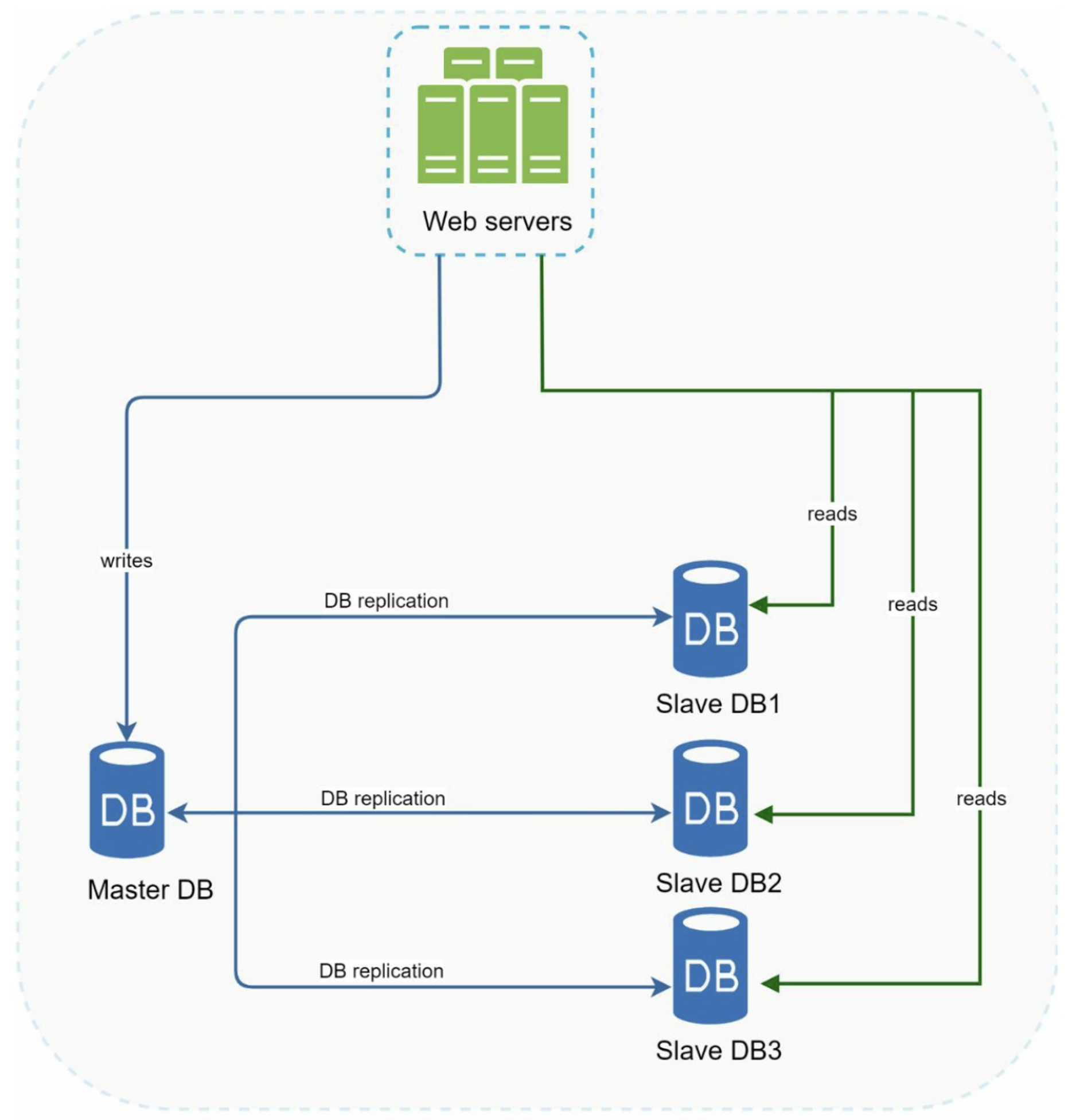
Advantages:
- Better performance: all writes and updates happen in master nodes; whereas, read operations are distributed across slave nodes.
- Reliability: If one of your database servers is destroyed by a natural disaster, you do not need to worry about data loss because data is replicated across multiple locations.
- High availability: By replicating data across different locations, your website remains in operation even if a database is offline as you can access data stored in another database server.
what if one of the databases goes offline:
- If one slave goes offline: read operations will be directed to the master database temporarily. As soon as the issue is found, a new slave database will replace the old one
- If the master database goes offline, a slave database will be promoted to be the new master. a new master might not be up to date:
- run data recovery scripts
- multi-masters
- circular replication
4. Database Selection
4.1 SQL vs NoSQL
SQL databases are suitable for structured data, where data is consistent, and relationships between tables are well-defined.
NoSQL databases are suitable for semi-structured or unstructured data, where the data does not conform to a predefined schema, and relationships between data elements are not well-defined.
SQL follows ACID properties (Atomicity, Consistency, Isolation and Durability) for the transaction management; NoSQL doesn't necessarily follow ACID properties.
SQL supports JOIN and complex queries; NoSQL doesn't support.
SQL use normalized data structure; NoSQL uses denormalized data structure
4.2 Key-Value Database vs Document Database
Document database and key-value database both are types of NoSQL design. Document database is an extension of the key-value database model. Rather than just storing data based on a key that maps to a value, document databases store structured data. These documents can contain multiple defined values that can be indexed to speed up queries and grab related data. Document databases can be seen as a middle ground between key-value databases and relational databases, where you have the option of creating a semi-structured schema if you choose.
4. Database Scaling
Two approaches for database scaling:
- vertical scaling
- horizontal scaling
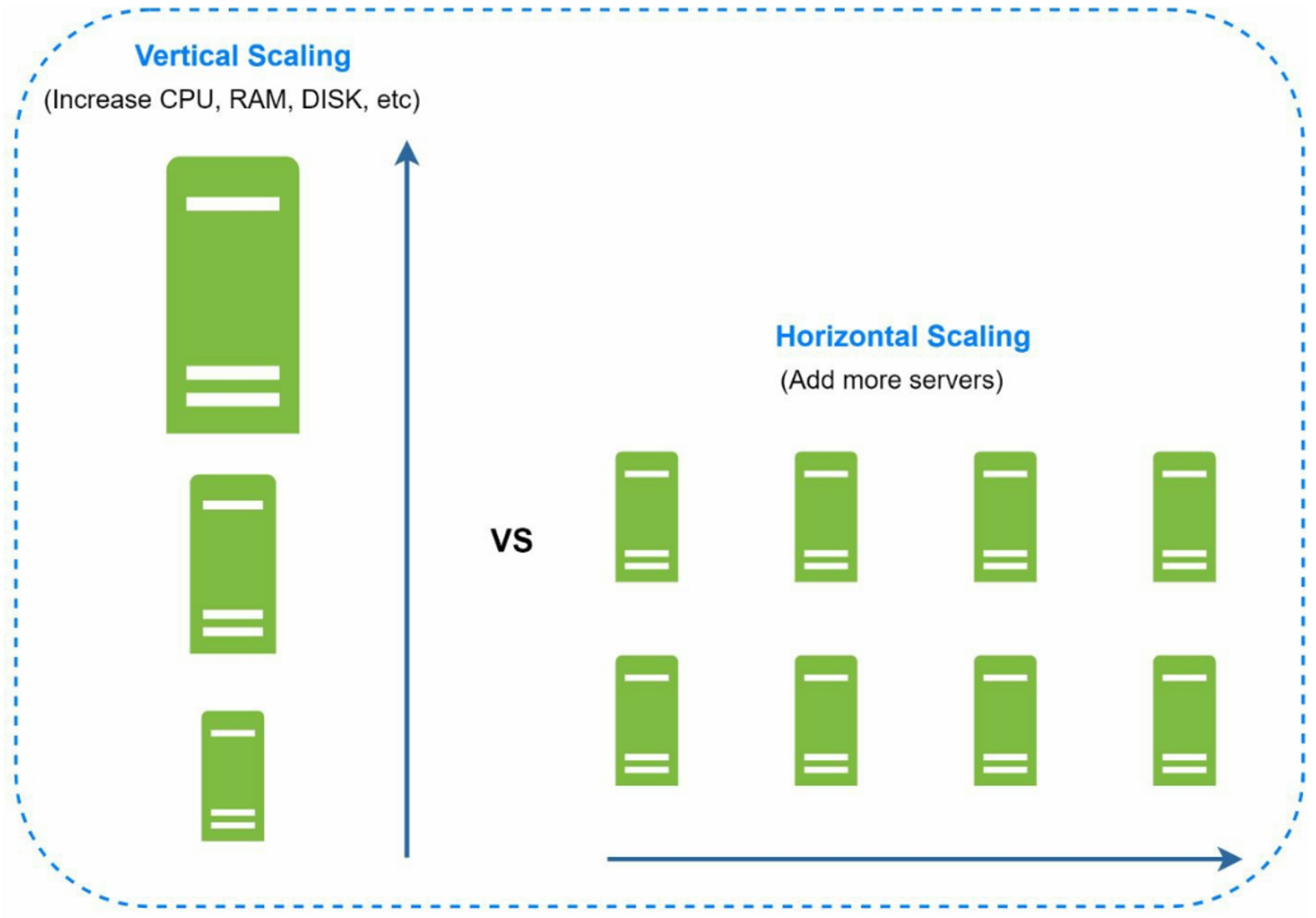
4.1 Database Vertical Scaling
Adding more power (CPU, RAM, DISK, etc.) to an existing machine.
Drawbacks:
- hardware limit for a single server
- Greater risk of single point of failures
- cost is high since powerful servers are much more expensive
4.2 Horizontal Scaling
Separating large databases into smaller parts, called shards. Each shard shares the same schema, though the actual data on each shard is unique to the shard.
The most important factor to consider when implementing a sharding strategy is the choice of the sharding key. Sharding key (known as a partition key) consists of one or more columns that determine how data is distributed.
4.3 Database Replication Techniques
There are several types of database replication based on the type of server architecture:
- Single-leader architecture: leader receives the write operations, slaves receive the read operations
- No-leader architecture: Every server can receive write and read operation. For example, Amazon's DynamoDB
4.4 Challenges of Sharding
- Resharding data:
- a single shard could no longer hold more data due to rapid growth.
- Certain shards might experience shard exhaustion faster than others due to uneven data distribution.
- Celebrity problem: Excessive access to a specific shard could cause server overload. For social applications, that shard with celebrity will be overwhelmed with read operations -> allocate a shard for each celebrity
- Join and de-normalization: hard to perform join operations across database shards -> denormalize the database so that queries can be performed in a single table.
5. Cache
A cache is a temporary storage area that stores the result of expensive responses or frequently accessed data in memory so that subsequent requests are served more quickly.
5.1 Advantages
- better system performance
- reduce database workload
- scale the cache tier independently
5.2 Considerations for using cache:
- when to use cache: using cache when data is read frequently but modified infrequently
- expiration policy: Once cached data is expired, it is removed from the cache.
- make the expiration date too short: reload data from the database too frequently
- make the expiration date too long: data can become stale
- consistency: Inconsistency can happen because data-modifying operations on the data store and cache are not in a single transaction.
- mitigating failures: A single cache server represents a potential single point of failure
- multiple cache servers across different data centers
- overprovision the required memory by certain percentages
- eviction policy: Once the cache is full, any requests to add items to the cache might cause existing items to be removed (Least-recently-used, LRU)
6. Content delivery network (CDN)
A CDN is a network of geographically dispersed servers used to deliver static content.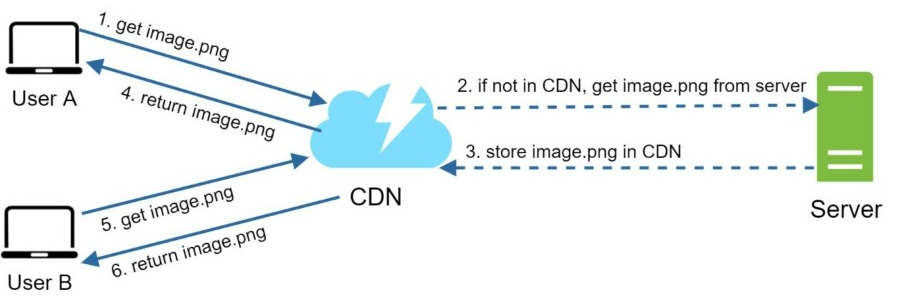
- User A tries to get image.png by using an image URL
- If the CDN server does not have image.png in the cache, the CDN server requests the file from the origin
- The origin returns image.png to the CDN server, which includes optional HTTP header Time-to-Live (TTL)
- The CDN caches the image and returns it to User A
Considerations of using a CDN:
- Cost: Caching infrequently used assets provides no significant benefits so you should consider moving them out of the CDN
- Setting an appropriate cache expiry
- too long: the content might no longer be fresh
- too short: cause repeat reloading of content from origin servers to the CDN
- CDN fallback: If there is a temporary CDN outage, clients should be able to detect the problem and request resources from the origin.
- Invalidating files: remove a file from the CDN before it expires by performing one of the following operations:
- use APIs provided by CDN vendors
- serve a different version of the object
7. Stateless web tier
scale the web tier horizontally -> move state out of the web tier: A good practice is to store session data in the persistent storage such as NoSQL. Each web server in the cluster can access state data from databases. In this stateless architecture, HTTP requests from users can be sent to any web servers, which fetch state data from a shared data store. State data is stored in a shared data store and kept out of web servers.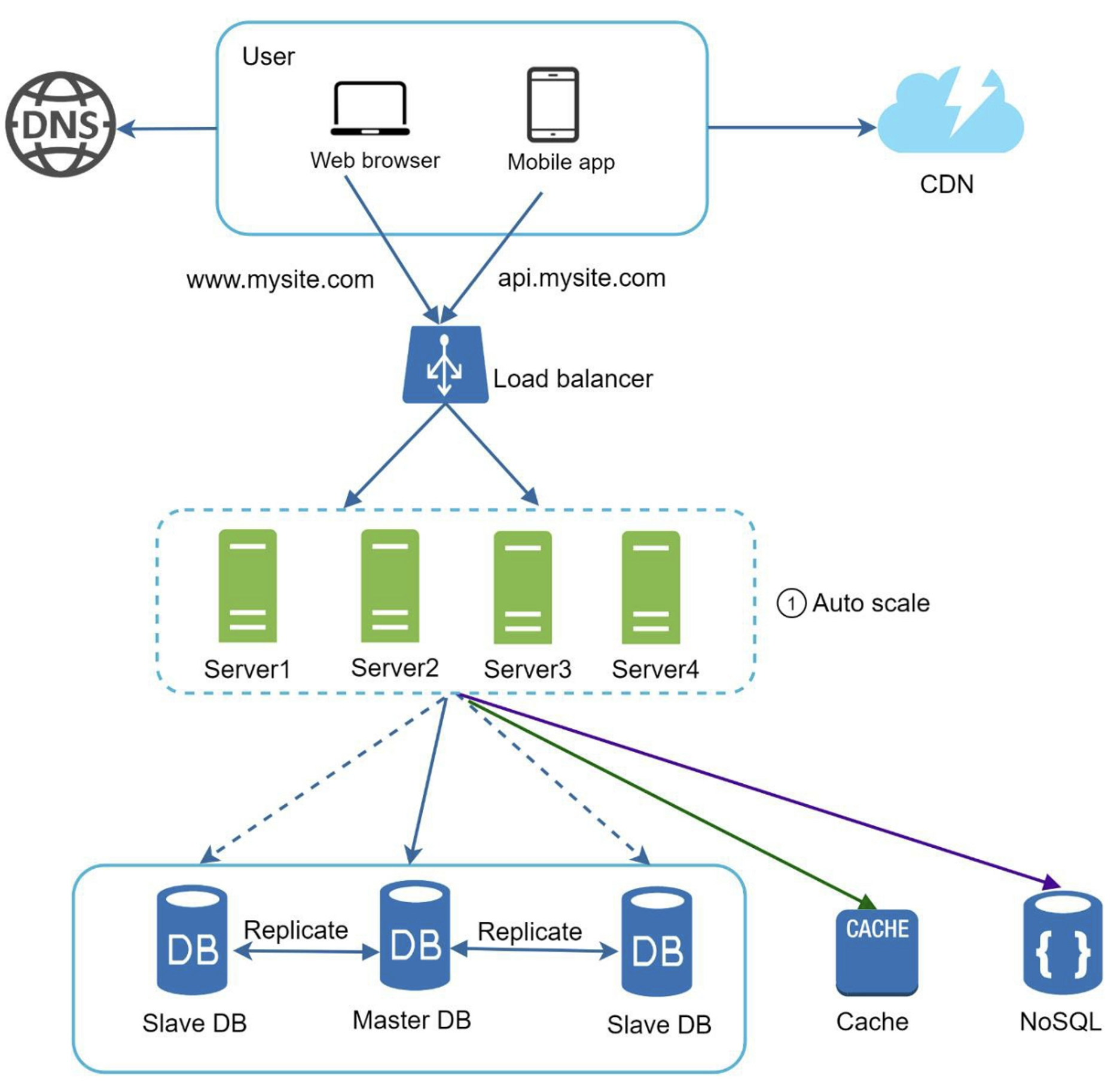
8. Data center
In normal operation, users are geoDNS-routed, also known as geo-routed, to the closest data center. geoDNS is a DNS service that allows domain names to be resolved to IP addresses based on the location of a user.
Challenges:
- Traffic redirection: need tools to direct traffic to the correct data center(GeoDNS)
- Data synchronization: Users from different regions could use different local databases or caches. In failover cases, traffic might be routed to a data center where data is unavailable. Solution: replicate data across multiple data centers.
- Test and deployment: Automated deployment tools are vital to keep services consistent through all the data centers
9. Message Queue

A message queue is a durable component, stored in memory, that supports asynchronous communication.
- producer: create messages, and publish them to a message queue
- consumers: connect to the queue, and perform actions defined by the messages
Advantage of MQ: Decoupling. producer can post a message to the queue when the consumer is unavailable to process it; consumer can read messages from the queue even when the producer is unavailable.
10. Logging, metrics, automation
- Logging: Monitoring error logs is important because it helps to identify errors and problems
- Metrics: Collecting different types of metrics help us to gain business insights and understand the health status
- Host level metrics: CPU, Memory, disk I/O
- Aggregated level metrics: for example, the performance of the entire database tier, cache tier
- key business metrics: daily active users, retention, revenue
- Automation: automation tool to improve producitivity.
11. Summary of How to Scale System to Support Millions of Users
- Keep web tier stateless
- Build redundancy at every tier
- Cache data as much as you can
- Support multiple data centers
- Host static assets in CDN
- Scale your data tier by sharding
- Split tiers into individual services
- Monitor your system and use automation tools