System Design - Google Drive
1. Introduction
Google Drive is a file storage and synchronization service that helps you store documents, photos, videos, and other files in the cloud. You can access your files from any computer, smartphone, and tablet. You can easily share those files with friends, family, and coworkers
2. Understand Problem and Establish Design Scope
- What are the most important features: Upload and download files, file sync, and notifications
- Is this a mobile app, a web app, or both: Both
- What are the supported file formats: Any file type
- Do files need to be encrypted: Yes, files in the storage must be encrypted
- Is there a file size limit: Yes, files must be 10 GB or smaller
- How many users does the product have: 10M DAU
Features of google drive:
- Add files. Drag and drop a file into Google drive
- Download files
- Sync files across multiple devices
- See file revisions
- Share files with others
- Send a notification when a file is edited, deleted, or shared with you
Requirements of this product:
- Reliability: Data loss is unacceptable
- Fast sync speed
- Bandwidth usage
- Scalability: system should be able to handle high volumes of traffic
- High availability: Users should still be able to use the system when some servers are offline, slowed down, or have unexpected network errors
2.1 Back of the envelope estimation
- 50 million signed up users
- 10 million DAU
- Users get 10 GB free space
- Users upload 2 files per day
- The average file size is 500 KB
- 1:1 read to write ratio
- Total space allocated: 50 million * 10 GB = 500 Petabyte
- QPS for upload API: 10 million * 2 uploads / 24 hours / 3600 seconds = ~ 240
- Peak QPS = QPS * 2 = 480
3. Propose High-level Design and Get Buy-in
First, we will try to build everything in a single server. Then, scale it up to support millions of users. The single server setup as list below:
- A web server to upload and download files
- A database to keep track of metadata like user data, login info, files info, etc
- A storage system to store files
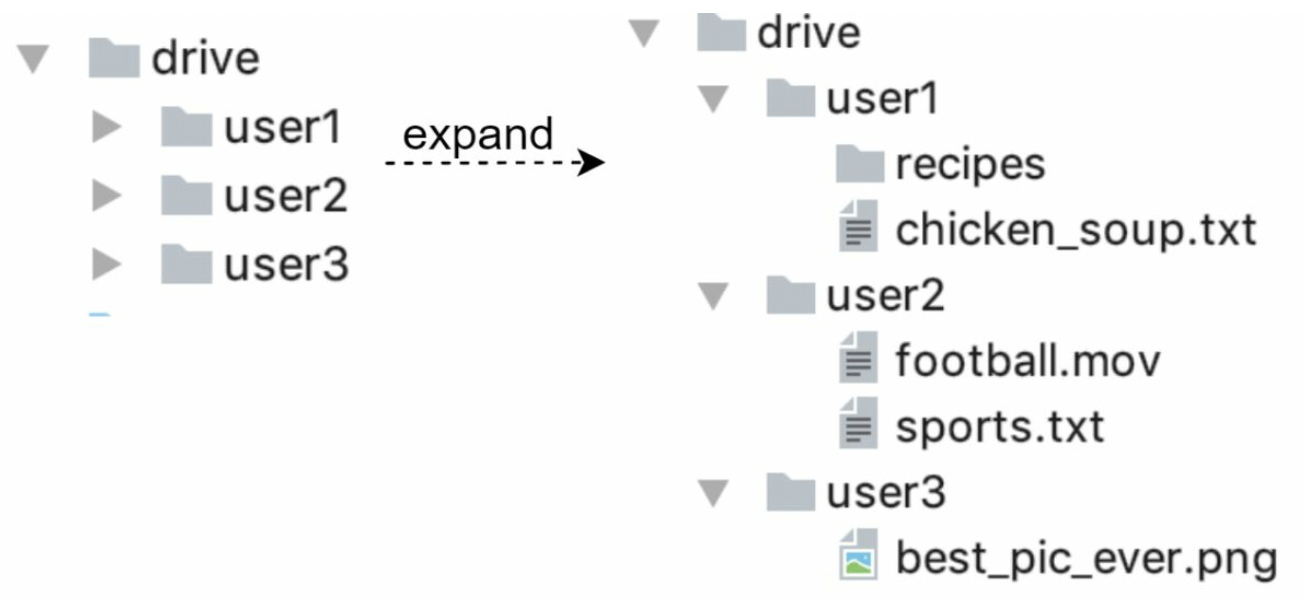
In the storage system:
- a directory called
drive/as the root directory - a list of subdirectories, known as
namespaces - Each namespace contains all the uploaded files for that user
- The filename on the server is kept the same as the original file name
- Each file or folder can be uniquely identified by joining the namespace and the relative path
3.1 APIs
3.1.1 Upload a file to Google Drive
Two types of uploads are supported:
Simple upload: file size is small
Resumable upload: file size is large and there is high chance of network interruption
HTTP POST
Params:
- uploadType=resumable
Data: Local file to be uploaded.
A resumable upload is achieved by 3 steps:
- Send the initial request to retrieve the resumable URL.
- Upload the data and monitor upload state.
- If upload is disturbed, resume the upload.
3.1.2 Download a file from Google Drive
- HTTP GET
- URL: https://api.example.com/files/download
- Params:
- path: download file path
3.1.3 Get file revisions
- HTTP GET
- URL: https://api.example.com/files/list_revisions
- Params:
- path: The path to the file you want to get the revision history.
- limit: The maximum number of revisions to return.
3.2 Move away from single server
When storage of single server is full. The first solution comes to mind is to shard the data. Here's an example of sharding based on user_id. But this solution still under the risk of potential data losses.
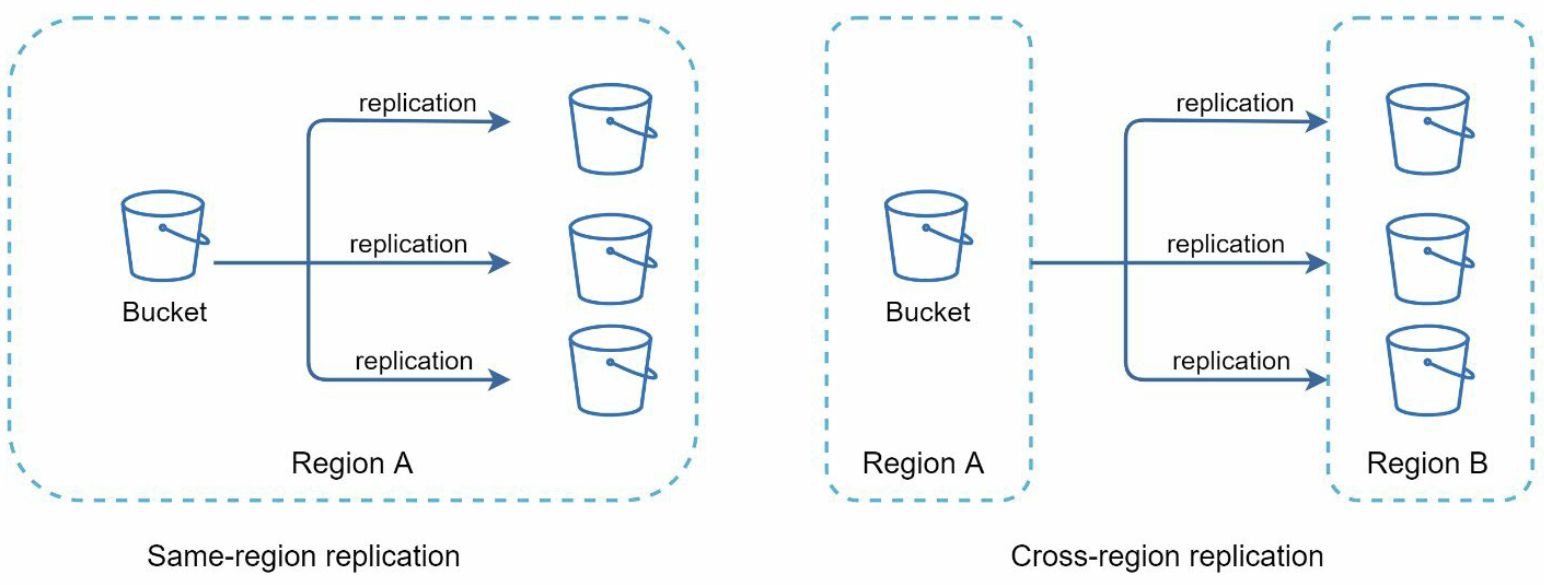
Amazon S3 for storage would be a good solution. In Amazon S3, each bucket is like a folder in file systems. It offers scalability, data availability, security, and high performance. Amazon S3 has two options of replication:
- same-region: all data is replicated on the same-region
- cross-region: data is replicated to the different region
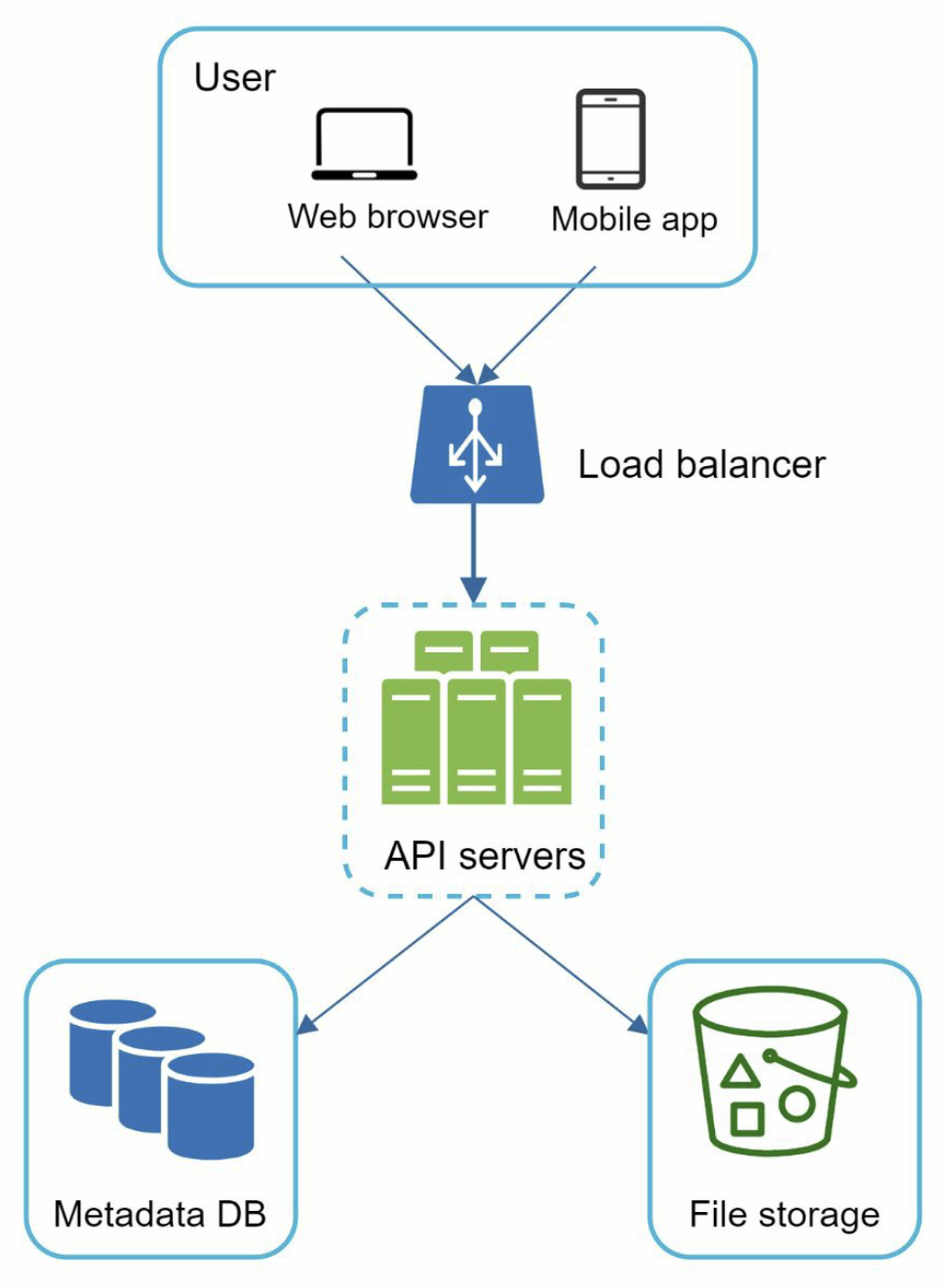
Other improvement:
- Load balancer: If a web server goes down, it will redistribute the traffic
- Web server: After a load balancer is added, more web servers can be added/removed easily, depending on the traffic load
- Metadata database: Move the database out of the server to avoid single point of failure. Set up data replication and sharding to meet the availability and scalability requirements
- File storage: Amazon S3 is used for file storage. To ensure availability and durability, files are replicated in two separate geographical regions
3.3 Sync Conflicts
How to deal with sync conflicts when two users modify the same file or folder at the same time: the first version that gets processed wins, and the version that gets processed later receives a conflict.
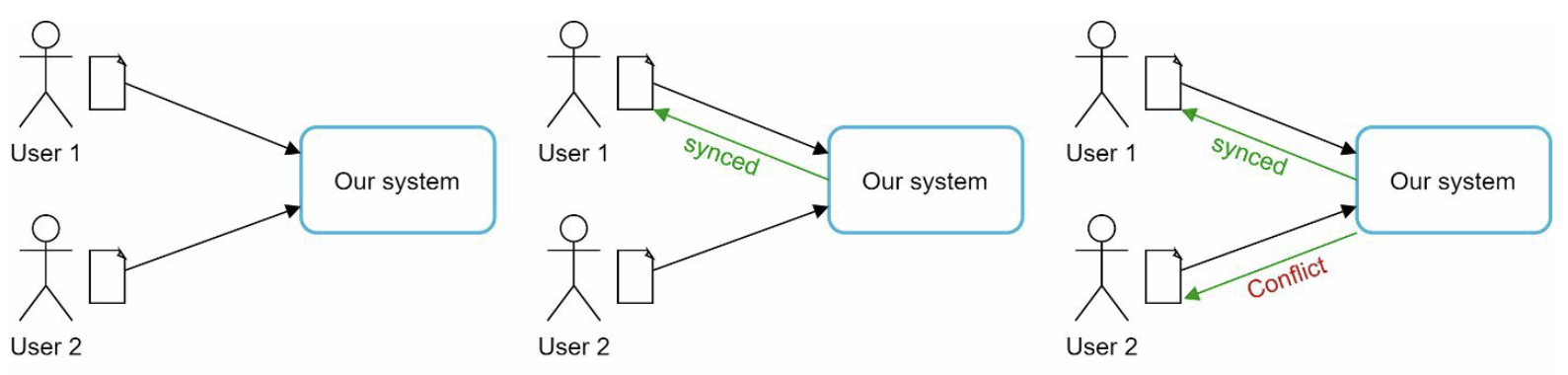
User who receives the sync conflict will have a local copy, and have the option to merge both files or override one version with the other.
3.4 High-level design
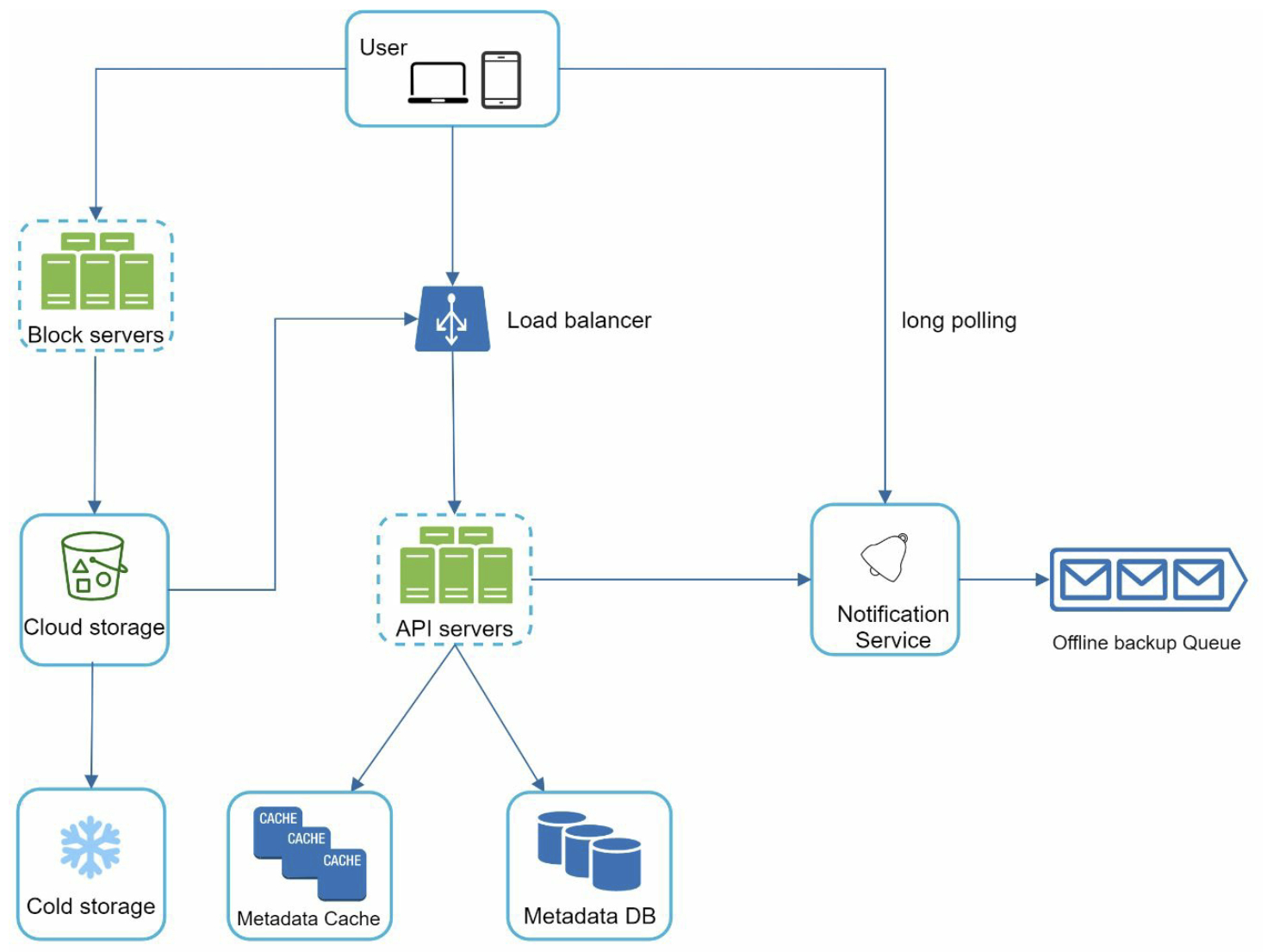
- User: use the application either through a browser or mobile app
- Block servers: upload blocks to cloud storage. A file can be split into several blocks, each with a unique hash value, stored in our metadata database. Maximal size of a block to 4MB.
- Cloud storage: A file is split into smaller blocks and stored in cloud storage
- Cold storage: a computer system designed for storing inactive data, meaning files are not accessed for a long time
- Load balancer: A load balancer evenly distributes requests among API server
- API servers: used for user authentication, managing user profile, updating file metadata, etc
- Metadata database: stores metadata of users, files, blocks, versions, etc
- Metadata cache: Some of the metadata are cached for fast retrieval
- Notification service: a publisher/subscriber system that allows data to be transferred from notification service to clients as certain events happen
- Offline backup queue: If a client is offline and cannot pull the latest file changes, the offline backup queue stores the info so changes will be synced when the client is online
4. Design deep dive
4.1 Block servers
Sending a large file on each update consumes a lot of bandwidth. Two optimizations are proposed to minimize the amount of network traffic:
- Delta sync: When a file is modified, only modified blocks are synced instead of the whole file
- Compression: compression on blocks can reduce the data size. Using different compression algorithms for different file types. For example, gzip and bzip2 for text files
Block servers process files passed from clients by splitting a file into blocks, compressing each block, and encrypting them, and only modified blocks are transferred.
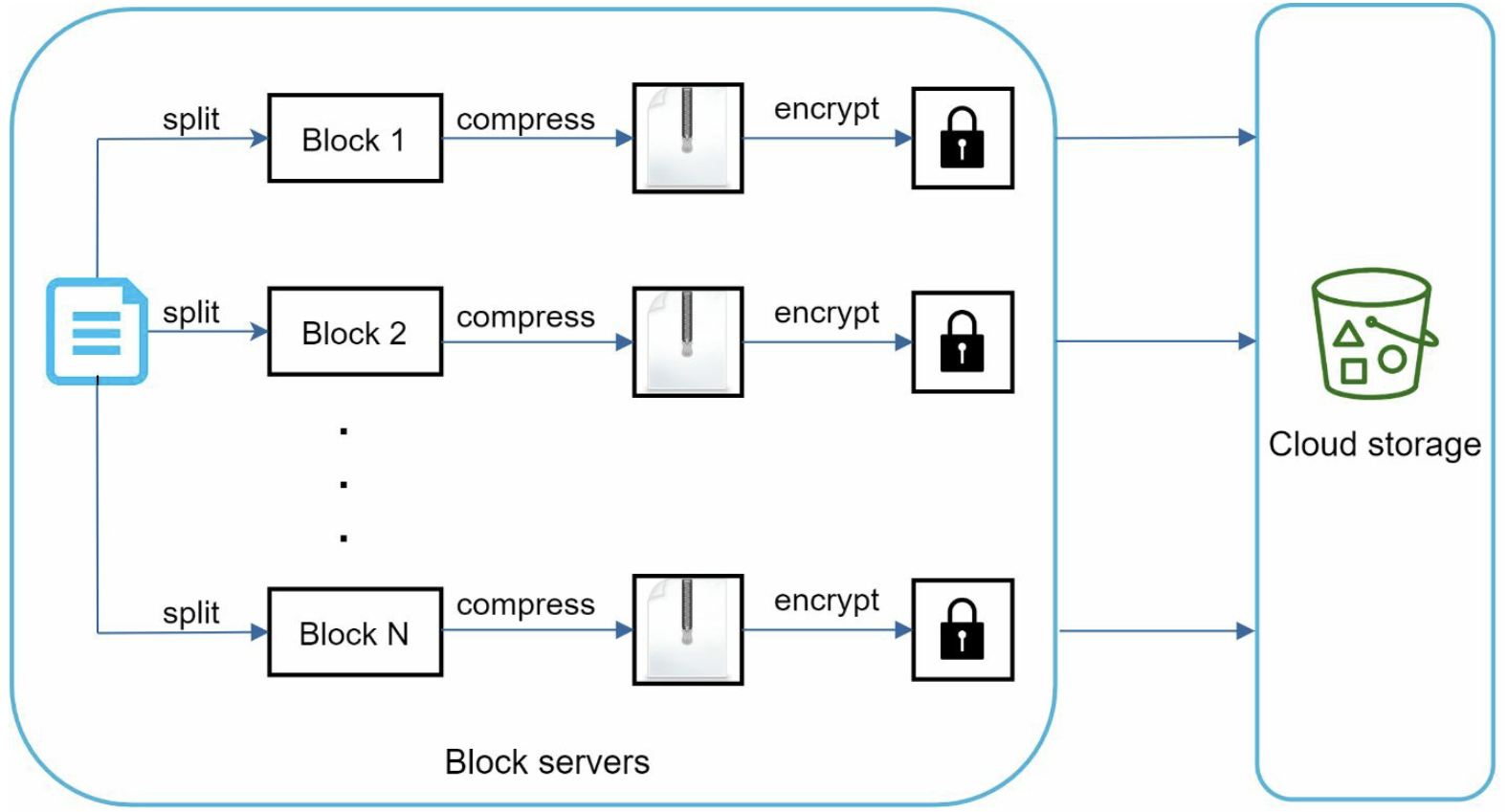
- A file is split into smaller blocks
- Each block is compressed using compression algorithms
- To ensure security, each block is encrypted
- Blocks are uploaded to the cloud storage
4.2 High Consistency Requirement
The system needs to provide strong consistency for metadata cache and database layers: different clients should view the same file at the same time. To achieve strong consistency, we must ensure the following:
- Data in cache replicas is consistent with data in the master database
- Invalidate caches when write data into database, it ensures cache and database hold the same value
4.3 Metadata Database
Relational database maintains the ACID, so we choose relational database.
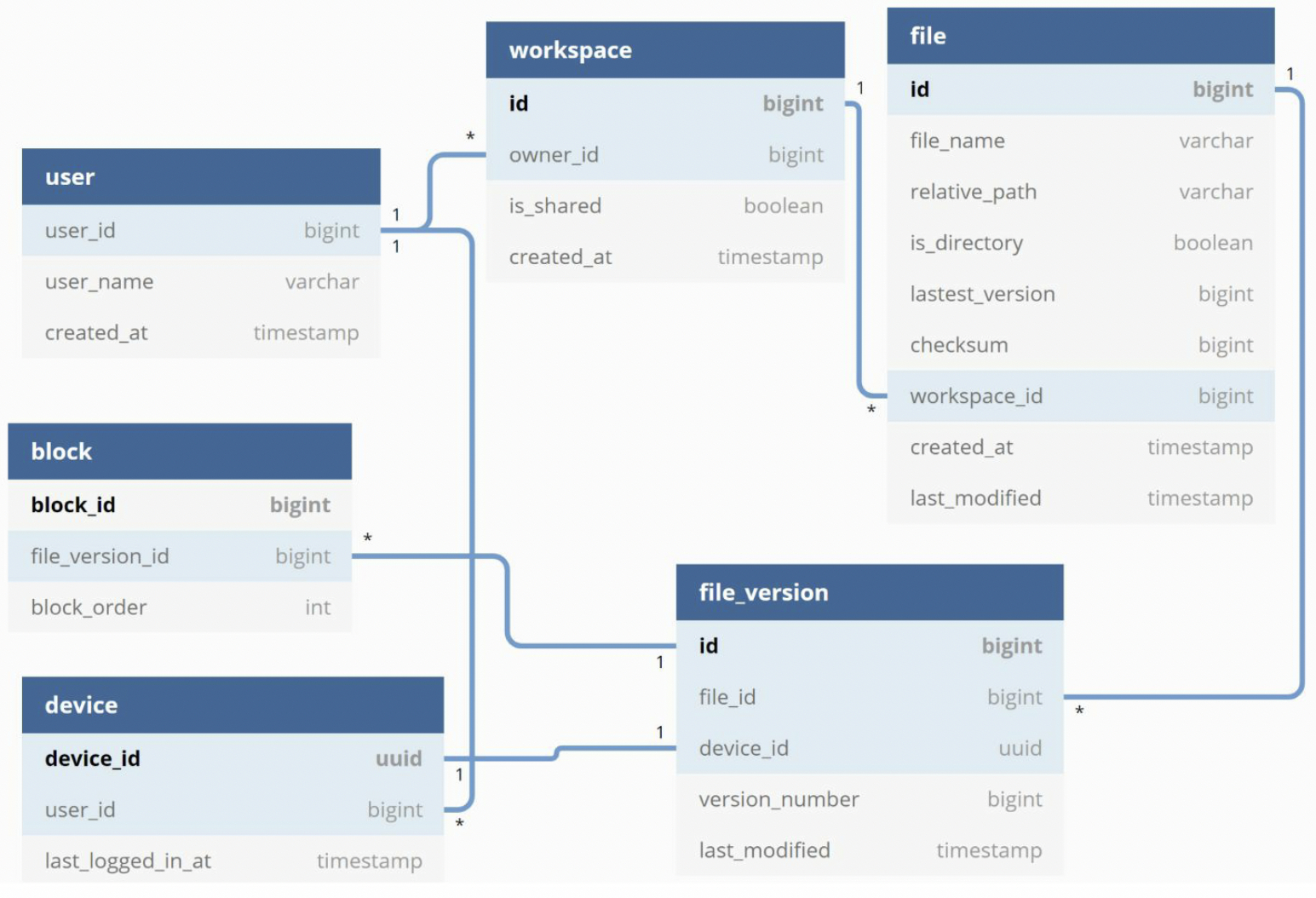
- User: basic information about the user such as username, email, profile photo, etc
- Device: device info.
Push_idis used for sending and receiving mobile push notifications. Note: A user can have multiple devices - Namespace: the root directory of a user
- File: everything related to the latest file
- File_version: version history of a file. Existing rows are read-only to keep the integrity of the file revision history
- Block: everything related to a file block
4.4 Upload flow
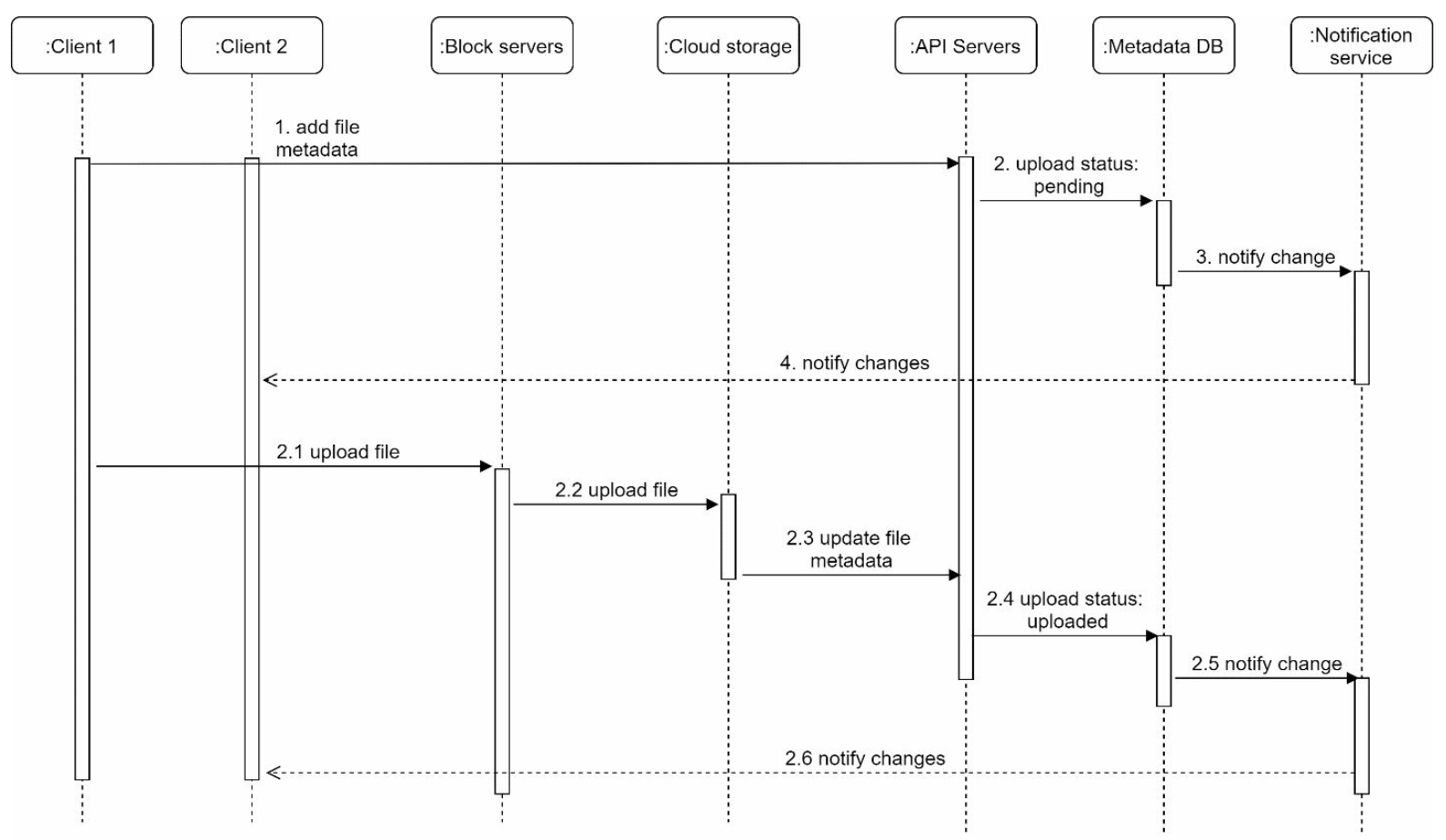
Two requests are sent in parallel: add file metadata and upload the file to cloud storage. Both requests from client 1:
- Add file metadata:
- Client 1 sends a request to add the metadata of the new file
- Store the new file metadata in metadata DB and change the file upload status to
pending - Notify the notification service that a new file is being added
- The notification service notifies other clients (client 2) that a file is being uploaded
- Upload files to cloud storage:
- Client 1 uploads the content of the file to block servers
- Block servers chunk the files into blocks, compress, encrypt and upload block to cloud storage
- Once the file is uploaded, cloud storage sent upload completion request to API servers
- File status changed to
uploadedin Metadata DB - Notify the notification service that a file status is changed to
uploaded - The notification service notifies other clients (client 2) that a file is fully uploaded
4.5 Download flow
Download flow is triggered when a file is added or edited by other client. There are two ways a client can know:
- If client A is online while a file is changed by another client, notification service will inform client A
- If client A is offline while a file is changed by another client, data will be saved to the cache. When client A is online again, it pulls the latest changes.
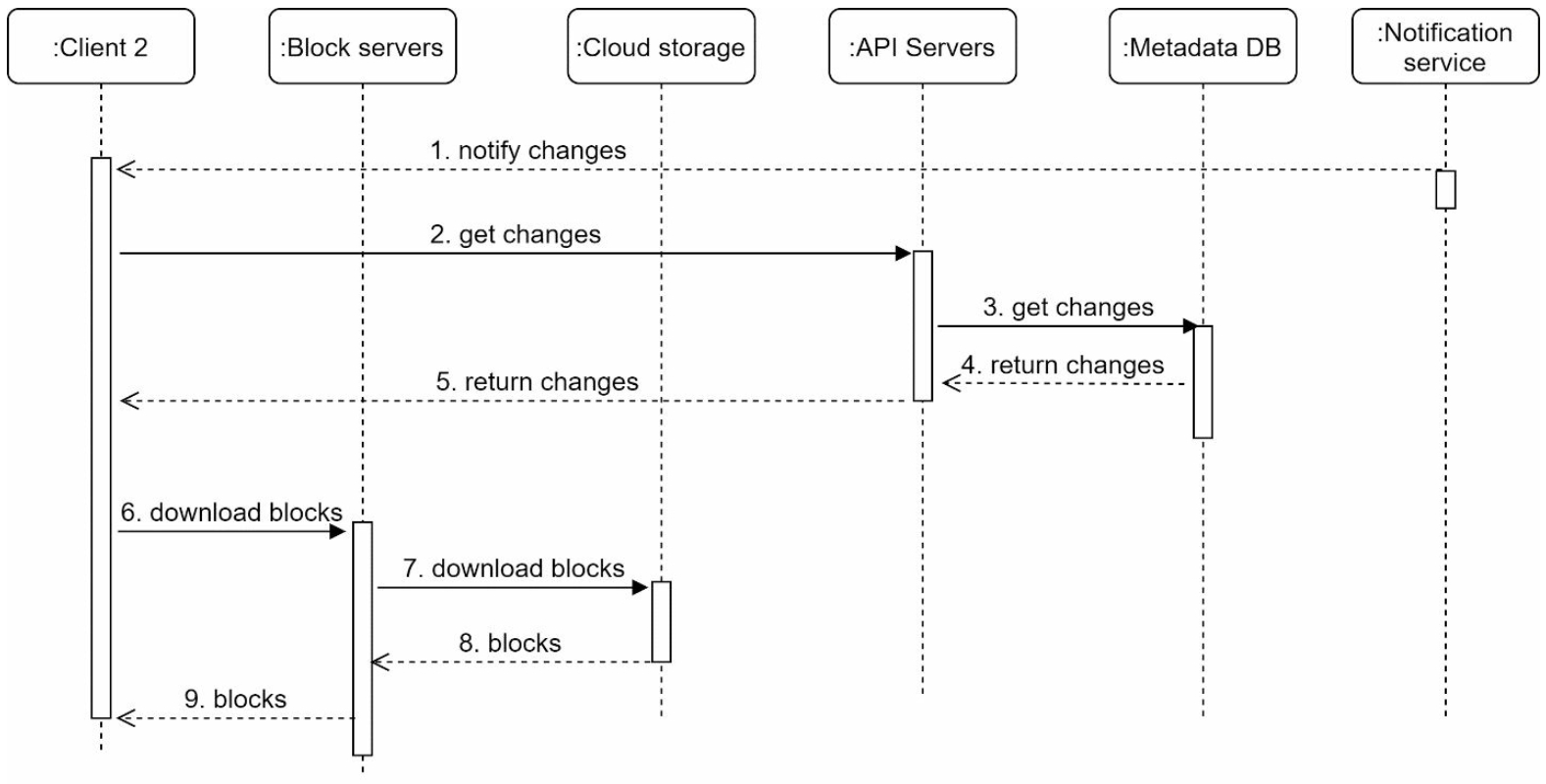
- Notification service informs client 2 that a file is changed
- Once client 2 knows that new updates are available, it sends a request to fetch metadata
- API server call metadata DB to fetch metadata of the changes
- Metadata is returned to the API servers
- Client 2 gets the metadata
- Once the client receives the metadata, it sends requests to block servers to download blocks
- Block servers first download blocks from cloud storage
- Cloud storage returns blocks to the block servers
- Client 2 downloads all the new blocks to reconstruct the file
4.6 Notification service
To maintain file consistency, any mutation of a file performed locally needs to be informed to other clients to reduce conflicts. Notification service is built to serve this purpose. Two options for the notification service:
- Long polling
- WebSocket
We choose long polling for two reasons:
- Notification service doesn't need bi-directional: server sends notification to client, but client doesn't send information to server
- WebSocket is suited for real-time bi-directional communication such as a chat app. Notifications are sent infrequently with no burst of data.
For long polling:
- Each client establishes a long poll connection to the notification service
- If changes to a file are detected, the client will close the long poll connection, and connect to the metadata server to download the latest changes
- After a response is received or connection timeout is reached, a client sends a new request to keep the connection open
4.7 Save Storage Space
To support file version history and ensure reliability, multiple versions of the same file are stored across multiple data centers. To reduce storage costs:
- De-duplicate data block: Two blocks are identical if they have the same hash value, remove the redundant block.
- Adopt an intelligent data backup strategy:
- Set a limit for the number of versions to store. If the limit is reached, the oldest version will be removed
- Keep valuable versions only: Some files might be edited frequently, To avoid unnecessary copies, we could limit the number of saved versions, give more weight to recent versions
- Moving infrequently used data to cold storage: Amazon S3 glacier is much cheaper than S3
4.8 Failure Handling
- Load balancer failure: If a load balancer fails, the secondary would become active and pick up the traffic. Load balancers usually monitor each other using a heartbeat, a periodic signal sent between load balancers
- Block server failure: If a block server fails, other servers pick up unfinished or pending jobs
- Cloud storage failure: If files are not available in one region, they can be fetched from different regions
- API server failure: It is a stateless service. If an API server fails, the traffic is redirected to other API servers by a load balancer
- Metadata cache failure: Metadata cache servers are replicated multiple times. If one node goes down, you can still access other nodes to fetch data.
- Metadata DB failure:
- Master down: If the master is down, promote one of the slaves to act as a new master and bring up a new slave node
- Slave down: If a slave is down, you can use another slave for read operations and bring another database server to replace the failed one
- Notification service failure: If a server goes down, all the long poll connections are lost, so clients must reconnect to a different server.
- Offline backup queue failure: Queues are replicated multiple times. If one queue fails, consumers of the queue may need to re-subscribe to the backup queue.