Understand Kubernetes Internals
1. Understanding the architecture
总体来说, 一个k8s cluster可分为两部分: k8s control plane和worker node. 若继续拆分, 可分为以下三个部分:
- control plane:
- etcd: 分布式的key-value数据存储系统
- API server: 用户和其他组件管理k8s cluster的唯一途径
- scheduler: 将未分配的pod分配到合适的node
- controller manager: 监控k8s cluster的状态, 检测其与期望状态的差异, 并纠正差异
- worker node:
- kubelet: 接收API server指令, 创建并监控pod, 并向API server回报pod状态
- kube-proxy: 实现Service的功能, 确保本机pod发出的数据正确地发送到指定pod
- container runtime (Docker, rkt等): 执行并管理container
- add-on component:
- k8s DNS server: 为k8s cluster内提供DNS服务, 允许pod使用hostname向其他pod发送数据
- dashboard: 方便管理员查看和管理k8s cluster的可视化工具
- ingress controller: 一个具有负载均衡的反向代理, 接收k8s cluster外部流量并根据规则将其发送给对应service
- heapster: k8s cluster的监控和指标收集工具
- CNI(container network interface)和CNI plugin: k8s为pod配置网络信息的一套标准接口
1.1 The distributed nature of Kubernetes components
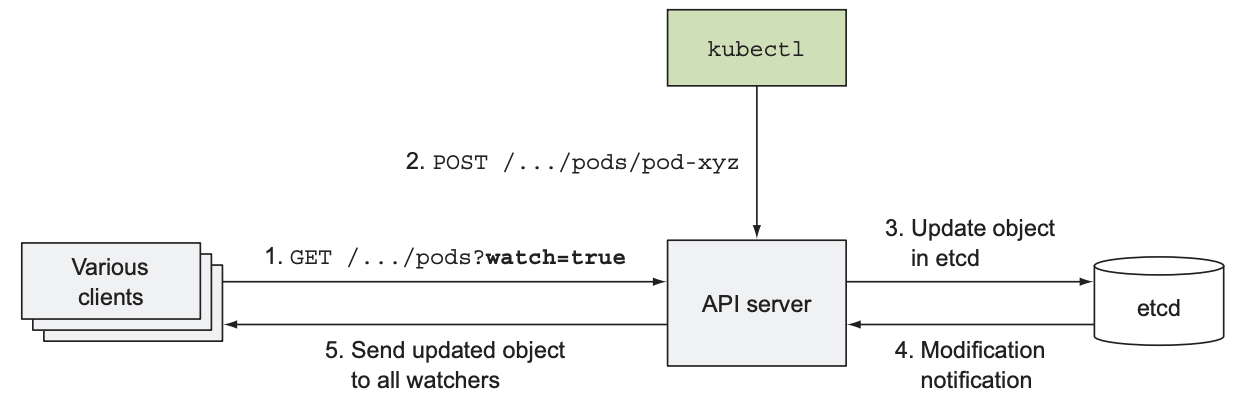
上述提到的所有组件都是独立运行的, 组件间的关系如下图: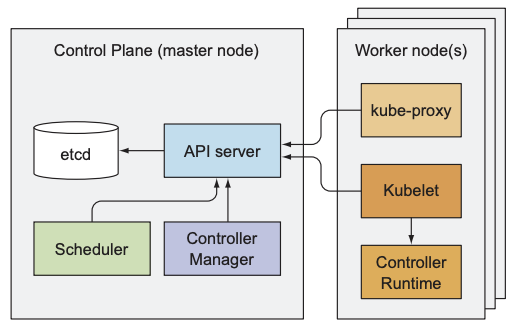
为启动k8s cluster的所有功能, 需运行所有组件; 有些组件不依赖其他组件, 而有些组件需要与其他组件合作. 若想查看control plane所有组件的状态, 可执行
$ kubectl get componentstatuses |
若想查询或写入etcd, 必须向API server发送信息, 因为API server是唯一与etcd沟通的组件, 这也是为什么其他组件都要与API server通信的原因. 大部分情况下是由其他组件向API server发起连接请求, 但若执行kubectl attach或kubectl port-forward时, API server会主动连接kubelet.
虽然一个worker node上的组件(kublet, kube-proxy, container runtime)只能运行一个实例, 但control plane的大部分组件可以运行多个实例, 以确保组件的可用性:
- 可运行多个实例的组件: etcd, API server
- 只能运行一个实例的组件: scheduler, controller manager(同一时间可存在多个实例, 但只有一个实例工作)
Control plane的组件和kube-proxy可直接在本机系统上运行, 也可在pod中运行; kubelet则只能在本机系统上运行, 因为其负责创建和监控pod. 若想让control plane的组件在pod中运行, 可在master node上运行kubelet. 以下是kube-system namespace下所有pod:
$ kubectl get po -o custom-columns=POD:metadata.name,NODE:spec.nodeName --sort-by spec.nodeName -n kube-system |
可以看到, etcd, API server, scheduler, controller manager和DNS server运行在master node上; kube-proxy和Flannel运行在worker node上, 且所有组件都以pod的形式运行.
1.2 How Kubernetes uses etcd
K8s中的所有资源以manifest的形式表示, 为防止API server崩溃重启时丢失manifest, k8s选择etcd作为其存储工具. etcd是一个快速响应, 分布式, 一致的键值存储工具:
- 分布式意味着一个etcd服务可运行多个实例, 即使其中一个实例的网络断开或崩溃也不会影响整个服务的读写
- API server是唯一与etcd通信的组件, 其他组件都需通过API server读取或写入数据
- 将API server作为etcd的唯一入口可更好地实现optimistic locking(乐观锁): 当k8s更新某个资源(deployment, Service等)时, manifest会包含一个名为
resourceVersion的版本号. API server会借助etcd的CAS操作对比版本号: 若版本号一致, 则更新并增加版本号; 若不一致, 则拒绝更新请求.
由于etcd的key可包含/(slash), 因此存储结构类似于文件系统: k8s将所有数据存放在/registry路径下, 不同路径对应不同资源类别:
$ etcdctl get /registry --prefix=true |
由于一个pod只能属于一个namespace, 因此/registry/pods路径下的不同路径对应不同namespace:
$ etcdctl ls /registry/pods |
$ etcdctl get /registry/pods/default/kubia-159041347-wt6ga |
API server将manifest以JSON形式存放在etcd中, etcd的每个文件路径都对应一个JSON文件, 且支持通过路径前缀查询该路径下的所有子路径.
由于k8s cluster中的所有数据都存放在一个etcd服务中, 任何k8s的请求都需要通过API server访问etcd. 为保证etcd高可用性, 一般会在一个etcd服务中运行多个etcd实例, 这样即使某个etcd实例崩溃也不会影响服务继续运行; 但多个实例会引入数据不一致性: 若API server分别向两个etcd实例写入同一资源的不同配置, 会导致两个etcd实例的数据不一致, 为此etcd使用RAFT共识算法保证任意时刻下都存在超半数的etcd实例拥有最新数据, 这样即使某个etcd实例崩溃或网络断开也不会影响整个etcd服务.
由于RAFT要求超过半数节点达成共识, 以下是节点数为偶数或奇数时的最大不可用节点数:
- 所有节点的数量为
2n: 最大不可用节点数为n-1 - 所有节点的数量为
2n-1: 最大不可用节点数仍为n-1
可以发现, 当最大不可用节点数相同时, 奇数需要的节点数更好, 因此etcd服务中通常配置奇数个etcd实例. 通常情况下, 一个大型k8s cluster需要5到7个etcd实例, 小型k8s cluster只需3个etcd实例.
1.3 What the API server does
K8s API server可被其他所有component或client使用, 其提供CRUD接口用于查询和修改k8s cluster状态, 并负责将状态保存到etcd中. 除此之外, API server还负责验证client上传的manifest是否正确, 并使用乐观锁确保同一资源不会被同时更新.
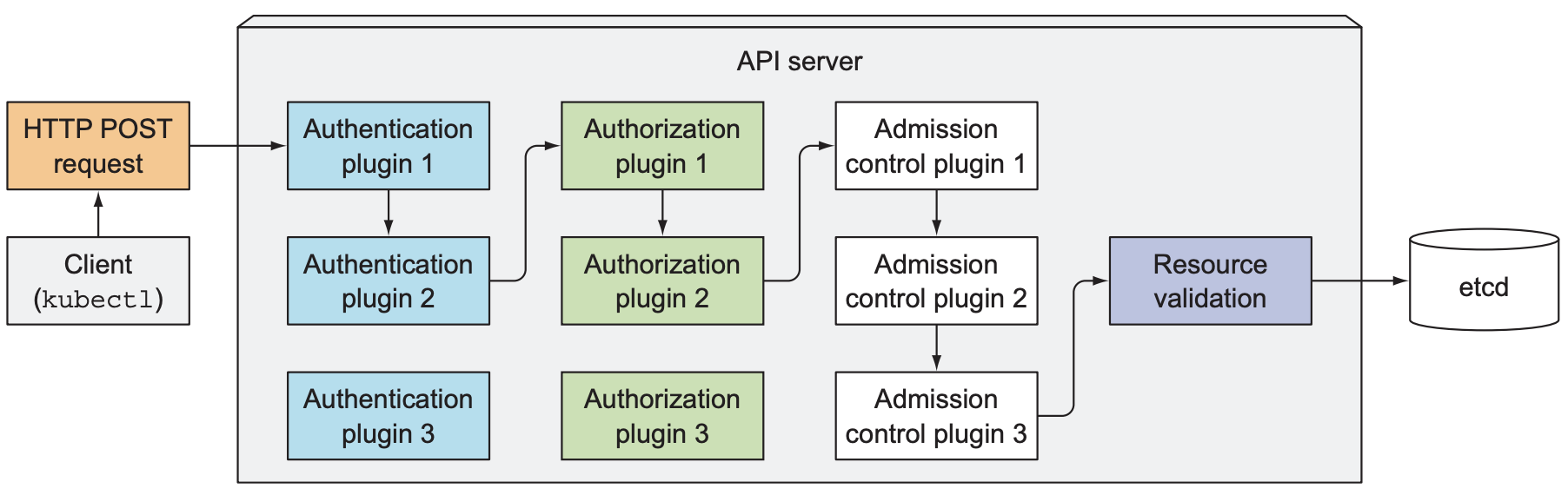
- 首先, API server需要认证发送请求的client, API server支持一个或多个身份认证插件(authentication plugin), 其会调用每一个插件, 直到某个插件成功验证请求. 不同的身份验证插件有不同验证方式, 如读取HTTP header的Authorization字段.
- API server还支持一个或多个授权插件(authorization plugin), 其决定用户可以进行哪些操作, 例如, 当请求想要创建pod时, API server需要依次查询授权插件来决定请求是否允许在指定namespace中创建pod, 只要其中一个授权插件允许即可进行下一步.
- 当请求需要创建, 修改或删除某个资源时, 请求会被发送到准入控制(Admission Control)插件, 其会因各种原因修改, 例如, 为缺失的字段添加默认值, 或覆盖某个字段值, 以下是一些常见的准入控制插件:
- AlwaysPullImages: 将pod的
imagePullPolicy重写为Always, 该字段保证每次部署pod时, 即使主机上存在image缓存也会重新下载image. - ServiceAccount: 若资源未指明service account, 则为pod添加默认值
- NamespaceLifecycle: 防止pod被删除时创建新的pod, 防止在不存在的namespace中创建pod
- ResourceQuota: 确保分配给pod的CPU或内存不会超过namespace的配额
- API server验证资源, 将其存入etcd, 并回应client
1.4 Understanding how the API server notifies clients of resource changes
API server不会创建pod, Replicaset或endpoint, controller manager负责创建资源. Controller会向API server请求监视某些资源的状态, 一旦API server收到创建, 修改或删除某个资源的请求时, 其会将其写入etcd并通知对应的controller.