Repository
1. Why we use Repository
由于ORM框架的大量使用, 程序员对于Entity的理解停留在数据映射的层面, 而忽略了Entity实体本身的行为, 造成代码中的模型仅包含属性, 而业务逻辑分散在service, controller, 和utils工具类. 也被称为Anemic Domain Model(贫血领域模型), 其具有以下特征:
- 定义了大量DO: 可表示Domain Object, 但仅仅包含数据库表的映射, 几乎没有业务逻辑
- Service和Controller中有大量业务逻辑: 比如校验逻辑, 计算逻辑, 格式转化逻辑, 对象关系逻辑, 数据存储逻辑
- 大量Utils工具类
贫血模型有以下缺点:
- 无法保证模型对象的完整性和一致性: 由于模型的属性都是公开的, 因此调用方很难维护模型的一致性
- 模型对象的可发现性很差: 单纯从模型对象上很难看出业务逻辑, 也无法判断什么时候被调用, 赋值边界是什么
- 代码逻辑重复: 校验, 计算逻辑可能出现在多个service中, 当贫血模型变更后, 校验逻辑由于出现在多次, 可能出现某些地方没有及时更新而导致校验失败
- 代码的健壮性差: 数据模型的变化可能导致整个代码块的变更
- 强依赖底层实现: 由于业务代码中强依赖底层数据库, 网络协议, 第三方服务, 造成逻辑代码僵化且维护成本高
以下是贫血模型出现的可能原因:
- 数据库思维: 由于程序员一开始学习各种工具和技术, 例如数据库, 因此思考项目的方式从写业务逻辑转变为读写数据库逻辑, 也就是CRUD代码
- 贫血模型的简单性: 由于数据库表的字段映射, 前后端可使用统一的格式沟通. 虽然开发时很方便, 但如果业务频繁变更, 反而会成为一件麻烦的事情
- 脚本思维: 脚本代码也称为胶水代码, 虽然容易理解, 但缺乏健壮性, 维护成本过高
更核心的原因在于, 开发者混淆了两个概念:
- Data Model(数据模型): 指如何将业务数据持久化, 以及数据之间的关系
- Domain Model(领域模型): 指业务逻辑中, 相关联数据如何联动
2. Overview of Repository
很多人听说过Repository Pattern, 但却缺乏Aggregate的概念, 随着数据关系复杂程度的升高, Repository也变得十分复杂. Repository的最大优势在于分离domain model和data model, 开发者可以更加轻松地拓展domain model, 优化数据库读取操作, 或向上层隐藏技术细节. Repository Pattern与DAO Pattern不同, DAO本质上是对数据库表的CRUD操作, 而Repository更专注于Domain Model(Aggregate)的操作. 不过Repository并不与DAO或ORM冲突, 甚至可以将DAO或ORM作为Repository的底层实现: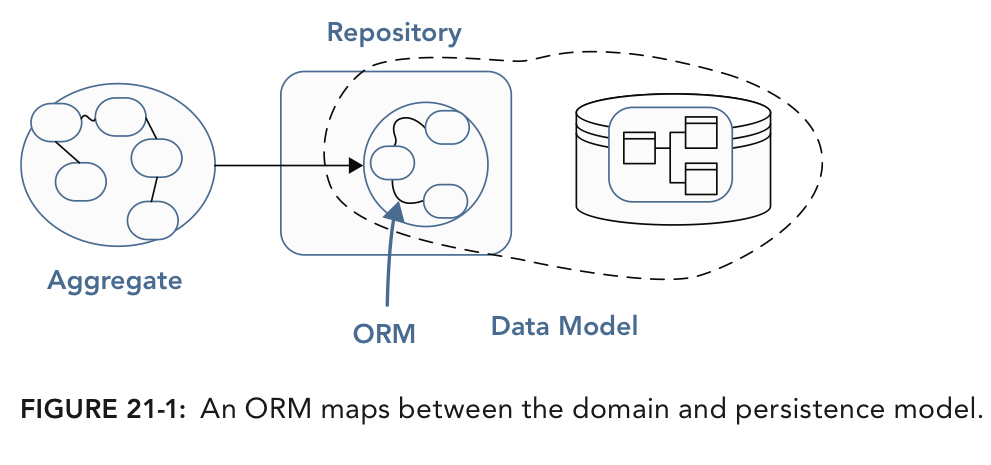
3. Application of Repository
实现Repository之前, 需要先了解Repository的特性:
- Repository只能从Aggregate Root中获取或修改domain model, 从而保证Aggregate内的variant
- Repository可隐藏底层的技术实现, 为上层提供一个与技术无关的接口
- Repository定义了domain model和data model的边界
class OrderId extends EntityId<string> {} |
Repository Interface可放在domain层, 与domain model(Order)一起, 这样能保证第一条特性. 有了interface, 以下是OrderRepository的实现(以Postgres为例):
class SqlOrderRepository implements OrderRepository { |
4. Separate the Technical Framework
首先定义一个通用的Repository:
interface Repository< |
然后在OrderRepository中使用这个Generic Repository:
class SqlOrderRepository implements OrderRepository { |
很多开发者更习惯于让Repository继承一个Generic Repository, 但这种做法会使得每个Repository采用相同的策略. 因此上述OrderRepository中, 我们采用composition的方式将Generic Reposiotry嵌入其中.
5. Convert between Domain Model and Data Model
从Repository中取出的data model需要重建为domain model, 而写入domain model之前也要先转换为data model. 实现这种转换的方式有很多, 最直接的方式就是将domain model中的所有属性都设置为public, 或实现一个Mapper专门用于转换:
class OrderMapper { |
6. Model Specification
| DO | Entity | DTO | |
|---|---|---|---|
| 目的 | 数据库表映射 | 业务逻辑 | 适配业务场景 |
| 代码层级 | Infrastructure | Domain | Application |
| 命名规范 | XxxDO | Xxx | XxxDTO |
| 字段名称标准 | 数据库表字段名 | 业务语言 | 与调用方协定 |
| 字段数据标准 | 数据库字段类型 | 表示业务含义的类型 | 与调用方协定 |
| 是否需要序列化 | 不需要 | 不需要 | 需要 |
虽然DO, Entity, DTO带来了代码量的膨胀, 但在复杂的业务场景下, 这样的功能区分会保证模型是功能单一且易测试的, 反而降低了逻辑复杂度.
假设我们想让项目从传统架构转向microservices, 项目中已有两个class: OrderDO和OrderDAO. 通过以下几个步骤可以实现Repository Pattern:
- 生成Order Entity类, 可保持和OrderDO相同字段
- 生成OrderDataConverter
- 测试Order和OrderDO之间的转化是否正确
- 生成OrderRepository interface和其实现
- 将原有代码中的OrderDO全部替换为Order
- 将原有代码中的OrderDAO改用OrderRepository