P2P Network
1. Peer-to-Peer(P2P)
从设计模式上来说, P2P打破了传统的客户端/服务器(Client/Sserver, 即C/S)模式, 在网络中的每个结点的地位都是对等的. 每个结点既充当服务器, 为其他结点提供服务, 同时也享用其他结点提供的服务. 下面是C/S模式和P2P模式的对比图: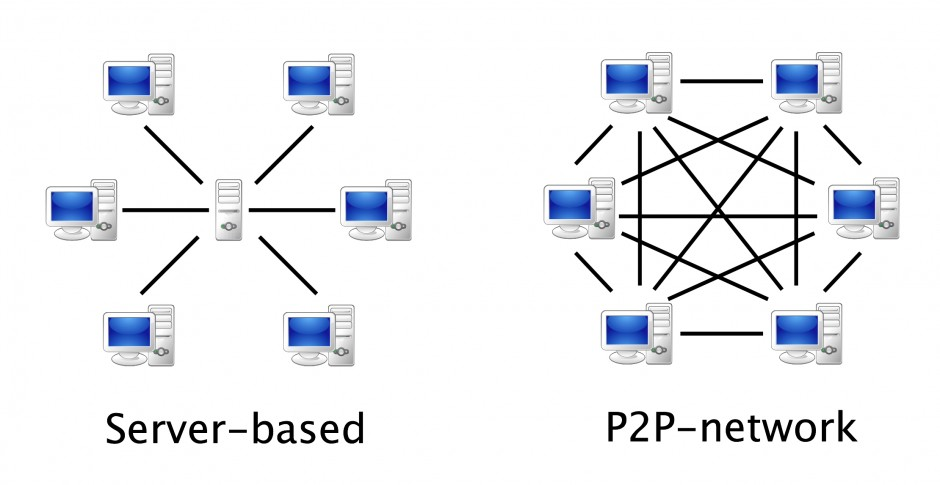
2. P2P优点
我尽量用通俗易懂的语言讲述, P2P有以下六点好处:
- 非中心化: 取消了Server的设定, 所以资源和服务都分散开来, 没有中心节点的控制和约束. 正是由于这条优点才引发了以下优点!
- 可扩展性: 在C/S模式中用户越多传输越慢, 因为服务器的能力有限, 所以扩展成满足大数量级用户群的架构很困难. 但P2P恰好相反, 由于用户增加会提供更多的资源, 所以网速会更快, 扩展性可以说是无限的.
- 健壮性: P2P中的一点被攻击不会导致整个架构崩溃, 会自动地调整拓扑结构;但C/S中Server被攻击后会影响所有client.
- 高性价比: P2P可利用互联网上散步节点进行存储和计算, 并不需要自己搭建大容量大计算能力的Server.
- 隐私保护: 由于信息的传输分散在各节点之间进行而无需经过某个集中环节, 用户的隐私信息被窃听和泄漏的可能性大大缩小. 普通情况下可以采用中继跳转的方法来保护隐私, 但P2P中每个节点都充当中继服务器的角色, 所以提高了匿名通讯的灵活性和可靠性.
- 负载均衡: P2P中每个节点既是客户端也是服务器, 资源也散布在各个节点, 所以没有集中计算和存储的需求.
3. P2P实现原理
3.1 NAT
NAT译为网络地址转换器(Network Address Translators). 由于IPv4的地址数量不能满足现实需要, 所以NAT应运而生, 缓解了IP地址不够的问题. 从历史角度分为两种: NAT(Basic Network Address Translators)和网络地址-端口转换器(NAPT, Network Address/Port Translators)
- 基本NAT(也叫作One-To-One NAT): 由于只有少量内网地址需要透过公网地址进行访问, 而且NAT设备有公网IP池, 这时可以直接将一个内网地址映射为一个公网地址, 不改变端口号
- NAPT(也叫作One-To-Many NAT): 同时修改IP和PORT, 这样可以实现一个公网IP映射多个内网IP
3.1.1 样例一
现在有一个IP为10.0.0.1的内网IP, 称为Client A, 他的外网网为155.99.25.11. 若Client A计算机中的某个进程创建了一个UDP Socket, PORT绑定为1234, 它试图访问18.181.0.31的1235端口, 接下来就是整个NAT的过程:
- NAT将改变这个数据包的原IP地址为它的外网地址
155.99.25.11, 端口号为62000, 这时连接从(10.0.0.1:1234->18.181.0.31:1235)变为(155.99.25.11:62000->18.181.0.31:1235) - NAT会记住62000端口对应
10.0.0.1:1234. 注意: 这里是指18.181.0.31的IP发送到该IP下会被转发, 其他IP发送到该端口就直接抛弃报文. - 接下来进入关键环节, 如果Client A的那个Socket向其他Server发送了UDP数据包会发生什么呢:
- NAT为这个Session再次分配一个端口号(如PORT 62001), 这种称为Symmetric NAT, 很多P2P软件可能失灵(后续会讲到)
- NAT端口号不变, 还是使用原来的端口号62000, 称为Cone NAT
- 接下来Client A就可IP以通过
155.99.25.11:62000这个Session地址与18.181.0.31:1235进行通讯,18.181.0.31这个IP可以向155.99.25.11:62000这个Session地址进行回复, 但其他外网IP不能向这个Session地址传输数据包, 因为路由在Client A进行穿透时进行了IP记录, 会自动抛弃除18.181.0.31之外的IP.
3.1.2 样例二
样例一描述了内网与外网的通讯, 该样例将会讲述两个内网之间的通讯, 因为这种情况更复杂, 也更普遍: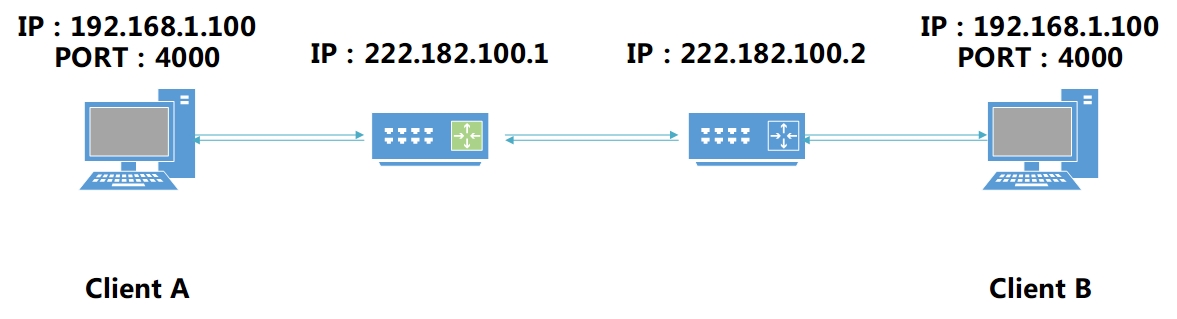
如上图所述:
- Client A的IP和PORT为
192.168.1.100:4000 - Client B的IP和PORT为
192.168.1.100:4000 - Client A的公网IP为
222.182.100.1 - Client B的公网IP为
222.182.100.2
这时Client A和Client B都没法与对方通讯, 因为将对方的内网地址发给路由时路由会直接扔掉. 这时需要一个固定的外网IP的服务方进行通讯协助, 我们假设双方的NAT都是Cone NAT.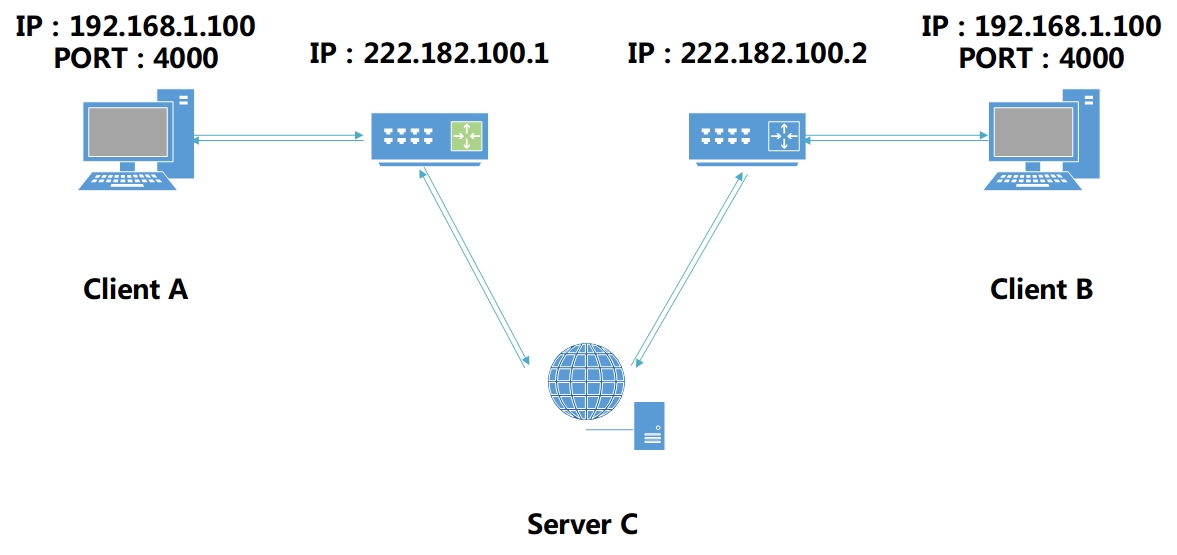
- 这时A通过路由向C发送信息, C获取A在路由上的Session地址, A在外网路径上建立临时Session地址.
- B也建立Session并向C发送信息, C同样获取B的Session地址.
- C通知A方B的Session, 也通知B方A的Session地址
- A想连接B, 所以向C发送请求探测的数据包
- C把A的请求转发给B, B向A的临时Session地址发送探测包, 由于该临时地址只能接受C发来的数据包, 所以被丢弃, B向C发送反馈报, 表示已经连接过A. (这一步并不浪费, 因为B已经可以接受A发来的信息)
- C转发给A反馈包, 这时A就可以发送数据包给B, 连接完成.
3.2 Cone NAT
Cone NAT对于已经建立的Session的输入还有分类:
- 全圆锥(Full Cone): 任何主机都可以通过这个Session地址来连接该内网主机
- 限制性圆锥(Restricted Cone): 建立Session时记录发送到的目的地IP, 只有该IP返回的数据包才接受, IP个数不定.
- 端口限制性圆锥(Port Restricted Cone): 建立Session时记录目的地的IP和PORT, 只有两者都正确的外网数据才能够进入.
讲述完Cone NAT的几种类型, 我们可以看一下端口限制性圆锥NAT和对称性NAT的内网沟通: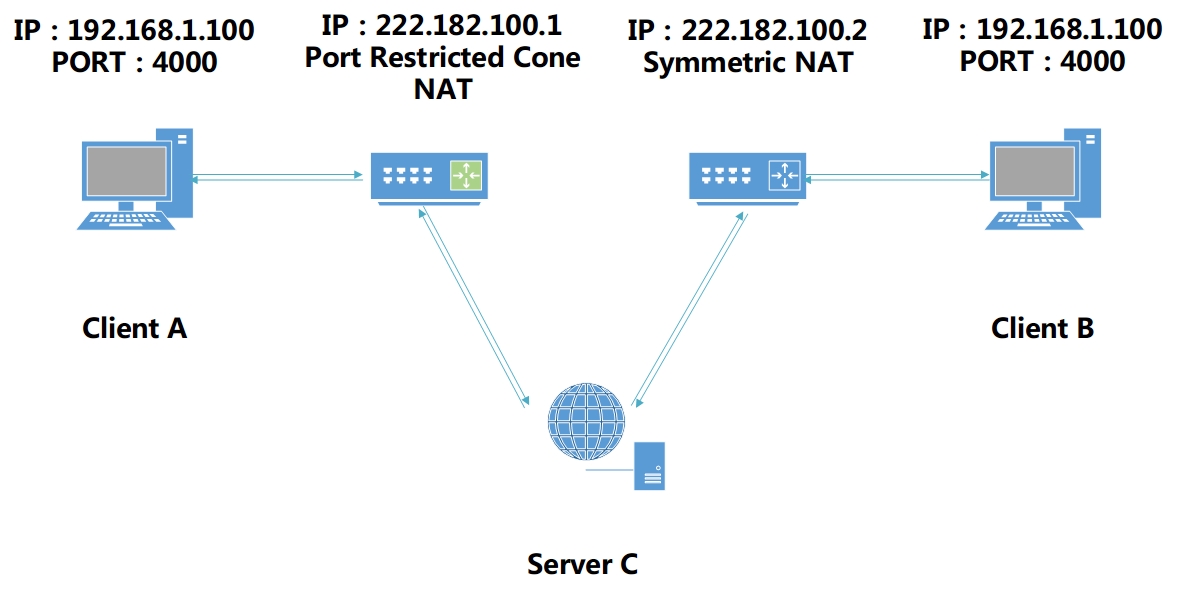
如上图所示: Client A的NAT为端口限制圆锥型, Client B的NAT是对称型.
假设B与C连接时使用的Session地址端口号为7000, 那么C告诉A方B的Session地址端口号也就是7000. 但由于B的NAT是对称型, 所以当B向A发送探测包时开启了另一个端口号, 假设端口号为8000, 那么A向B发送数据时由于A是向B端口号为7000的Session发送, 而B端口号7000的Session并不认识A, 所以导致直接丢弃数据包, 打洞失败. 但对于这种情况可以进行端口预测.
第二种情况就是两端内网的NAT都是对称型, 这样也没法进行内网穿透.
4. P2P的网络拓扑结构
拓扑结构部是指分布式系统中各个计算单元之间的物理或逻辑的互联关系. 目前互联网中广泛使用集中式、层次式等拓扑结构, 一般Web应用运行在集中式的服务器系统上, 这样的拓扑结构面临过度存储负载、DOS(Denial of Service)攻击、网络带宽限制等问题. P2P系统主要采用非集中式的拓扑结构, 分为以下四种:
- 中心化拓扑(Centralized Topology)
- 全分布式非结构化拓扑(Decentralized Unstructured Topology)
- 全分布式结构化拓扑(Decentralized Structured Topology, 也称作DHT网络)
- 半分布式拓扑(Partially Decentralized Topology)
4.1 中心化拓扑
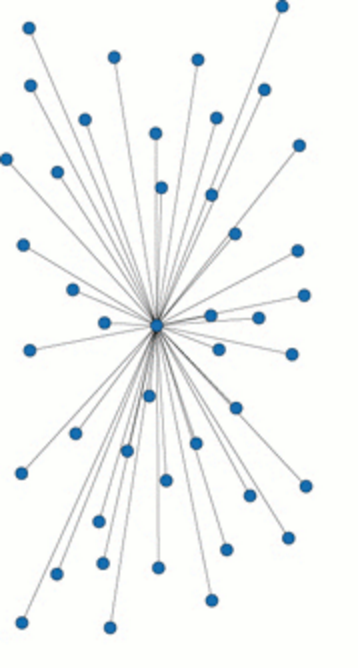
特征就是资源的发现依赖于中心化的目录系统. 该拓扑结构最大的优点就是维护简单, 资源发现效率高, 而且发现算法灵活高效, 能实现复杂查询. 但问题和C/S结构一样, 就是单一的点故障会造成整体受影响, 不易扩展和维护.
例如, Napster. Napster通过中央索引服务器保存所以Napster用户上传的音乐文件索引和存放位置, 当某个用户需要某个音乐文件时, 首先连接Napster中心索引服务器, 然后服务器搜索并返回该文件的用户信息, 再由请求者向音乐文件的所有者进行索要并传输文件.
综上所述, 该结构适合小型网络, 不适合大型网络.
4.2 全分布式非结构化拓扑结构
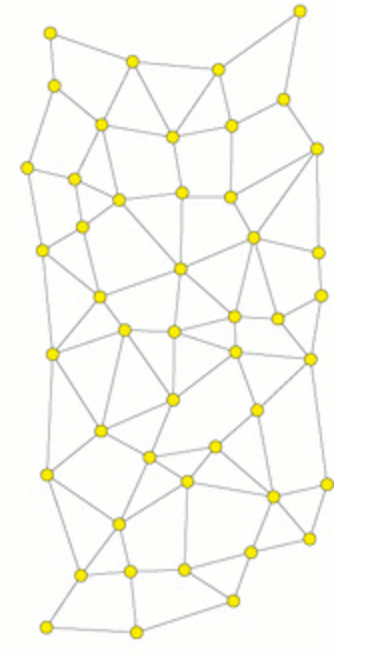
该结构采用随即图的组织方式, 节点度数服从Power-law规律, 从而能够较快发现目的节点. 具有很好的容错能力和可用性, 也支持复杂查询和模糊查询. 但由于随着节点数量的增加导致低带宽节点会因网络资源过载而实现, 所以很容易出现分区现象.
例如, Gnutella. 作为一种网络协议, 它的结构比Napster更加纯粹, 因为它没有中心索引服务器, 每台机器既是服务器, 也是客户端. 早期它使用Flooding搜索算法, Flooding算法距离步骤如下:
- 网络上的任一台主机在需要查询资源时, 先根据查询的内容形成一条查询消息(query 消息).
- 查询源主机将该query消息发送给网络上与其直接相连的其他主机.
- 收到query消息的主机搜索自身的资源. 如果有与查询消息相匹配的资源, 则形成一个queryHit消息, 按照query消息来时的路径发送给源查询主机;如果没有要找的信息, 收到query消息的主机将该消息转发至除发送消息的主机以外的其他主机.
4.3 半分布式拓扑结构
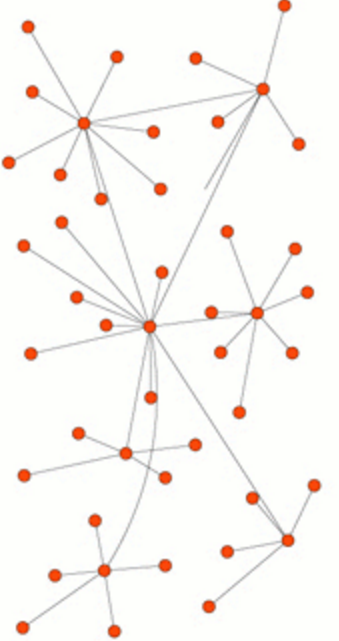
该结构吸取了中心化结构和全分布式非结构化拓扑的优点, 选择性能较高的节点作为超级节点. 在各个超级节点上存储了系统中其他部分的信息, 发现算法仅在超级节点之间转发, 超级节点再将查询请求转发给适当的叶子节点. 半分布式结构也是一个层次式结构, 超级节点之间构成一个高速转发层, 超级节点和所有负责的普通节点构成若干层次.
例如: KaZaa. 它使用Gnutella的全分布式的结构, 这样可以更好地拓展系统, 因为它无需中央索引服务器存储文件信息. 它会自动找寻性能较好的机器成为SuperNode, 并存储离它最近的叶子节点的文件信息, 这些SuperNode连通起来形成一个Overlay Network.
半分布式结构的优点是性能、可扩展性较好、较容易管理, 但对SuperNode依赖性大, 易于受到攻击, 容错性也受到影响.
4.4 全分布式结构化拓扑
该结构主要采用分布式散列表(Distributed Hash Table)技术来组织网络中的节点.
DHT原理介绍: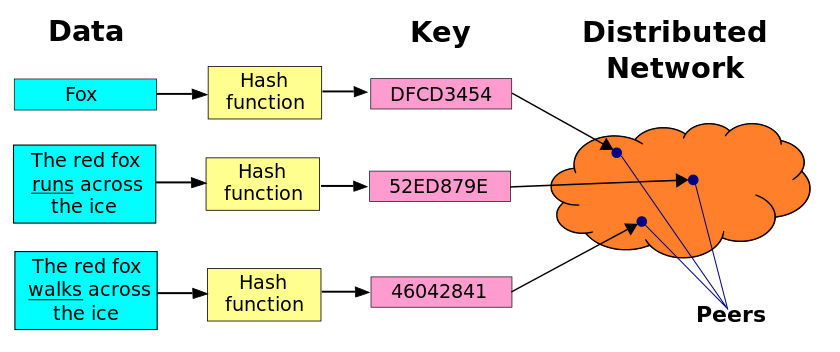
DHT是一个巨大的散列表, 被分割成不连续块, 每个节点被分配成一个属于自己的散列块, 并成为这个散列块的管理者.
每份资源都由一组关键字进行标示, 系统对其中的每个关键字进行Hash, 得到关键字标志符Key;网络中的每个节点也通过Hash节点IP得到节点标志符ID;关键字标志符Key和节点标志符ID都是唯一的, 按照某种映射关系, 将Key映射到ID上, 该ID对应的节点存储此Key的对应信息. 所有(Key, Value)对构成一张很大的文件索引散列表. Key是关键字标志符, Value是要存储的信息地址(所有ID). 这样用户搜索时就可以用同样的Hash算法计算出每个关键字的标志符Key, 再根据Key知道该Key对应信息的存储位置, 从而快速定位资源位置.
通过加密散列函数, 一个对象的名字或关键词被映射为128位或160位的散列值. DHT可以提供精确的发现, 主要目的节点存在于网络中DHT就肯定能发现它.
样例: Tapestry, Pastry, Chord和CAN
4.4.1 Tapestry
该算法可以对消息进行与位置无关的路由, 把查询消息传递到最近的存储有目标对象拷贝的节点. 它具有自组织、容错和负载平衡等特点. 每个Tapestry节点只需维护O(logN)大小的路由表信息, Tapestry从一个标识符空间中分配一个全局唯一标识符GUID(Globally Unique Identifier). Tapestry使用SHA-1来产生标识符, 使得nodeID和GUID均匀分布在标志符空间中. 所有节点依据标志符自组织成一个重叠网络.
4.4.2 Pastry
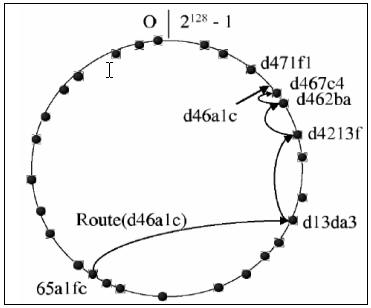
该结构时每个节点分配一个128位的节点标识符号(nodeID), 所有的nodeID形成一个环形的nodeID空间, 范围从0到2^128-1, 节点加入系统时通过散列节点IP地址在128位nodeID空间中随机分配.
4.4.3 Chord
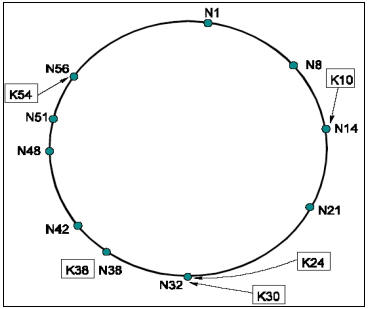
通过使用DHT技术使得发现指定对象只需要维护O(logN)长度的路由表. 在DHT技术中, 网络节点按照一定的方式分配一个唯一的节点标志符(Node ID), 资源对象通过散列运算产生一个唯一的资源标志符(Object ID), 且该资源将存储在节点ID与之相等或相近的节点上. Chord是相容散列算法的变体.
4.4.4 CAN(Content Addressable Networks)
采用多维的标志符空间来实现分布式散列算法, CAN将所有节点映射到一个n维的笛卡尔空间中, 并为每个节点尽可能均匀的分配一块区域. CAN采用的散列函数通过对<key, value>中的key进行散列运算, 得到笛卡尔空间中的一个点, 并将<key, value>存储在拥有该点所在区域的结点内. CAN采用的路由算法相当直接和简单, 知道目标点的坐标后, 就将请求传给当前结点四邻中坐标最接近目标点的结点. CAN是一个具有良好可扩展性的系统, 给定N个结点, 系统维数为d, 则路由路径长度为O(n1/d) , 每结点维护的路由表信息和网络规模无关为O(d).