System Design - Web Crawler
1. Introduction
Web crawler is used by search engines to discover new or updated content on the web. A web crawler starts by collecting a few web pages and then follows links on those pages to collect new content.
A crawler is used for many purposes:
- Search engine indexing: collect web pages to create a local index for search engines
- Web archiving: collect information from the web to preserve
data for future uses - Web mining: help to discover useful knowledge from the internet
- Web monitoring: help to monitor copyright and trademark infringements over the Internet
2. Understand the Problem and Establish Design Scope
Basic algorithm of a web crawler:
- Given a set of URLs, download all the web pages addressed by the URLs
- Extract URLs from these web pages
- Add new URLs to the list of URLs to be downloaded
2.1 Questions
- What is the main purpose of the crawler: Search engine indexing
- How many web pages does the web crawler collect per month: 1 billion pages
- What content types are included: HTML only
- Shall we consider newly added or edited web pages: Yes, both
- Do we need to store HTML pages crawled from the web: Yes, up to 5 years
- How do we handle web pages with duplicate content: Pages with duplicate content should be ignored
2.2 Characteristics of a Good Web Crawler
- Scalability: Web crawling should be efficient by using parallelization
- Robustness: web crawler should handle bad HTML, unresponsive servers, crashes, malicious links
- Politeness: web crawler should not make too many requests to a website in a short time interval
- Extensibility: minimal changes are needed to support new content types
2.3 Back of the Envelope Estimation
- Assume 1 billion web pages are downloaded every month
- QPS: 1,000,000,000 / 30 days / 24 hours / 3600 seconds = 400 pages per second
- Peak QPS = 2 * QPS = 800 pages per second
- Assume the average web page size is 500k
- 1,000,000,000 x 500k = 500 TB storage per month
- 500 TB * 12 months * 5 years = 30 PB for five years
3. Propose high-level design and get buy-in
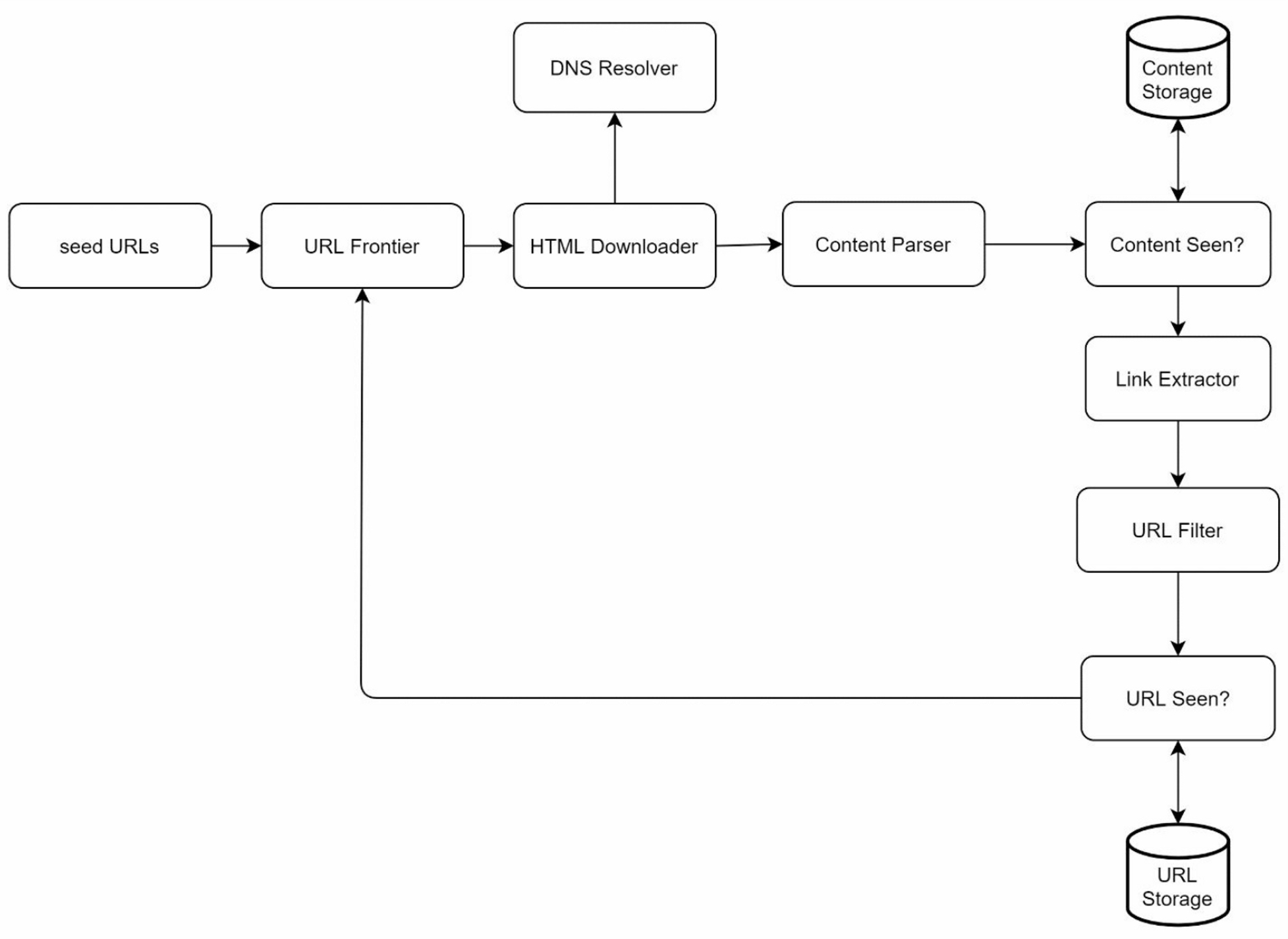
3.1 Seed URLs
A web crawler uses seed URLs as a starting point for the crawl process. A good seed URL serves as a good starting point that a crawler can utilize to traverse as many links as possible. The general strategy is to divide the entire URL space into smaller ones:
- Based on locality as different countries may have different popular websites
- Based on topics
3.2 URL Frontier
Most modern web crawlers split the crawl state into two:
- to be downloaded
- already downloaded
The component that stores URLs to be downloaded is called the URL Frontier, implemented by a First-in-First-out (FIFO) queue.
3.3 HTML Downloader
The HTML downloader downloads web pages from the internet. Those URLs are provided by the URL Frontier.
3.4 DNS Resolver
To download a web page, a URL must be translated into an IP address. The HTML Downloader calls the DNS Resolver to get the corresponding IP address for the URL.
3.5 Content Parser
After a web page is downloaded, it must be parsed and validated because malformed web pages could provoke problems and waste storage space.
3.6 Content Seen?
Online research reveals that 29% of the web pages are duplicated contents, which may cause the same content to be stored multiple times. This component is to eliminate data redundancy and shorten processing time. To compare two HTML documents:
- compare character by character: slow and time-consuming
- compare the hash values of the two web pages
3.7 Content Storage
Storage system for storing HTML content. The choice of storage system depends on factors such as data type, data size, access frequency, life span, etc.
- Most of the content is stored on disk because data set is too big to fit in memory
- Popular content is kept in memory to reduce latency
3.8 URL Extractor
Parse and extract links from HTML pages. Relative paths are converted to absolute URLs by adding website prefix.
3.9 URL Filter
Excludes certain content types, file extensions, error links and URLs in "blacklisted" sites.
3.10 URL Seen?
A data structure that keeps track of URLs that are visited before or already in the Frontier. Bloom filter and hash table are common techniques to implement the component.
3.11 URL Storage
Stores already visited URLs.
3.12 Web Crawler Workflow
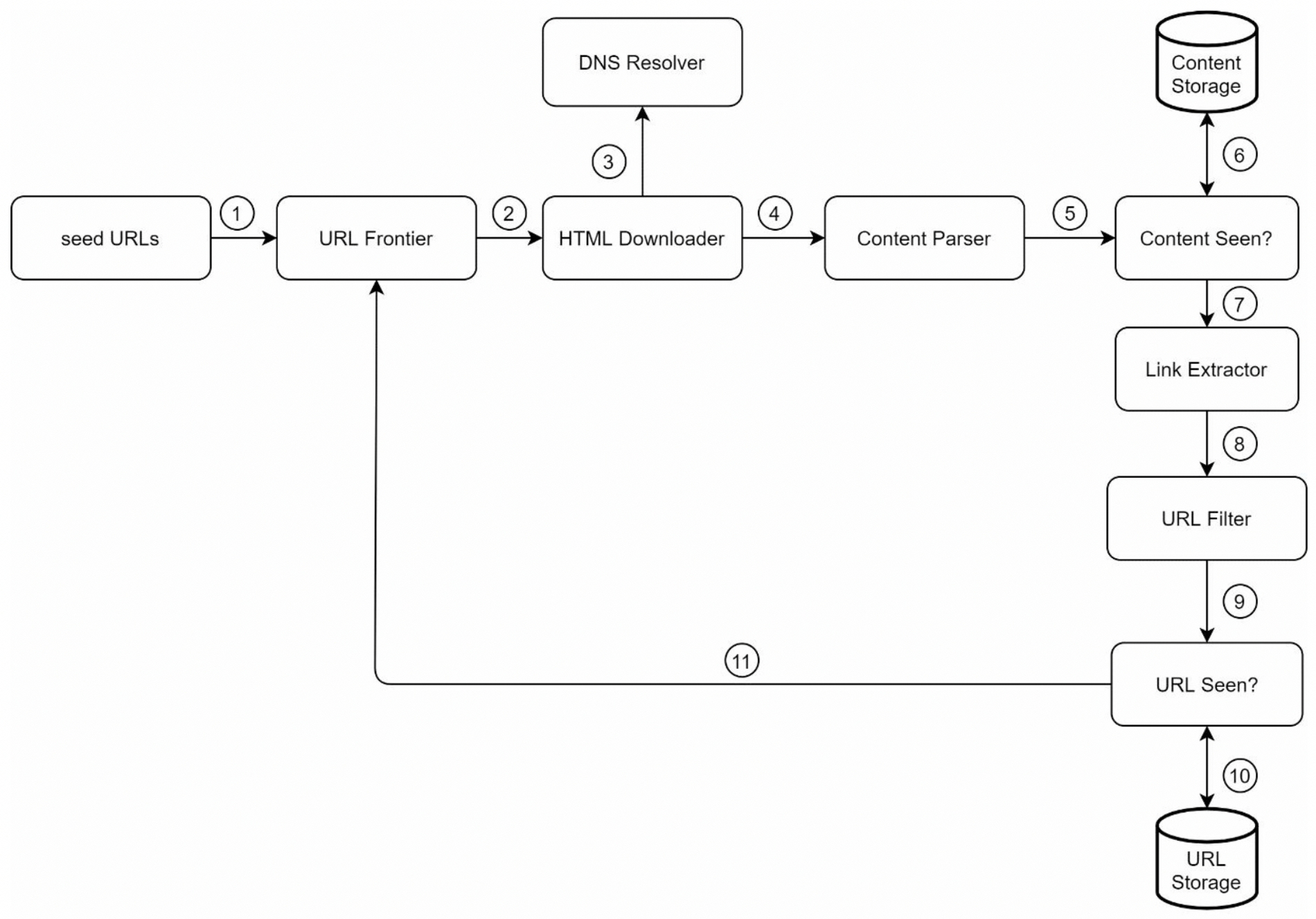
- Add seed URLs to the
URL Frontier HTML Downloaderfetches a list of URLs fromURL FrontierHTML Downloadergets IP addresses of URLs fromDNS resolverand starts downloadingContent Parserparses HTML pages and checks if pages are malformed, and passed to theContent Seen?Content Seen?checks if a HTML page is already in the storage- If it is in the storage, the HTML page is discarded
- If it is not in the storage, passed to
Link Extractor
Link extractorextracts links from HTML pages, and passed to theURL Seen?URL Seen?checks if a URL is already in the storage. if yes, it is processed before, and nothing needs to be done.- If a URL has not been processed before, added to the
URL Frontier
4. Design deep dive
4.1 DFS vs BFS
web as a directed graph, web pages serve as nodes and hyperlinks. Web crawl process can be seen as traversing a directed graph from one page to others. DFS is usually not a good choice because the depth of DFS can be very deep.
BFS is commonly used by web crawlers and is implemented by a first-in-first-out(FIFO) queue. This implementation has two problems:
- Most links from the same web page are linked back to the same host. When the crawler tries to download web pages in parallel, servers will be flooded with requests. This is considered as "impolite".
- Standard BFS does not take the priority of a URL into consideration, not every page has the same level of quality and importance.
4.1 URL frontier
A URL frontier is a data structure that stores URLs to be downloaded. The URL frontier is an important component to ensure politeness, URL prioritization, and freshness.
4.1.1 Politeness
A web crawler should avoid sending too many requests to the same hosting server within a short period.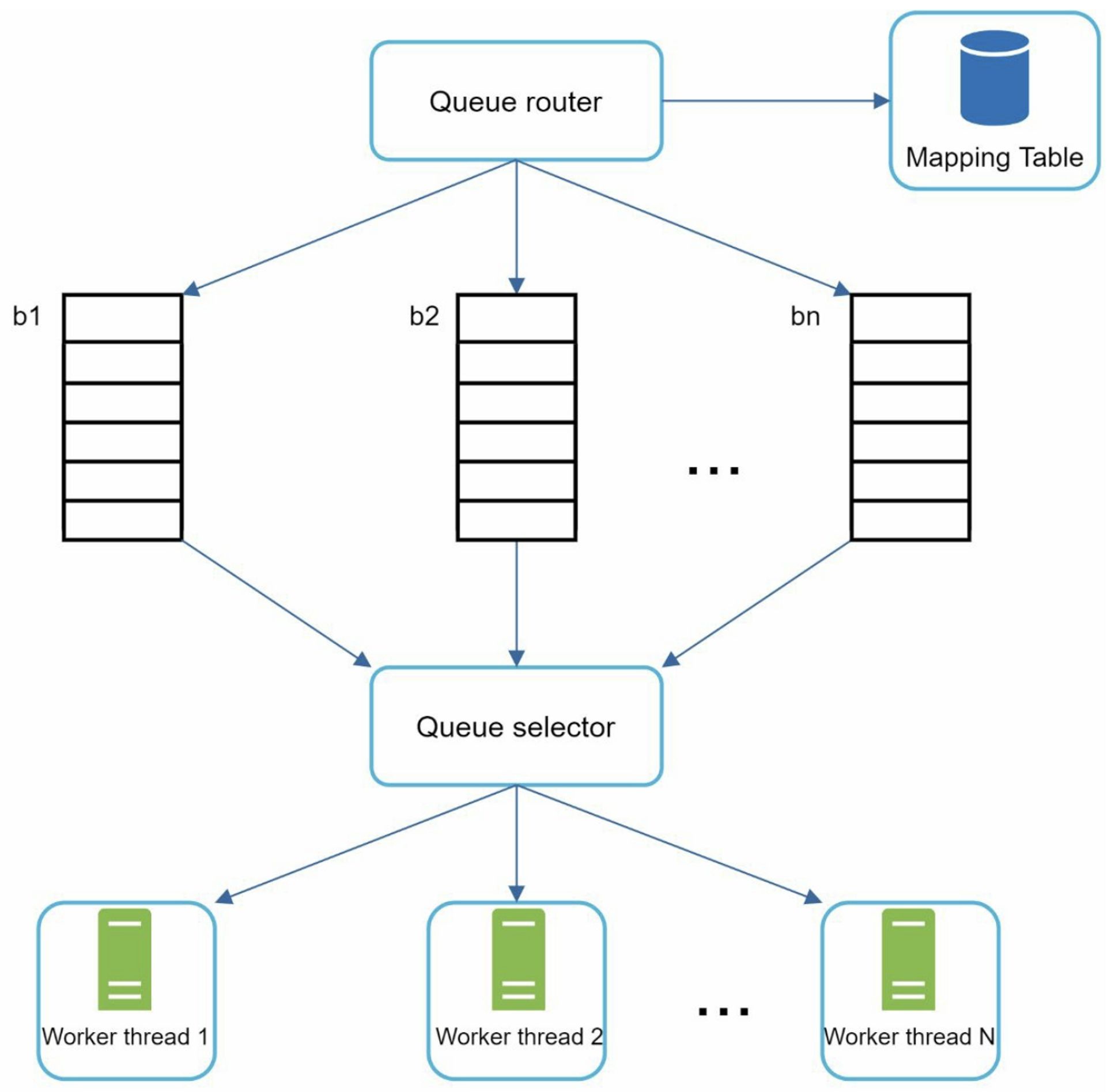
- Queue router: It ensures that each queue (b1, b2, … bn) only contains URLs from the same host
- Mapping table: It maps each host to a queue
- FIFO queues b1, b2 to bn: Each queue contains URLs from the same host
- Queue selector: Each worker is mapped to a FIFO queue, and it only downloads URLs from that queue
- A worker only downloads web pages from the same host. A delay can be added between two download tasks.
4.1.2 Priority
We prioritize URLs based on usefulness, which can be measured by PageRank, website traffic, update frequency, etc.
- The input URL will be passed to prioritizer(which handles URL prioritization)
- Queue f1 to fn: Each queue has an assigned priority.
- Queue selector: Randomly choose a queue with a bias towards queues with higher priority.
4.1.3 Freshness
A web crawler must periodically recrawl downloaded pages to keep our data set fresh. Few strategies to optimize freshness:
- Recrawl based on web pages' update history
- Prioritize URLs and recrawl important pages first and more frequently
4.1.4 Storage for URL Frontier
the number of URLs in the frontier could be hundreds of millions: The majority of URLs are stored on disk, maintain buffers in memory for enqueue/dequeue operations.
4.2 HTML Downloader
4.2.1 Robots.txt
Robots.txt, called Robots Exclusion Protocol, is a standard used by websites to communicate with crawlers. It specifies what pages crawlers are allowed to download.
4.2.2 Performance optimization
- Distributed crawl: To achieve high performance, crawl jobs are distributed into multiple servers, each downloader is responsible for a subset of the URLs.
- Cache DNS Resolver: DNS cache keeps the domain name to IP address mapping and is updated periodically by cron jobs.
- Locality: Distribute crawl servers geographically. When crawl servers are closer to website hosts, crawlers experience faster download time.
- Short timeout: If a host does not respond within a predefined time, the crawler will stop the job and crawl some other pages.
4.3 Robustness
- Consistent hashing: distribute loads among downloaders, a new downloader server can be added or removed using consistent hashing
- Save crawl states and data: To guard against failures, crawl states and data are written to a storage system.
- Exception handling: web crawler must handle exceptions
- Data validation
4.4 Extensibility
The crawler can be extended by plugging in new modules.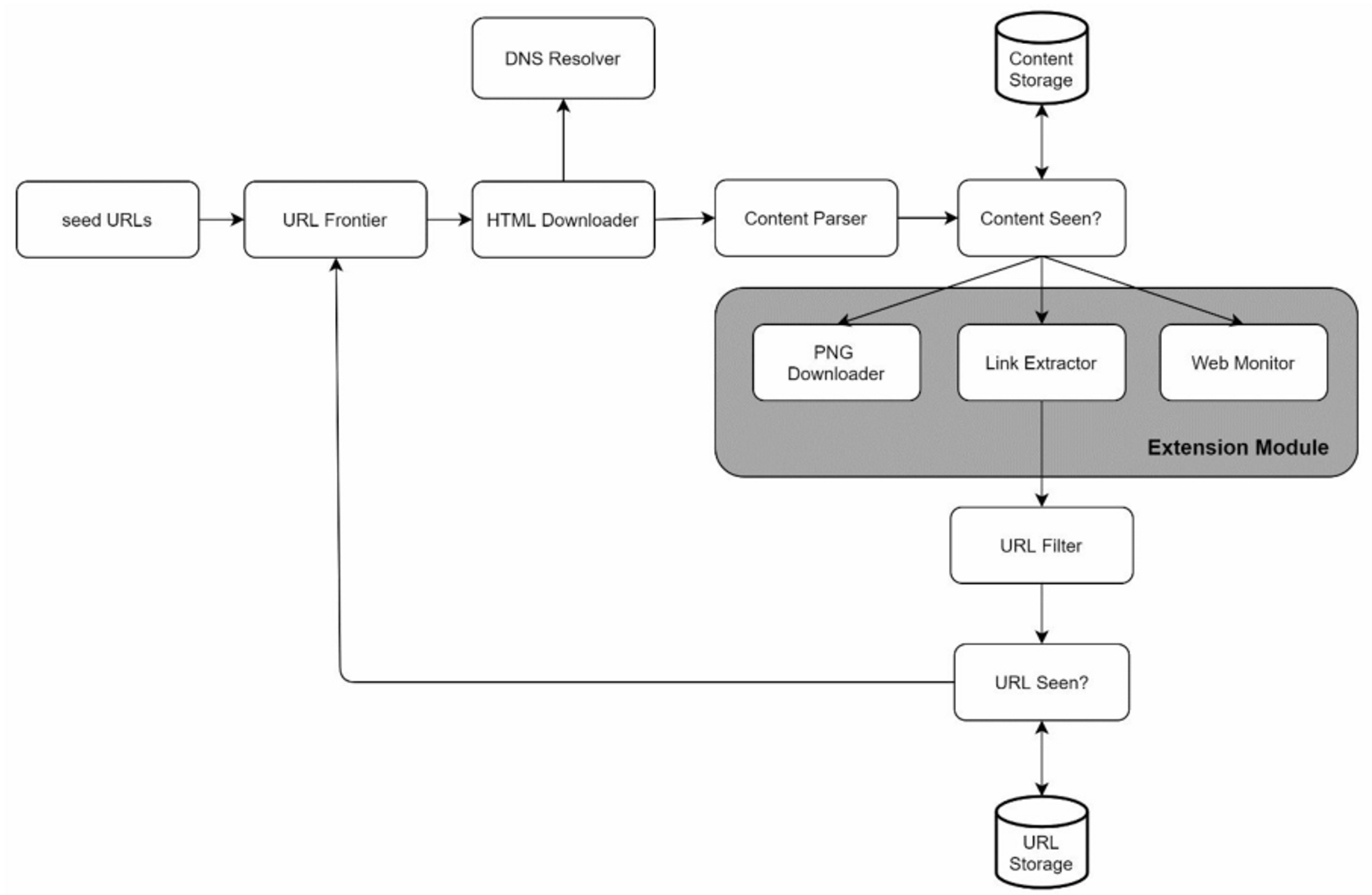
- PNG Downloader module is plugged-in to download PNG files.
- Web Monitor module is added to monitor the web and prevent copyright and trademark infringements
4.5 Detect and avoid problematic content
- Redundant content: Hashes or checksums
- Spider traps: A spider trap is a web page that causes a crawler in an infinite loop. For instance, an infinite deep directory structure is like:
www.example.com/foo/bar/foo/bar/foo/bar/.... Such spider traps can be avoided by setting a maximal length for URLs, but it's hard to develop automatic algorithms to avoid all types of spider traps. - Data noise: advertisements, code snippets, spam URLs should be excluded
5. Wrap up
Additional talking points:
- Server-side rendering: some website use scripts like JavaScript and AJAX to generate links. If we download and parse web pages directly, we will not be able to retrieve dynamically generated links.
- Filter out unwanted pages: an anti-spam component to filter out low quality and spam pages
- Database replication and sharding: replication and sharding are used to improve the data layer availability, scalability, and reliability
- Horizontal scaling: keep servers stateless -> thousands of servers perform download tasks
- Analytics: collect and analyze data