1. PyDictObject对象
PyDictObject作为一个关联容器, 最重要的功能就是建立key与value之间的联系, 并且key的搜索效率十分关键, C++的map采用了RB-tree, 时间复杂度为O(log2N). Python采用散列表(hash table)提供O(1)复杂度的搜索效率.
1.1 hash table
Hash table的基本思想: 通过一个函数将key映射成一个整数, 该整数作为索引(index)来访问某片连续的内存区域. 例如: 有十个整数, 依次对应a, b, ..., j. 申请一块连续内存, 并依次存储a, b, ..., j.

当我们需要寻找字母b时, 只需要将key转换为2即可, 然后访问这片内存的第2个位置, 就能得到字母b. 负责将key转换为index的函数称为散列函数(hash function), hash function的选择决定了散列表的搜索效率.
随着越来越多的元素装入hash table, 会出现散列冲突, 且与装载率有一定的关联. 装载率意为hash table中已使用空间与总空间的比例. 若hash table可容纳10个元素, 当装入第6个元素时发生了冲突, 那么装载率为6/10. 实践证明, 当装载率大于2/3时, 散列冲突发生的概率大大增加.
针对散列冲突, Python采用开放定址法来解决: 发生散列冲突时, 会通过一个两次探测函数f来计算下一个候选位置addr: 若addr可用, 将元素插入该addr; 若addr不可用, 则探测下一个位置, 直到找到空闲位置.
通过多次使用探测函数f, 即可从一个位置跳转到其他位置, 形成一个"冲突探测链". 需要删除探测链上某个元素时, 会造成探测链的断裂, 这样下次搜索元素时就不能绕过断裂点探测到后面的元素. 基于开放定址冲突策略的hash table中, 删除元素采用一种"伪删除"的策略, 即让被删除元素依然存在探测链上.
2. PyDictObject
2.1 关联容器的entry
关联容器的一个<key, value>称为一个entry, 定义如下:
typedef struct {
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;
|
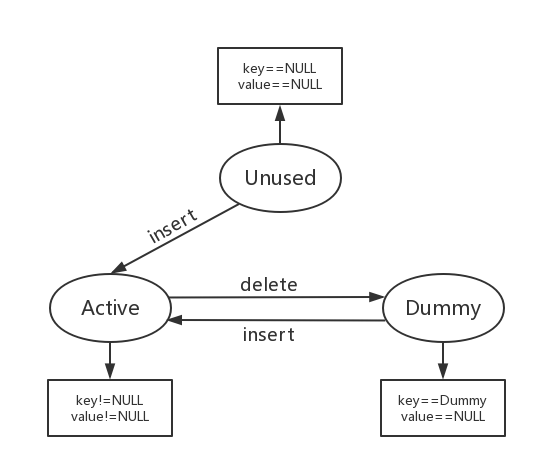
PyDictObject有三种状态: Unused, Active, Dummy
- entry中的key和value都为NULL: entry处于Unused. Unused态表示目前该entry没有存储元素, 每一个entry初始化时都处于该状态.
- entry存储了一个元素: 切换为Active, key和value都不能为NULL.
- entry中存储的元素被删除: 切换为Dummy, 若搜索元素时发现entry为Dummy, 说明该entry无效, 但该entry后面的entry可能是有效的.
2.2 关联容器的实现
以下是PyDictObject对象的实现:
#define PyDict_MINSIZE 8
typedef struct _dictobject PyDictObject;
struct _dictobject {
PyObject_HEAD
Py_ssize_t ma_fill;
Py_ssize_t ma_used;
Py_ssize_t ma_mask;
PyDictEntry *ma_table;
PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
};
|
当entry个数小于8个时, ma_table指向ma_smalltable; 当entry个数大于8个时, 将会申请额外的内存空间, ma_table指向额外空间.
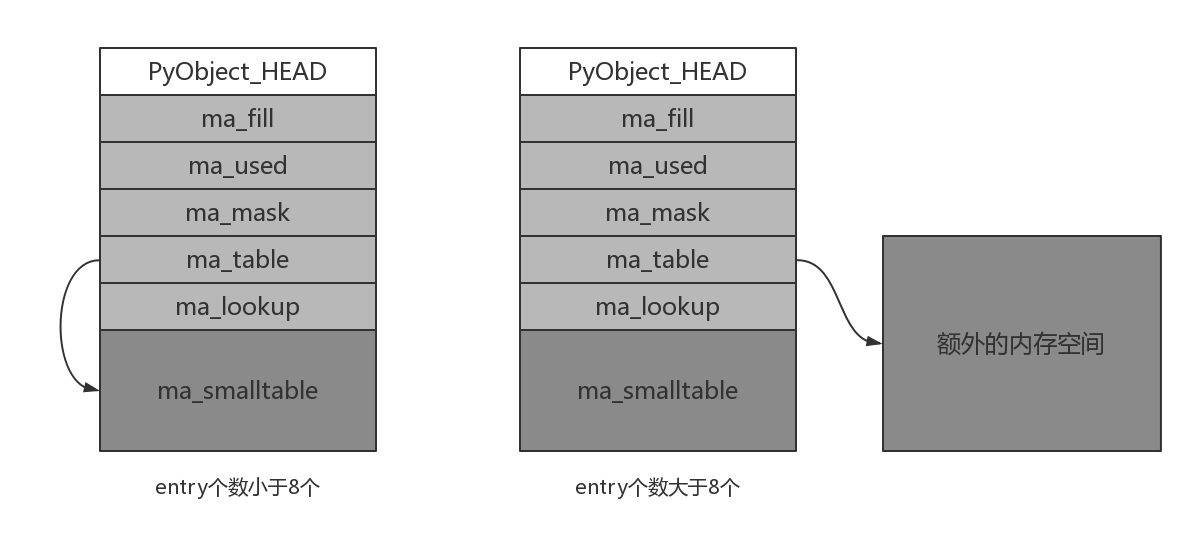
ma_mask表示PyDictObject中的entry个数, ma_lookup为探测函数的指针
3. PyDictObject的创建和维护
3.1 PyDictObject对象的创建
typedef PyDictEntry dictentry;
typedef PyDictObject dictobject;
#define INIT_NONZERO_DICT_SLOTS(mp) do { \
(mp)->ma_table = (mp)->ma_smalltable; \
(mp)->ma_mask = PyDict_MINSIZE - 1; \
} while(0)
#define EMPTY_TO_MINSIZE(mp) do { \
memset((mp)->ma_smalltable, 0, sizeof((mp)->ma_smalltable)); \
(mp)->ma_used = (mp)->ma_fill = 0; \
INIT_NONZERO_DICT_SLOTS(mp); \
} while(0)
PyObject* PyDict_New(void)
{
register dictobject *mp;
if (dummy == NULL) {
dummy = PyString_FromString("<dummy key>");
if (dummy == NULL)
return NULL;
}
if (num_free_dicts) {
mp = free_dicts[--num_free_dicts];
assert (mp != NULL);
assert (mp->ob_type == &PyDict_Type);
_Py_NewReference((PyObject *)mp);
if (mp->ma_fill) {
EMPTY_TO_MINSIZE(mp);
} else {
INIT_NONZERO_DICT_SLOTS(mp);
}
assert (mp->ma_used == 0);
assert (mp->ma_table == mp->ma_smalltable);
assert (mp->ma_mask == PyDict_MINSIZE - 1);
} else {
mp = PyObject_GC_New(dictobject, &PyDict_Type);
if (mp == NULL)
return NULL;
EMPTY_TO_MINSIZE(mp);
}
mp->ma_lookup = lookdict_string;
_PyObject_GC_TRACK(mp);
return (PyObject *)mp;
}
|
第一次调用PyDict_New时, 会创建一个dummy对象. 作为一个指示标志, 表示该entry曾被使用, 且下一个entry可能是有效的.
若PyDictObject对象的缓存池不可用, 会从系统堆中申请新的内存空间, 然后通过两个宏来完成初始化工作:
EMPTY_TO_MINSIZE: 将ma_smalltable清零, 并将ma_size和ma_fill设置为0INIT_NONZERO_DICT_SLOTS: 让ma_table指向ma_smalltable, 并设置ma_mask为7
除此之外, 还要将lookdict_string分配给ma_lookup, 作为PyDictObject的搜索策略
3.2 PyDictObject的元素搜索
Python有两种搜索策略: lookdict和lookdict_string. 实际上lookdict_string只是针对PyStringObject对象的特殊搜索方式, 由于PyStringObject对象经常作为entry的key, 所以lookdict_string为PyDictObject的默认搜索策略.
以下是Python的通用搜索策略lookdict:
static dictentry* lookdict(dictobject *mp, PyObject *key, register long hash)
{
register size_t i;
register size_t perturb;
register dictentry *freeslot;
register size_t mask = (size_t)mp->ma_mask;
dictentry *ep0 = mp->ma_table;
register dictentry *ep;
register int cmp;
PyObject *startkey;
i = (size_t)hash & mask;
ep = &ep0[i];
if (ep->me_key == NULL || ep->me_key == key)
return ep;
if (ep->me_key == dummy)
freeslot = ep;
else {
if (ep->me_hash == hash) {
startkey = ep->me_key;
Py_INCREF(startkey);
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0)
return NULL;
if (ep0 == mp->ma_table && ep->me_key == startkey) {
if (cmp > 0)
return ep;
} else {
return lookdict(mp, key, hash);
}
}
freeslot = NULL;
}
}
|
上述代码只是对探测到的第一个entry进行的操作. 由于需要将hash值映射到某个entry上, 所以让hash值与entry数量做与操作, 这样会处于entry数量之中. lookdict不会返回NULL, 即使没有找到对象, 也会返回一个entry, 这个entry的value为NULL, 表示没有搜索到对应元素.
freeslot是一个很重要的变量. 若探测链的某个位置上的entry为Dummy, 则将第一个Dummy entry赋予freeslot; 若搜索失败, 则返回freeslot, 由于entry的value为NULL, 所以表示搜索失败; 若探测链中没有Dummy entry且搜索失败, 则一定在某个Unused entry上结束搜索, 返回该Unused entry同样表示搜索失败.
Python中相同key有两层含义:
- 引用相同: 指向的内存是同一个地址
- 值相同: 指向了不同地址, 但存储的值相同
举个例子, 由于整数对象中小整数可以共享, 而大整数不共享, 所以下面的代码中不能使用引用相同来判断key是否相同:
>>> d={}
>>> d[9876] = "Python"
>>> print d[9876]
Python
>>>
|
第二行的9876和第三行的9876地址不同, 因为大整数并不共享, 每次创建都会占用不同的内存空间, 这时就需要"值相同"来确定key是否存在.
在lookdict中, 会先检查hash值是否相同. 如果hash值相同只说明值相同, 并通过PyObject_RichCompareBool进行比较, 以下是该函数原型:
int PyObject_RichCompareBool(PyObject* v, PyObject* w, int op)
|
当对比相同时, 返回1; 不同返回0; 比较发生错误返回-1. 以下是lookdict中进行第一次检查时所进行的动作步骤:
- 根据hash值获得entry索引, 作为冲突探测链的第一个entry索引
- 在两种情况下, 搜索结束:
- entry处于Unused态, 冲突探测链搜索完成, 搜索失败
ep->me_key == key, entry的key与所搜索的key匹配, 搜索成功
- 若当前entry处于Dummy, 设置freeslot
- 检查Active态entry中的key与待查找的key是否"值相同", 若相同则搜索成功; 如果探测链上的第一个entry的key不对应, 则会沿着探测链不断查找
static dictentry* lookdict(dictobject *mp, PyObject *key, register long hash)
{
register size_t i;
register size_t perturb;
register dictentry *freeslot;
register size_t mask = (size_t)mp->ma_mask;
dictentry *ep0 = mp->ma_table;
register dictentry *ep;
register int cmp;
PyObject *startkey;
for (perturb = hash; ; perturb >>= PERTURB_SHIFT) {
i = (i << 2) + i + perturb + 1;
ep = &ep0[i & mask];
if (ep->me_key == NULL)
return freeslot == NULL ? ep : freeslot;
if (ep->me_key == key)
return ep;
if (ep->me_hash == hash && ep->me_key != dummy) {
startkey = ep->me_key;
Py_INCREF(startkey);
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0)
return NULL;
if (ep0 == mp->ma_table && ep->me_key == startkey) {
if (cmp > 0)
return ep;
}
else {
return lookdict(mp, key, hash);
}
}
else if (ep->me_key == dummy && freeslot == NULL)
freeslot = ep;
}
assert(0);
return 0;
}
|
我们可以发现, 对于之后的entry的检查和第一个entry的检查相同. 下面是遍历探测链时所进行的操作:
- 根据探测函数获得下一个entry
- 检查到Unused态entry, 搜索失败:
- 如果freeslot不为空, 返回freeslot
- 如果freeslot为空, 返回该Unused态的entry
- 检查entry中key与待查找的key的引用是否相同
- 检查entry中key与待查找的key的值是否相同
- 发现Dummy态entry且freesolt为NULL时, 设置freesolt为该Dummy态entry
无论搜索是否成功, 一定会返回一个entry. 如果返回一个Dummy态的entry, 那么表明这个entry是空闲的, 可以被使用. 以下是Python的默认搜索策略lookdict_string:
static dictentry* lookdict_string(dictobject *mp, PyObject *key, register long hash)
{
register size_t i;
register size_t perturb;
register dictentry *freeslot;
register size_t mask = (size_t)mp->ma_mask;
dictentry *ep0 = mp->ma_table;
register dictentry *ep;
if (!PyString_CheckExact(key)) {
mp->ma_lookup = lookdict;
return lookdict(mp, key, hash);
}
i = hash & mask;
ep = &ep0[i];
if (ep->me_key == NULL || ep->me_key == key)
return ep;
if (ep->me_key == dummy)
freeslot = ep;
else {
if (ep->me_hash == hash && _PyString_Eq(ep->me_key, key))
return ep;
freeslot = NULL;
}
for (perturb = hash; ; perturb >>= PERTURB_SHIFT) {
i = (i << 2) + i + perturb + 1;
ep = &ep0[i & mask];
if (ep->me_key == NULL)
return freeslot == NULL ? ep : freeslot;
if (ep->me_key == key ||
(ep->me_hash == hash && ep->me_key != dummy
&& _PyString_Eq(ep->me_key, key)))
return ep;
if (ep->me_key == dummy && freeslot == NULL)
freeslot = ep;
}
assert(0);
return 0;
}
|
lookdict_string相当于lookdict的优化版, 由于知道了key为PyStringObject对象, 所以可以省去不少错误处理代码, 并且, _PyString_Eq也要简单的多, 这都提高了搜索效率.
3.3 插入与删除
以下是插入操作的函数:
static int insertdict(register dictobject *mp, PyObject *key, long hash, PyObject *value)
{
PyObject *old_value;
register dictentry *ep;
typedef PyDictEntry *(*lookupfunc)(PyDictObject *, PyObject *, long);
assert(mp->ma_lookup != NULL);
ep = mp->ma_lookup(mp, key, hash);
if (ep == NULL) {
Py_DECREF(key);
Py_DECREF(value);
return -1;
}
if (ep->me_value != NULL) {
old_value = ep->me_value;
ep->me_value = value;
Py_DECREF(old_value);
Py_DECREF(key);
}
else {
if (ep->me_key == NULL)
mp->ma_fill++;
else {
assert(ep->me_key == dummy);
Py_DECREF(dummy);
}
ep->me_key = key;
ep->me_hash = (Py_ssize_t)hash;
ep->me_value = value;
mp->ma_used++;
}
return 0;
}
|
步骤:
- 使用
ma_lookup在冲突链上寻找位置, 返回一个名为ep的entry
- ep为NULL, 理论上应返回一个entry, 说明发生错误
ep->me_value != NULL: 说明entry为Active, 更新me_value即可ep->me_key==NULL: 说明entry为Unused, 需要将mp->ma_fill+1ep->me_key==dummy: 说明entry为Dummy, 将dummy的引用-1
实际运行中并不会直接调用insertdict函数来实现插入和设置元素, 因为insertdict需要hash值作为参数. 所以在调用insertdict之前需要调用PyDict_SetItem:
int PyDict_SetItem(register PyObject *op, PyObject *key, PyObject *value)
{
register dictobject *mp;
register long hash;
register Py_ssize_t n_used;
if (!PyDict_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
assert(key);
assert(value);
mp = (dictobject *)op;
if (PyString_CheckExact(key)) {
hash = ((PyStringObject *)key)->ob_shash;
if (hash == -1)
hash = PyObject_Hash(key);
} else {
hash = PyObject_Hash(key);
if (hash == -1)
return -1;
}
assert(mp->ma_fill <= mp->ma_mask);
n_used = mp->ma_used;
Py_INCREF(value);
Py_INCREF(key);
if (insertdict(mp, key, hash, value) != 0)
return -1;
if (!(mp->ma_used > n_used && mp->ma_fill*3 >= (mp->ma_mask+1)*2))
return 0;
return dictresize(mp, (mp->ma_used > 50000 ? 2 : 4) * mp->ma_used);
}
|
以下是dictresize, 它负责调整table大小:
static int dictresize(dictobject *mp, Py_ssize_t minused)
{
Py_ssize_t newsize;
dictentry *oldtable, *newtable, *ep;
Py_ssize_t i;
int is_oldtable_malloced;
dictentry small_copy[PyDict_MINSIZE];
assert(minused >= 0);
for (newsize = PyDict_MINSIZE;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
oldtable = mp->ma_table;
assert(oldtable != NULL);
is_oldtable_malloced = oldtable != mp->ma_smalltable;
if (newsize == PyDict_MINSIZE) {
newtable = mp->ma_smalltable;
if (newtable == oldtable) {
if (mp->ma_fill == mp->ma_used) {
return 0;
}
assert(mp->ma_fill > mp->ma_used);
memcpy(small_copy, oldtable, sizeof(small_copy));
oldtable = small_copy;
}
}
else {
newtable = PyMem_NEW(dictentry, newsize);
if (newtable == NULL) {
PyErr_NoMemory();
return -1;
}
}
assert(newtable != oldtable);
mp->ma_table = newtable;
mp->ma_mask = newsize - 1;
memset(newtable, 0, sizeof(dictentry) * newsize);
mp->ma_used = 0;
i = mp->ma_fill;
mp->ma_fill = 0;
for (ep = oldtable; i > 0; ep++) {
if (ep->me_value != NULL) {
--i;
insertdict_clean(mp, ep->me_key, (long)ep->me_hash,
ep->me_value);
}
else if (ep->me_key != NULL) {
--i;
assert(ep->me_key == dummy);
Py_DECREF(ep->me_key);
}
}
if (is_oldtable_malloced)
PyMem_DEL(oldtable);
return 0;
}
|
以下是删除元素的操作函数:
int PyDict_DelItem(PyObject *op, PyObject *key)
{
register dictobject *mp;
register long hash;
register dictentry *ep;
PyObject *old_value, *old_key;
if (!PyDict_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
assert(key);
if (!PyString_CheckExact(key) ||
(hash = ((PyStringObject *) key)->ob_shash) == -1) {
hash = PyObject_Hash(key);
if (hash == -1)
return -1;
}
mp = (dictobject *)op;
ep = (mp->ma_lookup)(mp, key, hash);
if (ep == NULL)
return -1;
if (ep->me_value == NULL) {
set_key_error(key);
return -1;
}
old_key = ep->me_key;
Py_INCREF(dummy);
ep->me_key = dummy;
old_value = ep->me_value;
ep->me_value = NULL;
mp->ma_used--;
Py_DECREF(old_value);
Py_DECREF(old_key);
return 0;
}
|
3.4 PyDictObject对象缓冲池
PyDictObject对象的缓冲池如下:
#define MAXFREEDICTS 80
static PyDictObject *free_dicts[MAXFREEDICTS];
static int num_free_dicts = 0;
|
PyDictObject的缓冲机制与PyListObject相同, 都是在对象被销毁时进行缓冲.
static void
dict_dealloc(register dictobject *mp)
{
register dictentry *ep;
Py_ssize_t fill = mp->ma_fill;
PyObject_GC_UnTrack(mp);
Py_TRASHCAN_SAFE_BEGIN(mp)
for (ep = mp->ma_table; fill > 0; ep++) {
if (ep->me_key) {
--fill;
Py_DECREF(ep->me_key);
Py_XDECREF(ep->me_value);
}
}
if (mp->ma_table != mp->ma_smalltable)
PyMem_DEL(mp->ma_table);
if (num_free_dicts < MAXFREEDICTS && mp->ob_type == &PyDict_Type)
free_dicts[num_free_dicts++] = mp;
else
mp->ob_type->tp_free((PyObject *)mp);
Py_TRASHCAN_SAFE_END(mp)
}
|
与PyListObject相同, 缓冲池只保留PyDictObject对象, 释放系统堆中申请的内存. 在创建新的PyDictObject对象时, 若缓冲池有可用对象, 则从缓冲池取出:
PyObject *PyDict_New(void)
{
register dictobject *mp;
if (num_free_dicts) {
mp = free_dicts[--num_free_dicts];
_Py_NewReference((PyObject *)mp);
if (mp->ma_fill) {
EMPTY_TO_MINSIZE(mp);
} else {
INIT_NONZERO_DICT_SLOTS(mp);
}
}
}
|